DOI:10.32604/cmc.2020.012432
| Computers, Materials & Continua DOI:10.32604/cmc.2020.012432 | |
| Article |
A Stacking-Based Deep Neural Network Approach for Effective Network Anomaly Detection
1Department of Computer and Information Security, Sejong University, Seoul, 05006, Korea
2Data Science Group, Institute for Basic Science (IBS), Daejeon, 34126, Korea
3Department of Industrial Engineering, Ulsan National Institute of Science and Technology, Ulsan, 44919, Korea
*Corresponding Author: Sunghoon Lim. Email: sunghoonlim@unist.ac.kr
Received: 30 June 2020; Accepted: 26 August 2020
Abstract: An anomaly-based intrusion detection system (A-IDS) provides a critical aspect in a modern computing infrastructure since new types of attacks can be discovered. It prevalently utilizes several machine learning algorithms (ML) for detecting and classifying network traffic. To date, lots of algorithms have been proposed to improve the detection performance of A-IDS, either using individual or ensemble learners. In particular, ensemble learners have shown remarkable performance over individual learners in many applications, including in cybersecurity domain. However, most existing works still suffer from unsatisfactory results due to improper ensemble design. The aim of this study is to emphasize the effectiveness of stacking ensemble-based model for A-IDS, where deep learning (e.g., deep neural network [DNN]) is used as base learner model. The effectiveness of the proposed model and base DNN model are benchmarked empirically in terms of several performance metrics, i.e., Matthew’s correlation coefficient, accuracy, and false alarm rate. The results indicate that the proposed model is superior to the base DNN model as well as other existing ML algorithms found in the literature.
Keywords: Anomaly detection; deep neural network; intrusion detection system; stacking ensemble
Intrusion detection system (IDS) has been an active research in the cybersecurity domain recently. It contributes a critical role to a modern computing infrastructure in repealing any malicious activities in the network. In addition, as a protection mechanism, an IDS is accountable for taking preventive action to overcome any malignant acts in the computer network. By examining network access logs, audit trails, and other security-relevant information within an organization, an IDS detects and blocks attack without human intervention [1].
An IDS is typically split into two main techniques, i.e., anomaly and misuse. The differences lie in the number of attack classes to be predicted. An anomaly-based IDS (A-IDS) attempts to solve a binary classification problem, where the classifier is trained so that it is able to distinguish anomaly traffic from normal traffic. Since the trained model is only capable in handling two classes, a new type of attack can be discovered by A-IDS. Apart from this merit, this technique always suffers from high false alarm rate (FAR), thus bringing the network into vulnerable state. In contrast to A-IDS, a misuse-based IDS (M-IDS) attempts to solve multiclass classification problem, where a future attack could be detected by comparing it with some known attacks signatures stored in knowledge-based system. It results shows a lower FAR, however, unknown attacks cannot be easily detected [2].
Owing to the fact that A-IDS are powerful to find new types of attacks, it is more adopted in IDS research. Even though it offers a small improvement in the performance, such A-IDS would be a significant asset for an organization. For instance, it could help an organization to get rid of successful attack, e.g., service inaccessibility and performance breakdown, that might result into huge financial loss. However, maintaining a lower FAR while increasing the detection accuracy is also a challenging task. This trade-off is prevalently solved using the combination of feature selection and classification algorithms. Feature selection or feature importance methods are crucial as some irrelevant features might contribute to degrading classifier’s performance.
To develop an A-IDS that is able to learn anomaly or normal pattern within the network, a classification algorithm is trained using publicly available network traffic log datasets such as NSL-KDD [3], UNSW-NB-15 [4], and more recently, CICIDS-2017 [5]. These datasets are commonly used in the current literature for benchmarking the proposed A-IDS model. To improve an A-IDS, a considerable number of classification algorithms have been carried out, ranging from shallow machine learning models to deep neural network (DNN) models [6,7]. Besides, some ensemble learners are also taken into account due to their performance advantages over individual classification algorithms [8,9].
In an ensemble learner, multiple classification algorithms are trained to predict the same problem. Over the last few decades, ensemble learners have shown remarkable performance in various applications, including cybersecurity field. However, there still exist several research challenges while utilizing ensemble learners. For instance, the selection of the mixture technique for combining the base learner’s predictions and the multifariousness of classifiers in the wild. Thus, this study focuses on the development of an A-IDS technique using stacking-based deep neural network (DNN). Stacking is chosen due to its flexibility in combining multiple classifiers in heterogeneous way. The contributions of this paper lie in two different angles: (i) An ensemble approach of DNN is proposed, instead of just using DNN as an individual classifier; and (ii) A two-step significance test is employed to prove the effectiveness of the proposed model over individual model.
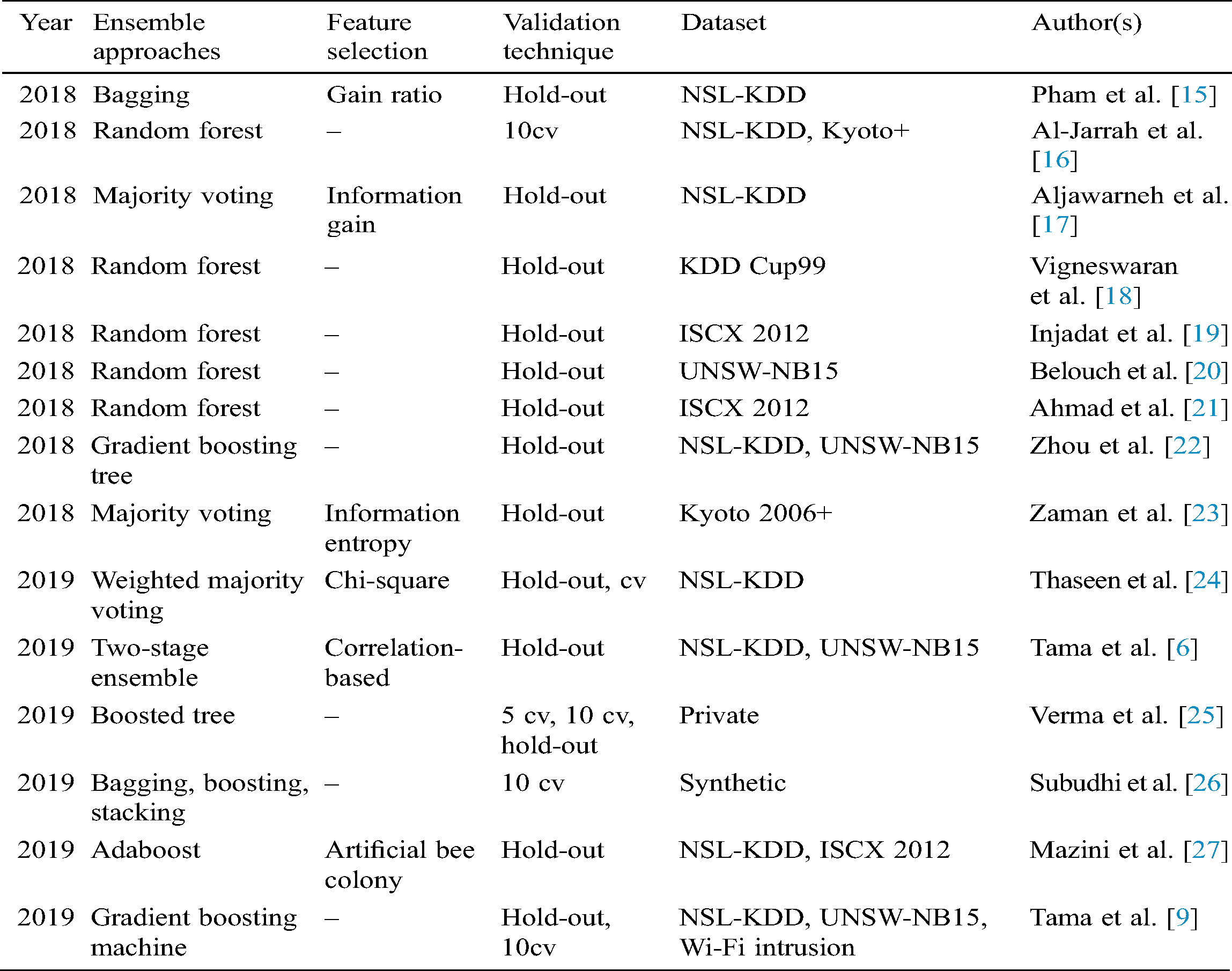
In this section, a brief review of existing A-IDS techniques is discussed. Since A-IDS is an active research field, we only provide the proposed techniques published in the last two years, e.g., 2018 and 2019 and studies that employed at least one classifier ensemble in their experiment. This is also to show the position of this paper in comparison with other state- of-the-art techniques. We summarize and classify the trend of A-IDS research in Tab. 1. Interested readers might refer to recently survey papers [10–14].
Table 1: Classification of A-IDS w.r.t detection approaches and other important categories
This section describes several publicly available datasets used in the experiment. The remaining part of this section details the proposed A-IDS model.
The following datasets are very common in IDS community. NSL-KDD and UNSW-NB15 are considered for network packets-based analysis, while CICIDS 2017 is used for Web traffic-based analysis. The datasets are described chronologically as follows.
NSL-KDD [3]:
It is an improved version of long-standing intrusion dataset, called KDD Cup 99. Unlike its predecessor, NSL-KDD possesses no redundant samples, providing more realistic and reliable dataset while applying machine learning algorithm to develop an IDS model. A number of training samples (e.g., 125,973 instances) are used for creating the classification model, where the number of samples representing anomaly and normal class is 67,343 and 58,630 samples, respectively. In addition, for the sake of the evaluation procedure, an independent testing set (e.g., KDDTest+) is taking into consideration. The testing set consists of 22,544 instances.
UNSW-NB15 [4]:
It was built by generating real-life normal network packets as well as synthetic attacks using IXIA PerfectStorm tool. A training set consisting of 37,000 normal and 45,332 attack samples is used in our experiment. In addition, an independent test set, called UNSW-NB15 test (e.g., 175,341 samples) is also used for evaluating the proposed classification model. The number of input feature is 42 with 1 class label attribute.
CICIDS 2017 [5]:
B-profile system was used to generate realistic benign background traffic. Moreover, several network protocols such as HTTP, HTTPS, FTP, SSH, etc. were also taken into consideration, providing a complete network traffic dataset with a diverse attack profiles. There are 78 input features, while the number of benign and malicious samples is 168,186 and 2,180 samples, respectively. Since an independent dataset is not provided, we simply apply a train-test split with a ratio of 80% and 20% for training and testing set, respectively.
The idea of our proposed model is briefly presented in the following subsections:
Since the advent of artificial neural networks (ANNs) that mimic human thought, deep neural networks (DNNs) (e.g., deep learning) is one of the most effective tools in comparison with other machine learning algorithms in the wild. DNN is built based on the initial ANN architecture that has a multilayer structure, activation and optimization functions. It is highly recognized due to the advancement of computing hardware. Fig. 1 denotes a base DNN model. The base DNN architecture consists of one input layer, three hidden layer, and one output layer. All features are fed into input layer, in which some nonlinear operations are then performed to provide the final class prediction in the output layer.

Figure 1: Architecture of a base DNN model
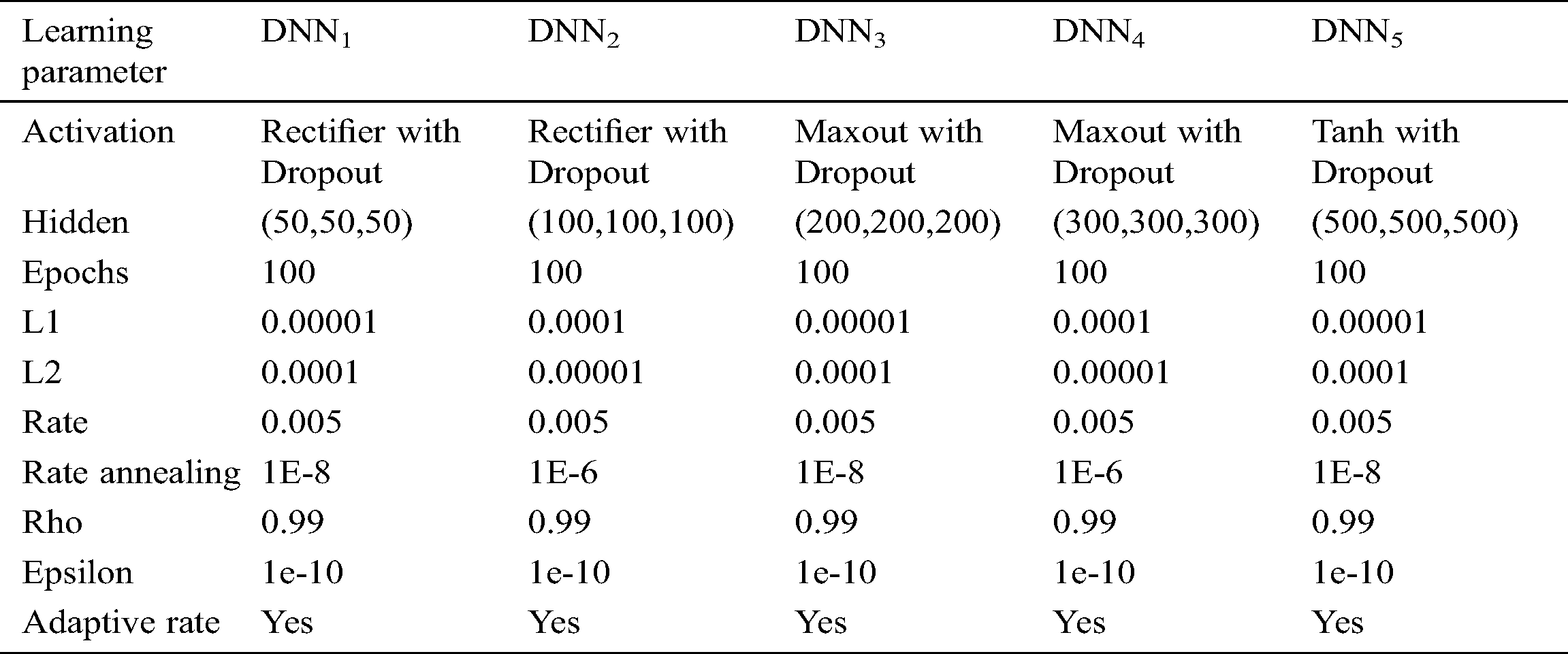
Stacking was firstly introduced by the researcher in [28]. Despite the fact that it was originally invented by Wolpert, the present-day stacking that uses internal k-fold cross-validation was Breiman’s contribution. Our proposed stacking-based deep learning model is detailed in Algorithm 1. In this study, five different DNN base models are taken into account. The goal of using such different models is to maximize the diversity of the ensemble. This is quite essential since without diversity, an ensemble is deemed to be unsuccessful as it is [29]. Diversity can be achieved in several ways: By using different base learners for constructing the ensemble (e.g., heterogeneous) and by using different training set. This paper is emphasized on the first strategy, specifically, different learning parameters of each base DNN are used. Moreover, a gradient boosting machine learning (GBM) [30] is considered as meta-learning classifier.
Algorithm 1: Proposed stacking-based deep neural network for A-IDS

In this section, the experimental results of staking-based deep neural network for an A-IDS is described. First of all, learning parameters of each base DNN model are specified in Tab. 2. As mentioned previously, by specifying different learning parameters, our objective is to maximize the diversity and we expect that an improved final ensemble prediction could be obtained. To evaluate the proposed model and baseline models, a Matthews correlation coefficient (MCC) is considered. The metric is found to be meaningful to measure the performance of classifier applied to imbalance datasets. Furthermore, two other metrics, i.e., accuracy and false alarm rate (FPR) that are commonly used in IDS research are also taken into consideration. Those three performance measures can be obtained as follows Fig. 2:

Figure 2: Proposed stacking-based DNN for anomaly-based IDS
Table 2: Learning parameters for each DNN base model
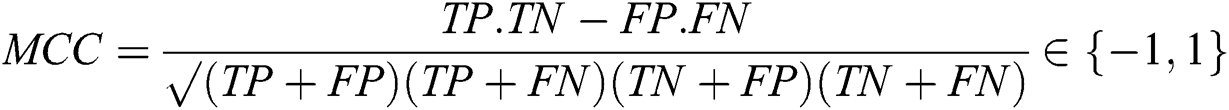
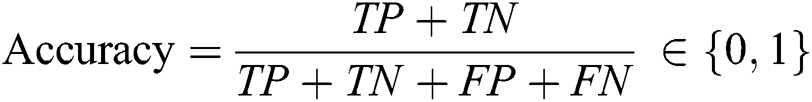
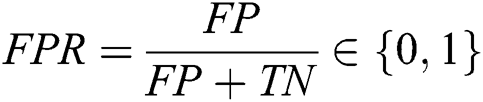
A deep learning framework, i.e., H2O was utilized for running classification task. All codes were implemented in R on a machine with Linux operating system, 32 GB memory, and Intel Xeon processor. First of all, the performance of all classifiers with respect to MCC metric are presented in Fig. 3. It is clear that for all IDS datasets, the proposed stacking-based DNN outperforms all baseline models, except for UNSW-NB15. Using NSL-KDD, the proposed model (MCC = 0.7994) has achieved better than DNN1 (MCC = 0.7189), DNN2 (MCC = 0.7737), DNN3 (MCC = 0.6893), DNN4 (MCC = 0.6724), and DNN5 (MCC = 0.6675). Similarly, the proposed model has a significant improvement over the baseline models when it is applied to CICIDS 2017. Tab. 3 compares relative performance between the proposed model and baseline models.
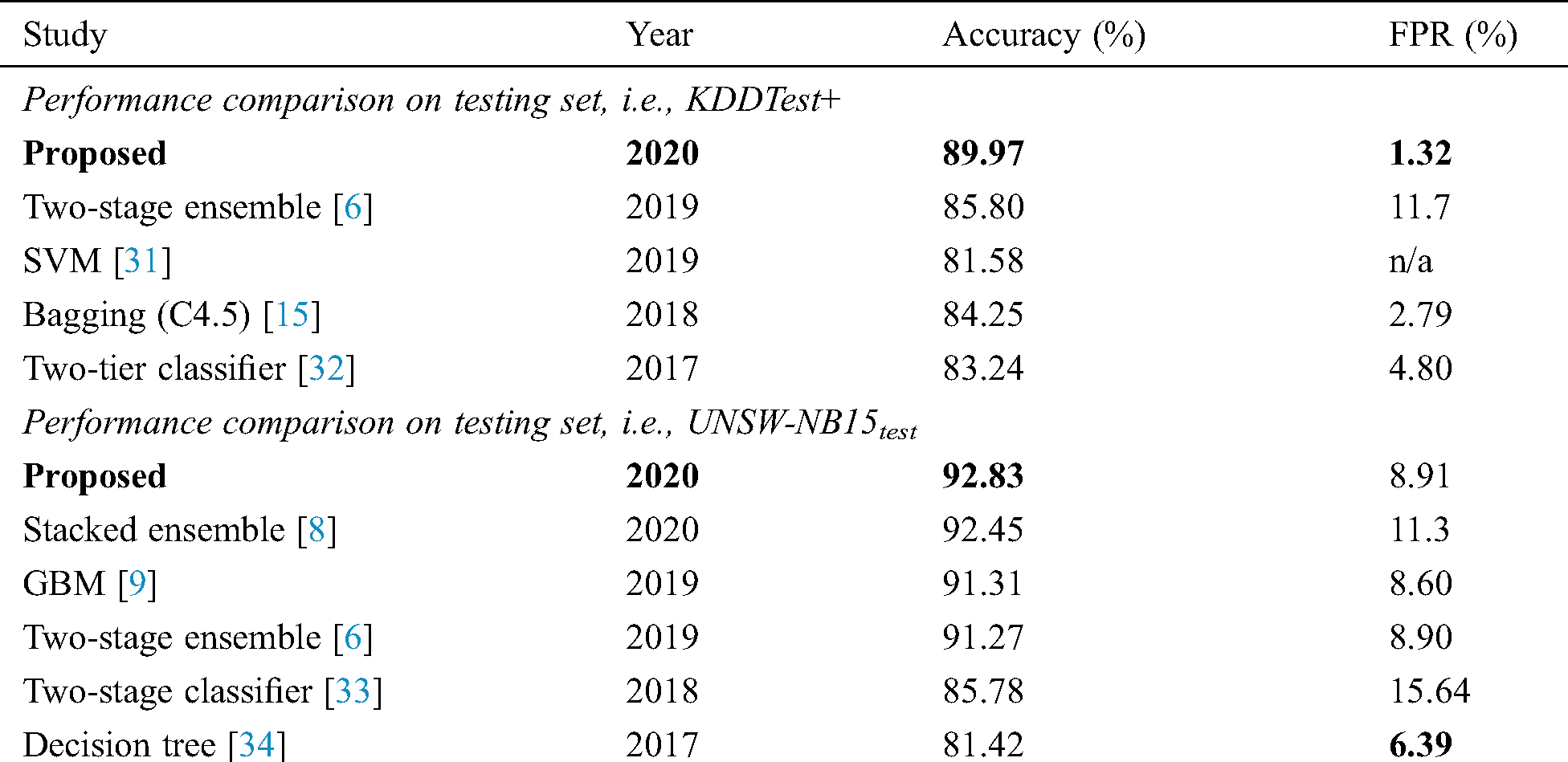
For the sake of completeness, an empirical comparison using statistical significance tests is also provided in this section. For this purpose, a two-fold Quade-Quade post hoc test [36] is employed. Quade test is deemed to be more powerful than other tests when comparing five or less different classifiers. The two or more classifiers are significantly different if p-value is less than a threshold (0.5 in our case). First of all, an omnibus test using Quade test yields p-value = 0.067, with degree of freedom, d f = 5 is conducted. Therefore, it can be inferred that at least one classifier has performed differently than others. Since the test demonstrates its contribution, Quade post hoc test is carried out. Tab. 4 exhibits the p-values of all pair-wise comparisons using Quade post hoc test. It conveys an information that the proposed model is statistically significant than DNN3, DNN4, and DNN5. Finally, in order to ensure the comprehensiveness of this study, it is compulsory to benchmark the proposed model and other existing approaches. Tab. 5 depicts such a fairer comparison with the state-of-the-arts in terms of accuracy and FPR. It proves that the proposed model is obviously superior to every other approach published in some major outlets.

Figure 3: Performance of stacking-based DNN and baseline models w.r.t MCC score
Table 3: Relative performance differences (%) between the proposed model and the base- lines. For example, the proposed model performance on NSL-KDD is 11.20% higher than DNN1
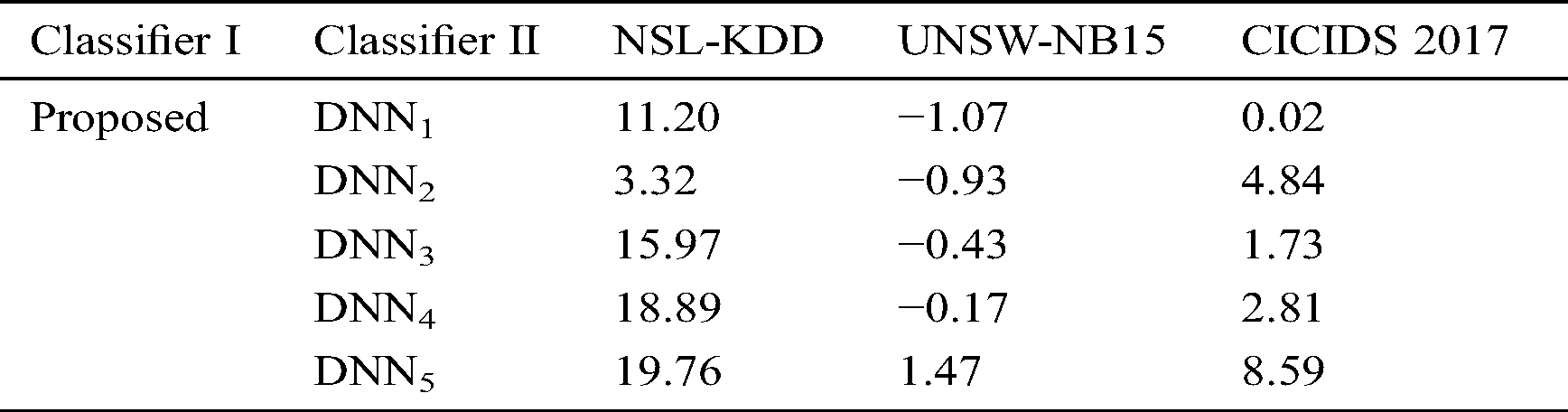
Table 4: Results of all pair-wise comparisons using Quade post hoc test (bold indicates significance)
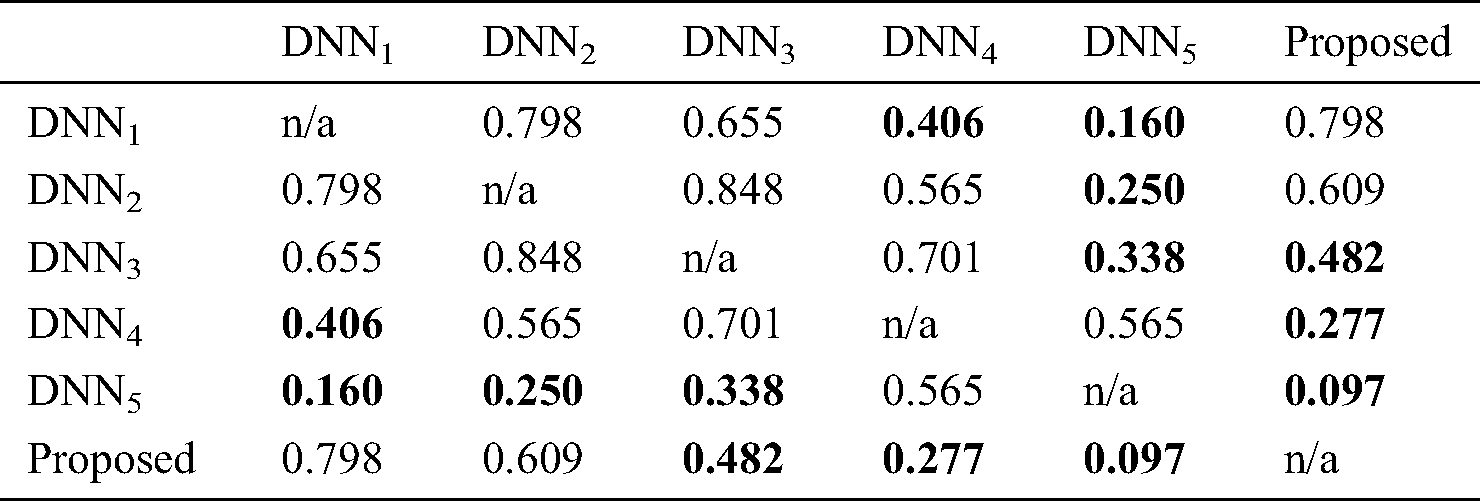
Table 5: Performance comparison between the proposed model and some state-of-the-art techniques (bold indicates best value)

Anomaly detection in computer network has always been an active research in cybersecurity domain. Many studies have been implemented to address network traffic logs as a binary classification problem. In the current literature, there is no available stacking-based deep neural network approach applied to anomaly-based IDS thus far. In this study, a stacking-based deep neural network is designed for anomaly detection, coping with a two-class detection problem, i.e., normal and malicious. To evaluate the effectiveness of the proposed model, the experiments were performed on three different intrusion datasets such as NSL-KDD, UNSW- NB15, and CICIDS 2017. Experimental results demonstrate that the proposed model is a first-rate method for anomaly detection with a detection accuracy of 89.97%, 92/83%, and 99.65% when dealing with specified training sets of KDDTest+, UNSW-NB15test, and CICIDS 2017, respectively.
Funding Statement: This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. 2019R1F1A1059346). This work was supported by the 2020 Research Fund (Project No. 1.180090.01) of UNIST (Ulsan National Institute of Science and Technology).
Conflict of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. R. Gupta, S. Tanwar, S. Tyagi and N. Kumar. (2020). “Machine learning models for secure data analytics: A taxonomy and threat model,” Computer Communications, vol. 153, pp. 406–440. [Google Scholar]
2. R. Primartha and B. A. Tama. (2017). “Anomaly detection using random forest: A performance revisited,” in Proc. IEEE ICoDSE, Palembang, Indonesia, pp. 1–6. [Google Scholar]
3. M. Tavallaee, E. Bagheri, W. Lu and A. A. Ghorbani. (2009). “A detailed analysis of the KDD CUP 99 data set,” in Proc. IEEE CISDA, Ottawa, Canada, pp. 1–6. [Google Scholar]
4. N. Moustafa and J. Slay. (2016). “The evaluation of network anomaly detection systems: Statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set,” Information Security Journal: A Global Perspective, vol. 25, no. 1-3, pp. 18–31. [Google Scholar]
5. I. Sharafaldin, A. H. Lashkari and A. A. Ghorbani. (2018). “Toward generating a new intrusion detection dataset and intrusion traffic characterization,” in Proc. ICISSP, Funchal, Portugal, pp. 108–116. [Google Scholar]
6. B. A. Tama, M. Comuzzi and K. H. Rhee. (2019). “TSE-IDS: A two-stage classifier ensemble for intelligent anomaly-based intrusion detection system,” IEEE Access, vol. 7, pp. 94497–94507. [Google Scholar]
7. C. Yin, Y. Zhu, J. Fei and X. He. (2017). “A deep learning approach for intrusion detection using recurrent neural networks,” IEEE Access, vol. 5, pp. 21954–21961. [Google Scholar]
8. B. A. Tama, L. Nkenyereye, S. R. Islam and K. S. Kwak. (2020). “An enhanced anomaly detection in web traffic using a stack of classifier ensemble,” IEEE Access, vol. 8, pp. 24120–24134. [Google Scholar]
9. B. A. Tama and K. H. Rhee. (2019). “An in-depth experimental study of anomaly detection using gradient boosted machine,” Neural Computing and Applications, vol. 31, no. 4, pp. 955–965. [Google Scholar]
10. A. Khraisat, I. Gondal, P. Vamplew and J. Kamruzzaman. (2019). “Survey of intrusion detection systems: Techniques, datasets and challenges,” Cybersecurity, vol. 2, no. 1, pp. 384. [Google Scholar]
11. R. Chapaneri and S. Shah. (2019). “A comprehensive survey of machine learning-based network intrusion detection,” in Smart Intelligent Computing and Applications, Smart Innovation, Systems and Technologies, Singapore: Springer, pp. 345–356.
12. K. A. P. da Costa, J. P. Papa, C. O. Lisboa, R. Munoz and V. H. C. de Albuquerque. (2019). “Internet of things: A survey on machine learning-based intrusion detection approaches,” Computer Networks, vol. 151, pp. 147–157.
13. P. Mishra, V. Varadharajan, U. Tupakula and E. S. Pilli. (2019). “A detailed investigation and analysis of using machine learning techniques for intrusion detection,” IEEE Communications Surveys & Tutorials, vol. 21, no. 1, pp. 686–728.
14. N. Moustafa, J. Hu and J. Slay. (2019). “A holistic review of network anomaly detection systems: A comprehensive survey,” Journal of Network and Computer Applications, vol. 128, pp. 33–55. [Google Scholar]
15. N. T. Pham, E. Foo, S. Suriadi, H. Jeffrey and H. F. M. Lahza. (2018). “Improving performance of intrusion detection system using ensemble methods and feature selection,” in Proc. ACSW, Brisbane, Australia, pp. 1–6. [Google Scholar]
16. O. Y. Al-Jarrah, Y. Al-Hammdi, P. D. Yoo, S. Muhaidat and M. Al-Qutayri. (2018). “Semi-supervised multi-layered clustering model for intrusion detection,” Digital Communications and Networks, vol. 4, no. 4, pp. 277–286. [Google Scholar]
17. S. Aljawarneh, M. Aldwairi and M. B. Yassein. (2018). “Anomaly-based intrusion detection system through feature selection analysis and building hybrid efficient model,” Journal of Computational Science, vol. 25, pp. 152–160. [Google Scholar]
18. K. R. Vigneswaran, R. Vinayakumar, K. Soman and P. Poornachandran. (2018). “Evaluating shallow and deep neural networks for network intrusion detection systems in cyber security,” in Proc. IEEE ICCCNT, Bengaluru, India, pp. 1–6. [Google Scholar]
19. M. Injadat, F. Salo, A. B. Nassif, A. Essex and A. Shami. (2018). “Bayesian optimization with machine learning algorithms towards anomaly detection,” in Proc. IEEE GLOBECOM, Abu Dhabi, UAE, pp. 1–6. [Google Scholar]
20. M. Belouch, S. El Hadaj and M. Idhammad. (2018). “Performance evaluation of intrusion detection based on machine learning using Apache Spark,” Procedia Computer Science, vol. 127, pp. 1–6. [Google Scholar]
21. I. Ahmad, M. Basheri, M. J. Iqbal and A. Rahim. (2018). “Performance comparison of sup- port vector machine, random forest, and extreme learning machine for intrusion detection,” IEEE Access, vol. 6, pp. 33789–33795. [Google Scholar]
22. Y. Zhou, M. Han, L. Liu, J. S. He and Y. Wang. (2018). “Deep learning approach for cyber- attack detection,” in IEEE INFOCOM, Honolulu, USA, pp. 262–267. [Google Scholar]
23. M. Zaman and C.H. Lung. (2018). “Evaluation of machine learning techniques for network intrusion detection,” in Proc. IEEE IFIP, Taipei, Taiwan, pp. 1–5. [Google Scholar]
24. I. S. Thaseen, C. A. Kumar and A. Ahmad. (2019). “Integrated intrusion detection model using chisquare feature selection and ensemble of classifiers,” Arabian Journal for Science and Engineering, vol. 44, no. 4, pp. 3357–3368. [Google Scholar]
25. A. Verma and V. Ranga. (2019). “Elnids: Ensemble learning based network intrusion detection system for rpl based internet of things,” in Proc. IEEE IoT-SIU, Ghaziabad, India, pp. 1–6. [Google Scholar]
26. S. Subudhi and S. Panigrahi. (2019). “Application of optics and ensemble learning for database intrusion detection,” Journal of King Saud University—Computer and Information Sciences, pp. 1–10. [Google Scholar]
27. M. Mazini, B. Shirazi and I. Mahdavi. (2019). “Anomaly network-based intrusion detection system using a reliable hybrid artificial bee colony and adaboost algorithms,” Journal of King Saud University—Computer and Information Sciences, vol. 31, no. 4, pp. 541–553. [Google Scholar]
28. L. Breiman. (1996). “Stacked regressions,” Machine Learning, vol. 24, no. 1, pp. 49–64. [Google Scholar]
29. L. I. Kuncheva and C. J. Whitaker. (2003). “Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy,” Machine Learning, vol. 51, no. 2, pp. 181–207. [Google Scholar]
30. J. H. Friedman. (2001). “Greedy function approximation: A gradient boosting machine,” Annals of Statistics, vol. 29, no. 5, pp. 1189–1232. [Google Scholar]
31. Q. M. Alzubi, M. Anbar, Z. N. M. Alqattan, M. A. Al-Betar and R. Abdullah. (2020). “Intrusion detection system based on a modified binary grey wolf optimization,” Neural Computing and Applications, vol. 32, no. 10, pp. 6125–6137. [Google Scholar]
32. H. H. Pajouh, G. Dastghaibyfard and S. Hashemi. (2017). “Two-tier network anomaly detection model: A machine learning approach,” Journal of Intelligent Information Systems, vol. 48, no. 1, pp. 61–74. [Google Scholar]
33. W. Zong, Y. W. Chow and W. Susilo. (2018). “A two-stage classifier approach for network intrusion detection,” in Proc. ISPEC, Tokyo, Japan, pp. 329–340. [Google Scholar]
34. C. Khammassi and S. Krichen. (2017). “A GA-LR wrapper approach for feature selection in network intrusion detection,” Computers & Security, vol. 70, pp. 255–277. [Google Scholar]
35. Y. Zhou, G. Cheng, S. Jiang and M. Dai. (2020). “Building an efficient intrusion detection system based on feature selection and ensemble classifier,” Computer Networks, vol. 174, pp. 107247. [Google Scholar]
36. R. Vinayakumar, M. Alazab, K. P. Soman, P. Poornachandran, A. Al-Nemrat et al. (2019). , “Deep learning approach for intelligent intrusion detection system,” IEEE Access, vol. 7, pp. 41525–41550. [Google Scholar]
37. T. A. Tang, D. McLernon, L. Mhamdi, S. A. R. Zaidi and M. Ghogho. (2019). “Intrusion detection in SDN-based networks: Deep recurrent neural network approach,” in Deep Learning Applications for Cyber Security, Cham, Switzerland: Springer, pp. 175–195. [Google Scholar]
38. M. Alrowaily, F. Alenezi and Z. Lu. (2019). “Effectiveness of machine learning based intrusion detection systems,” in Proc. SpaCCS, Georgia, USA, pp. 277–288. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |