
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Cartographie Automatique et Comptage des Arbres Oliviers A Partir de L’Imagerie de Drone par Un Reseau de Neurones Covolutionnel
Automatic Mapping and Counting of Olive Trees from Drone Imaging by a Convolutional Neural Network
1 Team of Remote Sensing and GIS Applied to Geosciences and Environment, Faculty of Sciences and Techniques, Sultan Moulay Slimane University, P.O. Box 523, Beni Mellal, 23000, Morocco
2 Laboratory of Industrial and Surface Engineering, Bioprocesses and Biointerfaces Team, Faculty of Science and Techniques, Sultan Moulay Slimane University, P.O. Box 523, Beni Mellal, 23000, Morocco
* Corresponding Author: Oumaima Ameslek. Email:
(This article belongs to the Special Issue: Applications of Artificial Intelligence in Geomatics for Environmental Monitoring)
Revue Internationale de Géomatique 2024, 33, 321-340. https://doi.org/10.32604/rig.2024.054838
Received 09 June 2024; Accepted 30 July 2024; Issue published 03 September 2024
 View Full Text
View Full Text Download PDF
Download PDFRÉSUMÉ
L’agriculture de précision (AP) est une stratégie de gestion agricole fondée sur l’observation, la mesure et la réponse à la variabilité des cultures inter/intra-champ. Il comprend des avancées en matière de collecte, d’analyse et de gestion des données, ainsi que des développements technologiques en matière de stockage et de récupération de données, de positionnement précis, de surveillance des rendements et de télédétection. Cette dernière offre une résolution spatiale, spectrale et temporelle sans précédent, mais peut également fournir des informations détaillées sur la hauteur de la végétation et diverses observations. Aujourd’hui, le succès des nouvelles technologies agricoles signifie que de nombreuses tâches agricoles sont devenues automatisées et que les scientifiques ont mené davantage d’études et de recherches basées sur des algorithmes intelligents qui apprennent automatiquement les règles de décision à partir des données. L’utilisation de l’apprentissage profond (DL) et en particulier le développement et l’application de certains de ses algorithmes appelés réseaux de neurones convolutifs (CNN) sont considérés comme un succès particulier. Dans le présent travail, nous avons appliqué et testé les performances d’un réseau de neurones convolutif pour détecter et cartographier automatiquement les oliviers à partir d’une imagerie de drone Phantom4. Le flux de travail impliquait l’acquisition d’images et la génération d’ortho-mosaïque avec le logiciel Pix4D, ainsi que l’utilisation d’un système d’information géographique. Les résultats obtenus avec une base d’apprentissage composée de 4500 images de 24 * 24 pixels sont satisfaisants à une précision de 95%, un Recall de 99% et un F-score de 97%.Abstract
Precision agriculture (PA) is an agricultural management strategy based on observation, measurement and response to the variability of inter/intra-champ cultures. It includes advances in terms of data collection, analysis and management, as well as technological developments in terms of data storage and recovery, precise positioning, yield monitoring and remote sensing. The latter offers an unprecedented spatial, spectral and temporal resolution, but can also provide detailed information on the height of the vegetation and various observations. Today, the success of new agricultural technologies means that many agricultural tasks have become automated and that scientists have conducted more studies and research based on smart algorithms that automatically learn the decision rules from data. The use of Deep Learning (DL) and in particular the development and application of some of its algorithms called Convolutional Neural Networks (CNNs) are considered to be a particular success. In this work, we have applied and tested the performance of a network of convolutional neural network to automatically detect and map olive trees from Phantom4 drone imagery. The workflow involved the acquisition of images and the generation of ortho-mosaic with Pix4D software, as well as the use of a geographic information system. The results obtained with a training dataset of 4500 images of 24 * 24 pixels are very satisfying: 95% Precision, a 99% Recall and an F-score of 97%.MOTS CLÉS
Keywords
Aujourd’hui les drones ou UAVs (Unmanned Aerial Vehicules) sont de plus en plus utilisés comme un outil de télédétection dans plusieurs domaines, notamment dans l’agriculture [1]. Leur résolution spatiale à l’échelle centimétrique dans le contexte de la végétation réside dans sa capacité à résoudre l’unité écologique fondamentale : les plantes individuelles [2]. Pour l’agriculture de précision, l’utilisation des drones est principalement destinée à la détection des mauvaises herbes [3], à l’estimation du rendement, à la détection des ravageurs ou des maladies, à la surveillance et à la cartographie des parcelles [4,5], Outre la détection et le comptage des arbres.
Dans ce contexte, différentes méthodologies ont été appliquées pour l’identification et la délimitation des arbres individuels, allant du traitement d’image classique dans les premières années aux méthodes les plus récentes basées sur l’apprentissage profond ces dernières années. Cependant, lorsqu’il s’agit de montrer la relation entre certains algorithmes et certaines données spatiales, cette hypothèse reste encore floue car chaque étude a ses propres considérations.
L’apprentissage profond fait référence à un sous-domaine de l’apprentissage automatique et de l’IA. Il comprend divers algorithmes capables d’apprendre automatiquement des caractéristiques à partir d’un grand nombre d’échantillons d’apprentissage et de bien fonctionner avec de grandes quantités de données [6]. Les réseaux de neurones sont des algorithmes DL courants, leur introduction aux géosciences et à la télédétection est révolutionnaire vu leur capacité à résoudre efficacement les problèmes d’analyse de télédétection notamment la classification et la segmentation [7].
Le réseau neuronal convolutif (CNN) peut être considéré comme l’un des algorithmes d’apprentissage profond les plus appliqués, conçu principalement pour la classification d’images [8–10]. Il a été proposé pour la première fois par Kunihiko Fukushima en 1988 [11], puis après la mise en œuvre de la plateforme Google Tensor Flow et la sortie d’AlexNet en 2012, il est devenu plus populaire [12]. Il s’agit d’un algorithme supervisé fonctionnant avec des données étiquetées. Un CNN se compose d’une couche d’entrée, de couches d’unités cachées et d’une couche de sortie. Les unités cachées sont similaires aux neurones humains, dont chacune a une connexion avec chaque neurone de la couche précédente. La couche d’entrée est l’image donnée en entrée à valeurs multiples, qui subit un certain nombre de couches cachées pour arriver à la sortie finale.
Le processus du CNN peut être divisé en deux étapes principales : l’extraction des caractéristiques et la classification [12]. Les couches convolutionnelles et de pooling sont incluses dans la section d'extraction des caractéristiques ou d'apprentissage de fonctionnalités, tandis que la section de classification se compose d’une couche entièrement connectée (Fig. 1). Plus la base de données d’apprentissage est grande, meilleures sont les performances du CNN [10].
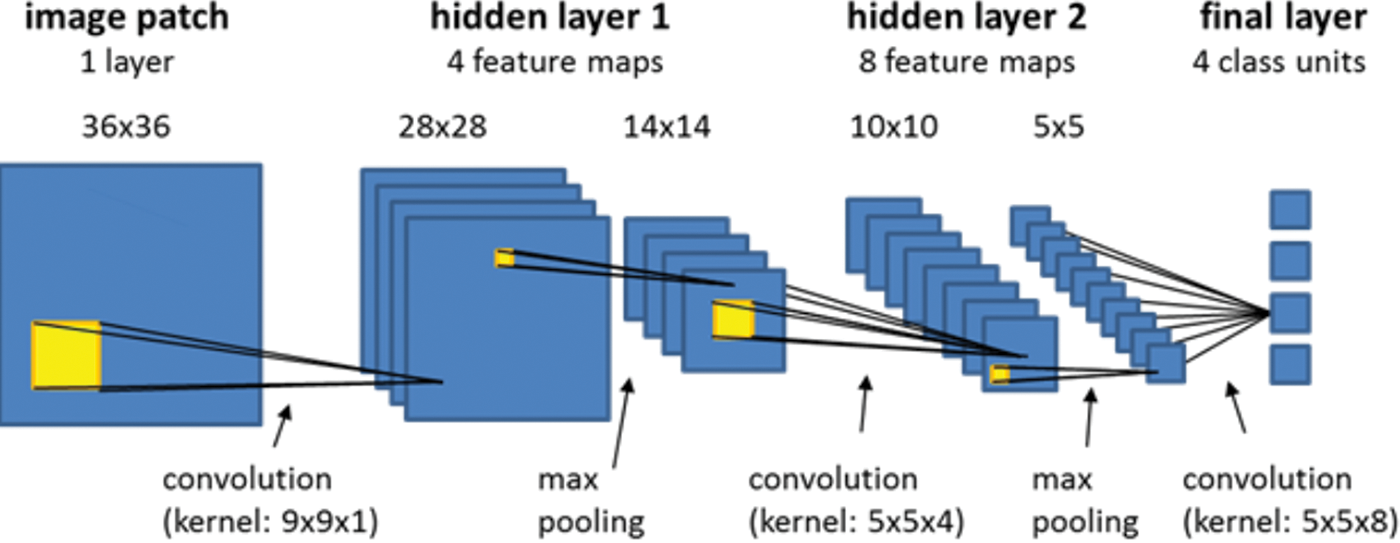
Figure 1: Schéma d’un réseau neuronal à convolution à deux couches cachées (hidden layers)
La combinaison de l’imagerie de drone avec les réseaux de neurones convolutifs (CNN) est une approche prometteuse. Cependant, il manque des modèles et des méthodes permettant de les intégrer dans les flux de travail géospatiaux [13]. Les techniques d’apprentissage en profondeur combinées avec les images de drone pourraient augmenter la précision globale du processus de classification. Par conséquent, notre étude évalue les performances du CNN pour l’identification et la détection des centres des arbres oliviers à partir d’une image de drone RGB.
Le CNN nécessite une grande quantité de données afin d’apprendre. Les bases de données utilisées peuvent être créé manuellement ou automatiquement. Il est vrai que procéder manuellement reste une tâche difficile et fastidieuse mais la qualité des bases de données obtenues justifie ce choix. Pour cette étude, nous allons faire apprendre le model de CNN développé avec des échantillons créés manuellement, par la suite nous évaluons l’exactitude des résultats lorsqu’ils sont appliqués à la détection et au comptage automatiques d’arbres oliviers individuellement à partir d’images de drones RGB.
La zone de recherche est située au nord-est du Maroc (42,904549°S, 147,328536°E) dans la région Orientale, mené d’un climat Méditerranéen sur les côtes, semi-aride à l’intérieur, et aride sur les zones australes de la région.
La zone de recherche se situe plus exactement dans la province de Taourirt, à environ 100 km à l’ouest de la ville d’Oujda (postcode : 60000) capitale de la région. C’est un champ d’arbres oliviers d’une superficie de 13.4 ha et comptant près de 3800 oliviers (Figs. 2 and 3).
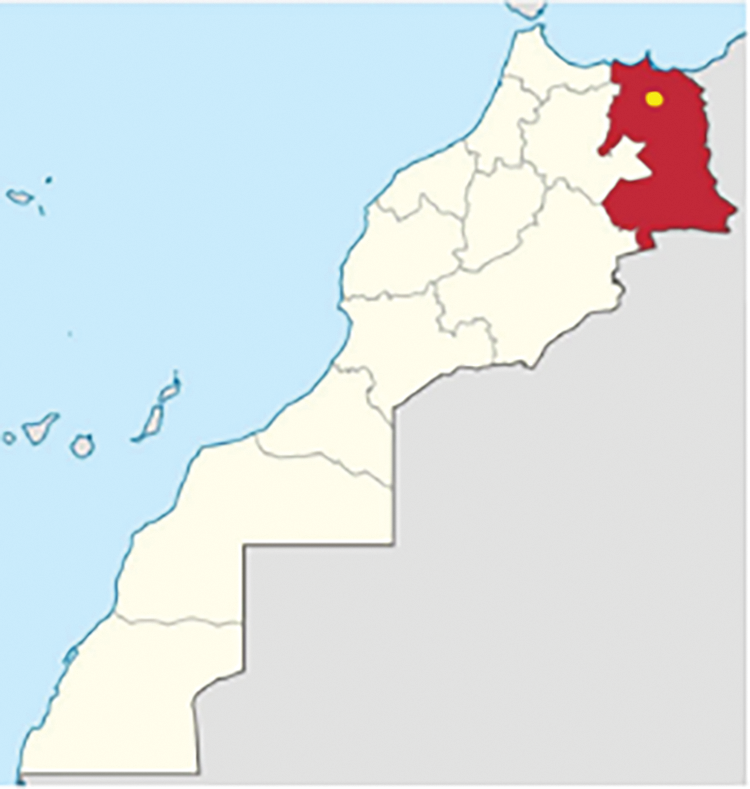
Figure 2: Région de l’étude

Figure 3: Zone d’étude
La complexité de l’environnement étudié est désignée par la nature, la densité et la taille des objets y figurant. La zone d’étude est considérée un environnement assez complexe composé de la végétation, du sol nu, de bâtiments ainsi que de la voirie. Nous ce qui nous intéresse c’est la végétation et plus exactement les arbres oliviers, ils sont caractérisés par des tailles différentes petite, moyenne est grande. Leur distribution est mixte on trouve des parties ou la distribution est assez régulière et les arbres sont bien alignée (Zone 1) alors que d’autre parties sont caractérisées par une distribution pas assez régulière, différents alignements et des tailles d’arbres non homogènes (Zone 2). Le Tableau 1 présente quelques illustrations pour les deux types de zone. La présence importante d’ombre sur l’ortho photo de la zone survolée rajoute encore plus de complexité au travail.

2.2 Acquisition de l’Imagerie de Drone
Les images du drone ont été acquises à l’aide d’un drone Phantom4 avancé doté d’une caméra RGB. C’est l’un des drones les plus professionnels et plus populaires sur le marché. Il capture des images d’une qualité remarquable grâce à sa caméra 4K. Le drone est doté de fonctionnalités intéressantes comme “ ActiveTrack ” ou le mode “ Dessin ”.
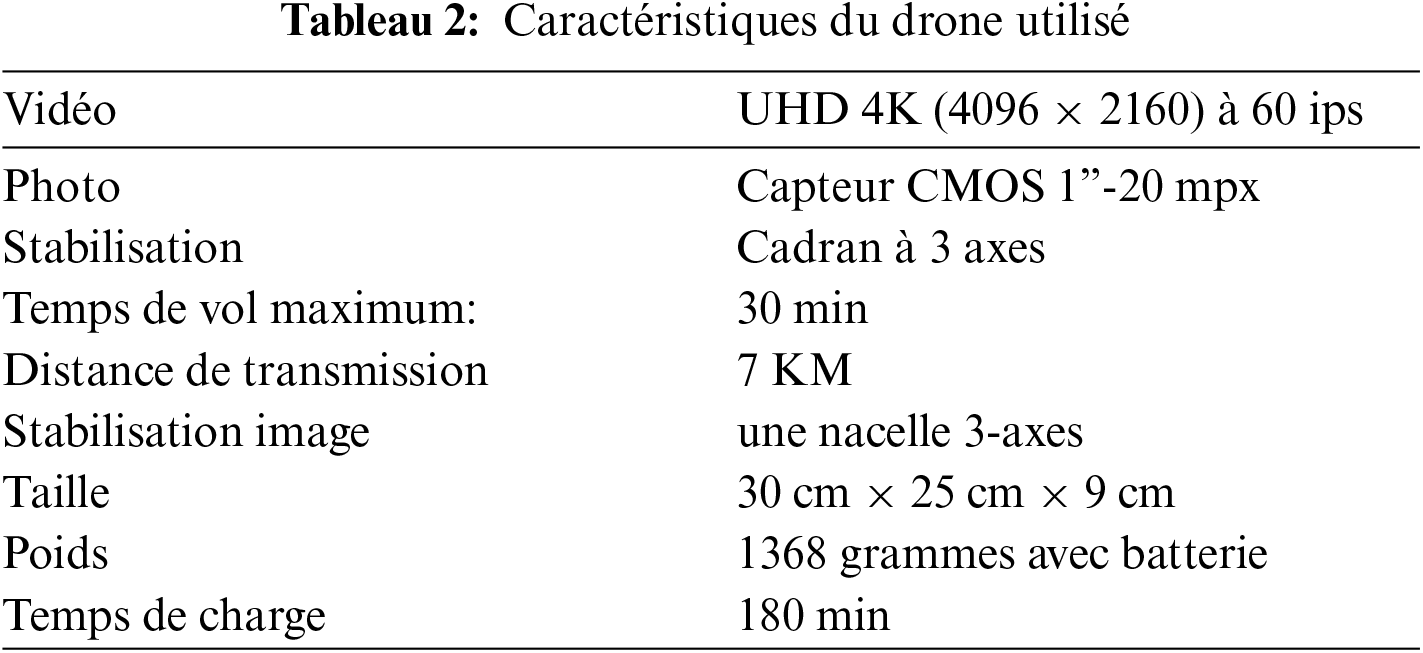
Le Phantom 4 Advanced (Fig. 4) peut voler pendant 30 min, ce qui représente une augmentation du temps de vol effectif de 25% par rapport au Phantom 3 Professional. Il peut parcourir 7 km de portée avec un contrôle complet et une HD 720p en direct vue de tout ce que la caméra voit (Tableau 2). De plus, l’utilisation de « Active Track » permet de suivre un sujet en mouvement aussi facilement que quelques tapotements. Le drone fournit une fonction POI qui peut être activée pour faire tourner le drone autour du sujet de l’utilisateur lorsqu’il se déplace ou recadrez la photo de l’utilisateur en faisant glisser le sujet sur l’écran.

Figure 4: Drone Phantom4 advanced
Le logiciel de planification et de contrôle du vol est Pix4D.L’orthophoto obtenu du champ d’olivier est composée des bandes rouge, verte et bleue (Fig. 5), avec une haute résolution spatiale (0.24 mètres).

Figure 5: Exemple des bandes vert (a), rouge (b), bleu (c) et l’image en couleur réels (d)
Toutes les analyses ont été effectuées sur un ordinateur doté d’un système 64 bits, de 16 Go de RAM et d’un processeur Intel(R) Core(TM) i7-7700 à 3,60 GHz. Les arbres ont été identifiés à l’aide d’un réseau de neuron convolutionel CNN sur eCognition Developer 9.4 de Trimble (Trimble eCognition Software, 2019) (Fig. 6) basé sur Google TensorFlow. C’est l’un des logiciels OBIA les plus connus, le choix de cette plateforme a donc permis d’intégrer la technique CNN avec le raffinement du résultat basé sur l’analyse OBIA, et par conséquent d’exécuter l’analyse complète dans un seul logiciel et de mieux visualiser les résultats.
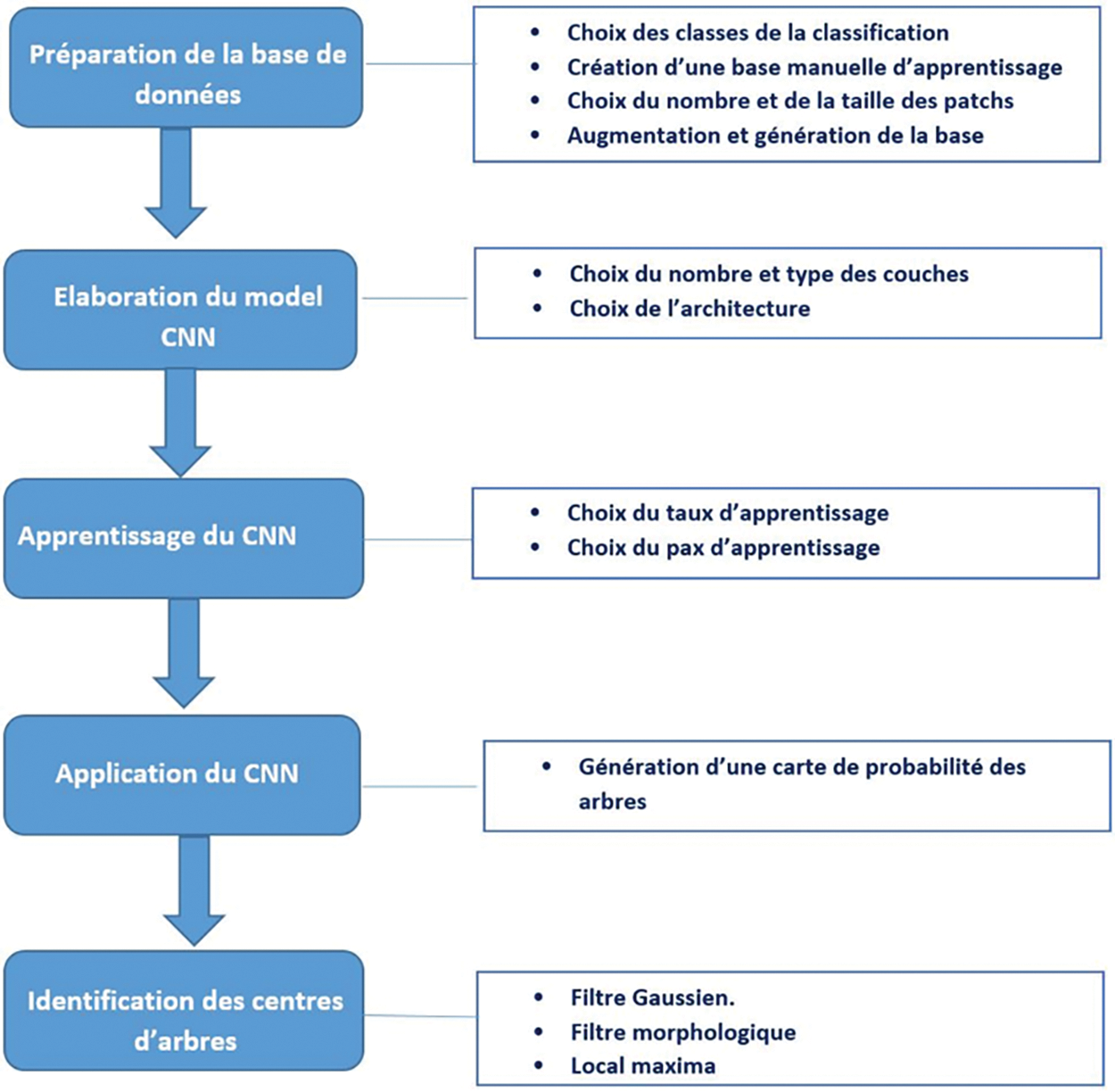
Figure 6: Organigramme représentant le flux opérationnel du (CNN)
2.3.1 Préparation de la base de données (Génération des patchs)
Le champ d’olivier a été dans un premier temps divisé en deux parties : une partie nord pour l’apprentissage du réseau CNN et une partie sud pour la validation (Fig. 7). Les deux parties nord et sud comportent chacune différentes tailles d’arbres oliviers suivant différentes distributions régulière et pas assez régulière comme mentionnées auparavant dans la Section 2.1.

Figure 7: Division de la zone d’étude
Ce qui est important de savoir c’est que toutes les images utilisées doivent être préalablement étiquetées, c’est à dire que chacune des images utilisées doit appartenir à une classe en particulier. Dans notre cas, la base de données d’entraînement est composée de trois classes : arbres, non-arbres et ombres. Ces images appelés patchs ont été générées en se basant sur une base de données d’arbres individuels qui ont été identifiés manuellement et représentés par leurs centres sur la partie nord.
Dans un premier temps 779 points ont été créés pour la classe des arbres, 687 points ont été créés pour la classe de l’ombre et 552 points ont été créés pour la classe non-arbres. Chacun de ces points représente le centre d’une image « patch ». Il suffit de fixer la taille des patchs pour générer les images « patchs » constituant la base d’entrainement (Fig. 8).

Figure 8: Génération des images patches à partir des points pour chaque classe
Pour augmenter la base d’entrainement une zone tampon « Buffer » de 2 × 2 pixels a été utilisée autour de chaque centre d’arbre pour augmenter le nombre d’échantillons et la robustesse du CNN. De cette manière, chaque arbre est présenté par quatre pixels autour du centre de l’arbre, et au lieu d’avoir seulement 1 seule image patch par point, on peut obtenir 4 images patchs pour un seul point. Ce qui permet d’augmenter la taille de la base de données utilisée pour l’entraînement du model CNN. Par la suite l’algorithme choisira aléatoirement parmi ces quatre pixels. Le tableau suivant (Tableau 3) illustre les étapes suivies pour l’augmentation.

Après l’augmentation de la base d’apprentissage le nombre des patchs est multiplié *4 environ. Par conséquence la classe arbres est composés d’environ 2500 patchs, la classe ombre d’environ 2200 patchs et la classe non- arbres est composée d’environ 1700 patchs.
Afin que la base d’apprentissage soit équilibrée, le nombre des patchs doit être le même pour chaque classe. On a donc choisi aléatoirement 1500 patchs pour chacune des trois classes : arbres, non-arbres et ombre. La base d’apprentissage est finalement composée de 4500 patches choisis de manière aléatoire et élaborée à partir de la partie nord du champ.
Les patches d’une classe donnée sont sensés présenter le mieux possible cette classe. La taille idéale du patch est déterminée approximativement par le nombre de pixels capables de présenter correctement et seulement un arbre sur l’ortho-photo, sans inclure d’autres composantes de l’image (ombre, sol nu,...). Dans nôtre cas la taille idéale du patch est fixée à 24 × 24 pixels, elle a été déterminée selon plusieurs tests et expérimentations. Des tailles du patch plus petit ont provoqué le problème de détection de plusieurs couronnes d’arbres « Double Crown Detection » où un seul arbre peut être identifié deux fois, tandis que des tailles plus grandes n’ont pas permis de détecter les petits arbres. En fixant la taille 24 × 24 on a pu obtenir des images qui représentent correctement la nature de chaque classe (Tableau 4).

Notre CNN est constitué d’une seule couche cachée « Hidden Layer». La taille de l’image d’entrée est identique à celle utilisée pour générer les Patches. Chaque couche cachée est déterminée par la taille du noyau « Kernel Size», le nombre de cartes de fonctionnalités « Feature maps» et le max pooling. Étant donné que les noyaux de taille paire génèrent des unités cachées qui sont décalées pour correspondre aux bordures de pixels, un noyau (11 * 11) se voit attribuer 40 cartes de fonctionnalités. La résolution des cartes de fonctionnalités est réduite par le Max pooling avec un filtre 2 * 2 et une foulée de deux dans les directions horizontale et verticale. Par conséquent, le noyau de la couche cachée a un poids de 3 × 11 × 11 × 40. Le facteur principal (3) indique le nombre de couches d’image, les facteurs (11 × 11) indiquent le nombre d’unités dans l’environnement local à partir desquelles les connexions sont transmises à la couche cachée et le dernier facteur (40) fait référence au nombre de cartes de fonctionnalités générées. Ainsi, 40 noyaux 3 × 11 × 11 différents sont formés dans ce réseau, ce qui signifie que 14 520 poids différents sont formés dans la seule couche de ce CNN.
La formation du modèle est effectuée à l’aide des échantillons de patchs étiquetés. Les poids sont ajustés par rétro-propagation. On a attribué un taux d’apprentissage de 0.0015 par méthode d’essais et d’erreurs. Ce taux détermine le degré d’adaptation des poids à chaque itération (Logiciel Trimble eCognition, 2019). Plus le taux d’apprentissage est élevé, plus la formation est rapide, mais il peut ne pas être possible d’atteindre le minimum optimal. Tandis que des taux d’apprentissage plus faibles ralentiront le processus de formation et pourraient être verrouillés dans des poids minimaux locaux qui ne sont même pas proches de la valeur optimale (Trimble eCognition, 2019). Dans notre cas, un total de 5 000 étapes d’apprentissage a été défini de manière à ce que chaque étape utilise 50 échantillons d’apprentissage.
Une carte thermique est générée lorsque nous appliquons le modèle CNN entraîné à la zone de validation (partie sud). Cela illustre la probabilité d’être un arbre. On aura besoin de raffiner le résultat obtenu afin de pouvoir identifier les centres des arbres détectés.
2.7 Identification des centres d’arbres (Raffinement)
Un raffinement a été établit aux résultats obtenus par l’application du réseau neuronal convolutif. Tout d’abord la carte de probabilité de présence d’arbres obtenue a été filtrée à l’aide d’un filtre Gaussien de 7 × 7, puis un filtre morphologique (dilate) de 9 × 9 pixels est appliqué pour générer des maximas locaux dans la carte thermique lissée. Les arbres sont délimités avec un seuil de 0.3 pour les maximas locaux. Cela a permis d’identifier le centre de chaque arbre individuellement.
Une base de données (n = 2 952) d’arbres de référence délimités manuellement a été utilisé pour la validation. Nous nous sommes concentrés uniquement sur les arbres dans notre processus de validation, en ignorant les non-arbres et les ombres, puisque l’ensemble de données de référence ne contenait que des arbres. Chaque arbre identifié par CNN a été comparé à l’arbre le plus proche localisé manuellement. Nous avons utilisé des statistiques d’évaluation communes pour la classification binaire [14,15] et calculé le nombre de vrais positifs (TP) (un arbre correctement identifié) et le nombre de faux positifs (FP) (un arbre mal identifié) ; et des Faux Négatifs (FN) (un arbre est manqué ; une erreur d’omission). FP, FN et TP indiquent respectivement une sur-identification, une sous-identification et une identification parfaite. Nous avons calculé le F-score (F), la précision (P) et le rappel (R). Le F-score est la moyenne harmonieuse du rappel et de la précision et donne la précision globale en tenant compte à la fois des erreurs de commission et des erreurs d’omission (Eq. (1)) ; La précision (c’est-à-dire la valeur de prédiction positive) mesure l’exactitude des arbres détectés et la façon dont l’algorithme a traité les faux positifs (Eq. (2)) et le rappel (c’est-à-dire la sensibilité) mesure le taux de détection des arbres et la façon dont l’algorithme traite les faux négatifs (Eq. (3)).
Le processus CNN produit une carte thermique probabiliste illustrant la probabilité de présence d’un arbre dans la région de validation. Les valeurs de probabilité sont comprises entre 0 et 1. 0 représente la moindre chance et 1 la plus élevée. La figure suivante illustre la carte thermique, où le blanc représente la probabilité la plus élevée de présence d’arbres tandis que le noir représente la probabilité la plus faible de présence d’arbres (Fig. 9).

Figure 9: Carte de probabilité de présence d’arbre
La Fig. 9 représente la probabilité d’existence d’un arbre sur l’image. La valeur élevée de probabilité indique une forte chance qu’un arbre existe à ce point et une probabilité faible indique une faible chance de trouver un arbre à ce point. On ne peut pas donc établir une relation directe entre la probabilité qu’un arbre peut exister ou pas à un point donné avec le mode de distribution des oliviers sur les champs. Mais on a remarqué que les arbres des zones de distributions régulières et organisés sont mieux détectés, on remarque moins d’erreur de détection à ces zones. Alors que pour les distributions non régulières on remarque des erreurs de détections des fois liées à l’intersections de deux ou de plusieurs couronnes d’oliviers ce qui mène à des erreurs de détections (par exemple à l’intersection de trois couronnes d’arbres, au lieu de détecter 3 arbres il détecte seulement 2 arbres ou inversement selon la grandeur des couronnes).
Un raffinement a été établit aux résultats obtenus par l’application du réseau neuronal convolutif pour identifier les centres des arbres. Les emplacements des centres devraient coïncider avec les maxima locaux (les valeurs élevées) dans la carte de probabilité. Avec « local », nous avons une distance spécifique à l’esprit, car les centres d’arbres ne peuvent pas apparaître à seulement quelques pixels les unes des autres.
Tout d’abord la carte de probabilité de présence d’arbres obtenue a été lissée à l’aide d’un filtre Gaussien de 7 × 7 pour obtenir une « carte-lissée » (Fig. 10), puis un filtre morphologique (dilate) de 9 × 9 pixels est appliqué pour générer une couche des maximas locaux. Cette couche « localMax » (Fig. 11) reflète la valeur maximale de la carte de probabilité lissé « carte-lissée » dans un voisinage de 9 pixels (le paramètre d’itérations 9 définit le rayon).
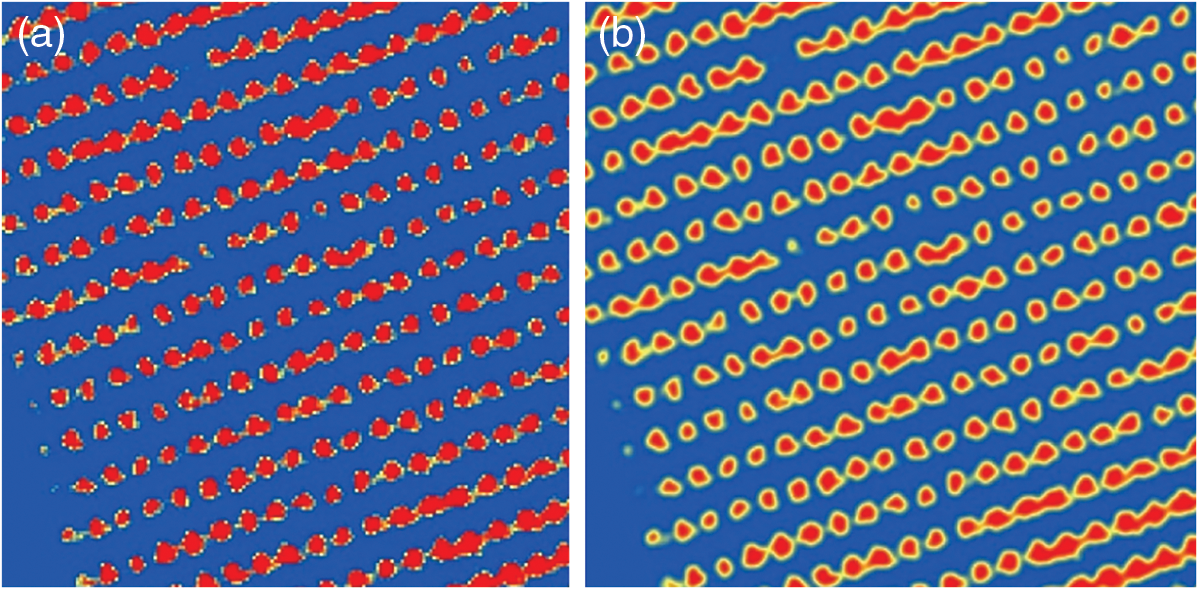
Figure 10: a-Carte de probabilité de présence des arbres en dégradé de couleur : le rouge présente la valeur maximale et le bleu présente la valeur minimale, b-Carte filtrée par un filtre « Gaussian »
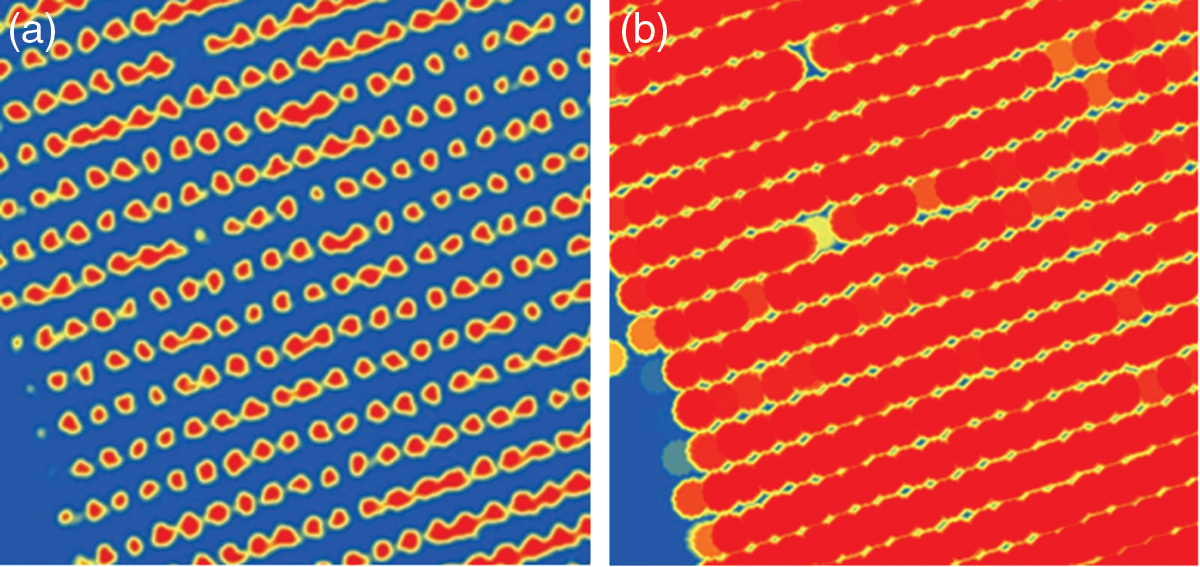
Figure 11: a-La carte de probabilité filtrée par un filtre Gaussian.b-Application du filtre morphologique « dilate »
Ainsi, lorsque les deux couches « localMax » et « carte-lissée » ont exactement la même valeur, nous sont à un maximum local de la couche « carte-lissé ». On commence par trouver beaucoup trop d’objectifs, en appliquant un seuil assez libéral de 0, 5. À la fin un seuil de 0, 3 est choisi pour les maximas locaux. Les polygones obtenus présentent les cimes des arbres (Fig. 12a). On détermine par la suite les centres de gravité de ces polygones qu’on considère comme les centres des arbres oliviers sur l’ortho-photo. Cela a permis d’identifier le centre de chaque arbre individuellement (Fig. 12b).
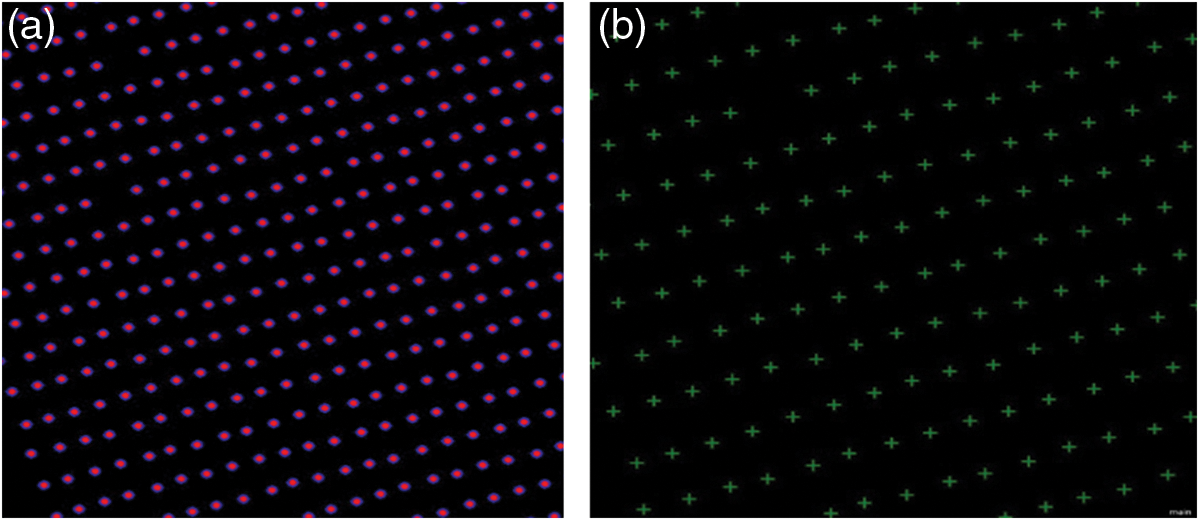
Figure 12: Identification des centres des arbres : a-Les cimes des arbres obtenues, b-Les centres des arbres finaux
La Fig. 13 présente le résultat final de l’identification des centres des. Chaque centre d’arbre identifié est présenté par une croix jaune. Cela permet une cartographie automatique des arbres oliviers sur l’ortho-photo.

Figure 13: Les centres des arbres détectés en croix jaune
Au total, 2 934 arbres individuels ont été détectés lors de la classification finale, contre 2 952 arbres de référence. Le TP (arbres correctement détectés) était de 2 934, le FN (arbres manqués) était de 18 et le FP (faux arbres ajoutés) était de 149. La matrice de confusion peut être présentée comme suit (Fig. 14):
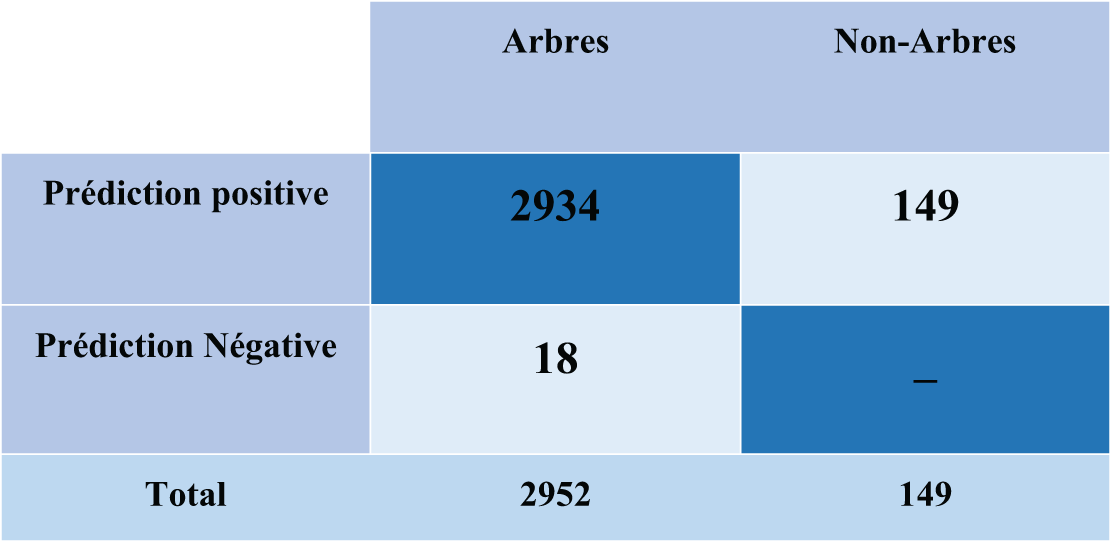
Figure 14: La matrice de confusion
La classification au final a abouti à une précision de 95.16%, un Recall de 99.39% et un F-score de 97.25%. La Fig. 15 illustre les centres des arbres détectés par CNN en rouge à côté des arbres de référence en jaune.

Figure 15: Présentation des centres des arbres détectés en rouge contre les centres des arbres de référence en jaune
La Fig. 16 au-dessous illustre les paramètres utilisés pour l’évaluation de la détection des arbres individuels par la technique CNN. Les résultats de cette méthode sont comparés avec ceux de « Template Matching » et de « OBIA » moyennant une segmentation multi-résolutionnelle. La TM a abouti à une précision globale de 99%, un Recall de 71% et un F-score de 83%. Tandis que l’OBIA. a donné une précision de 84%, un Recall de 96% et un F-score de 89% comme illustré sur la figure suivante (Fig. 16).
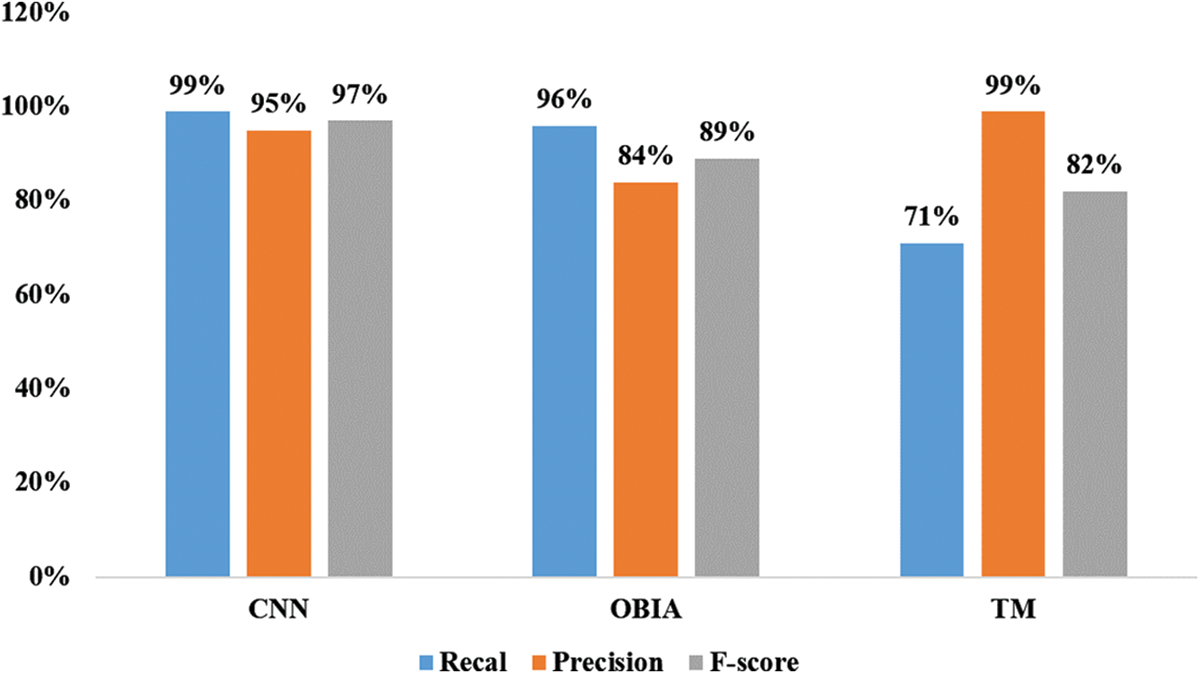
Figure 16: Précision, Recall et F-score obtenus par CNN, TM et OBIA
La précision était élevée pour les deux techniques CNN et le TM (95% et 99%), indiquant des faux positifs très limités, c’est-à-dire que les détections cartographiées sont généralement correctes et représentaient en fait un arbre olivier. Le TM a fourni un meilleur résultat de précision par rapport à CNN, mais il a détecté moins d’arbre (rappel plus faible 71%), alors que le rappel de CNN était plus élevé et cohérent (99%). Autrement dit, Le TM détecte moins d’arbre et commis par conséquence moins d’erreur alors que le CNN détecte plus d’arbre avec haute précision.
De l’autre côté l’OBIA a fourni une valeur de rappel élevée (0.96) c’est-à-dire qu’il arrive à détecter plus d’arbres mais avec moins de précision (0.84). Par conséquence le nombre des fausses positives est plus important. En comparant les scores F qui donnent une idée plus générale sur la qualité de la détection, CNN a fourni un résultat supérieur à celui du TM et de l’OBIA (97% contre 89% et 82%).
Comme pour la plupart des cultures arboricoles, la détection individuelle (et la délimitation ultérieure) des plantes est importante afin de permettre une surveillance spécifique à la plante et une gestion ciblée [5,16]. Ceci est particulièrement pertinent pour les oliviers occupant de vastes territoires et constituant un élément important dans l’arboriculture du Maroc.
Les précisions finales obtenues dans cette étude sont très satisfaisantes et similaires aux recherches précédentes qui utilisaient l’imagerie par drone pour la détection des arbres individuellement, ce qui constitue l’un des problèmes les plus difficiles en matière de télédétection et d’agriculture de précision. D’autres études ont associé l’imagerie multispectrale aux DSM (Digital Surface Models) [17], aux CHM (Canopy Height Models) [18] ou aux nuages de points LIDAR [19]. Pour répondre à cette problématique. Notre étude utilise le CNN sur des images RGB seulement pour atteindre un haut degré de précision. Cela vérifie l’utilité des données RGB dans la détection et le comptage des arbres individuels et prouve leur capacité à réduire énormément le coût de la gestion et du suivi par drone. Ce qui s’accorde très bien avec les principes d’optimisation de l’agriculture de précision.
Pour le CNN, l’ajout d’un nombre de patchs supplémentaire, l’augmentation de la base d’apprentissage (par rotation par exemple) ainsi que la réalisation de plus de tests et l’optimisation des paramètres peuvent améliorer encore plus les résultats [20]. Cependant, comme cette étude était élaborée dans un contexte régional spécifique, des méthodes identiques peuvent ne pas être applicables directement à la détection des arbres oliviers dans différentes régions géographiques ou même dans différentes exploitations. La variation de la variété des oliviers, de la croissance, de la végétation environnante, du sol, des pratiques agricoles et de nombreux autres facteurs environnementaux, culturels et de gestion peut rendre la transférabilité et la généralisation difficile [21].
Outre la formation des modèles CNN, la collecte d’échantillons représentatifs et de haute qualité prend du temps. La création d’une base de données d’apprentissage plus grande, de haute qualité et plus diversifiée fournirait un outil excellent pour une adaptation plus large du CNN et une amélioration de la transférabilité pour la détection des oliviers par drone de manière individuelle [13,22].
Considérant l’importance des arbres oliviers dans l’agriculture méditerranéenne et tenant en compte de leurs caractéristiques spécifiques de morphologie et de croissance, la cartographie des oliviers de manière individuelle est une étape importante vers l’obtention de mesures précises et d’informations précieuses sur leur croissance, leur état et même leur rendement grâce à l’utilisation d’informations spectrales et morphologiques (hauteur, étendue de la couronne, etc.) dérivées des données d’images UAV.
Dans cette étude, des images RGB de drone ont été capturées pour déterminer la capacité des réseaux de neurone convolutionnel à détecter les arbres oliviers dans un environnement GEOBIA. La base de données élaborée est composée de 4 500 images de 24 × 24 pixels. Les résultats obtenus ont démontré que l’application de cet algorithme intelligent CNN pour la détection individuelle était la mieux adaptée par rapport au « Template Matching » et au « OBIA » avec une précision de 95%, un Recall de 99% et un F-score de 97%. Compte tenu de ces résultats, l’application de la méthode CNN décrite convient aux objectifs de cette étude et ajoute des informations importantes pour le développement de méthodes appropriées et d’autres possibilités d’application dans des recherches futures, ainsi que pour des applications dans la gestion des cultures. Aussi, l’augmentation de la base d’apprentissage et l’utilisation d’une base de données d’images d’arbres oliviers plus diversifiée fournirait un outil excellent pour une généralisation du CNN et une transférabilité du model à d’autres cas d’étude concernant la détection individuelle des oliviers par drone.
Les résultats de détection réussis soutiennent l’utilisation des drones comme moyen approprié pour le développement ultérieur des approches de surveillance et de suivi des champs d’oliviers et prouvent leur capacité à réduire considérablement le processus de comptage des arbres, par rapport à la procédure manuelle, surtout s’ils sont associés à des algorithmes d’apprentissage profond.
L’objectif des travaux futurs est de développer davantage l’utilisation d’images capturées par des drones pour extraire des informations utiles pertinentes pour la gestion réelle des cultures. Plus précisément, le développement des méthodes de délimitation des couronnes à partir d’images de drones et l’évaluation de leur capacité à mesurer les attributs morphologiques des oliviers (par exemple, l'étendue de la couronne, la hauteur) de manière plus automatisée afin de faciliter le suivi des cultures et l’estimation du rendement. Des techniques CNN plus approfondies, telles que le CNN basé sur la région (R-CNN) et (Mask R-CNN), peuvent également être utilisées.
Remerciements/Acknowledgment: None.
Financements/Funding Statement: This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Contributions des auteurs/Author Contributions: Oumaima Ameslek, El Mostafa Bachaoui : Concept et conception de la recherche, Collecte et/ou assemblage des données, Analyse et interprétation des données, Rédaction de l’article et Approbation finale de l’article. Hafida Zahir, Soukaina Mitro : Révision critique de l’article, Analyse et interprétation des données. Tous les auteurs ont examiné les résultats et approuvé la version finale du manuscrit.
Disponibilité des données et du matériel/Availability of Data and Materials: Readers can access the data used in this study by contacting the corresponding author.
Avis éthiques/Ethics Approval: Not applicable.
Conflits d’intérêt/Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Velusamy P, Rajendran S, Mahendran RK, Naseer S, Shafiq M, Choi JG. Unmanned aerial vehicles (UAV) in precision agriculture: applications and challenges. Energies. 2022;15(1):217. doi:10.3390/en15010217. [Google Scholar] [CrossRef]
2. Marconi S, Graves SJ, Weinstein BG, Bohlman S, White EP. Estimating individual level 2. Plant traits at scale. Ecol Appl. 2021;31(4):e02300. doi:10.1002/eap.2300. [Google Scholar] [PubMed] [CrossRef]
3. Peña JM, Torres-Sánchez J, de Castro AI, Kelly M, López-Granados F. Weed mapping in early-season maize fields using object-based analysis of Unmanned Aerial Vehicle (UAV) images. PLoS One. 2013;8(10):1–11. doi:10.1371/journal.pone.0077151. [Google Scholar] [PubMed] [CrossRef]
4. Malek S, Bazi Y, Alajlan N, AlHichri H, Melgani F. Efficient framework for palm tree detection in UAV images. IEEE J Sel Top Appl Earth Obs Remote Sens. 2014;7(12):4692–703. doi:10.1109/JSTARS.2014.2331425. [Google Scholar] [CrossRef]
5. Torres-Sánchez J, López-Granados F, Serrano N, Arquero O, Peña JM. High-throughput 3-D monitoring of agricultural-tree plantations with Unmanned Aerial Vehicle (UAV) technology. PLoS One. 2015;10(61–20. [Google Scholar]
6. Liu T, Abd-Elrahman A, Morton J, Wilhelm VL. Comparing fully convolutional networks, random forest, support vector machine, and patch-based deep convolutional neural networks for object-based wetland mapping using images from small unmanned aircraft system. GIScience Remote Sens. 2018;55(2):243–64. doi:10.1080/15481603.2018.1426091. [Google Scholar] [CrossRef]
7. Csillik O, Cherbini J, Johnson R, Lyons A, Kelly M. Identification of citrus trees from unmanned aerial vehicle imagery using convolutional neural networks. Drones. 2018;2(4):1–16. doi:10.3390/drones2040039. [Google Scholar] [CrossRef]
8. Zhang Q, Wang Y, Liu Q, Liu X, Wang W. CNN based suburban building detection using monocular high resolution Google Earth images. Int Geosci Remote Sens Symp. 2016;2016:661–4. doi:10.1109/IGARSS.2016.7729166. [Google Scholar] [CrossRef]
9. Zhu XX, Tuia D, Mou L, Xia G-S, Zhang L, Xu F, et al. Deep learning in remote sensing: a review. 2017. doi:10.1109/MGRS.2017.2762307. [Google Scholar] [CrossRef]
10. Fu T, Ma L, Li M, Johnson BA. Using convolutional neural network to identify irregular segmentation objects from very high-resolution remote sensing imagery. J Appl Remote Sens. 2018;12(2):025010. doi:10.1117/1.JRS.12.025010. [Google Scholar] [CrossRef]
11. Fukushima K. Neocognitron: a hierarchical neural network capable of visual pattern recognition. Neural Netw. 1988;1(2):119–30. doi:10.1016/0893-6080(88)90014-7. [Google Scholar] [CrossRef]
12. Alom MZ, Tarek MT, Yakopcic C, Stefan W, Paheding S, Nasrin MS, et al. The history Began from AlexNet: A comprehensive survey on deep learning approaches; 2018. Available from: http://www.mhlw.go.jp/new-info/kobetu/roudou/gyousei/anzen/dl/101004-3.pdf. [Accessed 2023]. [Google Scholar]
13. Pearse GD, Tan AYS, Watt MS, Franz MO, Dash JP. Detecting and mapping tree seedlings in UAV imagery using convolutional neural networks and field-verified data. ISPRS J Photogramm Remote Sens. 2020;168:156–69. doi:10.1016/j.isprsjprs.2020.08.005. [Google Scholar] [CrossRef]
14. Li W, Guo Q, Jakubowski MK, Kelly M. Photogrammetric engineering & remote sensing. Photogramm Eng Remote Sens. 2012 Jan 75;78(1):75–84. doi:10.14358/PERS.78.1.75. [Google Scholar] [CrossRef]
15. Saito T, Rehmsmeier M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS One. 2015;10(3):1–21. doi:10.1371/journal.pone.0118432. [Google Scholar] [PubMed] [CrossRef]
16. Johansen K, Raharjo T, McCabe MF. Using multi-spectral UAV imagery to extract tree crop structural properties and assess pruning effects. Remote Sens. 2018;10(6):854. doi:10.3390/rs10060854. [Google Scholar] [CrossRef]
17. Caruso G, Zarco-Tejada PJ, González-Dugo V, Moriondo M, Tozzini L, Palai G, et al. High-resolution imagery acquired from an unmanned platform to estimate biophysical and geometrical parameters of olive trees under different irrigation regimes. PLoS One. 2019;14(1):1–19. doi:10.1371/journal.pone.0210804. [Google Scholar] [PubMed] [CrossRef]
18. Gu J, Grybas H, Congalton RG. A comparison of forest tree crown delineation from unmanned aerial imagery using canopy height models vs. spectral lightness. Forests. 2020;11(6):605. doi:10.3390/f11060605. [Google Scholar] [CrossRef]
19. Timilsina S, Sharma SK, Aryal J. Mapping Urban trees within cadastral parcels using an object-based convolutional neural network. ISPRS Ann Photogramm Remote Sens Spat Inf Sci. 2019;4:111–7. doi:10.5194/isprs-annals-IV-5-W2-111-2019. [Google Scholar] [CrossRef]
20. Ye Z, Wei J, Lin Y, Guo Q, Zhang J, Zhang H, et al. Extraction of olive crown based on UAV visible images and the U2-Net deep learning model. Remote Sens. 2022;14(6):1–20. doi:10.3390/rs14061523. [Google Scholar] [CrossRef]
21. Weiss M, Jacob F, Duveiller G. Remote sensing for agricultural applications: a meta-review. Remote Sens Environ. 2020;236:111402. doi:10.1016/j.rse.2019.111402. [Google Scholar] [CrossRef]
22. Kattenborn T, Leitloff J, Schiefer F, Hinz S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J Photogramm Remote Sens. 2021;173:24–49. doi:10.1016/j.isprsjprs.2020.12.010. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools