DOI:10.32604/cmc.2021.013744
| Computers, Materials & Continua DOI:10.32604/cmc.2021.013744 | |
| Article |
Recognition of Offline Handwritten Arabic Words Using a Few Structural Features
Department of Electrical Engineering, Laboratory: LTIT, Tahri Mohammed University, Bechar, 08000, Algeria
*Corresponding Author: Abderrahmane Saidi. Email: saidi.abderrahmane.2017@gmail.com
Received: 18 August 2020; Accepted: 12 October 2020
Abstract: Handwriting recognition is one of the most significant problems in pattern recognition, many studies have been proposed to improve this recognition of handwritten text for different languages. Yet, Fewer studies have been done for the Arabic language and the processing of its texts remains a particularly distinctive problem due to the variability of writing styles and the nature of Arabic scripts compared to other scripts. The present paper suggests a feature extraction technique for offline Arabic handwriting recognition. A handwriting recognition system for Arabic words using a few important structural features and based on a Radial Basis Function (RBF) neural networks is proposed. The methods of feature extraction are central to achieve high recognition performance. The proposed methodology relies on a feature extraction technique based on many structural characteristics extracted from the word skeleton (subwords, diacritics, loops, ascenders, and descenders). In order to reach our purpose, we built our own word database and the proposed system has been successfully tested on a handwriting database of Algerian city names (wilayas). Finally, a simple classifier based on the radial basis function neural network is presented to recognize certain words to verify the reliability of the proposed feature extraction. The experiments on some images of the benchmark IFN/ENIT database show that the proposed system improves recognition and the results obtained are indicative of the efficiency of our technique.
Keywords: Offline Arabic handwriting recognition; preprocessing; feature extraction; structural features; RBF neural network
Arabic is one of the world’s most used languages. It is today spoken by more than 300 million people in the Arab World, and is an official language in 22 countries. The importance of the Arabic script lies in being the writing medium of many languages (e.g., Arabic, Urdu, Persian, etc.), as spoken by millions of people in many Islamic countries such as Iran, Afghanistan, Pakistan, and many others. Over the past three decades, many research papers and articles have been proposed and suggest various solutions for the problem of Arabic handwriting recognition. Arabic handwriting is both cursive and unconstrained. It is one of the most complicated scripts since it presents variants of Latin handwriting recognition. Its off-line recognition is one of the most challenging problems. Nevertheless, compared to Latin and Chinese handwritten character recognition, little research has been done on Arabic’s handwritten character recognition [1].
In general, the word recognition procedure comprises two basic steps: First, feature extraction: where each word is represented as a feature vector; second, classification of the vectors into a number of classes: the selection of the feature extraction method might be the most important step to accomplish a high recognition accuracy. Due to the nature of Arabic handwriting with its high degree of variability and imprecision, obtaining these features is a difficult task. There are various sorts of features proposed by researchers. These features can broadly be classified into two types: structural and statistical features. Structural features are intuitive aspects of writing, such as loops, branch points, endpoints, dots, etc.
Many Arabic letters share common primary shapes, differing only in the number of diacritic points (dots) and whether the dots are above or below the primary shape. Structural features are a natural method for capturing dot information explicitly, which is required to distinguish such letters. This perspective may be a reason that structural features remain more common for the recognition of Arabic script than for that of Latin [2]. Statistical features are numerical measures computed over images or parts of images. They include pixel densities, histograms of chain code directions, moments, Fourier descriptors, etc. [3]. Structural features describe the geometrical and topological characteristics of a pattern by describing its global and local properties.
Several studies have investigated Arabic handwritten word recognition using structural features, Almuallim et al. [4] proposed one of the first attempts using structural features. The system was based on simple geometrical features and words were segmented into “strokes” called graphemes, which were classified and combined into characters. In [5], Arabic words were described by a set of features describing structural characteristics, and then the classification of this description was performed by means of a Hidden Markov Model (HMM). After preprocessing, the skeleton binary image of each word, the latter is decomposed into a number of curved edges in a certain order. Each edge is transformed into a feature vector, including features of curvature and length that are normalized to stroke thickness. Recognition rates ranging from 68% to 73% were accomplished depending on the task performed. In [6] a system based on a neuro-symbolic classifier for the recognition of handwritten Arabic literal amounts was implemented. Authors extracted structural features like loops, diacritics dots, ascenders, descenders and sub-words. Next, a database was constructed according to their features. The system was tested on 1200 words and achieved a recognition rate of 93.00%.
Azizi et al. [7] used global structural features that include the number of sub-words, descenders, ascenders, a unique dot below the baseline, unique dot above the baseline, two dots below the baseline, two dots bound above the baseline, three bound dots, Hamzas (zigzags), Loop, tsnine (by calculating the number of intersections in the middle of the median zone) and Concavity features with the four configurations. They also used the density measures or “zoning.” Kacem et al. [8] presented an efficient feature extraction technique for the Arabic handwritten word in which a structural feature extraction method was proposed for Arabic handwritten personal names recognition with the purpose of maximizing recognition rate with the least of elements. The method incorporates a considerable structural information like loops, stems, legs, and diacritics. Features extraction results were evaluated by computing the Levenshtein distance or edit distance, which is a string metric to measure the distance between two sequences. Parvez et al. [9] proposed the first integrated offline Arabic handwritten text recognition system based on structural features. For the implementation of the system, several novel algorithms for Arabic handwriting recognition using structural features were introduced. A segmentation algorithm was integrated into the recognition phase of the handwritten text, which was followed by Arabic character modelling by “fuzzy” polygons. This proposed system was tested using the IFN/ENIT database and the recognition rate achieved was promising, attaining as much as 79.58%.
El-Hajj [10] has introduced a system for Arabic handwriting recognition without segmentation based on HMM. That system uses baseline dependent features in which the upper and lower baselines of words are extracted using horizontal projection. The images are divided into vertical overlapping frames. 24 features being extracted from each frame. Two types of features are used: distribution features and concavity features. This system was evaluated on an IFN/ENIT database and achieved an average recognition rate of 86.51%.
AlKhateeb et al. [11] presented a comparative study of approaches for recognizing handwritten Arabic words using Hidden Markov Models (HMM) and Dynamic Bayesian Network (DBN) classifiers. This system involves three steps. First, preprocessing tasks including skew/slant correction and normalisation. Secondly, the word image is divided into frames from which a set of features are extracted. This system was tested on the IFN/ENIT, and achieved a recognition rate of 82.32% and 83.55% with re-ranking. Ghanmi et al. [12], authors used a simple and reduced set of features, the system is based on two Hidden Markov Models (HMM) using dynamic Bayesian network formalism. This system was tested on a set of 9 classes from the IFN/ENIT and achieved a recognition rate of 73.5% with re-ranking. In [13] CNN was applied for feature extraction and classification as well, and achieved a recognition rate of 89.23%.
In this paper, a feature extraction model has been proposed to improve the recognition of handwritten Arabic words. As a first step, we used the RBF neural network, and for the classification step, we used structural characteristics but in a different way from those used in previous methods. The rest of this study is organized as follows: In the second section, we describe the characteristics of the Arabic language handwriting. In the third section, we will present an overview of the proposed recognition system, the fourth section is devoted to the presentation of our Arabic word recognition system and its four parts, with focus on the feature extraction technique. Finally, we present the experimental results followed by some conclusions.
3 Overview of the Proposed System
The recognition of Arabic handwritten word is achieved into four principal steps: Image acquisition, preprocessing, feature extraction, and word classification. We have intentionally avoided the step of words segmentation into characters by using the holistic (global) approach. Several systems are available based on two approaches: (1) A global approach that considers the word as non-divisible, (2) The analytical approach based on the decomposition of the word sequence into characters or graphemes proceeding by a segmentation phase. Due to the presence of the ligature and to the cursive nature of Arabic script. Several researchers have presented techniques based on the global approach without segmentation [10–14], considering the word as a non-divisible base entity, and avoiding the segmentation process and its constraints. The system proposed here uses this approach because it is reliable and applicable for vocabularies of limited size.
Fig. 1 shows the overall process in word recognition. For image acquisition, the paper is scanned and each word is put in a separated image. In the second step, the word images are preprocessed to remove unwanted regions and reduce noise in order to increase accuracy. The processed image is now fed into feature extraction step to obtain a feature vector. Feature vector is a set of features that can uniquely classify each word. Feature extraction is the process of analyzing the whole word image to extract a set of features. The feature vector, thus obtained is given into the classifier based on the RBF neural network. Classifiers will take this feature vectors and their corresponding labels as input and produce some models. In the testing stage, the test image is preprocessed and placed for feature extraction, and this feature vector along with classifier model is used to produce the desired output.
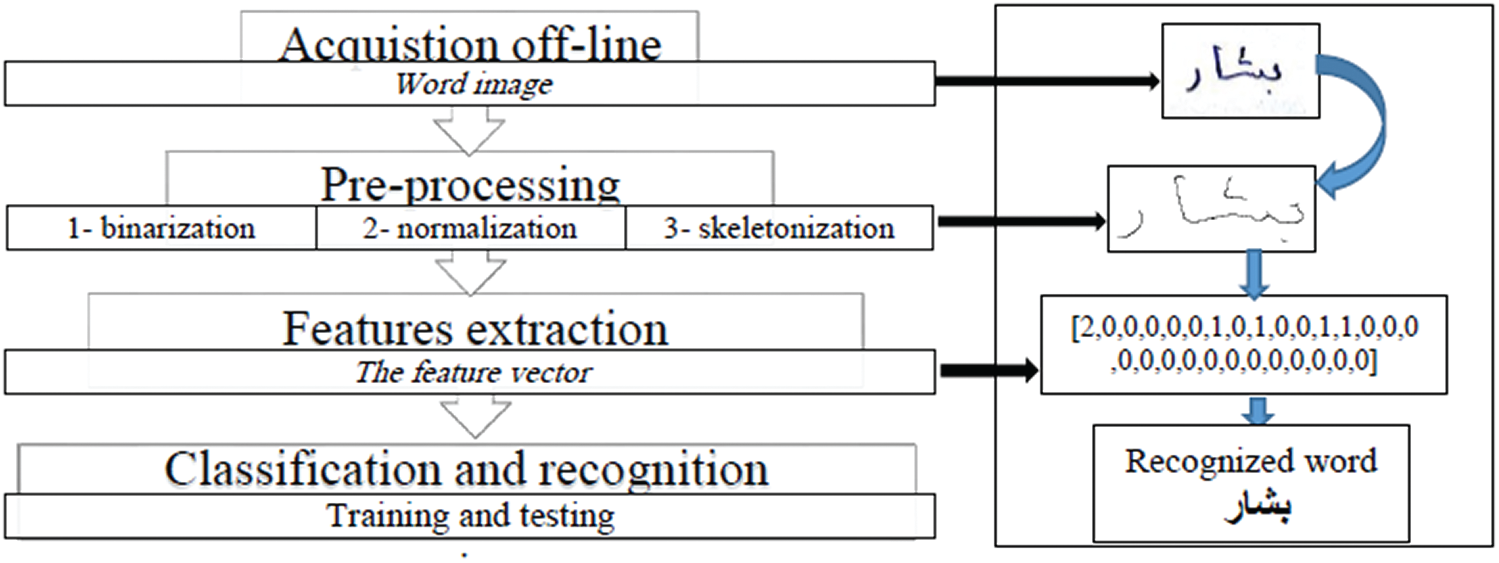
Figure 1: Overview of system
The proposed system is developed for Arabic handwriting word recognition, in our work, we used MATLAB language to implement this system recognition. Below is a description of the different steps followed by our system.
4.1 Data Acquisition and Preprocessing
At this stage, the input image is converted into a digitally image using a scanner with JPG format, which is suitable for a digital computer. After this procedure, we cut each word as an image by means of a snipping tool program, then we stored images in a separated file in a JPG format at 300 dpi (dpi (dots per inch)) with (8 bits/pixels). The forms were scanned in color mode. Fig. 2 shows some images of the developed database before and after the cutting process.
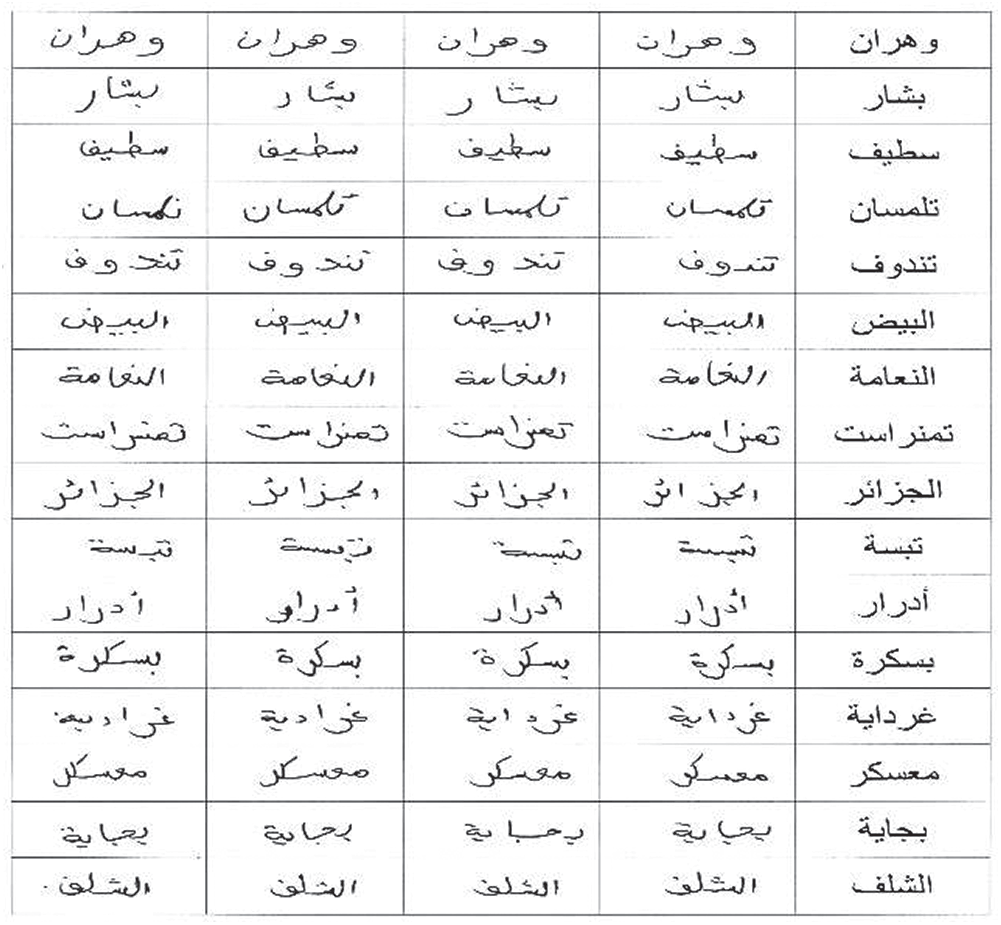
Figure 2: Samples of the proposed database
After scanning the document, some basic preprocessing tasks have to be performed like converting the input image to grey image, image binarization, and noise reduction. Preprocessing is the second step in a recognition system, which consists of several operations performed to improve the quality of the original image and make it suitable for future processing [15]. Fig. 3 illustrates sample images and images after the preprocessing steps. In our case, we used the following preprocessing operations:
Noise Removal: Distortion in the image usually occurs during the scanning process. Small objects not part of the writing can be considered as noise, and this step removes the unwanted bit patterns from the image. The median filtering technique has been used by most of the researchers to remove it.
Binarization: The images of the words were first converted into grey scale images and then into Black & White Binary Images. The grayscale word images are converted into their respective binarized images using an adaptive thresholding technique. The adaptive threshold value is considered as the average of the maximum and minimum grayscale values of the respective images.
Skeletonization: This is a crucial step; the skeleton is a one-pixel thick representation showing the center lines of the word. Skeletonization or “thinning” facilitates shape classification and features detection.
Normalization: The last step in the preprocessing phase is to resize the input image to normalize all the input images with different sizes. Size normalization is commonly used to reduce size variation and adjust the word sizes to an identical size [16], for this, the height and width of all words are fixed to a value. In illustration below, each word image has been normalized to  pixels.
pixels.
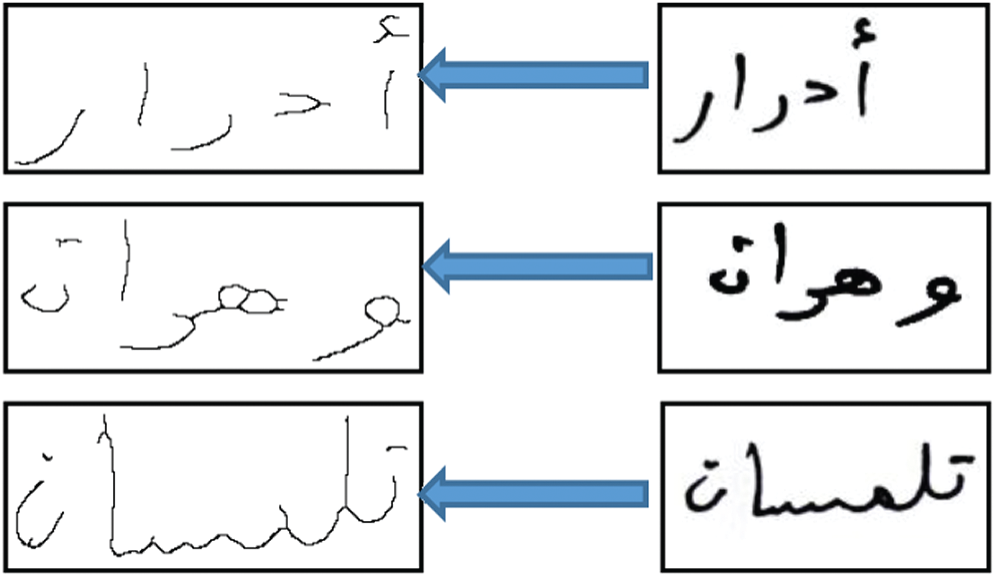
Figure 3: Samples of original images with preprocessed images
In the process of automatic handwriting recognition, feature extraction is an important step, which consists in finding a set of measured values that accurately discriminate the input handwritten words. Features are the information extracted from a word/character or some representation of the image, which is relied on to represent the shape. There are numerous types of features proposed by researchers. In general, there are two categories of features to be extracted; structural and statistical features. Nevertheless, the real problem for a given application, is not only to find different features extraction approaches but to decide which features extraction method is the best. Hence, choosing the right method for feature extraction might be the most important step for achieving a high recognition rate [17].
In our system we choose only structural features because psychological studies have shown that they are extensively used during the human reading process [18,19], also, structural features are based on topological and geometrical properties. We can observe that handwritten Arabic characters differ from one person to another, but the geometrical features are always the same [20]. An explanation of how to extract some structural features will be given such as ascenders, descenders, loops, diacritic points and their position related to the baseline and consider their position in the word: at the beginning, in the middle or at the end, in the upper or lower bands. Afterwards, connected components are respectively extracted. We collected 28 structural features from each image that are proposed in this paper and are then stored in an array called feature vector.
—Baseline Estimation: Indeed, a common step is the detection of the baseline because the baseline information can be of great importance for efficient feature extraction. Horizontal projection methods are commonly used by the OCR researchers to detect Arabic baseline [21], which is the projection of the binary image of a word or line of text into a Horizontal line. The baseline can be detected as the maximal peak. This approach is ineffective for some single words or short sequences of words. Detecting the baseline helps determine certain structural features, such as diacritic points and their positions, ascenders and descenders, as well as enabling skew/slant correction. Our method considers the entire word skeleton to detect a single Arabic handwriting baseline. We will compute the row-wise sum of all black pixels of a stripe of 20 consecutive rows to determine the baseline. In order to do that, it is important to estimate the region that contains the baseline then detects the baseline as a straight line. It is worth remembering that all word Skelton images are normalized to the size of  , so we have 100 rows. Based on this, the process steps of the proposed Arabic baseline estimation are as follows:
, so we have 100 rows. Based on this, the process steps of the proposed Arabic baseline estimation are as follows:
Step 1: The candidate region that may contain the baseline will be estimated using a horizontal projection histogram.
Step 2: Any region in the horizontal histogram having a set of 20 continuous rows of text pixels, which must contain the maximum number of foreground pixels (black pixels) BR is considered as a candidate baseline region, as it is shown in Fig. 5.
Step 3: The baseline divides the image into inferior and superior parts, where one can notice 15 rows in the superior part and 5 rows in the inferior part as shown in Fig. 4.

Figure 4: The proposed baseline estimation

Figure 5: The proposed baseline estimation
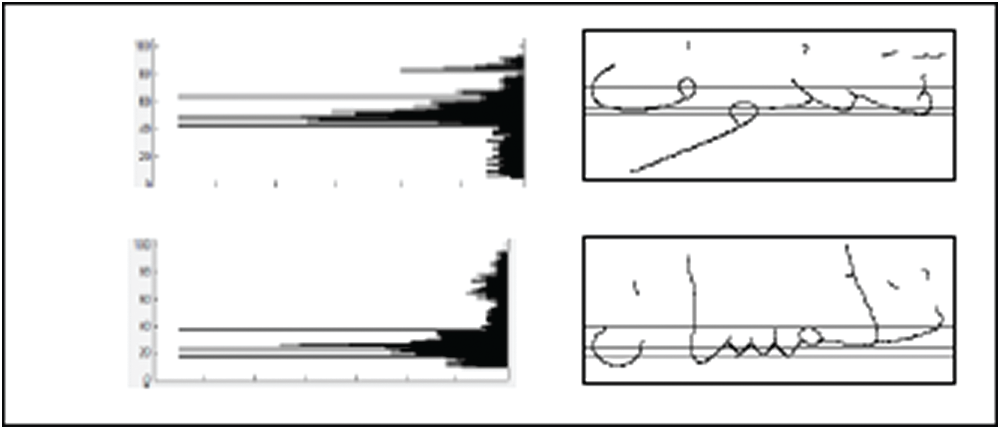
Figure 6: Examples of word baseline estimation
—Diacritics points Extraction: First, the area of each connected component in the word must be obtained from the Skelton image resized in  . In comparison to any other isolated character in Arabic scripts, the shape intensity of diacritics appears rather diminished typically [22].
. In comparison to any other isolated character in Arabic scripts, the shape intensity of diacritics appears rather diminished typically [22].
After analyzing all the areas of the Diacritic points in a word, it was found that the areas of the Diacritic points are all less than the threshold value threshold 1 in a specific area (i.e., 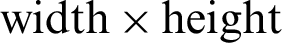 ) upon the calculation of the number of foreground black pixels. Thus, any component that is less than
) upon the calculation of the number of foreground black pixels. Thus, any component that is less than 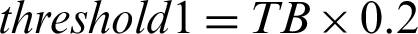 which TB is the total number of black pixels of the whole word (skeleton image), and the specific area used (
which TB is the total number of black pixels of the whole word (skeleton image), and the specific area used (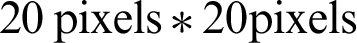 ) is considered as Diacritic points. Notice that diacritic points do not cross the baseline and can sometimes be merged into one component, so two or three diacritic points can be presented in the same way. The diacritical point position is determined relative to the baseline, at the beginning, in the middle and/or at their end. The number of diacritic points varies from one to three (see Fig. 7).
) is considered as Diacritic points. Notice that diacritic points do not cross the baseline and can sometimes be merged into one component, so two or three diacritic points can be presented in the same way. The diacritical point position is determined relative to the baseline, at the beginning, in the middle and/or at their end. The number of diacritic points varies from one to three (see Fig. 7).

Figure 7: Diacritic extraction results
—Connected Components Extraction (PAWs): Connected components are subwords composed of a set of connected characters and called Parts of the Arabic Word. Connected components remain in the skeleton image and we can deduce them in the study. PAW (Piece of Arabic Word) body refers to connected components in handwriting after diacritic point removal.
—Loops Extraction: Loop feature exists in approximately half of the non-punctuated Arabic character set. The first idea in loop extraction is to use the contour. After going over all extracted contours, we detect the closed ones (see Fig. 10).
—Ascender and descenders: The ascender and descender are respectively defined as a shape having an extension above the upper baseline and below the lower baseline [23]. Moreover, ascenders and descenders are respectively determined by the top and bottom lines. The distance between this maximum and the baseline should not above a certain threshold. This threshold is estimated as 75% of the superior part BUB determining the line of ascenders, and 65% of the inferior part BLB determining the line of descenders. Fig. 8 presents some of our extraction methods of ascenders and descenders.
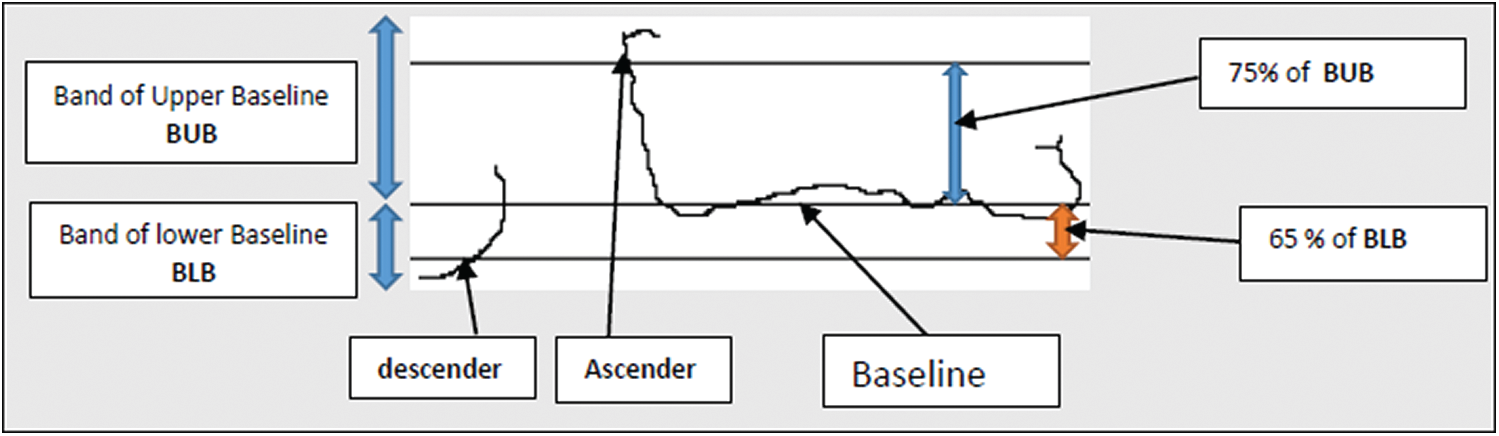
Figure 8: Ascender and descender extraction results
In this study, the word image has been implicitly divided horizontally into an upper and a lower band according to baseline. We also divided the word image rows vertically, into three strips; The beginning (50 rows), the middle (150 rows) and end band (50 rows) as shown in Fig. 9. This work proposed a method to extract some structural features, mainly loops, ascenders, descenders and diacritics points, considering their position in the word: at the beginning, in the middle or at the end, in the upper and the lower bands. Tab. 1 shows the extracted structural features and classifies them according to their positions in the word.
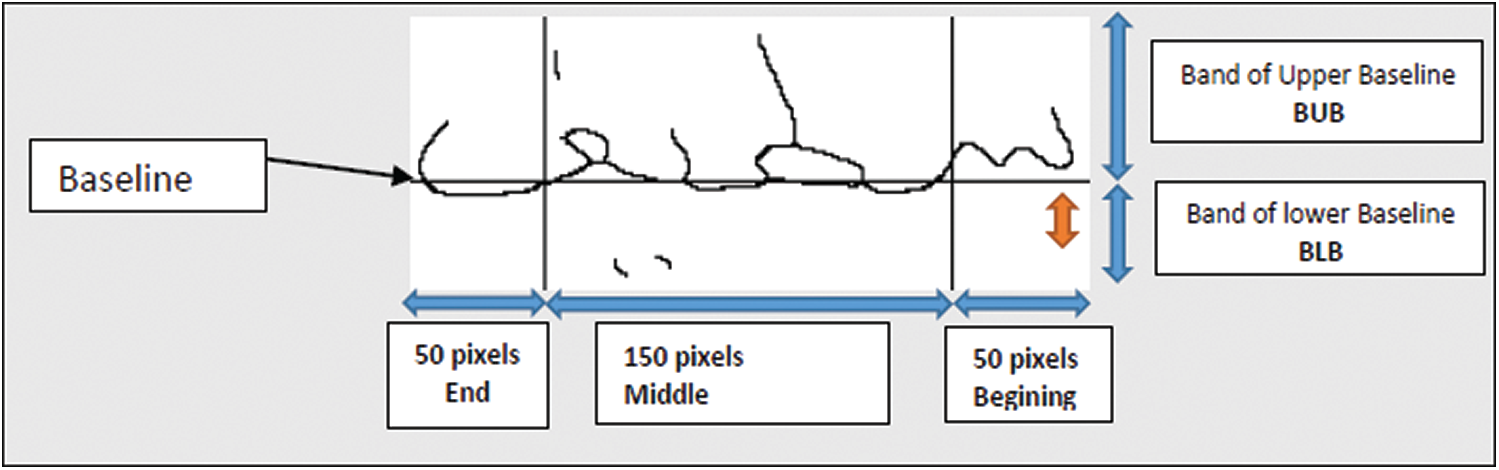
Figure 9: The parts used for word recognition (beginning, middle, end bands; the upper baseline and lower baseline bands)
Table 1: Extracted structural features in the Arabic vocabulary
We extracted some structural features form of skeleton images such as diacritic points, ascenders, descenders and loops and we determined their position depending on whether they are: at the beginning, middle or end band of a word, and upper or lower band of it. Fig. 10 illustrates an example of the word وهران with its structural features. Fig. 11 illustrates an example of the word الشرايع from IFN/ENIT database with its structural features. At the end of the feature extraction phase, a word is described by a features vector containing 28 elements as shown in Tabs. 2 and 3; these features are utilized for recognition in the classification stage.
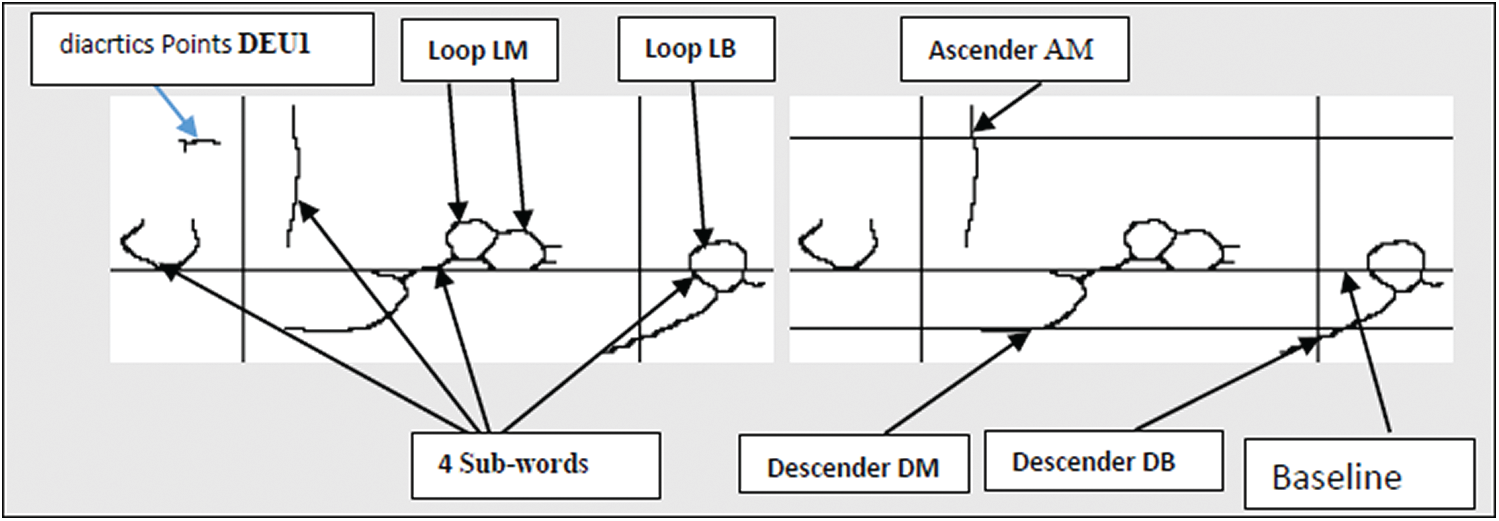
Figure 10: Features extraction results of word وهران
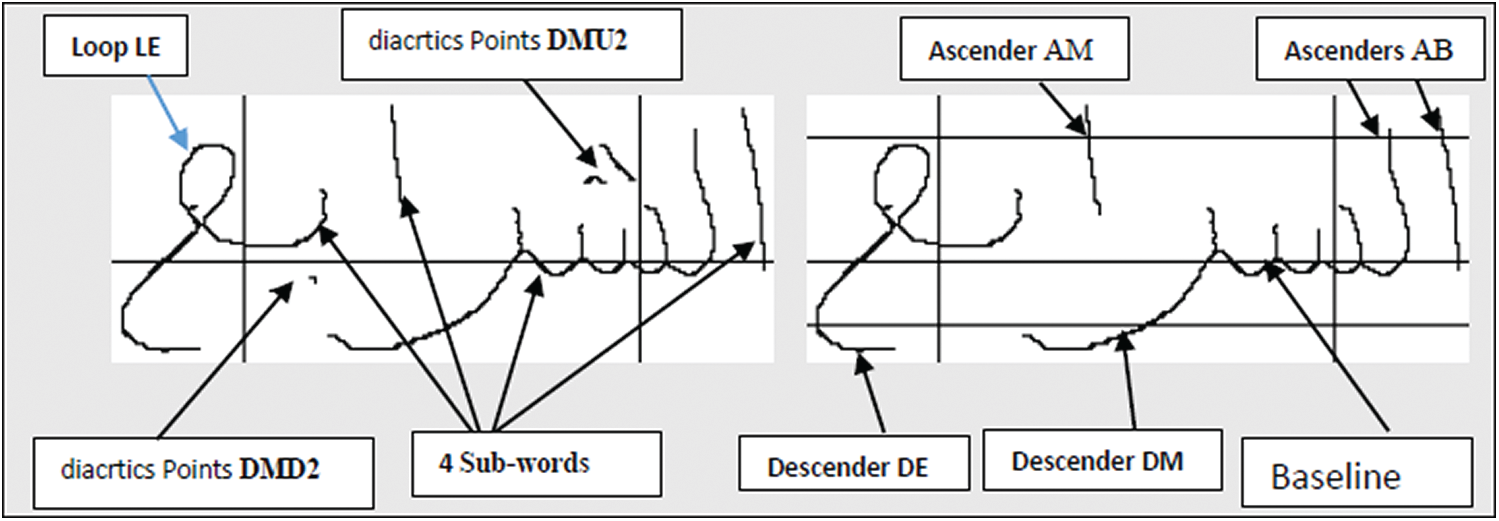
Figure 11: Features extraction results of word الشرايع
Table 2: Features of word وهران
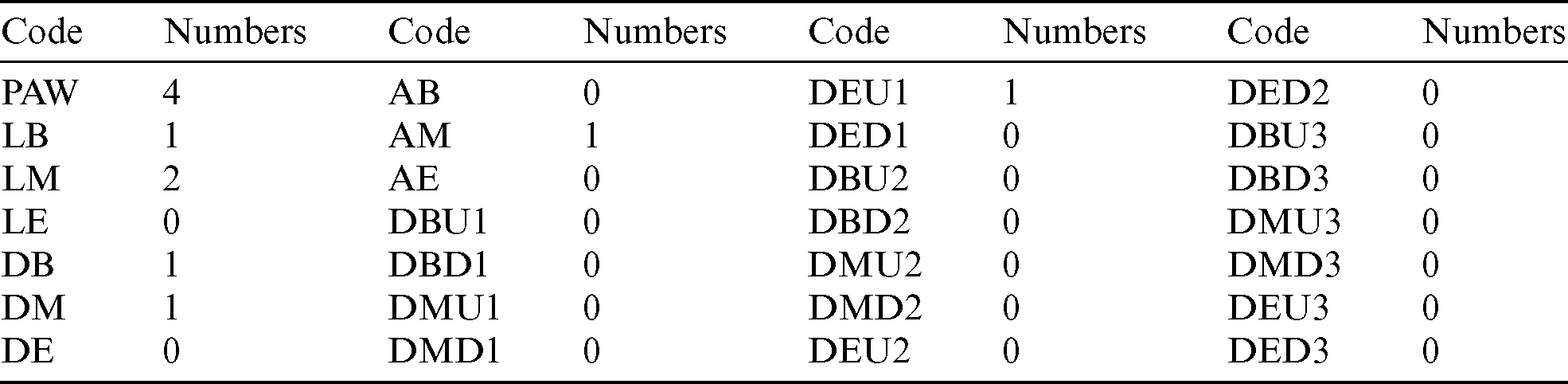
Table 3: Vector features of word وهران and بشار

This section briefly describes the classifier used in our research; it is based on the radial basis function (RBF) neural network. Classification is the decision making part of a recognition system which attempts to identify an object by comparing its features with one of a given set of classes. The classification stage uses the features extracted in the previous stage. Our system performs a global recognition of city names (Cities) where the word is recognized as one entity. The learning method used for classification is based on RBF neural network. Radial-Basis Function (RBF) is also the most commonly used, an RBF is a feed-forward neural network that has only one hidden layer with an unsupervised training method [24] RBF has been widely used in many different research fields, such as pattern classification, function approximation, regularization, noisy interpolation and text classification [25,26].
RBF neural network is one of the effective non-linear separation methods, which has attracted considerable attention in recent years due to its simple structure and instruction. These networks have three layers: (1) An input layer, (2) A hidden layer with a non-linear RBF activation function, and (3) A linear output layer. At the output layer, linear combinations of the hidden layer node responses are added to form the output. The hidden layer size contains the number of samples taken for classification. In this layer, a pure linear transfer function is used to calculate the weighted input and net input. The output layer contains the number of classes in the input samples.
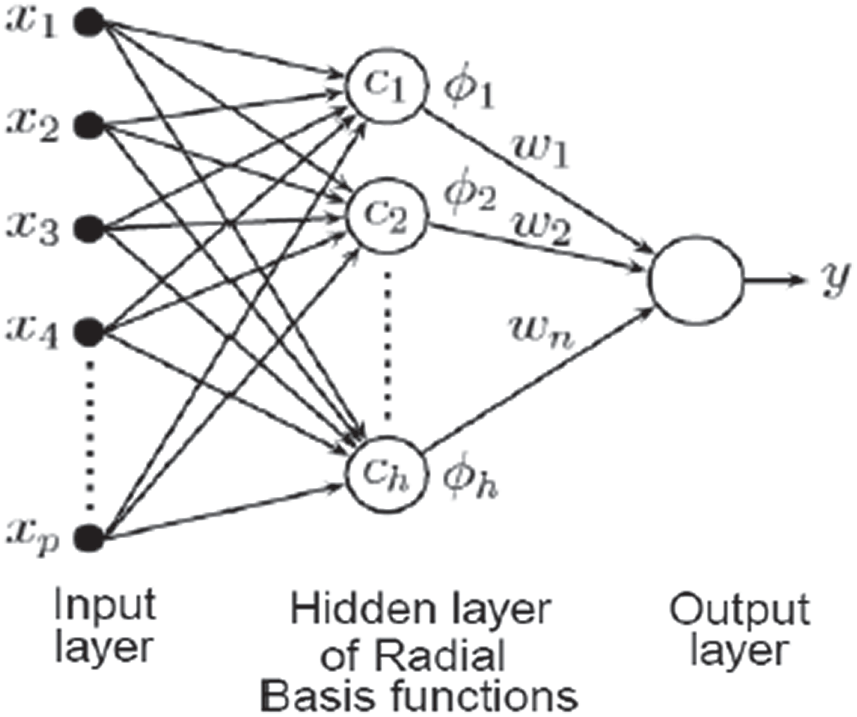
Figure 12: The architecture of radial basis function neural network [26]
Thus the output 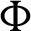 of the network for N number of neurons in the hidden layer is:
of the network for N number of neurons in the hidden layer is:
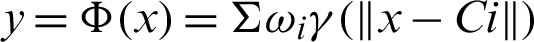
where x represents input vector (containing 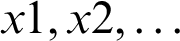 ),
), 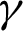 represents the RBF functions in the hidden layer, Ci is the center vector for neurons i and finally
represents the RBF functions in the hidden layer, Ci is the center vector for neurons i and finally 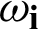 is the weight of the linear output neurons. In the basic form, all inputs neurons are connected to each hidden neuron. The norm is generally taken to be the Euclidean distance and the basis function is taken to be Gaussian. In this study, the number of hidden layer nodes is equal to the number of classes in the training set.
is the weight of the linear output neurons. In the basic form, all inputs neurons are connected to each hidden neuron. The norm is generally taken to be the Euclidean distance and the basis function is taken to be Gaussian. In this study, the number of hidden layer nodes is equal to the number of classes in the training set.
The training of the RBF network should be divided into two processes. The first is unsupervised learning, which adjusts the weight vector between the input and hidden layer. The other, named supervised learning, adjusts the weight vector between the hidden and output layer. Three parameters should be given by using Matlab before training: Input vector, target vector and the threshold value. The training algorithm is described in [27,28].
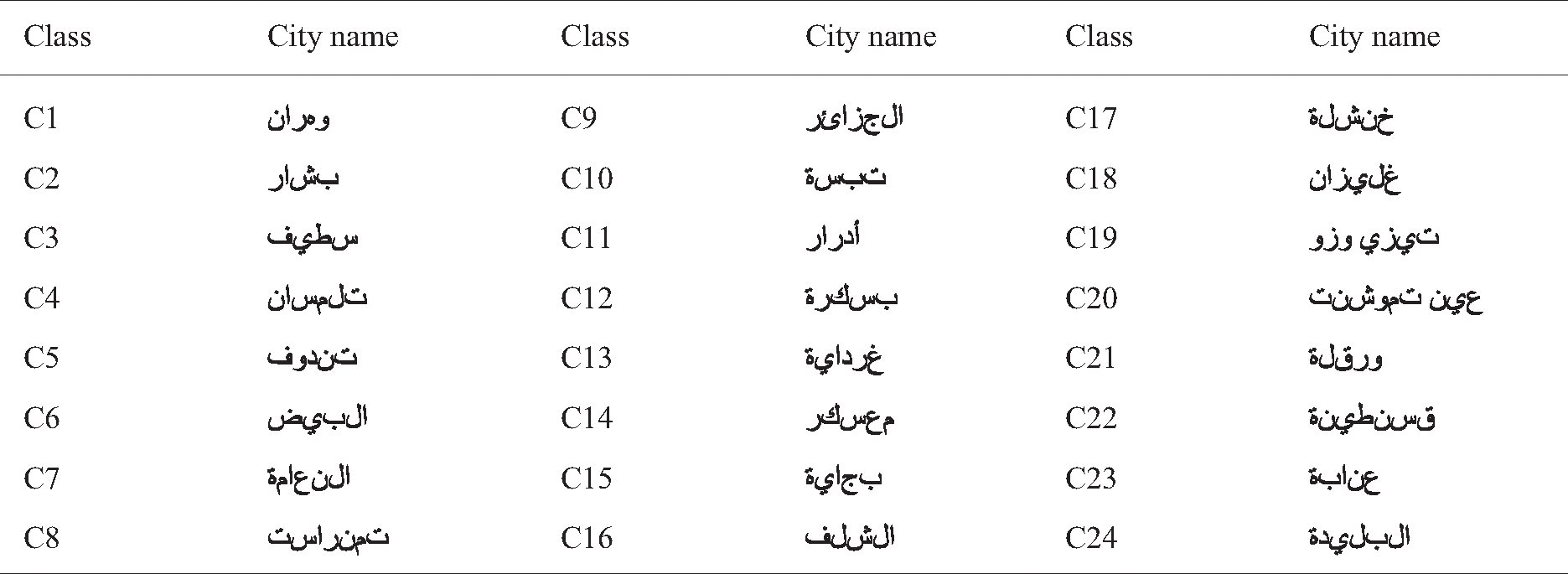
The recognition system evaluated using a development database, which contains 24 words of Algerian city names were written by fifteen writers. In this work, we used 5400 images for training and 1800 images for testing (three-quarters of data for training and quarter for testing). The network is trained with 225 samples of handwritten words where each sample has 24 words of city names. In the proposed experiment, 5400 (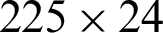 ) handwritten words have been involved. In this study, a database has been constructed for Arabic word images obtained by the scanner. As a result, the database consists of 7200 samples.
) handwritten words have been involved. In this study, a database has been constructed for Arabic word images obtained by the scanner. As a result, the database consists of 7200 samples.
Table 4: Algerian city names vocabulary
The number of neurons in the input and output layers are fixed at 28 and 24 respectively. The number of neurons in the input layer is equal to the number of attributes in the feature vector of the word image. The features were extracted from preprocessed images as explained in the Section IV. Hence, 28 variables obtained after the step of features extraction represent the elements of the feature vector. The number of neurons at the input layer is equal to 28. The discriminative power of the network depends on the selection of centers and the number of centers in a hidden layer. The K-means clustering algorithm was used to form the centers in the hidden layer. Classification accuracy with a different number of centers was verified, and the accuracy was found to be maximum when the number of centers is equal to 100. The number of neurons at the output layer is equal to the number of classes used for classification, which is equal to 24 in this case.
Table 5: Some names of Algerian cities employed within the experimental model

On one hand, we have evaluated and tested the performance of our system on a database containing 7200 words images. On the other hand, the samples are divided randomly into two sets, one for training stage (5400 samples) and the other for the testing stage (1800 samples). Approximately 95% of these words were properly assigned to the correct class. Tab. 6 shows the experimental results of recognition rate using Algerian city names from our developed database. The recognition rates achieved by the proposed system are among the best for the same task. Overall, we achieved very interesting results, knowing that only a set of 28 features was used.
Table 6: Experimental testing results

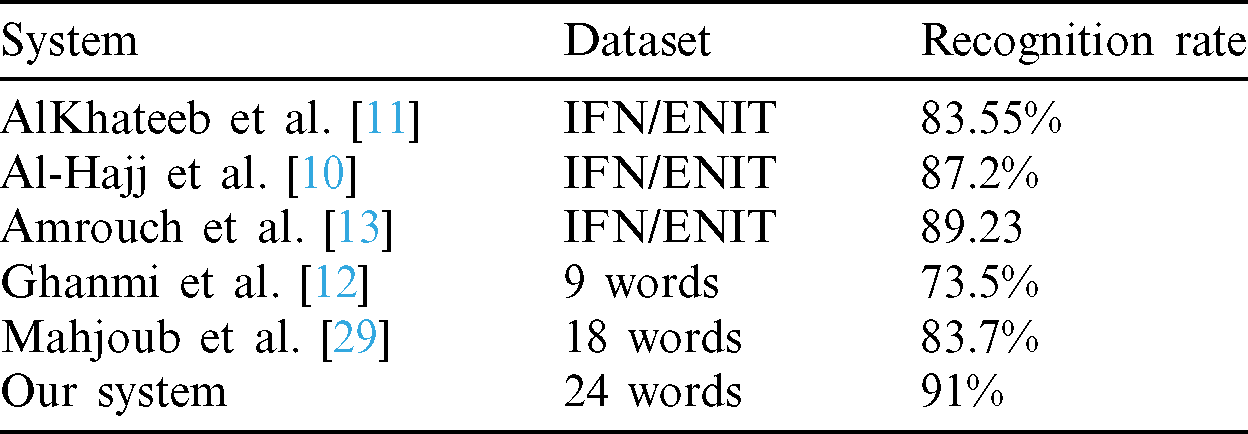
In order to investigate the potential of our system for offline handwriting recognition, Experiments are carried out on subset images from IFN/ENIT benchmark database. These images represent the names of Tunisian towns. We considered 24 classes (3600 words samples, three-quarters of data for training and quarter for testing) and the average accuracy of 91% was achieved; one can therefore conclude that the performance of handwritten Arabic recognition system is altogether improved using our system.
Table 7: Comparison of the proposed system with other methods on ifn/enit dataset
In this paper, Arabic language characteristics were stated, and the operations of off-line handwritten Arabic word recognition stages were discussed and clarified. The proposed system was developed with many important structural features and an RBF neural network. The accuracy of the developed system is over 95%. The type and size of databases have an effect on handwritten Arabic word recognition systems, so another database may be used on this system. Consequently, results were satisfactory, and the approach proved its efficiency. The proposed system consists of four stages: Image acquisition, Preprocessing, Feature Extraction and Classification. These stages cooperate to enhance the systems recognition ratio. Each stage affects the viability and effectiveness of the system.
The proposed system was tested on a subset of words from the IFN/ENIT database, and the obtained results are very promising, without using statistical features and with only 28 structural features extracted in this paper; the average recognition rate has exceeded 91%. A fascinating result for the Arabic handwriting recognition is that a subset of twenty-eight features produced effectively great outcomes. A simple classifier based on RBF neural network is presented to recognize words to verify the ability of the proposed feature extraction. The performance of Radial Basis Function Neural Networks on classification is always excellent, compared to other networks, and experiments were carried on a set of Algerian cities names. The obtained results are encouraging. The feature extraction and classification stage is the most important part of the accuracy measurement. Nevertheless, the preprocessing stage still influences the system indirectly.
Funding Statement: The author(s) received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1 A. Lawgali. (2015). “A survey on Arabic character recognition,” International Journal of Signal Processing, Image Processing and Pattern Recognition, vol. 8, no. 2, pp. 401–426. [Google Scholar]
2 L. M. Lorigo and V. Govindaraju. (2006). “Offline Arabic handwriting recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 28, no. 5, pp. 712–724. [Google Scholar]
3 M. T. Parvez and S. A. Mahmoud. (2013). “Offline Arabic handwritten text recognition,” Journal of the Association for Computing Machinery, vol. 45, no. 2, pp. 1–35. [Google Scholar]
4 H. Almuallim and S. Yamaguchi. (1987). “A method of recognition of Arabic cursive handwriting,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 9, no. 5, pp. 715–722. [Google Scholar]
5 M. S. Khorsheed and W. F. Clocksin. (1999). “Structural features of cursive Arabic script,” in Proc. of British Machine Vision Conf., Nottingham, UK, pp. 1285–1294. [Google Scholar]
6 L. Souici-meslati and M. Sellami. (2004). “A hybrid approach for Arabic literal amounts recognition,” Arabian Journal for Science and Engineering, vol. 29, pp. 177–194. [Google Scholar]
7 N. Azizi, N. Farah, M. T. Khadir and M. Sellami. (2009). “Arabic handwritten word recognition using classifiers selection and features extraction/selection,” in 17th IEEE Conf. in Intelligent Information System, Proc. of Recent Advances in Intelligent Information Systems, Warsaw: Academic Publishing House, pp. 735–742. [Google Scholar]
8 A. Kacem, N. Aouiti and A. Belaid. (2012). “Structural features extraction for handwritten Arabic personal names recognition,” in Int. Conf. on Frontiers in Handwriting Recognition, Bari, Italy: IEEE, pp. 268–273. [Google Scholar]
9 M. Parvez and S. Mahmoud. (2013). “Arabic handwriting recognition using structural and syntactic pattern attributes,” Pattern Recognition, vol. 46, no. 1, pp. 141–154. [Google Scholar]
10 R. El-Hajj, L. Likforman-Sulem and C. Mokbel. (2005). “Arabic handwriting recognition using baseline dependant features and hidden Markov modelling,” in Proc. of the Eighth Int. Conf. on Document Analysis and Recognition, Seoul, South Korea: IEEE, vol. 2, pp. 893–897. [Google Scholar]
11 J. H. Alkhateeb, J. Ren, J. Jiang and H. Al-Muhtaseb. (2011). “Offline handwritten Arabic cursive text recognition using hidden markov models and re-ranking,” Pattern Recognition Letters, vol. 32, no. 8, pp. 1081–1088. [Google Scholar]
12 N. Ghanmi, A. M. Awal and N. Kooli. (2017). “Dynamic Bayesian networks for handwritten Arabic words recognition,” in 2017 1st Int. Workshop on Arabic Script Analysis and Recognition, Nancy. [Google Scholar]
13 M. Amrouch, M. Rabi and Y. Es-Saady. (2018). “Convolutional feature learning and CNN based HMM for Arabic handwriting recognition,” in Int. Conf. on Image and Signal Processing, Cham: Springer, pp. 265–274. [Google Scholar]
14 J. H. AlKhateeb, R. Jinchang, J. Jianmin, S. S. Ipson and H. El-Abed. (2008). “Word-based handwritten Arabic scripts recognition using DCT features and neural network classifier,” in 5th Int. Multi-Conf. on Systems, Signals and Devices, Amman, Jordan: IEEE Press, pp. 1–5. [Google Scholar]
15 S. Usman. (2014). “Automatic recognition of handwritten Arabic text, a survey,” Life Science Journal, vol. 11, no. 3s, pp. 232–235. [Google Scholar]
16 Z. Q. Liu, J. Cai and R. Buse. (2003). “Handwriting Recognition: Soft Computing and Probabilistic Approaches.” Berlin: Springer, pp. 31–57. [Google Scholar]
17 A. Lawgali, A. Bouridane, M. Angelova and Z. Ghassemlooy. (2011). “Handwritten arabic character recognition: Which feature extraction method,” International Journal of Advanced Science and Technology, vol. 34, pp. 1–8. [Google Scholar]
18 A. Belaïd and C. Choisy. (2006). “Human reading based strategies for off-line Arabic word recognition,” in Proc. of the 2006 Conf. on Arabic and Chinese Handwriting Recognition, Berlin, Germany: Springer, pp. 137–149. [Google Scholar]
19 L. Souici-Meslati and M. Sellami. (2006). “Perceptual recognition of Arabic literal amounts,” Computing and Informatics Journal, vol. 25, pp. 43–59. [Google Scholar]
20 N. aouadi and A. K. Echi. (2016). “Word extraction and recognition in Arabic handwritten text,” International Journal of Computing & Information Sciences, vol. 12, no. 1, pp. 17. [Google Scholar]
21 H. M. Eraqi and S. Abdelazeem. (2011). “An on-line Arabic handwriting recognition system based on a new on-line graphemes segmentation technique,” in Proc. of the Int. Conf. on Document Analysis and Recognition, Beijing, China: IEEE, pp. 409–413. [Google Scholar]
22 M. M. Fahmy, M. Haytham and H. El-Messiry. (2001). “Automatic recognition of typewritten Arabic characters using Zernike moments as a feature extractor,” Studies in Informatics and Control Journal, vol. 10, no. 3, pp. 227–236. [Google Scholar]
23 D. Guillevic. (1995). “Unconstrained handwriting recognition applied to the processing of bank checks,” Ph.D. dissertation. Concordia University, Canada. [Google Scholar]
24 S. Chen, C. F. N. Cowan and P. M. Grant. (1991). “Orthogonal least squares learning algorithm for radial basis function networks,” IEEE Transaction on Neural Networks, vol. 2, no. 2, pp. 302–309. [Google Scholar]
25 A. S. Khalifa, R. A. Ammar, M. F. Tolba and T. Fergany. (2008). “Dynamic online allocation of independent task onto heterogeneous computing systems to maximize load balancing,” in 8th IEEE Int. Sym. on Signal Processing and Information Technology, Sarajevo, Bosnia and Herzegovina, Serbia, pp. 418–425. [Google Scholar]
26 Y. Zhang and Z. Xue. (2010). “RBF neural network application to face recognition,” in Int. Conf. on Challenges in Environmental Science and Computer Engineering, Wuhan, China: IEEE, vol. 2, pp. 381–384. [Google Scholar]
27 Z. Wang, Y. He and M. Jiang. (2006). “A comparison among three neural networks for text classification,” in Proc. of the IEEE 8th Int. Conf. on Signal Processing, Beijing, China, pp. 1883–1886. [Google Scholar]
28 F. Lampariello and M. Sciandrone. (2001). “Efficient training of RBF neural networks for pattern recognition,” IEEE Transaction on Neural Networks, vol. 12, no. 5, pp. 1235–1242. [Google Scholar]
29 M. A. Mahjoub, N. Ghanmy, K. Jayech and I. Miled. (2013). “Multiple models of Bayesian networks applied to offline recognition of Arabic handwritten city names,” International Journal of Imaging & Robotics, vol. 9, no. 1, pp. 84–105.
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |