
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Enhancing Multi-Modality Medical Imaging: A Novel Approach with Laplacian Filter + Discrete Fourier Transform Pre-Processing and Stationary Wavelet Transform Fusion
1 Department of Computer Science, Institute of Management Sciences, Peshawar, 25000, Pakistan
2 Department of Computer Science, City University of Science & Technology, Peshawar, 25000, Pakistan
3 Department of Computer Science, Iqra National University, Swat, 19200, Pakistan
4 Department of Computer Science and Software Technology, University of Swat, Swat, 19200, Pakistan
5 Department of Medical Science, Saidu Medical College, Swat, 19200, Pakistan
6 Department of Allied Health Science, Iqra National University, Swat, 19200, Pakistan
* Corresponding Author: Sarwar Shah Khan. Email:
Journal of Intelligent Medicine and Healthcare 2024, 2, 35-53. https://doi.org/10.32604/jimh.2024.051340
Received 03 March 2024; Accepted 28 May 2024; Issue published 08 July 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Multi-modality medical images are essential in healthcare as they provide valuable insights for disease diagnosis and treatment. To harness the complementary data provided by various modalities, these images are amalgamated to create a single, more informative image. This fusion process enhances the overall quality and comprehensiveness of the medical imagery, aiding healthcare professionals in making accurate diagnoses and informed treatment decisions. In this study, we propose a new hybrid pre-processing approach, Laplacian Filter + Discrete Fourier Transform (LF+DFT), to enhance medical images before fusion. The LF+DFT approach highlights key details, captures small information, and sharpens edge details, effectively identifying meaningful discontinuities and modifying image frequencies from low to high. The sharpened images are then fused using the Stationary Wavelet Transform (SWT), an advanced technique. Our primary objective is to improve image clarity and facilitate better analysis, diagnosis, and decision-making in healthcare. We evaluate the performance of the resultant images both visually and statistically, comparing the novel SWT (LF+DFT) approach with baseline techniques. The proposed approach demonstrates superior results on both breast and brain datasets, with evaluation metrics such as Root Mean Square Error (RSME), Percentage Fit Error (PFE), Mean Absolute Error (MAE), Entropy, and Signal-to-Noise Ratio (SNR) confirming its effectiveness. The technique aims to enhance image quality, enable better medical analysis, and outperform existing fusion methods. In conclusion, our proposed LF+DFT approach followed by SWT fusion shows promising results for enhancing multi-modality medical images, which could significantly impact medical diagnosis and treatment in the future.Keywords
Image fusion involves merging multiple source images of the same scene into one fused image that contains complete and valuable information. This fused image is higher informative and accurate than any individual source image, as it incorporates complementary data [1]. Image fusion techniques find application in various domains, including image recognition, hazy image restoration [2], multi-focus image fusion [3], surveillance systems, foggy image enhancement [4], pan-sharpening [5], and medical imaging [6]. This manuscript specifically emphasizes the fusion of multi-modality medical images, which assists doctors in disease diagnosis.
In today’s healthcare, medical imaging is essential, revolutionizing the field and enabling scientists to study and understand various aspects of the human body. Many modalities such as Single-Photon Emission Computed Tomography (SPECT), Positron Emission Tomography (PET), Magnetic Resonance Imaging (MRI), and Computed Tomography (CT) are used to extract valuable and hidden information [7]. For example, CT images are excellent for visualizing bones and blood vessels but are not as effective for soft tissue. Conversely, MRI images offer a higher soft tissue contrast but lack clarity in bone visualization. To overcome these limitations, a combination of CT and MRI images from different modalities is often required for accurate diagnosis and treatment. There are two approaches to integrating these modalities. The first involves upgrading hardware devices, which is complex and expensive. The second approach involves image processing, which is a cost-effective and convenient way to obtain a valuable and informative integrated image [8].
In recent decades, significant research efforts have focused on developing and implementing fusion methods to improve the quality and effectiveness of medical images. However, when it comes to multi-modality fused images, such as combining CT and MRI images, several issues arise that can impact their utility in diagnosing and treating diseases. One common issue is the presence of gradient and texture distortion in the affected regions of the fused images. This distortion can lead to inaccuracies and inconsistencies in the representation of the affected area, making it challenging for radiologists to interpret the images accurately. These distortions may arise due to the differences in imaging principles, acquisition parameters and image resolutions between the two modalities. Another issue is the misalignment or registration errors between the CT and MRI images. Since these modalities capture images using different techniques, it can be challenging to precisely align the corresponding anatomical structures in the fused image. Misalignment can result in spatial discrepancies and misinterpretation of the fused image, affecting the accuracy of diagnosis and treatment planning. Furthermore, variations in image intensity and contrast between the CT and MRI images can pose challenges in achieving a seamless fusion. Differences in intensity levels, brightness and contrast can make it difficult to integrate the information from both modalities effectively, leading to inconsistencies and artifacts in the fused image [7].
Trying to cover and resolve these issues developed many techniques such as Guided Image Filter (GIF) [7], Rolling Guidance Filtering [8], Stationary Wavelet Transform (SWT) Gram-Schmidt Spectral Sharpening, Discrete Wavelet Transforms (DWT) [9], Dual-Tree Complex Wavelet Transforms (DTCWT) [10], Majority Filter (MF) [11], and Principal Component Analysis (PCA) [12], Discrete Cosine Harmonic Wavelet (DCHWT) [13]. While these techniques address specific challenges in multi-modality image fusion, it is challenging to find a single approach that accommodates all issues comprehensively. Ongoing research focuses on developing hybrid fusion frameworks that combine a couple of techniques to overcome the limitations and enhance the overall performance of multi-modality image fusion.
This manuscript introduces a novel hybrid sharpening algorithm that combines the benefits of LF+DFT. The novel technique aims to enhance the visibility of sharp edges in multi-modality medical images, specifically MRI and CT images. Following the sharpening step, the fused image is generated using the SWT approach. The contribution of this paper can be summed up as follows:
• The utilization of a Laplacian Filter (LF) helps to emphasize the primary details of the image, detect small information and enhance edge sharpness. LF is particularly effective in identifying significant changes and discontinuities within the image.
• Discrete Fourier Transform (DFT) is essential in calculating the frequency information of the image discretely. This frequency information is integral to the image-sharpening process. DFT helps to identify rapid changes in the image, which correspond to shifts from low to high frequencies.
• The novel sharpening approach combines the frequency information obtained from the Fourier transform with the second derivative masking of LF, thereby leveraging the strengths of both techniques.
• The proposed method follows a two-step process where image enhancement is applied to sharpen the images, followed by the fusion approach for combining the sharpened images.
• This dual-step process represents a novel concept in the field of image fusion, yielding exceptional results compared to existing methods.
The remaining structure of the manuscript is formed as follows. Section 2 briefly depicts the previous work of fusion techniques on medical images. Section 3 depicts the algorithm, such as LF + DFT with SWT. Section 4 shows the discussion with experimental results. Section 5, finally the article is concluding.
In [14], Gram-Schmidt Spectral sharpening has been used to display the anatomical items from the higher resolution CT image alongside the physiological data from the PET imaging. Wei et al. A novel approach to multimodal medical image fusion has been introduced, aiming to address various medical diagnostic challenges. This method leverages a fusion strategy employing a pulse-coupled neural network with boundary measurements, combined with an energy attribute fusion strategy within the non-subsampled shearlet transform domain. In [8], Rolling Direction uses a filter to divide the architectural and technical elements of the source medical photos. According to the Laplacian Pyramid fusion rule, the structural component is fused. For the detail component, a sum-modified-Laplacian (SML) based strategy is applied.
In [15], Principal Components Analysis (PCA) and Stationary Wavelet Transform (SWT) are used to analyze many types of imagery. For input photos with various contrast/brightness levels, PCA seems to perform improved. When the input visuals are multi-sensor and multi-modal, SWT seems to perform better.
Based on a guided image filter and the image statistics [7], a weighted average fusion method to marge CT and MRI brain images has been presented. This is the suggested algorithm: Each source image detail layer is extracted using a guided image filter. Arif et al. [16], based on the genetic algorithm (GA) and curvelet transform, offer a novel technique and algorithm of fusion for multi-modality biomedical images.
In [17], the last ten years have seen tremendous advancements in the multimodal medical image fusion sector. However, color distortion, blurring, and noise are constant problems with older techniques. In this paper, we offer a brand-new Laplacian re-decomposition (LRD) architecture designed specifically for the integration of multimodal medical images. There are two technical advancements in the suggested LRD. First, offer a Laplacian decision graph decomposition approach with image augmentation to get more information, redundant information and low-frequency subband images. Second, introduce the concepts of the overlapping domain (OD) and non-OD (NOD), where the OD helps to fuse extra information and the NOD helps to fuse complementary information, taking into account the varied properties of redundant and complementary information. Wang et al. [18] present a biomedical image fusion algorithm established on convolutional neural networks (CNN).
In [19], the advantages of convolutional neural networks (CNNs) and non-subsampled shear let transform (NSST) are combined in a novel model for biomedical picture fusion equally. Al-Ameen et al. [20] introduce a new method for fusing multimodal medical images to address existing challenges. The proposed approach combines guided filtering and image statistics within the shearlet transform domain. Initially, the multimodal images undergo decomposition using shearlet transform, which captures texture information in various orientations. This decomposition separates the images into low-and high-frequency components, representing base and detail layers, respectively. Subsequently, a guided filter with a high epsilon value determines the weights of the original paired images. These weights are then applied to the base layer to obtain unified base layers. Fusion of the base layers is achieved through a guided image filter and image statistics fusion rule, which computes covariance matrix and Eigenvalues to identify significant pixels in the neighborhood.
Trentacoste et al. [21] introduce a morphological preprocessing technique to tackle issues like non-uniform illumination and noise, employing the bottom-hat–top-hat strategy. Subsequently, grey-principal component analysis (grey-PCA) is applied to convert RGB images into grayscale, preserving intricate details. Next, the local shift-invariant shearlet transform (LSIST) decomposes the images into low-pass (LP) and high-pass (HP) sub-bands, effectively recovering significant characteristics across various scales and orientations. The HP sub-bands are then processed through two branches of a Siamese convolutional neural network (CNN), involving feature detection, initial segmentation, and consistency verification to capture smooth edges and textures. Meanwhile, the LP sub-bands are fused using local energy fusion via averaging and selection modes to restore energy information.
This article presents a new approach aimed at improving the accuracy and visibility of objects in a multi-modality image fusion environment. The key concept introduced in this study involves a pre-processing assessment of the image before fusion, followed by the application of the conventional SWT approach for fusion, as demonstrated in Algorithm 1. The entire procedure is visually depicted in Fig. 1 and the novel approaches are further elaborated below for better understanding.
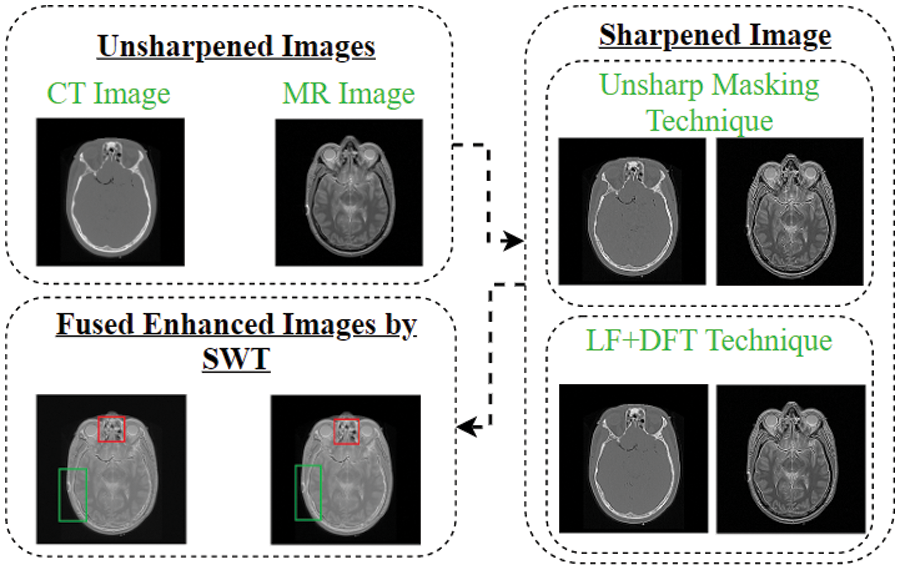
Figure 1: The novel concept schematic flow-chart
The term “unsharp mask” may seem misleading, but it is an effective edge-sharpening filter used to enhance the visibility of edges in an image. The name originated from the process it employs, which involves creating an unsharp version of the original image and identifying the presence of edges, similar to a high-pass filter [20]. By sharpening an image, the texture, and finer details can be enhanced. One common method for sharpening is known as “unsharp masking,” which can be employed in various kinds of images. It should be noted that the unsharp mask technique does not introduce artifacts or add new details to the image, but it significantly enhances the appearance of existing details by increasing the acutance of small-scale elements, making important details easier to perceive [12,21,22]. When images are sharpened, their size and similarity are maintained, but a UM simply increases the acutance of an image’s sharpness. In the UM method, the sharpened image
where
LF is a popular image enhancement technique used to highlight edges and fine details in an image. It is based on the second derivative of the image intensity, which measures the rate of change of intensity across the image. By employing the Laplacian operator in the image, we can accentuate regions of rapid intensity changes, such as edges and fine structures. The Laplacian operator is a differential operator that calculates the Laplacian of a function. In the case of image processing, it is typically applied to grayscale or single-channel images. The Laplacian operator is defined as the sum of the second derivatives of the image concerning the spatial coordinates. In mathematical notation, the Laplacian operator
Here, g(r, s) represents the pixel intensities of the given image and
To apply the Laplacian Filter to an image, we convolve the image with the Laplacian operator. The convolution operation involves sliding a small kernel (representing the Laplacian operator) over the image and computing the sum of element-wise multiplications between the kernel and the corresponding image pixels. The resulting values are then mapped to a new image, known as the Laplacian image. The Laplacian Filter highlights regions of rapid intensity changes by producing positive values for bright-to-dark transitions (edges) and negative values for dark-to-bright transitions. This creates a sharpening effect, enhancing the edges and fine details in the image.
3.3 Discrete Fourier Transform (DFT)
The DFT is a mathematical approach used to analyze the frequency components of a signal or an image. It converts a signal from its time or spatial domain representation to the frequency domain representation. In the case of images, the DFT provides information about the frequency content of different spatial components of the image. The equation for the DFT is given by:
Here, F(x, y) represents the transformed image in the frequency domain, g(r, s) denotes the original image in the spatial domain, (x, y) represents the spatial frequency indices, M and N represent the dimensions of the image, and j represents the imaginary unit. The DFT calculates the frequency spectrum of the image, representing the magnitude and phase of different frequency components. It allows us to analyze the frequency content of the image and apply various frequency-based operations, such as filtering, enhancement and reconstruction.
This article introduces a novel method for multi-modality medical image fusion using a hybrid sharpening algorithm called LF + DFT. This hybrid algorithm combines the advantages of LF and DFT approaches. LF, also known as an edge detection approach, is utilized to identify important edges in the image. It detects areas of the image where rapid changes occur, similar to abrupt changes in frequencies from low to high. On the other hand, DFT is a widely used method for computing frequency information in discrete form. The hypothesis is that incorporating frequency information through DFT can significantly enhance image sharpness. In this unique technique, the frequency information obtained from Fourier transforms is combined with the second derivative masking from LF. This combination results in a powerful sharpening method that takes advantage of both LF and DFT to improve the visibility of edges and fine details in the image shown in Fig. 2. By merging the strengths of LF and DFT, this novel hybrid sharpening approach offers a promising solution for multi-focus image fusion. It provides a more effective and accurate method for enhancing image sharpness and improving the overall quality of fused images. Here is the requirement of spatial conversion to the frequency and inverse see Eqs. (3) and (4). So, this is the purpose of calling that the cross-domain technique.
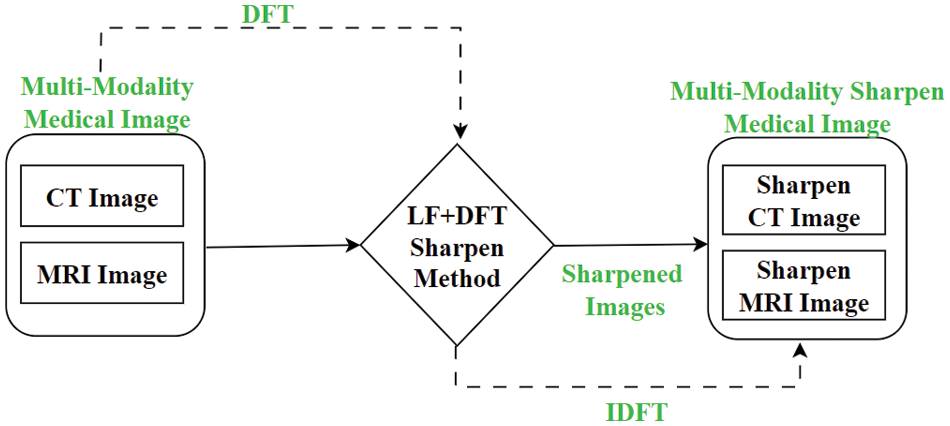
Figure 2: The proposed approach’s framework
Where the square image of resolution M × M, the multidimensional DFT in Eq. (2) is as follows:
Whereas
The new approach for a square picture of resolution M × M, the multidimensional is given by using the Laplacian Eq. (1) and Fourier Eq. (3):
Resolution and acutance are two fundamental factors that contribute to the clarity and sharpness of an image. Resolution refers to the size of the image in terms of pixels and is a straightforward and objective measure. A higher-resolution image, with more pixels, generally results in sharper details. On the other hand, acutance is a subjective measure that quantifies the contrast at an edge. It reflects the perceived sharpness and clarity of an edge in an image. While there is no precise numerical measure for acutance, our visual system recognizes edges with higher contrast as having more distinct and well-defined boundaries. Given the significance of both resolution and acutance in image quality, the motivation for using edge sharpening techniques becomes evident. By enhancing the visibility and sharpness of edges, edge sharpening methods aim to improve both the resolution and acutance of an image. This not only enhances the overall visual appeal of the image but also enables better analysis, interpretation, and decision-making in various applications. Therefore, incorporating edge sharpening techniques, such as the one proposed in this article, holds great potential for improving the clarity and quality of multi-modality medical images. By emphasizing the important edges and enhancing their contrast, the proposed approach can provide medical professionals with more accurate and informative images, facilitating better diagnosis and treatment decisions.
3.5 Stationary Wavelet Transform (SWT)
In image fusion applications, the SWT can be utilized to decompose multiple input images into wavelet coefficients at different scales. The fusion process involves combining these coefficients to create a single fused image that contains the relevant information from each input image. Let’s consider two input images, A and B, that are decomposed using the SWT. The SWT decomposes an image into approximation (Aj) and detail (Dj) coefficients at different scales. These coefficients capture the low-frequency and high-frequency information, respectively. Mathematically, the decomposition of image A at level j can be represented as:
Similarly, the decomposition of image B at level j can be represented as:
The approximation coefficients (Aj and Bj) represent the low-frequency content of each image, while the detail coefficients (Dj) capture the high-frequency details. To fuse the coefficients, various fusion rules or strategies can be applied. One common approach is to combine the approximation coefficients using a weighted average or maximum selection. For example, the fused approximation coefficient (Fj) can be computed as:
where wA and wB are the weights assigned to images A and B, respectively. These weights can be determined based on image quality, relevance, or other factors. The fused detail coefficients (FDj) can be obtained by applying a fusion rule, such as maximum selection or weighted averaging, to the corresponding detail coefficients (Dj) of the input images. Finally, the fused image can be reconstructed by combining the fused approximation and detail coefficients at each level using the inverse SWT [12,19].
We provide a brief explanation of the process of the suggested multi-modality image fusion method in Algorithm 1 to condense all the above considerations.

The following table presents the measurements used to assess the experimental results of the novel method:
This section evaluates the effectiveness and accuracy of the novel algorithm for multi-modality medical images, specifically focusing on brain lesions and breast images. The algorithm aims to enhance the images and sharpen the edges to improve small details before performing the fusion process. The evaluation was conducted using three pairs of CT and MRI images, obtained from the website “https://sites.google.com/site/aacruzr/image-datasets” (accessed on 06/03/2024). The image sets had dimensions of 258 × 258 for sets 1 and 2, and 385 × 460 for set 3. The evaluation of the algorithm was carried out both visually and statistically [29].
The resulting fused images were assessed using six commonly used statistical evaluation metrics shown in Table 1. The PFE measures the dissimilarity between the corresponding pixels of the fused image and the original image, normalized by the norm of the original image. Entropy is used to evaluate the texture, appearance, or information content of the resultant image. The PSNR quantifies the spatial quality of the resultant image. The MAE is calculated to determine the difference between the resulting image and the reference image. The SNR is a performance metric that measures the ratio of information to noise in the fused image. The RMSE indicates the discrepancy between the fused image and the original image. These statistical metrics serve as quantitative measures to assess the quality and accuracy of the resultant images obtained from the novel algorithm. The novel technique outperforms the existing approaches, as demonstrated through comparisons with six other techniques, namely SWT, DWT [9], DTCWT [10], Majority Filter MF [11], PCA [12], and DCHWT [13]. The experiments were conducted using MATLAB 2018b on a computer equipped with an Intel(R) Core (TM) i7-6700K CPU operating at 4.00 GHz and 8 GB of RAM. The performance of the novel technique was assessed on three benchmark multi-modality medical image datasets. This evaluation aimed to compare the proposed technique with baseline techniques in terms of visual quality and statistical measures.

Figs. 4–11 display the original CT and MRI images along with their corresponding enhanced images obtained through the proposed sharpening technique, including Unsharp masking and LF+DFT Sharpen. The enhanced images effectively highlight and enhance minor details, making them clearer and more perceptible. These enhanced images play a crucial role in subsequent stages of the fusion process, where the aim is to integrate the essential information from both CT and MRI modalities.
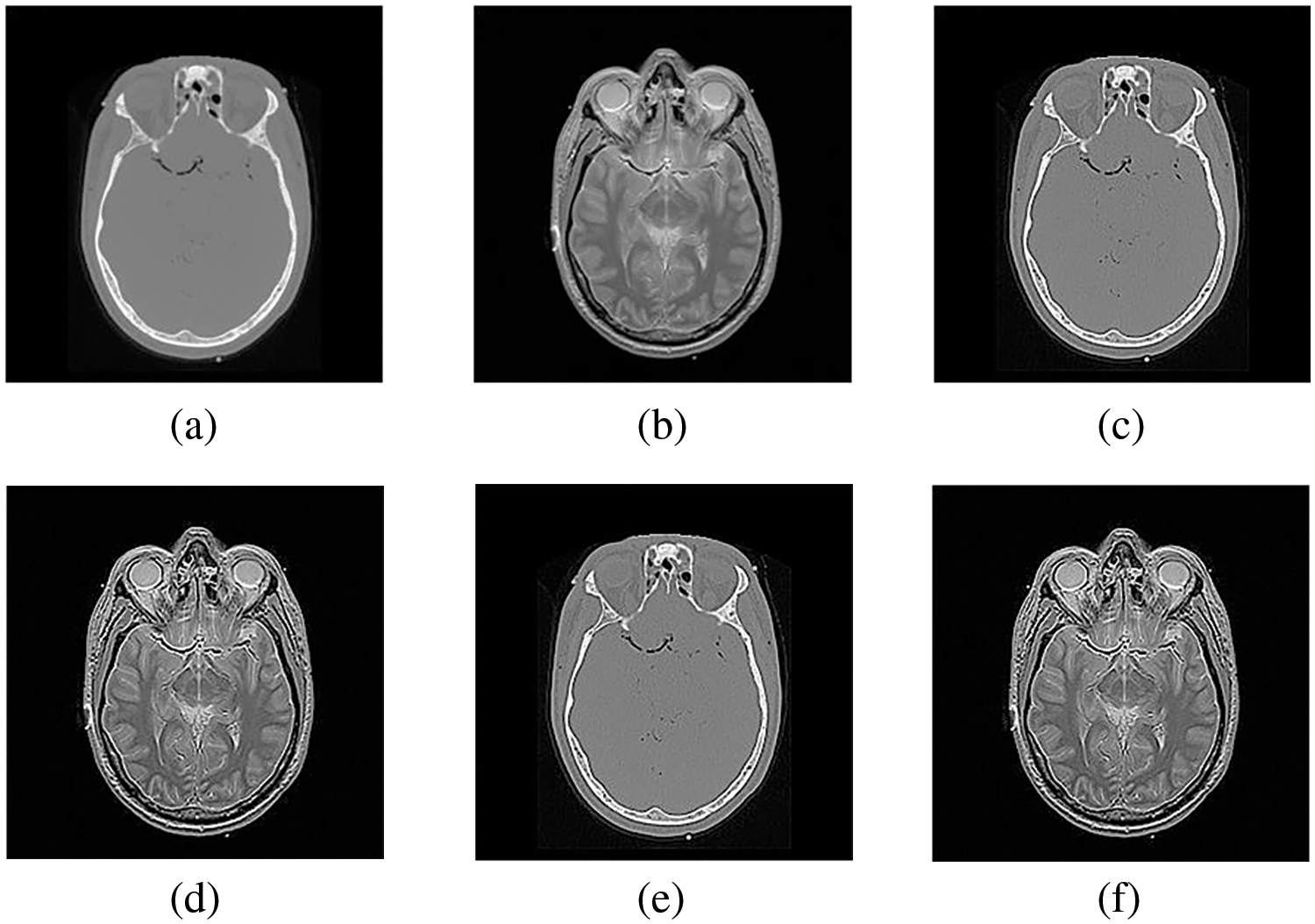
Figure 3: The sharpened results of “Brain CT, and MRI Image set 1” (a, b) are two source images CT and MRI, respectively, (c, d) are sharpened images by Unsharp masking and (e, f) LF+DFT sharpen images
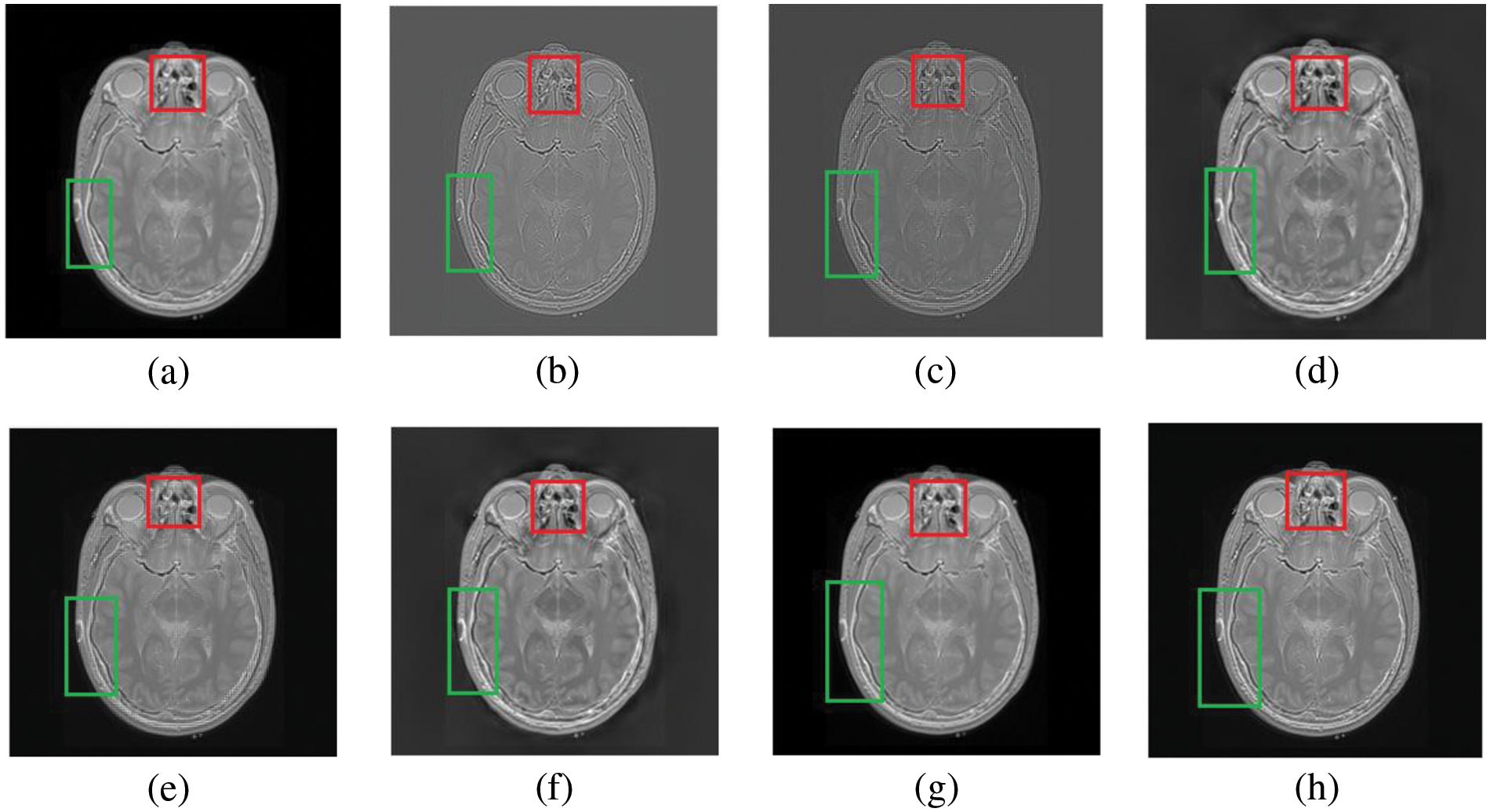
Figure 4: The fusion results of “Brain CT and MRI Image set 1” (a) PCA (b) MF, (c) DWT, (d) DTCWT, (e) DCHWT, (f) SWT, (g) SWT+UM, (h) SWT+(LF+DFT)
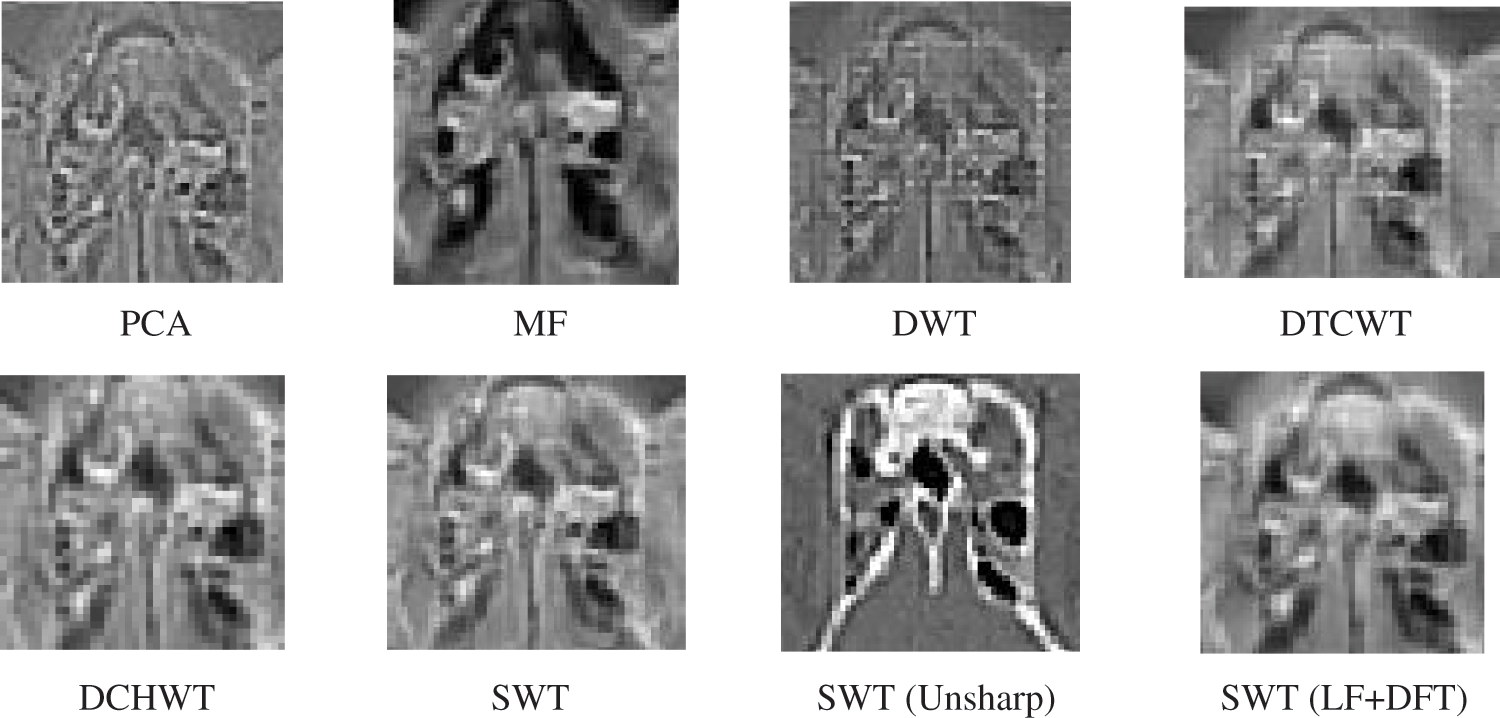
Figure 5: The magnified version of the red region marked in Fig. 4, correspondingly

Figure 6: The difference between (a, b) simple CT and MRI images and (c, d) Sharpen CT and MRI images
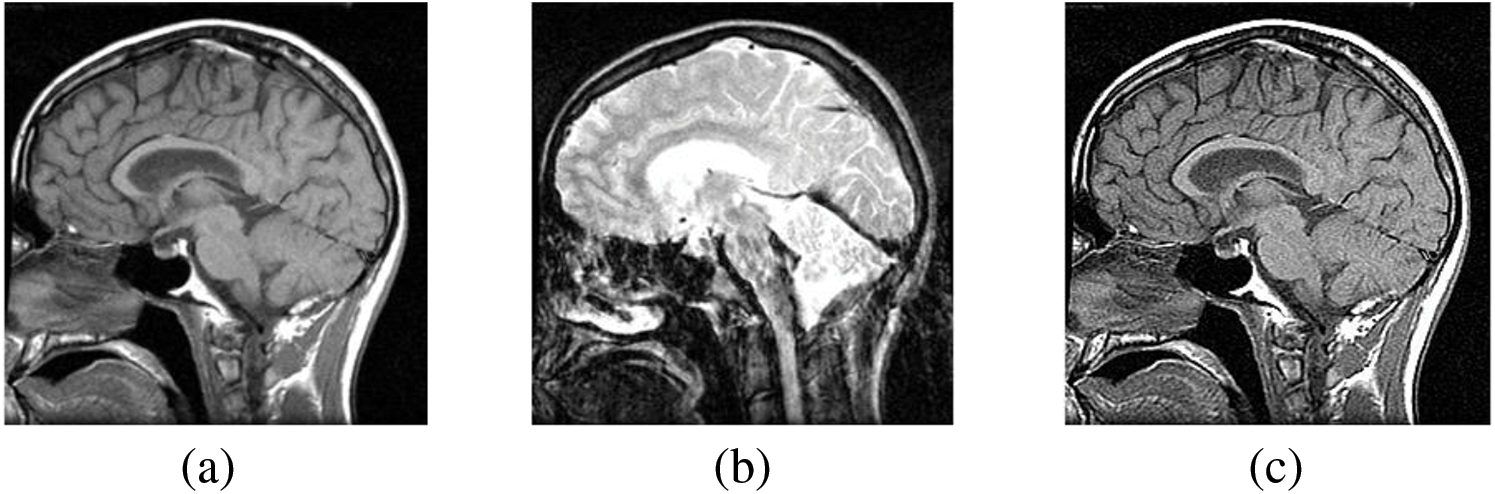
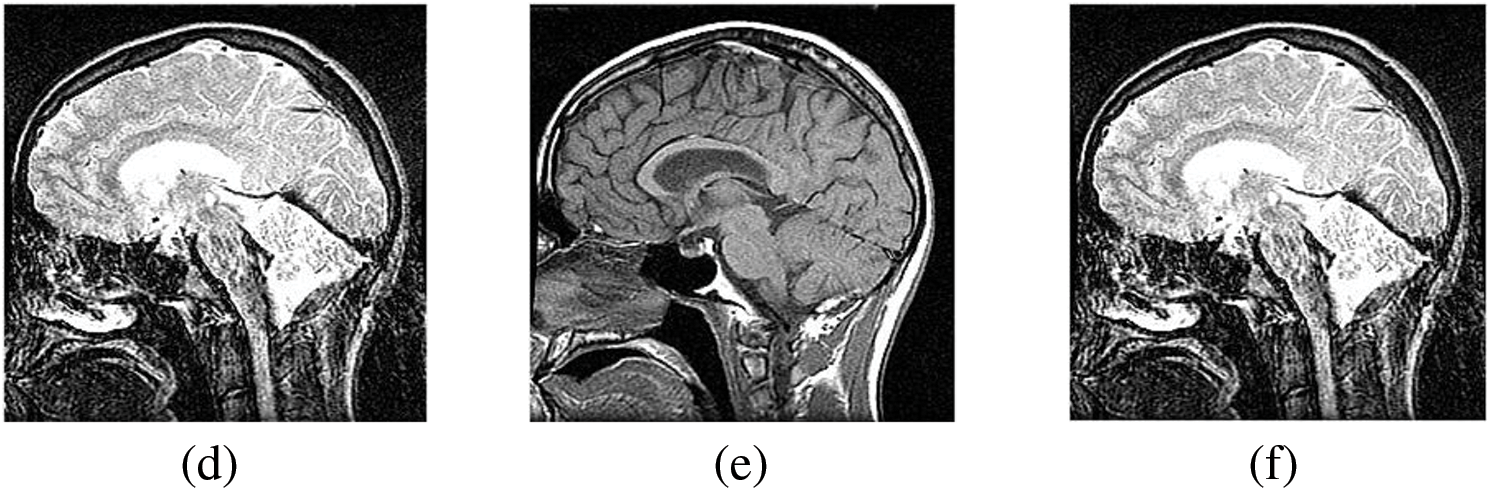
Figure 7: The sharpened results of “Brain CT and MRI Image set 2” (a), (b) are two source images CT and MRI, respectively, (c), (d) are sharpen images by Unsharp masking and (e), (f) LF+DFT sharpened images
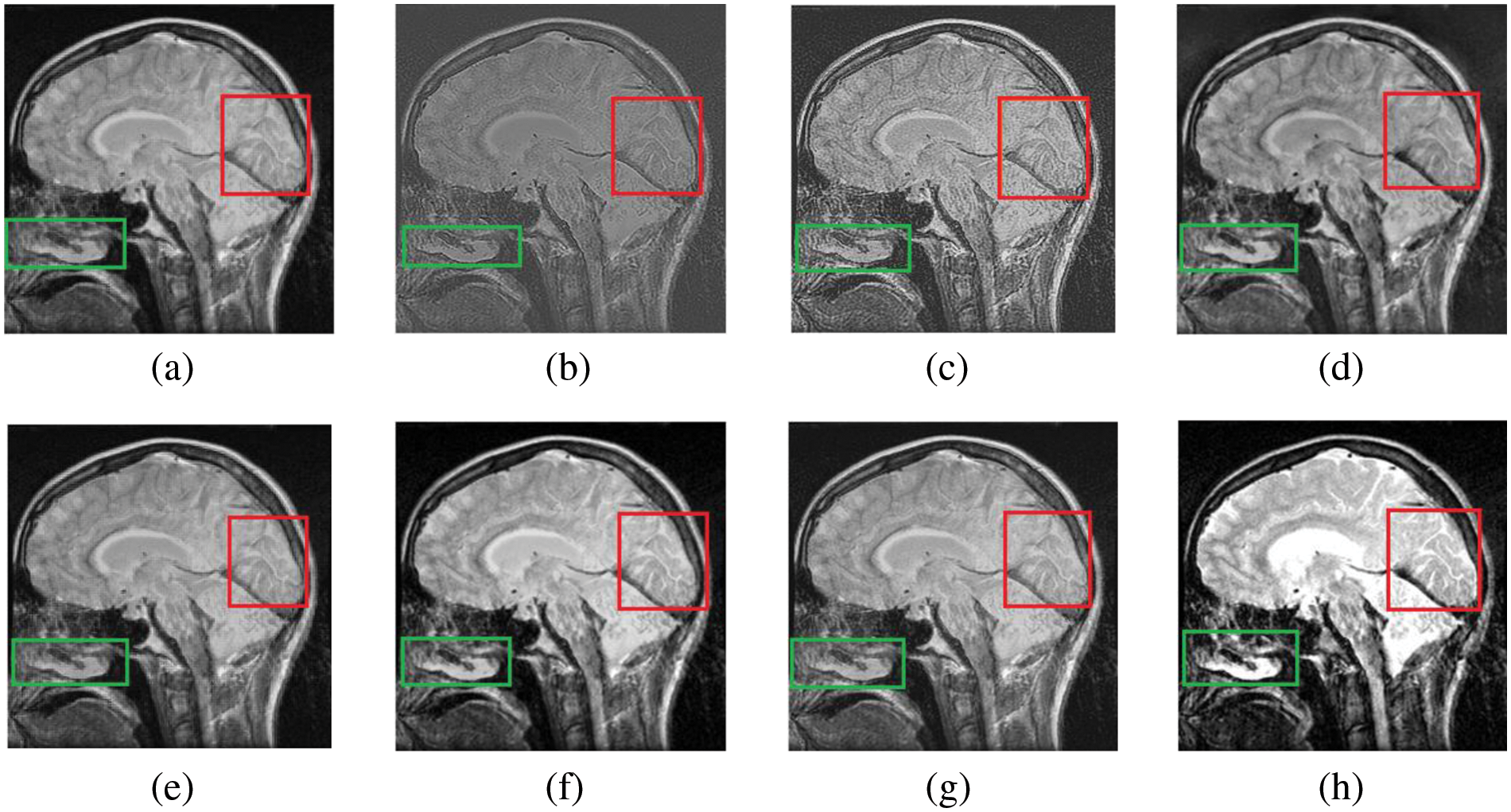
Figure 8: The fusion results of “Brain CT and MRI Image set 2” (a) PCA (b) MF, (c) DWT, (d) DTCWT, (e) DCHWT, (f) SWT, (g) SWT+UM, (h) SWT+(LF+DFT)

Figure 9: The magnified version of the red region marked in Fig. 8, correspondingly
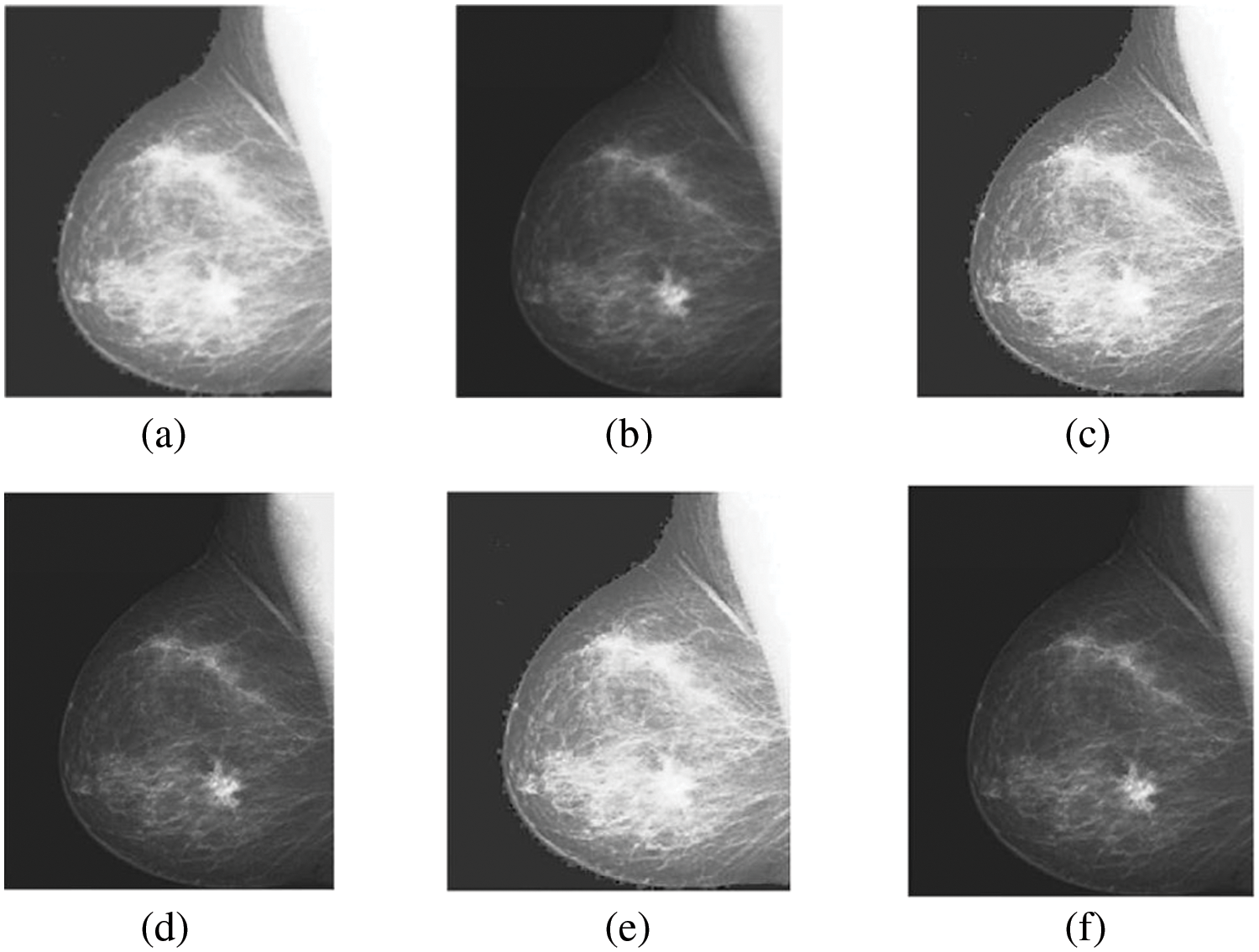
Figure 10: The sharpened results of “Breast CT, and MRI Image set 3” (a, b) are two source images CT and MRI, respectively, (c, d) are sharpen images by unsharp masking and (e, f) LF+DFT sharpened images
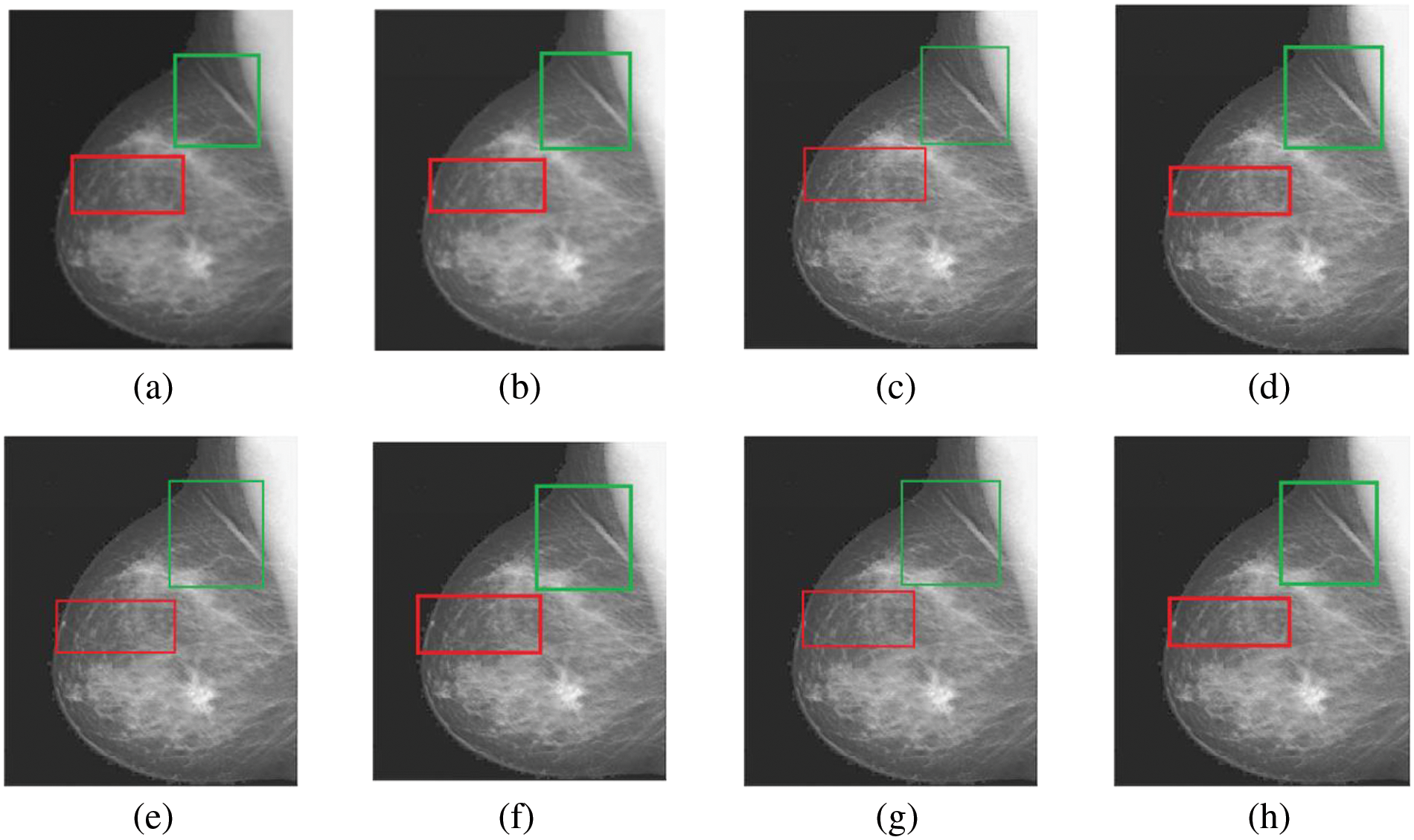
Figure 11: The fusion results of “Breast CT and MRI Image set 3” (a) PCA (b) MF, (c) DWT, (d) DTCWT, (e) DCHWT, (f) SWT, (g) SWT+UM, (h) SWT+(LF+DFT)
Figs. 4–11 present the fused images obtained from both existing and proposed hybrid approaches. The existing approaches, including PCA, MF, DWT, DTCWT, DCHWT and SWT, initially fuse the source images. Then, the SWT method is combined with the proposed sharpening techniques and applied to fuse the sharpened images. Comparatively, the fused images generated by the proposed methods, namely SWT+Unsharp masking and SWT+(LF+DFT), exhibit significant improvements compared to the baseline techniques. To highlight the differences among the fused images and facilitate a better understanding of the enhanced and informative nature of the images, specific areas are marked with red and green boxes in Figs. 3–10. Furthermore, a magnified version of the region marked with the red box is provided in Figs. 5 and 9 to further illustrate the qualitative analysis of brain datasets.
Understanding the difference between simple and sharpened images is crucial. Sharpened images exhibit higher acutance, which is a subjective measure of edge contrast. Acutance cannot be quantified directly; it relies on the observer’s perception of whether an edge has sufficient contrast or not. Our visual system tends to perceive edges with higher contrast as having more clearly defined boundaries. In Fig. 6, we zoom in on specific areas of the images, highlighting them with green and red boxes for simple and sharpened images, respectively. This allows us to easily observe the dissimilarity between the two versions, particularly in the enhanced details visible within the green boxes.
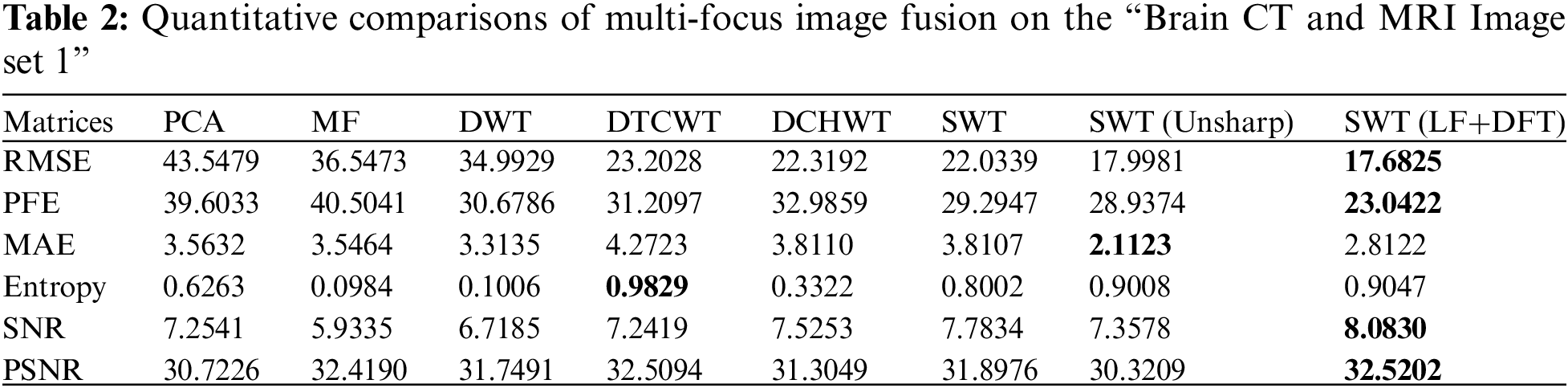
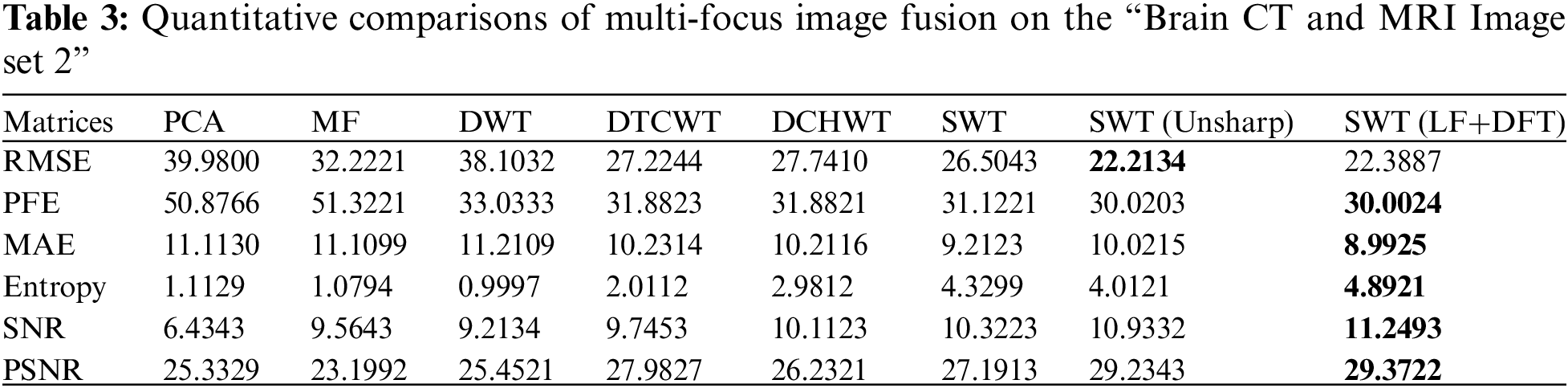
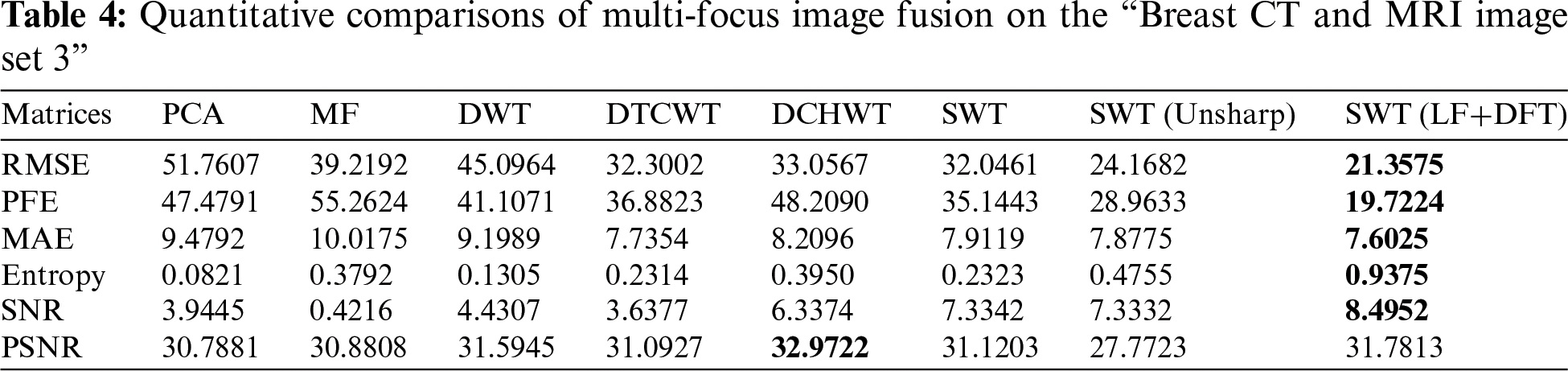
In this section, a quantitative comparison is performed between the novel approach and baseline methods using well-known assessment measures. The evaluation metrics used are RMSE, PFE, MAE, entropy, SNR and PSNR. Tables 2–4 present the quantitative results, demonstrating the superiority of the proposed methods. The bold values in the tables indicate favorable outcomes, indicating better image quality. However, Table 4 provides a detailed analysis and comparison of the results obtained by the proposed methods (SWT with Unsharp masking and SWT with LF+DFT) across the three datasets. In dataset 1, the DTCWT method performs well in terms of entropy, indicating a higher level of information contained in the image. The SWT with Unsharp masking achieves high results in MAE, indicating its ability to capture the dissimilarity between the final and reference images. The other four metrics show favorable values for the proposed approach SWT with LF+DFT. Moving on to dataset 2, the SWT with Unsharp masking exhibits higher RMSE values, highlighting the differences between the final and reference images. However, the remaining five metrics indicate good values for SWT with LF+DFT. Lastly, in dataset 3, the DCHWT method achieves the best PSNR value, indicating high spatial quality in the image. Similarly, the other five metrics demonstrate favorable values for the proposed approach SWT with LF+DFT.
In Fig. 12, a comparison is presented between the fusion techniques using SWT along with two different sharpening methods: Unsharp masking and the proposed sharpening technique LF+DFT. The purpose of this comparison is to evaluate the effectiveness of these techniques and determine which one yields better results. By visually examining the fused images, it can be observed that both Unsharp masking and LF+DFT sharpening techniques contribute to enhancing the quality and clarity of the fused images. This comparison serves to emphasize the advantages of the proposed LF+DFT sharpening technique in improving the overall quality of the resultant images. It demonstrates that the combination of LF+DFT sharpening with SWT fusion produces superior results compared to the fusion technique using Unsharp masking.
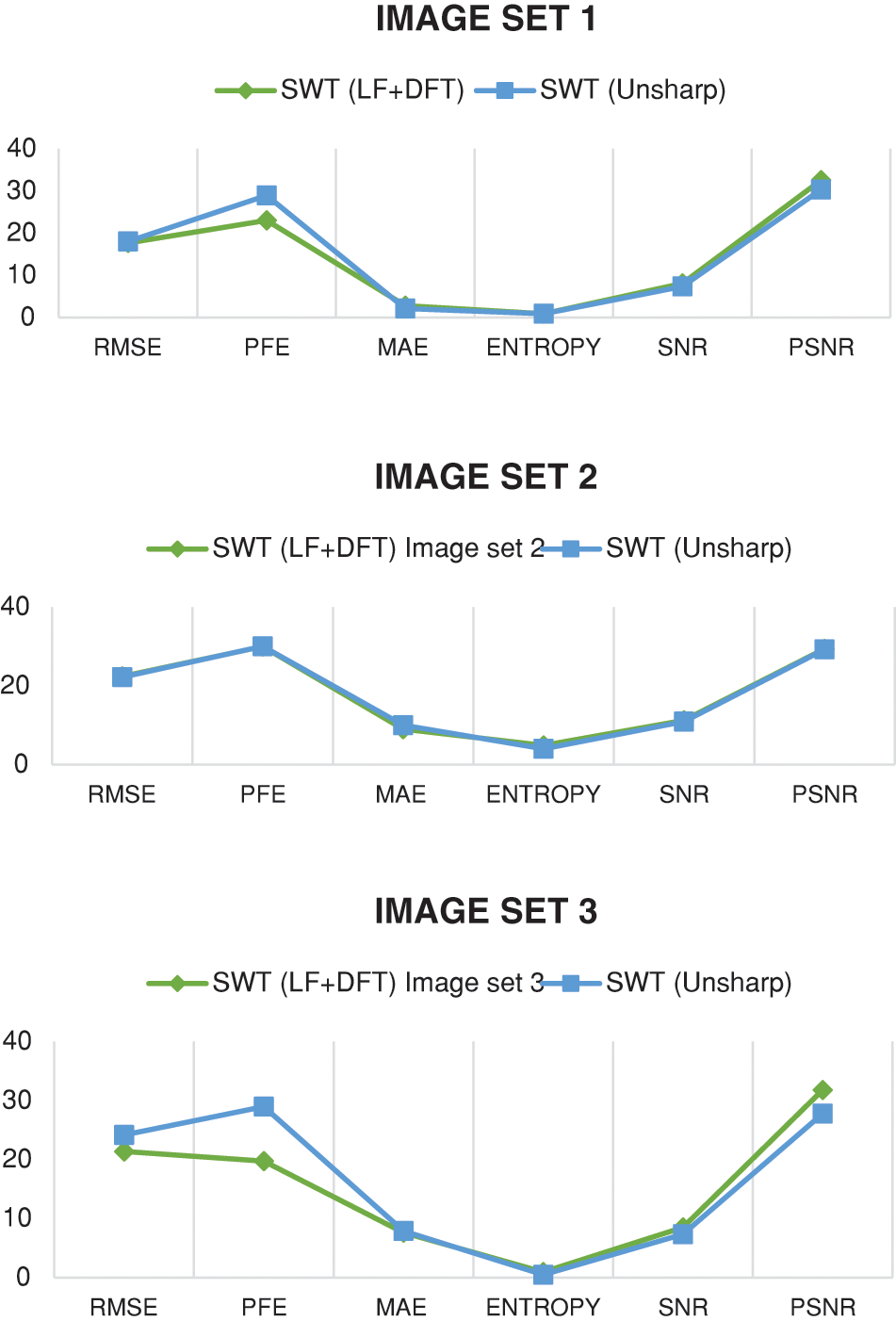
Figure 12: The comparison is presented between the fusion techniques using SWT along with two different sharpening methods: Unsharp masking and the proposed sharpening technique LF+DFT
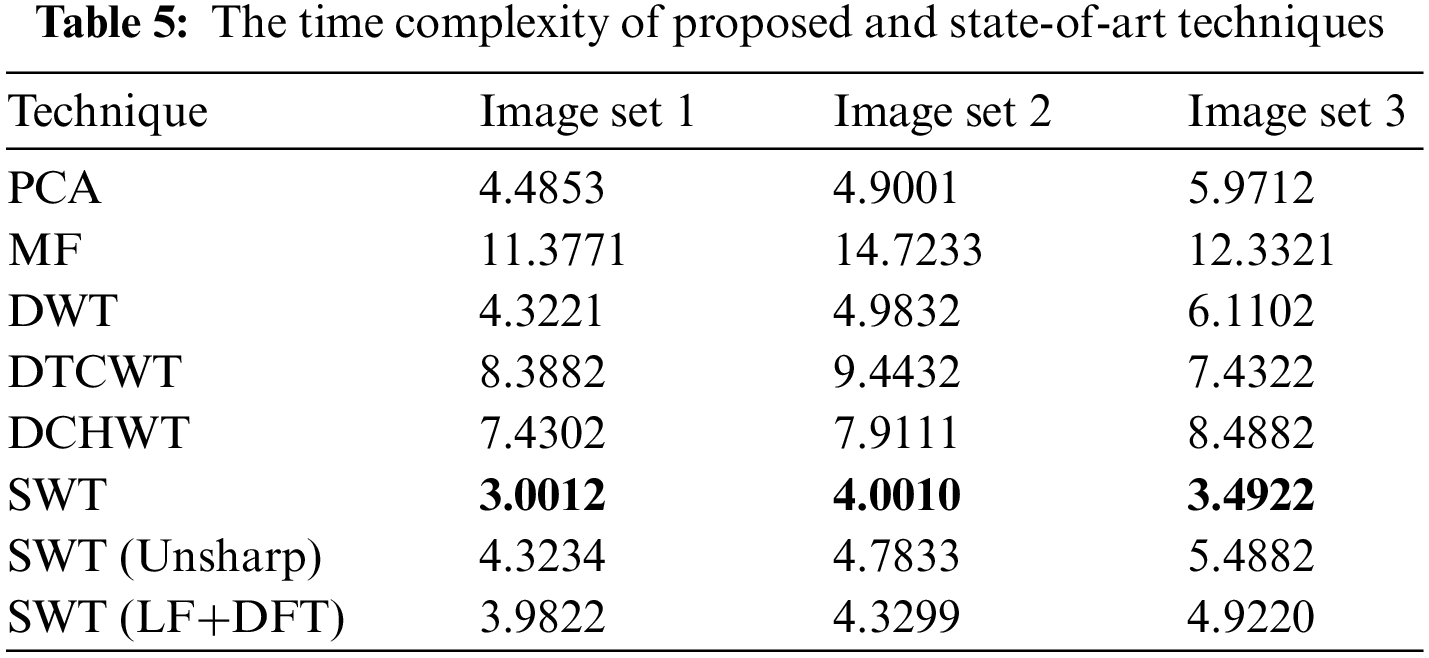
The computational resources used by a technique concerning the size of the input are measured by an algorithm’s time complexity. In Table 5, the time complexity values represent the execution times (in seconds) for each technique on different image datasets (Image set 1, Image set 2 and Image set 3). Based on the values in the table, it can be observed that the SWT technique generally has lower time complexity values compared to the other techniques, indicating faster computation. The bold values in the table indicate lower time complexity values for SWT in comparison to the other techniques. However, it is important to note that the proposed algorithms, which involve the combination of SWT with LF+DFT or Unsharp masking sharpening techniques, have slightly higher time complexity values. This is because the additional time required for the sharpening step is incorporated into the overall computation time.
In this study, we focused on the fusion of CT and MRI images, which belong to different medical modalities. The aim was to generate a single resultant image that combines both anatomical and physiological information effectively. To achieve this, introduced a novel approach that involves enhancing the images through sharpening techniques before performing the fusion process. Specifically, we utilized LF+DFT and Unsharp masking as the sharpening methods, followed by fusion using SWT. The combination of these two steps, sharpening and fusion, demonstrated promising results compared to other existing and baseline techniques. The effectiveness of the proposed approach was evaluated both visually and statistically. For the statistical evaluation, we employed six well-known performance metrics and assessed the results across three different brain datasets. In future work, it would be valuable to explore the use of alternative sharpening techniques in conjunction with advanced fusion methods to further improve the results. This concept has the potential to be applied in various scenarios and applications, offering opportunities for further advancements in image sharpening and fusion techniques. In the future, we aim to incorporate various modalities such as PET or ultrasound images.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Mian Muhammad Danyal, Sarwar Shah Khan, Rahim Shah Khan: Conceptualization; Methodology; Formal analysis; Investigation; Mian Muhammad Danyal: Roles/Writing–original draft preparation. Saifullah Jan, Naeem ur Rahman: Supervision; Validation; Writing-review and editing. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Conflicts of Interest: The authors declare that there is no conflict of interest regarding the publication of this paper.
References
1. Z. Wang, Z. Cui, and Y. Zhu, “Multi-modal medical image fusion by Laplacian pyramid and adaptive sparse representation,” Comput. Biol. Med., vol. 123, pp. 103823, 2020. doi: 10.1016/j.compbiomed.2020.103823. [Google Scholar] [PubMed] [CrossRef]
2. D. Singh, D. Garg, and H. Singh Pannu, “Efficient landsat image fusion using fuzzy and stationary discrete wavelet transform,” Imaging Sci. J., vol. 65, no. 2, pp. 108–114, 2017. [Google Scholar]
3. S. S. Khan, M. Khan, and Y. Alharbi, “Multi focus image fusion using image enhancement techniques with wavelet transformation,” Int. J. Adv. Comput. Sci. Appl., vol. 11, no. 5, pp. 414–420, 2020. doi: 10.14569/issn.2156-5570. [Google Scholar] [CrossRef]
4. D. Singh and V. Kumar, “Dehazing of remote sensing images using improved restoration model based dark channel prior,” Imaging Sci. J., vol. 65, no. 5, pp. 282–292, 2017. [Google Scholar]
5. S. S. Khan, Q. Ran, and M. Khan, “Image pan-sharpening using enhancement based approaches in remote sensing,” Multimed. Tools Appl., vol. 79, no. 43–44, pp. 32791–32805, 2020. doi: 10.1007/s11042-020-09682-z. [Google Scholar] [CrossRef]
6. M. Kaur and D. Singh, “Fusion of medical images using deep belief networks,” Cluster Comput., vol. 23, pp. 1439–1453, 2020. doi: 10.1007/s10586-019-02999-x. [Google Scholar] [CrossRef]
7. D. P. Bavirisetti, V. Kollu, X. Gang, and R. Dhuli, “Fusion of MRI and CT images using guided image filter and image statistics,” Int. J. Imaging Syst. Technol., vol. 27, no. 3, pp. 227–237, 2017. doi: 10.1002/ima.22228. [Google Scholar] [CrossRef]
8. J. Chen, L. Zhang, L. Lu, Q. Li, M. Hu and X. Yang, “A novel medical image fusion method based on rolling guidance filtering,” Internet of Things, vol. 14, pp. 100172, 2021. doi: 10.1016/j.iot.2020.100172. [Google Scholar] [CrossRef]
9. M. Diwakar, A. Tripathi, K. Joshi, A. Sharma, P. Singh and M. Memoria, “A comparative review: Medical image fusion using SWT and DWT,” Mater. Today Proc., vol. 37, pp. 3411–3416, 2021. doi: 10.1016/j.matpr.2020.09.278. [Google Scholar] [CrossRef]
10. H. Talbi and M. K. Kholladi, “Predator prey optimizer and DTCWT for multimodal medical image fusion,” in 2018 Int. Symp. Program. Syst. (ISPS), 2018, pp. 1–6. [Google Scholar]
11. K. Zhan, J. Teng, Q. Li, and J. Shi, “A novel explicit multi-focus image fusion method,” J. Inf. Hiding Multim. Signal Process., vol. 6, no. 3, pp. 600–612, 2015. [Google Scholar]
12. S. S. Khan, M. Khan, Y. Alharbi, U. Haider, K. Ullah and S. Haider, “Hybrid sharpening transformation approach for multifocus image fusion using medical and nonmedical images,” J. Healthc. Eng., vol. 2021, pp. 1–17, 2021. doi: 10.1155/2021/7000991. [Google Scholar] [PubMed] [CrossRef]
13. X. Li and J. Zhao, “A novel multi-modal medical image fusion algorithm,” J. Ambient Intell. Humaniz. Comput., vol. 12, pp. 1995–2002, 2021. doi: 10.1007/s12652-020-02293-4. [Google Scholar] [CrossRef]
14. W. Tan, P. Tiwari, H. M. Pandey, C. Moreira, and A. K. Jaiswal, “Multimodal medical image fusion algorithm in the era of big data,” Neural Comput. Appl., vol. 30, pp. 1–21, 2020. doi: 10.1007/s00521-020-05173-2. [Google Scholar] [CrossRef]
15. R. Bashir, R. Junejo, N. N. Qadri, M. Fleury, and M. Y. Qadri, “SWT and PCA image fusion methods for multi-modal imagery,” Multimed. Tools Appl., vol. 78, pp. 1235–1263, 2019. doi: 10.1007/s11042-018-6229-5. [Google Scholar] [CrossRef]
16. M. Arif and G. Wang, “Fast curvelet transform through genetic algorithm for multimodal medical image fusion,” Soft Comput., vol. 24, no. 3, pp. 1815–1836, 2020. doi: 10.1007/s00500-019-04011-5. [Google Scholar] [CrossRef]
17. X. Li, X. Guo, P. Han, X. Wang, H. Li and T. Luo, “Laplacian redecomposition for multimodal medical image fusion,” IEEE Trans. Instrum. Meas., vol. 69, no. 9, pp. 6880–6890, 2020. doi: 10.1109/TIM.2020.2975405. [Google Scholar] [CrossRef]
18. K. Wang, M. Zheng, H. Wei, G. Qi, and Y. Li, “Multi-modality medical image fusion using convolutional neural network and contrast pyramid,” Sensors, vol. 20, no. 8, pp. 2169, 2020. doi: 10.3390/s20082169. [Google Scholar] [PubMed] [CrossRef]
19. Z. Ding, D. Zhou, R. Nie, R. Hou, and Y. Liu, “Brain medical image fusion based on dual-branch CNNs in NSST domain,” Biomed Res. Int., vol. 2020, 2020. [Google Scholar]
20. Z. Al-Ameen, M. A. Al-Healy, and R. A. Hazim, “Anisotropic diffusion-based unsharp masking for sharpness improvement in digital images,” J. Soft Comput. Decis. Support Syst., vol. 7, no. 1, 2020. [Google Scholar]
21. M. Trentacoste, R. Mantiuk, W. Heidrich, and F. Dufrot, “Unsharp masking, countershading and halos: Enhancements or artifacts?” Comput. Graph. Forum, vol. 31, pp. 555–564, 2012. doi: 10.1111/j.1467-8659.2012.03056.x. [Google Scholar] [CrossRef]
22. H. T. Mustafa, J. Yang, and M. Zareapoor, “Multi-scale convolutional neural network for multi-focus image fusion,” Image Vis. Comput., vol. 85, pp. 26–35, 2019. [Google Scholar]
23. J. Zhao, S. Song, and B. Wu, “An efficient USM weak sharpening detection method for small size image forensics,” Int. J. Netw. Secur., vol. 25, no. 1, pp. 175–183, 2023. [Google Scholar]
24. K. Bhalla, D. Koundal, B. Sharma, Y. C. Hu, and A. Zaguia, “A fuzzy convolutional neural network for enhancing multi-focus image fusion,” J. Vis. Commun. Image Rep., vol. 84, pp. 103485, 2022. doi: 10.1016/j.jvcir.2022.103485. [Google Scholar] [CrossRef]
25. S. S. Khan, M. Khan, and Y. Alharbi, “Fast local laplacian filter based on modified laplacian through bilateral filter for coronary angiography medical imaging enhancement,” Algorithms, vol. 16, no. 12, pp. 531, 2023. doi: 10.3390/a16120531. [Google Scholar] [CrossRef]
26. A. Dogra and S. Kumar, “Multi-modality medical image fusion based on guided filter and image statistics in multidirectional shearlet transform domain,” J. Ambient Intell. Hum. Comput., vol. 14, no. 9, pp. 12191–12205, 2023. doi: 10.1007/s12652-022-03764-6. [Google Scholar] [CrossRef]
27. S. Basu, S. Singhal, and D. Singh, “A systematic literature review on multimodal medical image fusion,” Multimed. Tools Appl., vol. 83, no. 6, pp. 15845–15913, 2024. doi: 10.1007/s11042-023-15913-w. [Google Scholar] [CrossRef]
28. S. S. Khan, M. Khan, and R. S. Khan, “Automatic segmentation and classification to diagnose coronary artery disease (AuSC-CAD) using angiographic images: A novel framework,” in 2023 18th Int. Conf. Emerg. Technol. (ICET), Pakistan, IEEE, Peshawer, 2023, pp. 110–115. [Google Scholar]
29. S. S. Khan, M. Khan, and Q. Ran, “Multi-focus color image fusion using Laplacian filter and discrete fourier transformation with qualitative error image metrics,” ACM Int. Conf. Proc. Ser., pp. 41–45, 2019. doi: 10.1145/3341016. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools