
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Evaluations of Chris-Jerry Data Using Generalized Progressive Hybrid Strategy and Its Engineering Applications
1 Department of Mathematical Sciences, College of Science, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
2 Department of Statistics, Al-Azhar University, Cairo, 11884, Egypt
3 Faculty of Technology and Development, Zagazig University, Zagazig, 44519, Egypt
* Corresponding Author: Ahmed Elshahhat. Email:
(This article belongs to the Special Issue: Incomplete Data Test, Analysis and Fusion Under Complex Environments)
Computer Modeling in Engineering & Sciences 2024, 140(3), 3073-3103. https://doi.org/10.32604/cmes.2024.050606
Received 12 February 2024; Accepted 28 March 2024; Issue published 08 July 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
A new one-parameter Chris-Jerry distribution, created by mixing exponential and gamma distributions, is discussed in this article in the presence of incomplete lifetime data. We examine a novel generalized progressively hybrid censoring technique that ensures the experiment ends at a predefined period when the model of the test participants has a Chris-Jerry (CJ) distribution. When the indicated censored data is present, Bayes and likelihood estimations are used to explore the CJ parameter and reliability indices, including the hazard rate and reliability functions. We acquire the estimated asymptotic and credible confidence intervals of each unknown quantity. Additionally, via the squared-error loss, the Bayes’ estimators are obtained using gamma prior. The Bayes estimators cannot be expressed theoretically since the likelihood density is created in a complex manner; nonetheless, Markov-chain Monte Carlo techniques can be used to evaluate them. The effectiveness of the investigated estimations is assessed, and some recommendations are given using Monte Carlo results. Ultimately, an analysis of two engineering applications, such as mechanical equipment and ball bearing data sets, shows the applicability of the proposed approaches that may be used in real-world settings.Keywords
Numerous researchers have struggled to model lifespan data with a long tail. In recent decades of literature, the oldest common heavy-tailed distributions were exponential, Lindley, and Pareto. A new one-parameter lifetime distribution by mixing two popular distributions, namely, exponential and gamma distributions, called the Chris-Jerry (CJ
and
respectively; see Onyekwere et al. [1]. Also, the respective reliability function (RF) and hazard rate function (HRF) of Y at time
and
In Fig. 1, for specific values of
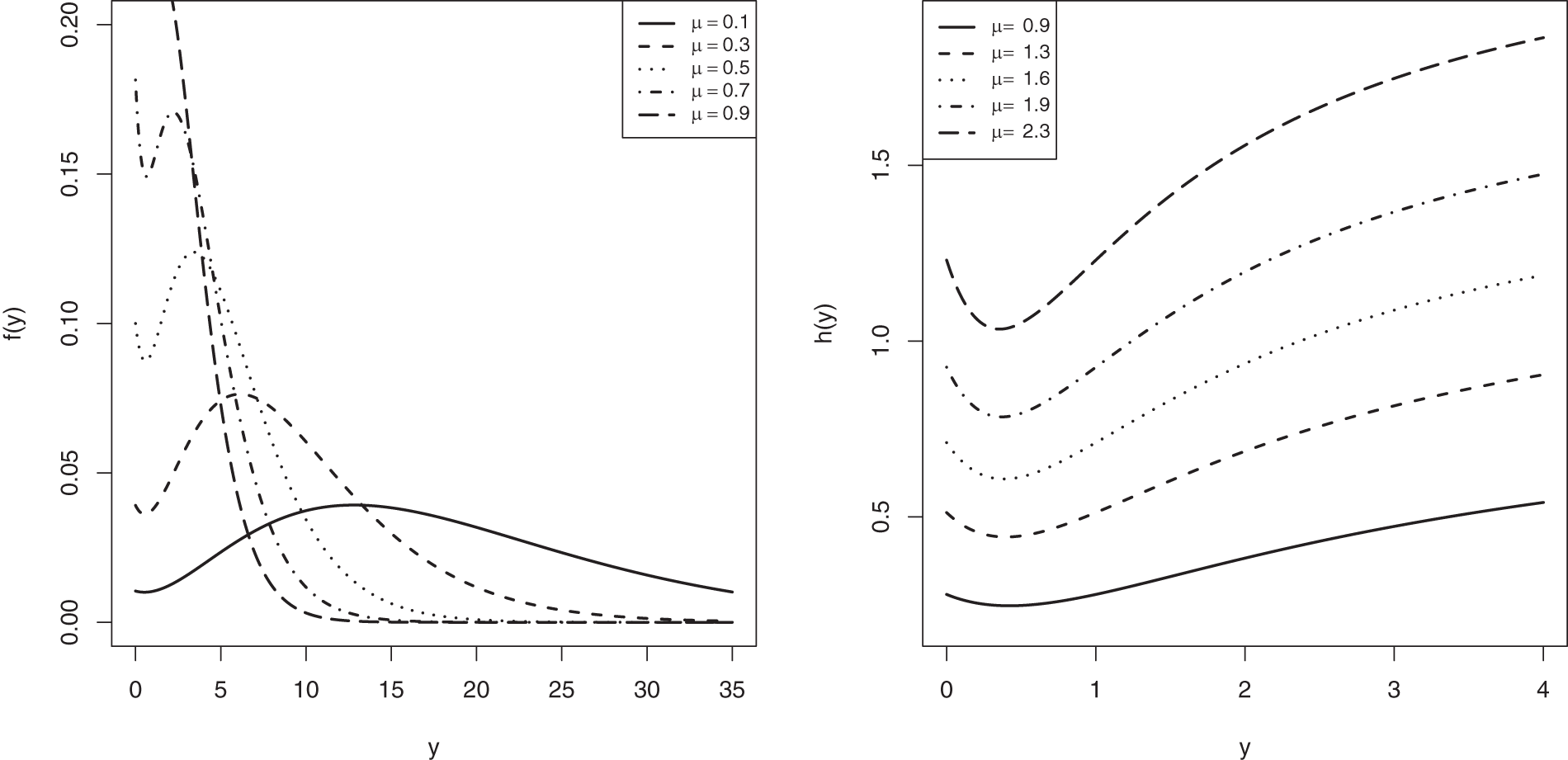
Figure 1: The CJ-PDF (left side) and CJ-HRF (right side) shapes
The reliability practitioner’s goal in life-testing research is to end the test before all of the tested subjects fail. It happens due to financial or time constraints. A hybrid censoring is a system that combines Type-I (time) and Type-II (failure) censoring techniques. One disadvantage of standard Type-I, Type-II, or hybrid censoring methods is that they do not allow units to be withdrawn from the test at locations other than the ultimate termination point; see Balakrishnan et al. [2]. Intermediate removal may be advantageous when a balance between decreased experimental duration and observation of at least some extreme lifespan is desired, or when some of the surviving units in the experiment that are removed early on can be re-purposed for future testing. These reasons and incentives direct dependability practitioners and theorists towards the field of progressive technique.
Progressive censoring Type-II (PC-T2) has been used the most, especially in reliability and survival analyses. It is preferable to the usual Type-II censoring approach. It can be advantageous in numerous scenarios, such as in professional environments and health-care settings. It enables the removal of operational experimental units throughout the experiment. Assume that
If test subjects are very reliable, the PC-T2 has the disadvantage of having an extremely lengthy test time. To overcome this issue, Kundu et al. [4] proposed an alternate kind of censoring termed progressive hybrid censoring Type-I (PHC-T1), in which the examination terminates at
This research is novel as, for the first time, it compares two different methods of determining the CJ distribution for life parameters under imperfect information. Hence, we aim to complete the current work for the following motives:
• The CJ model outperforms various competitor models in the literature, including the exponential, Lindley, and Muth lifespan models, in fitting engineering data sets, as proved later in the actual data section.
• The estimations of the CJ distribution parameters of life under incomplete sampling plans have not been investigated yet in the literature. So, we consider the G-PHC strategy.
• The proposed G-PHC plan is beneficial because it allows for the flexibility of stopping trials at a predefined period and reducing overall test length while keeping the desired features of a progressive system in practice. So, more accurate statistical estimates can be directly deduced from this study.
• The CJ failure rate has a bathtub shape, which is a preferred occurrence in many practical areas.
As far as we understand, no discussion of inferential elements of the CJ distribution exists. Therefore, the purpose of this work, which employs the G-PHC strategy, has the next six objectives:
1. Explore several estimation challenges of the CJ’s parameter (including:
2. Employ an approximation method called Monte-Carlo Markov-chain (MCMC) to evaluate the Bayesian estimations of the CJ parameters using a gamma conjugate prior and the squared error loss.
3. Create the approximate confidence interval (ACI) as well as the highest posterior density (HPD) interval estimates for each unknown quantity.
4. Install ‘
5. Assess the effectiveness of all acquired estimators via a series of numerical evaluations.
6. Examine two engineering applications, based on repairable mechanical equipment and ball bearings data sets, to demonstrate the CJ distribution’s capacity to fit varied data types and adapt the offered methodologies to actual practical circumstances.
The next parts are organized as follows: Section 2 describes the proposed G-PHC plan. Maximum likelihood and Bayes’ estimations are provided in Sections 3 and 4, respectively. Simulation findings are presented in Section 5. Two engineering applications are examined in Section 6. Finally, several conclusions, remarks, and recommendations are listed in Section 7.
This section explains the G-PHC procedure. Let us give
where

Recently, several researchers have done G-PHC-based investigations; for example, Koley et al. [8], Elshahhat [9], Wang [10], Lee et al. [11], Lee [12], Zhu [13], Singh et al. [14], Elshahhat et al. [15], Maswadah [16], later, Alotaibi et al. [17].
We have two limitations in this study, as follows: (i) All inferential methodologies discussed in the next sections are investigated based on the assumption that the quantity
Using (1), (2) and (5), we can express Eq. (5), where
where
As a result, the maximum likelihood estimator (MLE), denoted by
where
Obviously, from (8), the MLE
It is essential to investigate the existence and uniqueness of the MLE
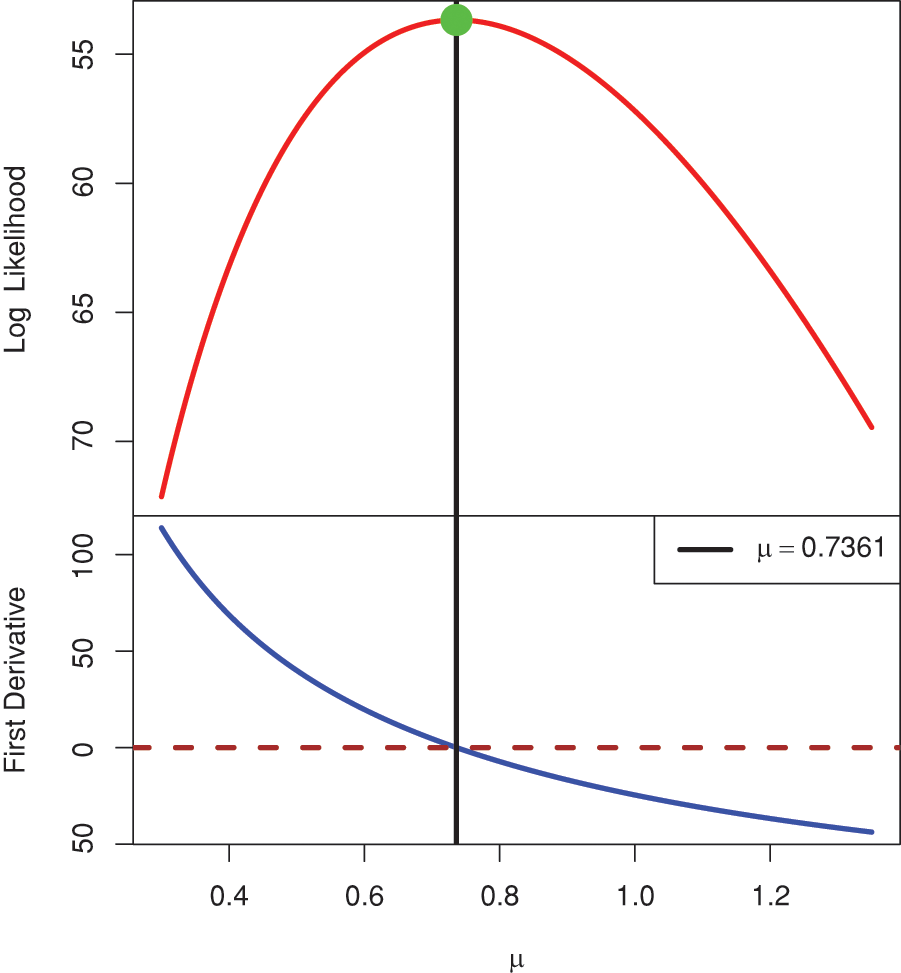
Figure 2: The log-likelihood and normal-equation curves
Once
and
Aside from the point estimate, the
where
Thus, the
where
Additionally, to build the
where
and
As a consequence,
Bayesian setup is an effective method for integrating knowledge in challenging scenarios. Briefly, we report some of its advantages and inconveniences as follows:
• Some advantages of employing Bayesian analysis:
– It offers a natural and logical approach to combining previous knowledge with data inside a strong theoretical framework for decision-making.
– It gives conditional and accurate conclusions without the need for asymptotic approximations.
– It gives interpretable responses and follows the probability principle.
– It offers a suitable environment for a variety of models, including hierarchical models and missing data issues.
• Some inconveniences of employing Bayesian analysis:
– It does not explain how to choose a previous. There is no proper way to select a predecessor.
– It can produce posterior distributions that are heavily influenced by the priors.
– It often comes with a high computational cost, especially in models with a large number of parameters.
– It provides simulations that produce slightly different answers unless the same random seed is used.
However, the major topic of discussion in this part is the Bayesian inference of
Choosing a prior for an unknown parameter might be difficult. In reality, as stated by Arnold et al. [19], there is no accepted method for picking an appropriate prior for Bayesian estimation. Because the CJ parameter
From (6) and (10), the posterior PDF (say
where
Using (11), due to the nonlinear form in (6), the Bayes estimate of
Step 1. Set
Step 2. Put
Step 3. Generate
Step 4. Obtain
Step 5. Obtain a variate
Step 6. If
Step 7. Redefine
Step 8. Set
Step 9. Redo Steps 3–8
Step 10. Find
where
Step 11: Compute the
where
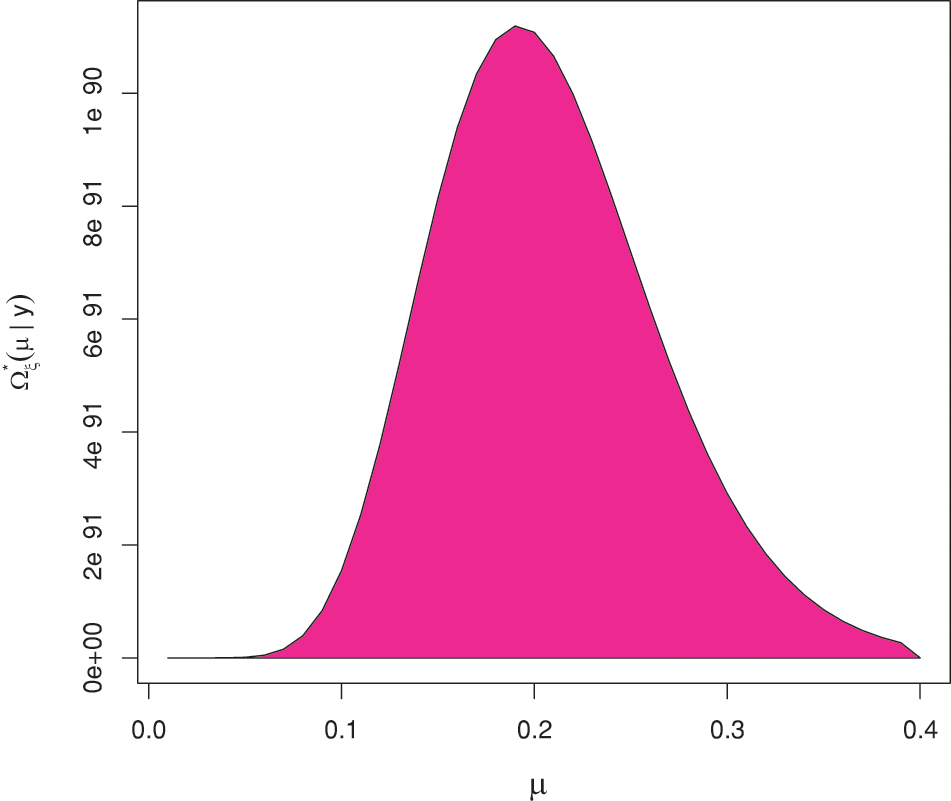
Figure 3: The posterior PDF of
In this part, to assess the accuracy and utility of the acquired estimates of
First, to get the point (or interval) estimate of
where
To get a G-PHC sample from CJ
Step 1. Assign the actual value of
Step 2: Simulate an ordinary PC-T2 sample of size
a. Generate
b. Set
c. Set
d. Set
Step 3.Determine
Step 4. Specify the G-PHC data type as:
a.
b.
c.
As soon as the 1,000 G-PHC samples are collected, the offered frequentist point/interval estimates of
Simulating 12,000 MCMC variates and then burning-in the first 2,000 draws, the Bayes MCMC and 95% HPD interval estimates of

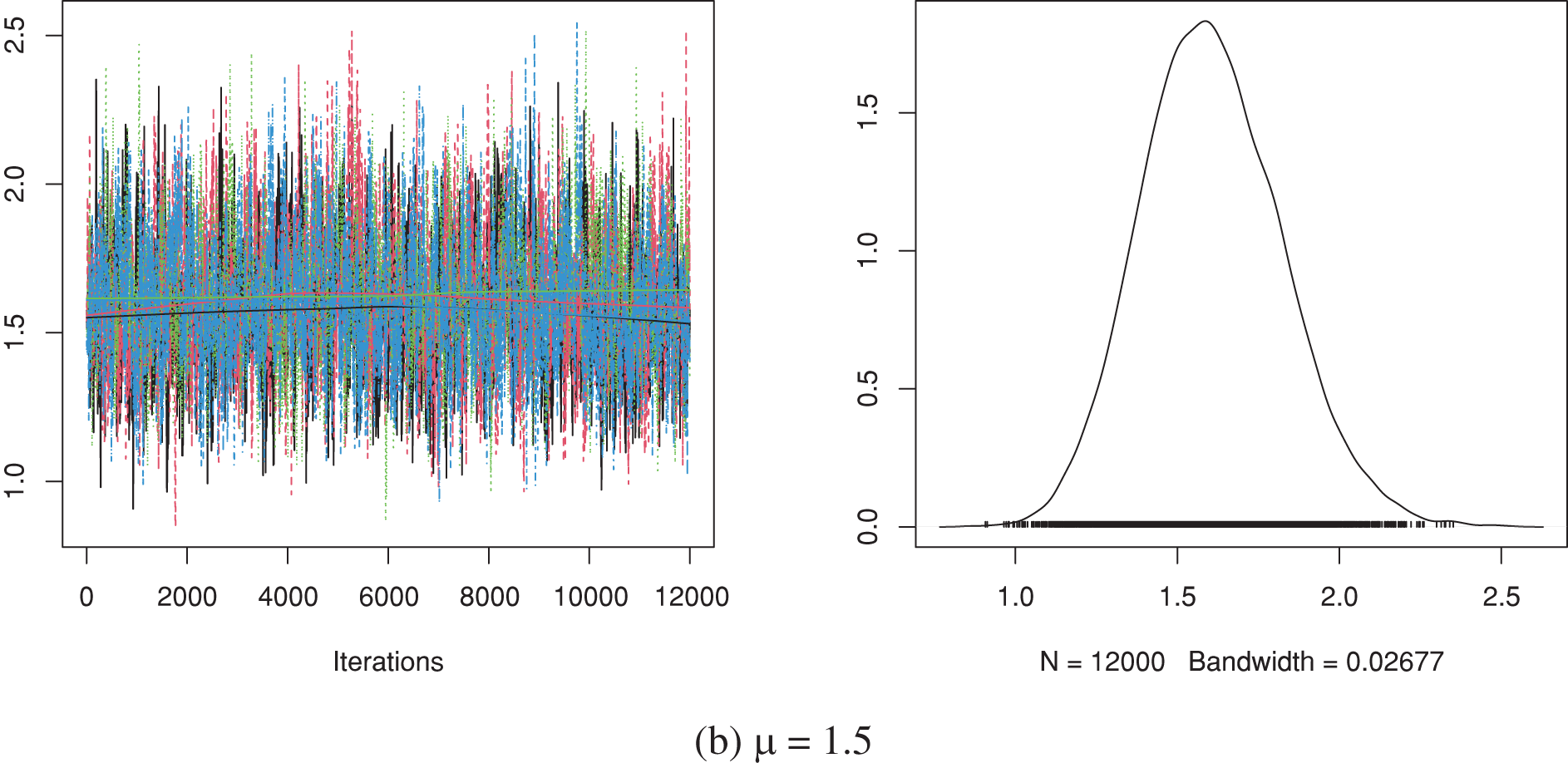
Figure 4: Trace (left) and density (right) diagrams of
Next, we calculate the following quantities of
• Average Point Estimate (Av.PE):
• Root Mean Squared Error (RMSE):
• Mean Relative Absolute Bias (MRAB):
• Average Confidence Length (ACL):
• Coverage Percentage (CP):
• where
5.2 Simulation Results and Discussions
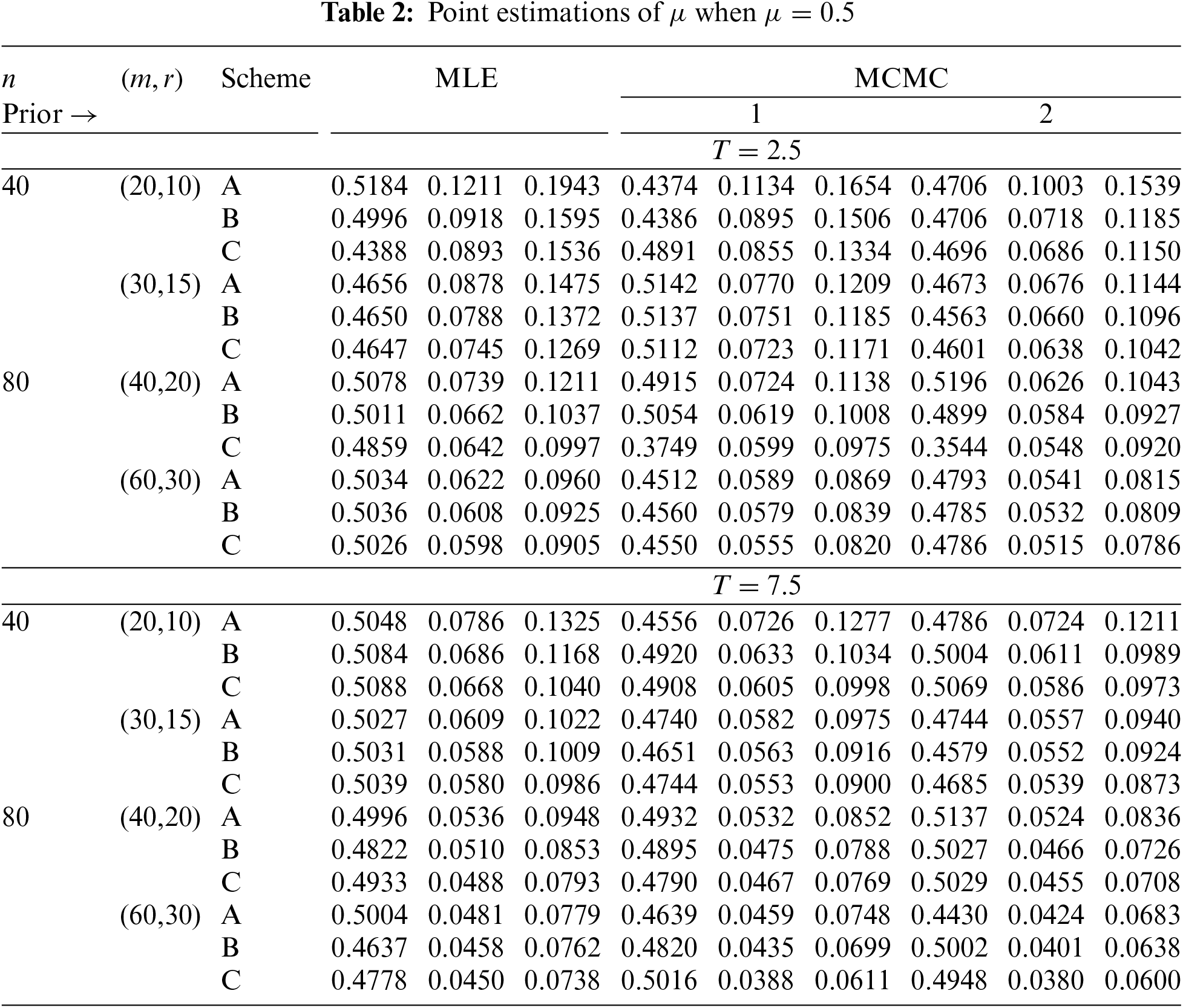
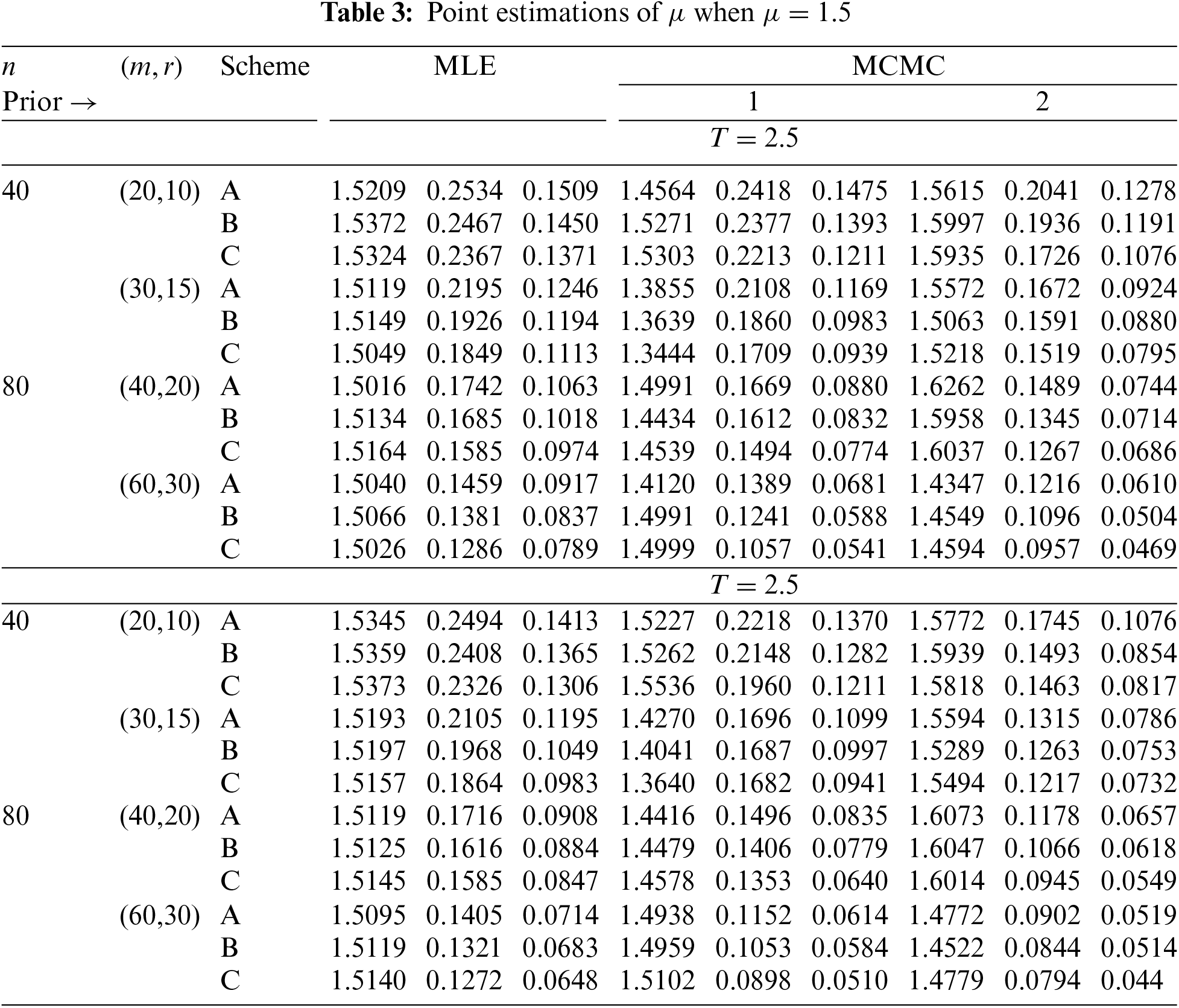
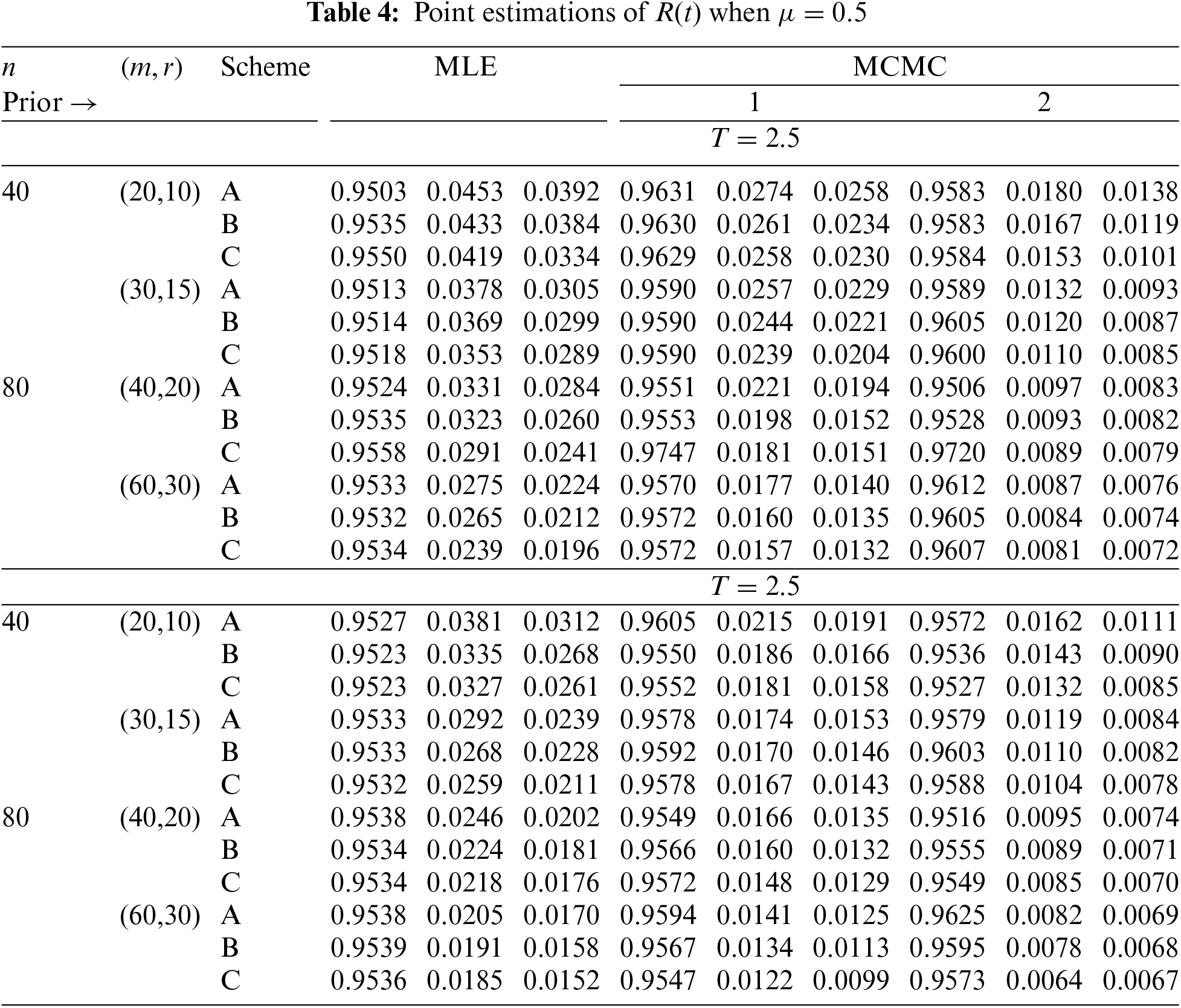
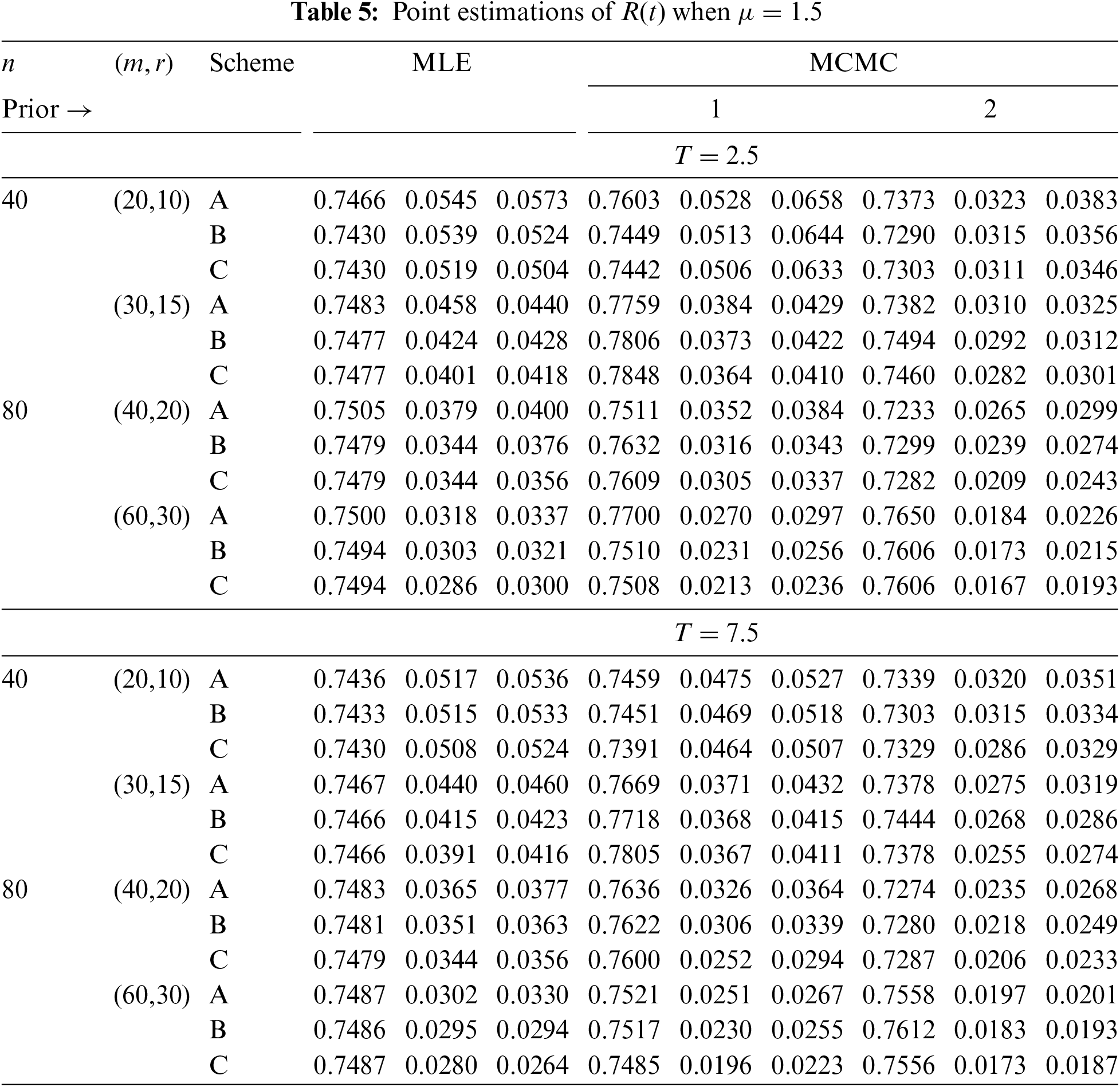
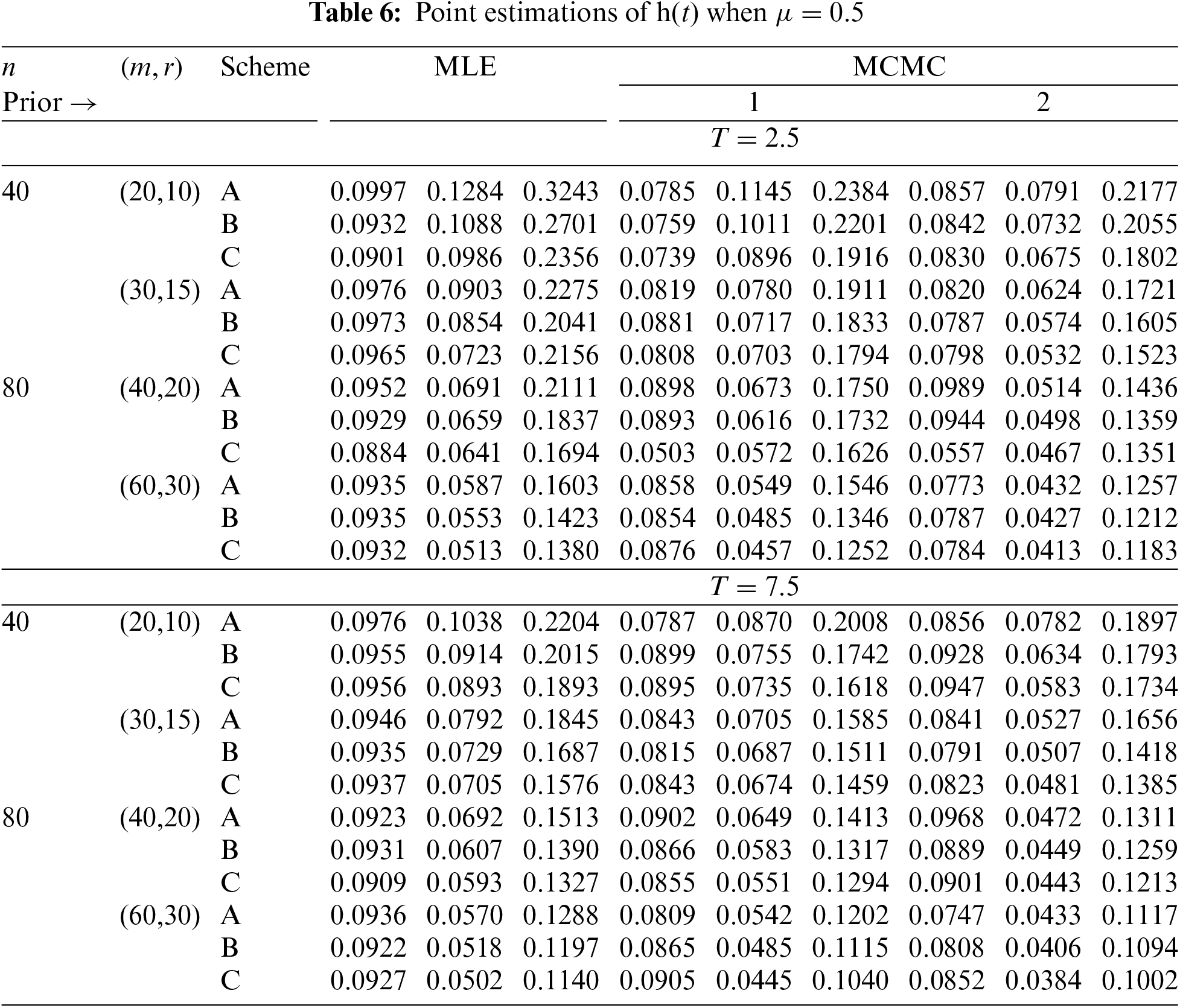
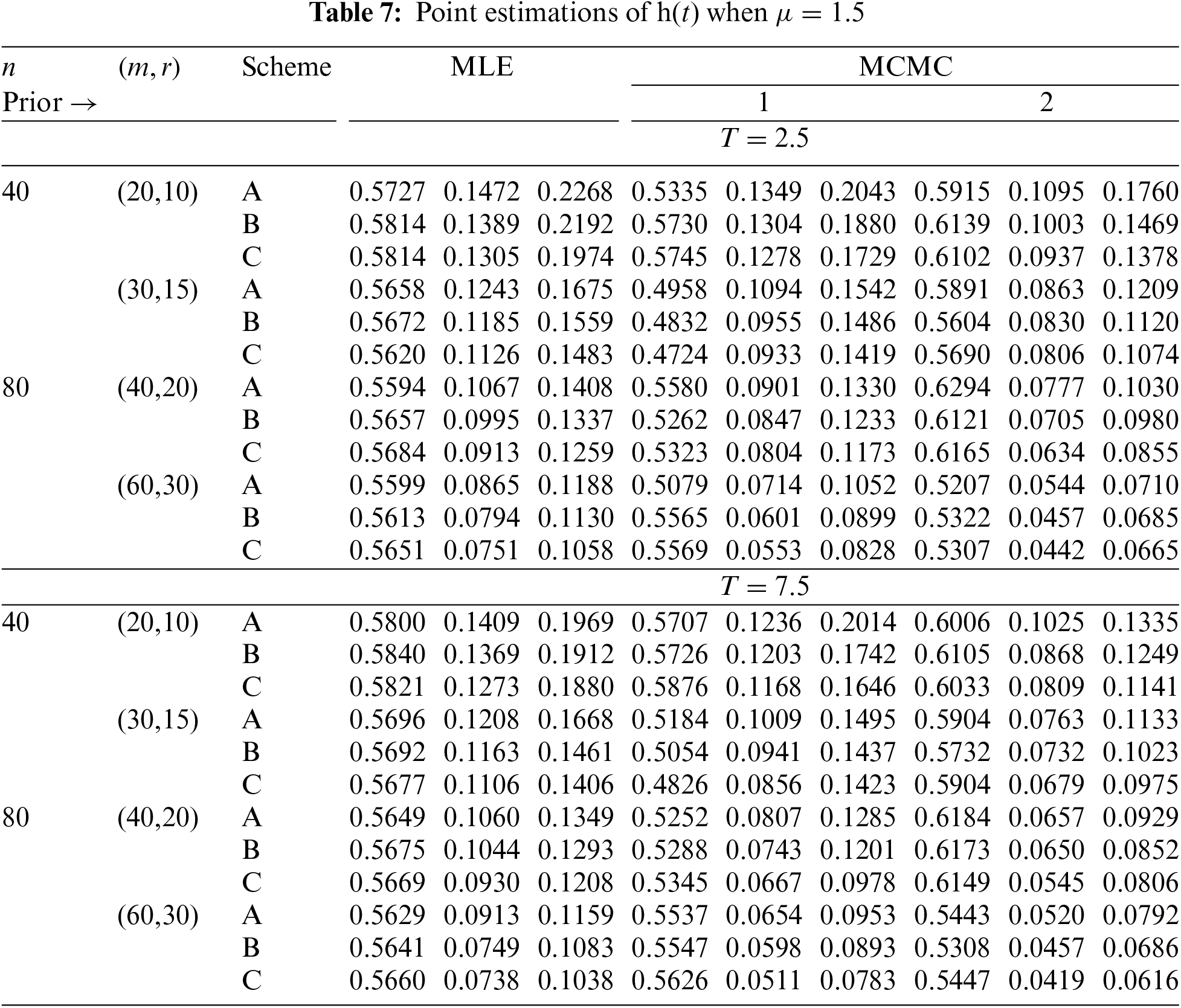
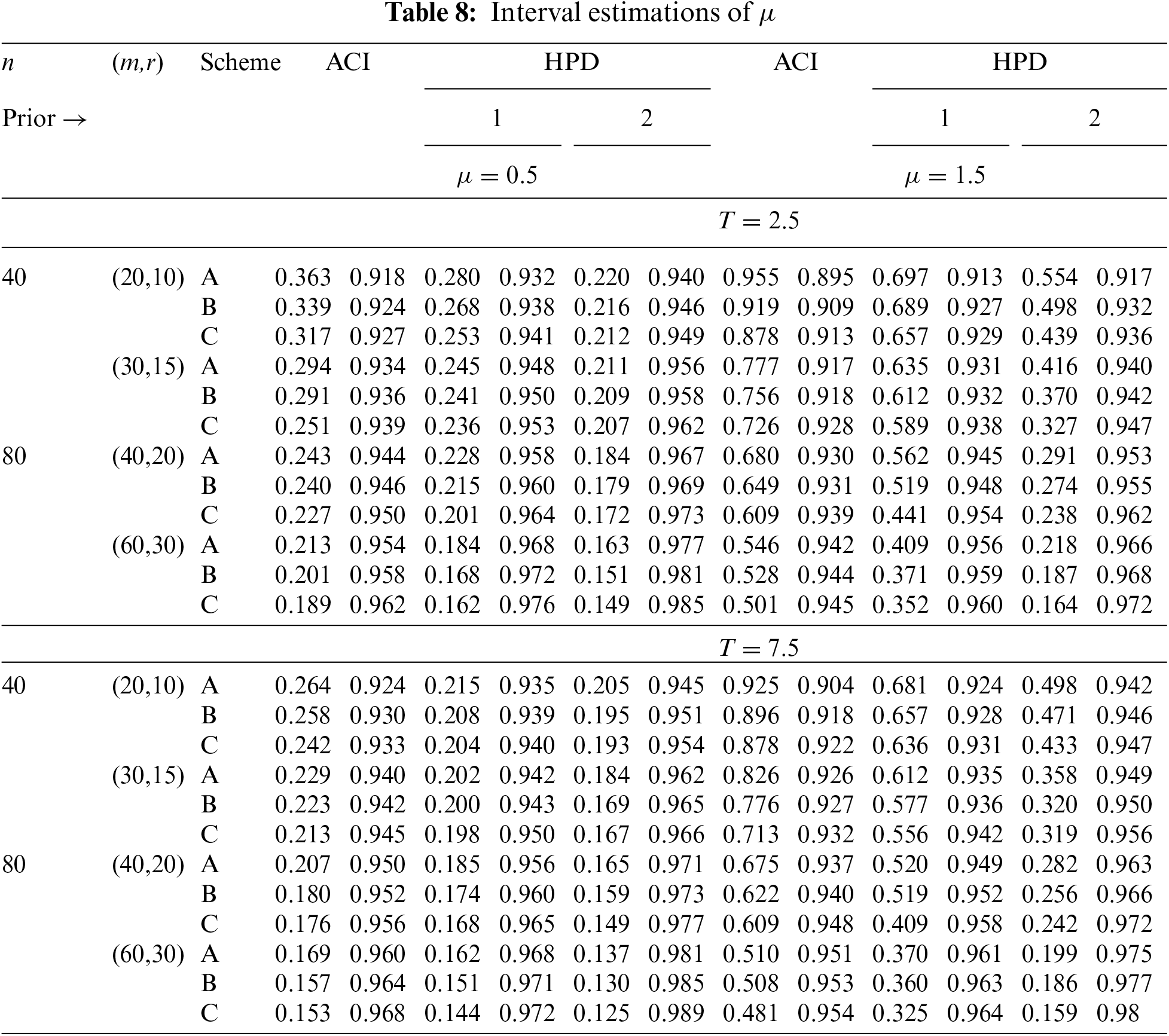
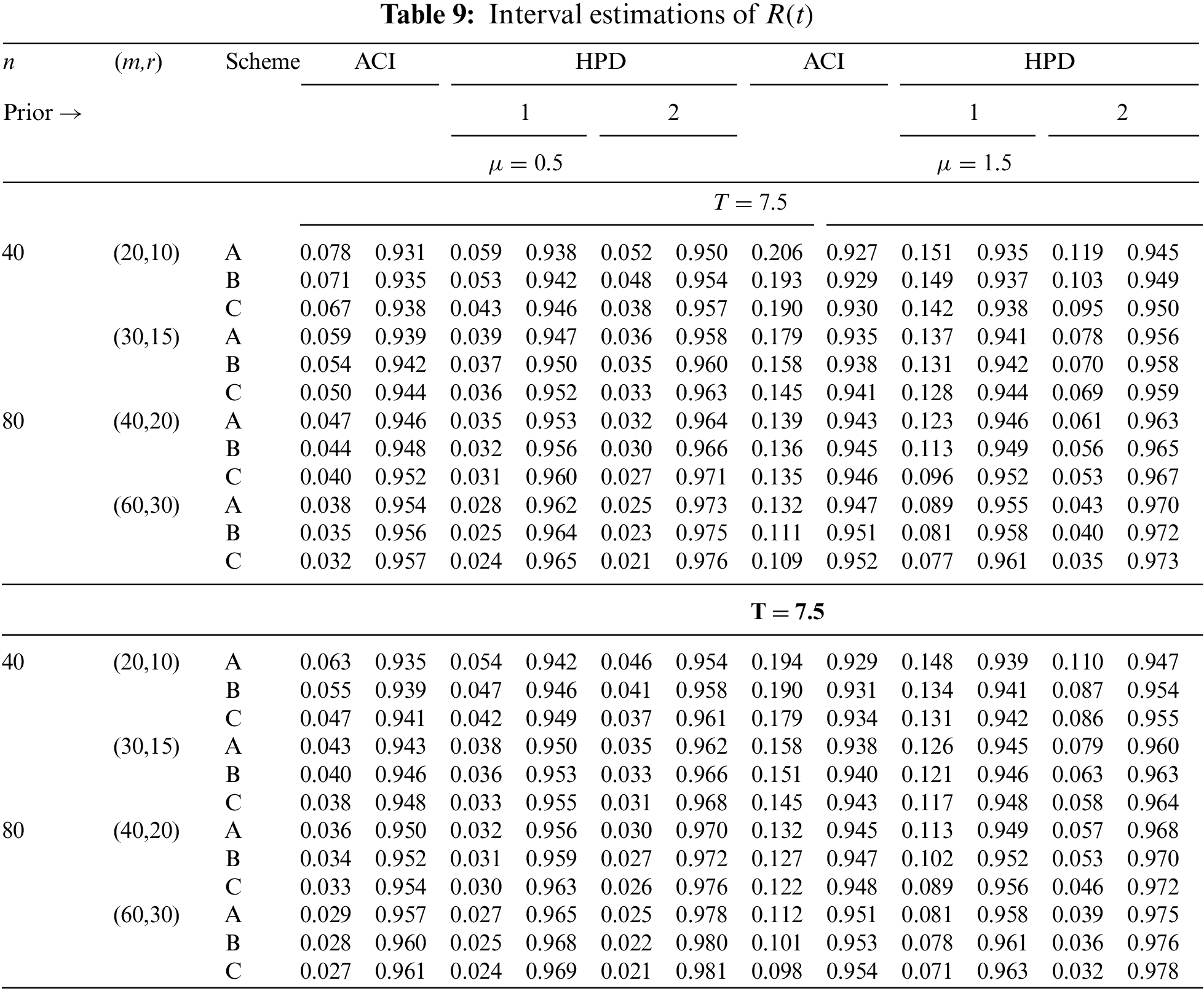
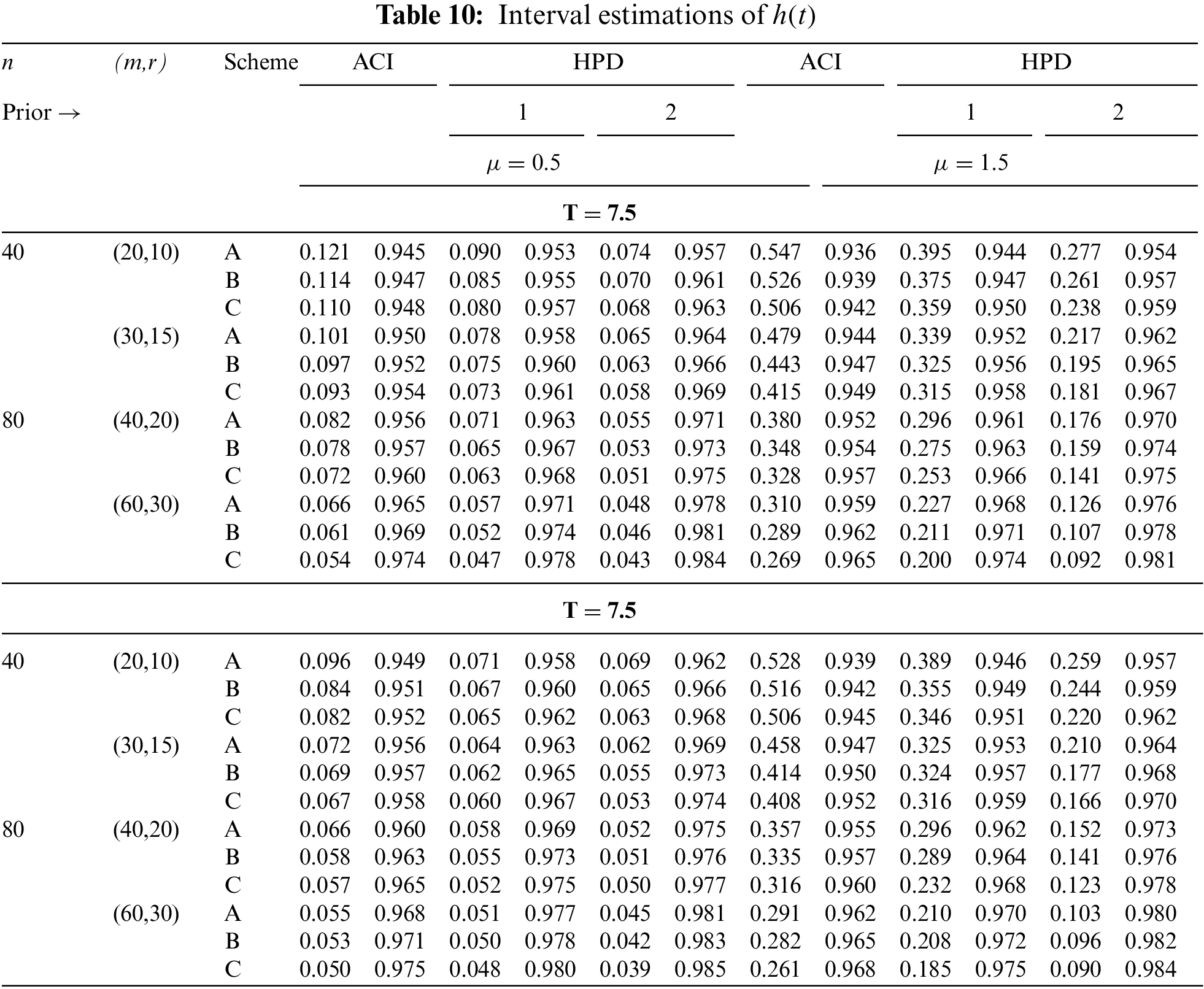
In Tables 2–7, the Av.PEs, RMSEs, and MRABs are reported in the first, second, and third columns, respectively, while in Tables 8–10, the ACLs and CPs are reported in the first and second columns, respectively. Obviously, an effective estimator of
• All acquired results of
• As
• To acquire a highly efficient estimation of
• As T increases, for each value of
• As T grows, for each value of
• As
• As
• In most cases, the simulated CPs of
• Due to the availability of gamma prior information, Bayesian evaluations of
• For each value of
• The HPD interval estimations of
• Comparing the suggested PC-T2 designs A, B, and C, the offered point (or interval) findings using Scheme-C (or conventional Type-II censoring) of all parameters perform better than others.
• To summarize, when the reliability practitioner performs the proposed strategy, it is advised to explore the Chris-Jerry lifetime model using Bayes’ MCMC technique via the Metropolis-Hastings sampler.
This part analyzes two sets of actual data from the engineering field to assess the effectiveness of the estimating methods in practice. In a similar way, without loss of generality, one can easily apply the same proposed methods to other actual datasets from scientific fields, e.g., medicine, physics, chemistry, etc.
To highlight the utility of methodologies proposed for an actual phenomenon, an engineering application representing the failure times for 30 items of repairable mechanical machines (RMM) is analyzed in this subsection; see Table 11. Nassar et al. [23] reanalyzed the RMM data set after it was first provided by Murthy et al. [24].

From the full RMM data, to check the effectiveness of the CJ model, we shall compare its fit to other five models in the literature, namely: XLindley (XL
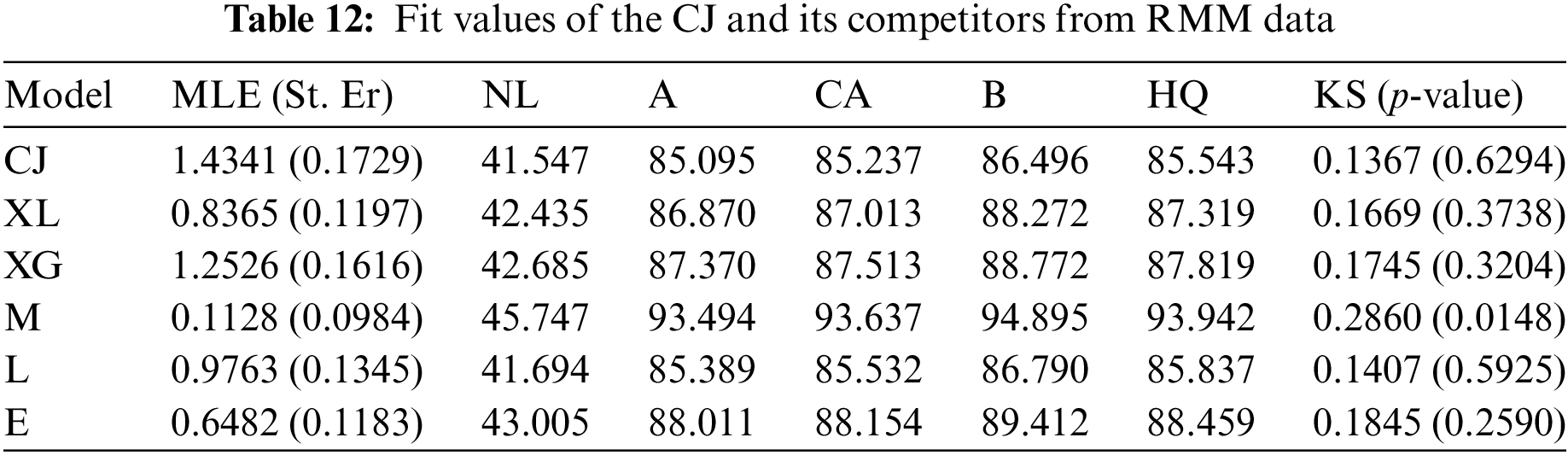
It shows, from Table 12, that the CJ distribution has the best values of all proposed criteria than its competing distributions. So, based on the RMM data, depending on all considered criteria, we decided that the CJ lifespan model is superior to the others. Fig. 5 shows the fitted PDFs, the fitted RFs, and probability–probability (PP) for the CJ and its competing models. As expected, it confirms the numerical findings established in Table 12.
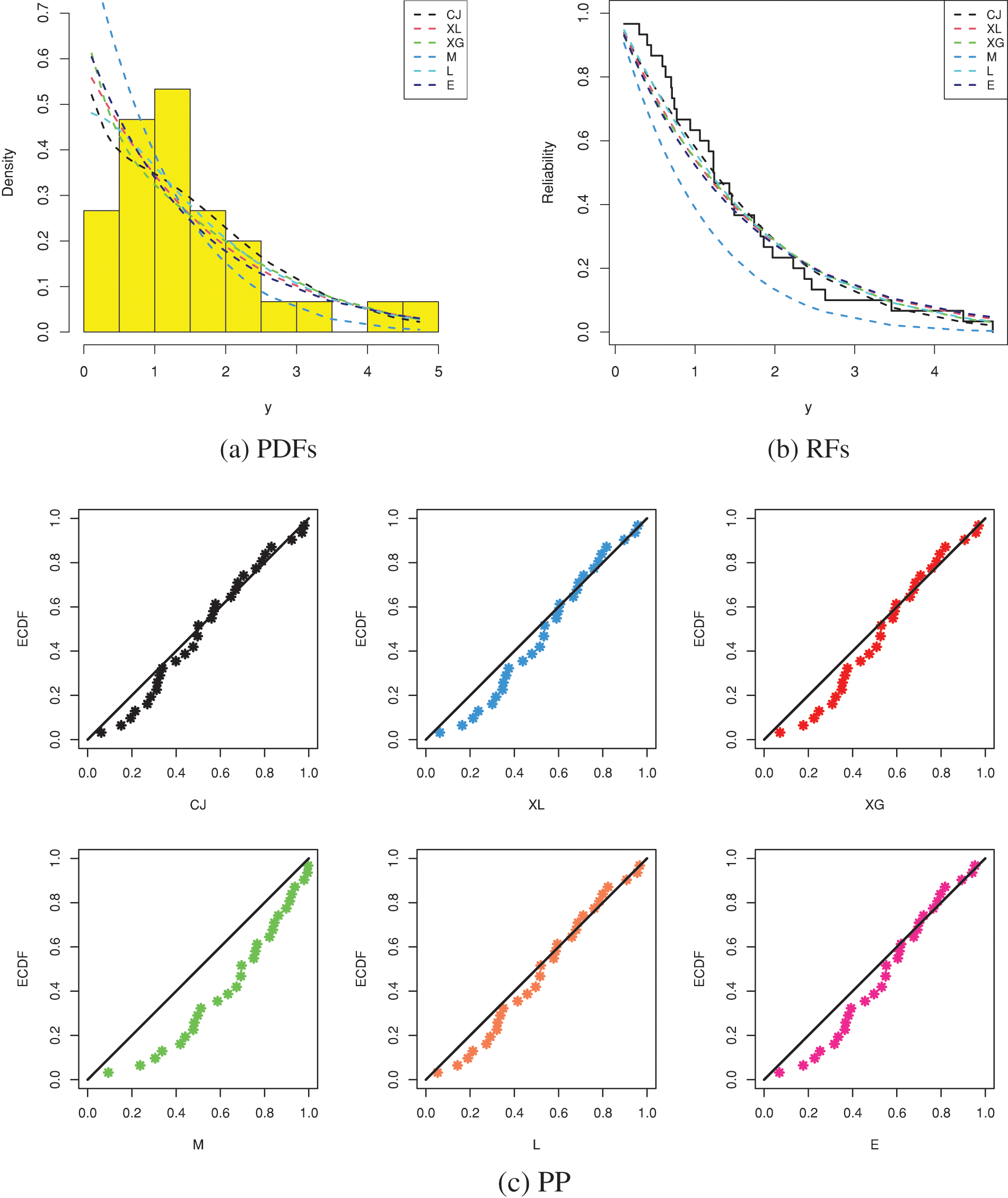
Figure 5: Fitting plots from RMM data
To examine the acquired theoretical estimators of
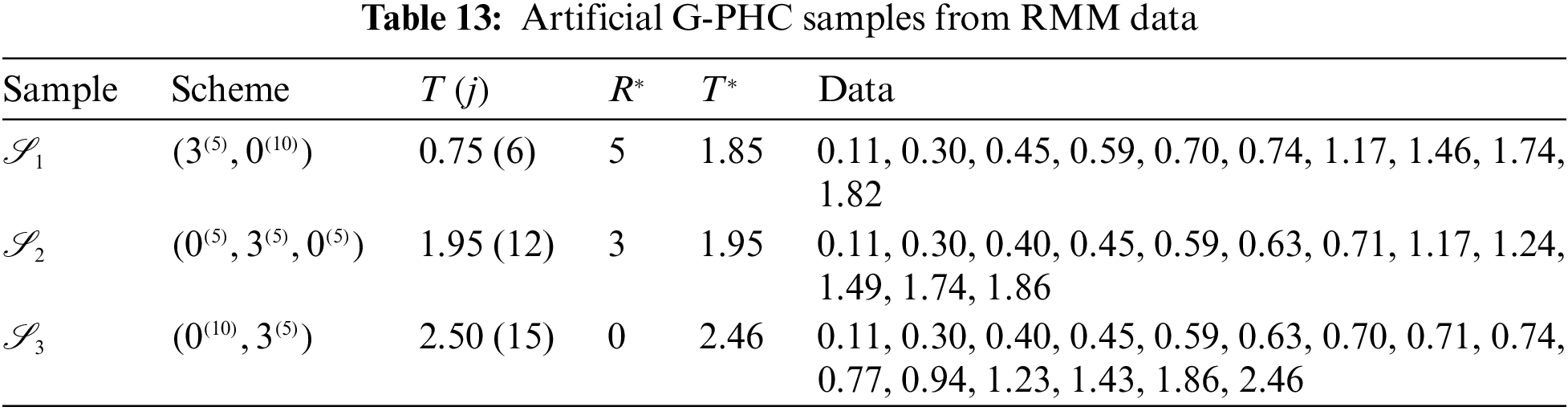
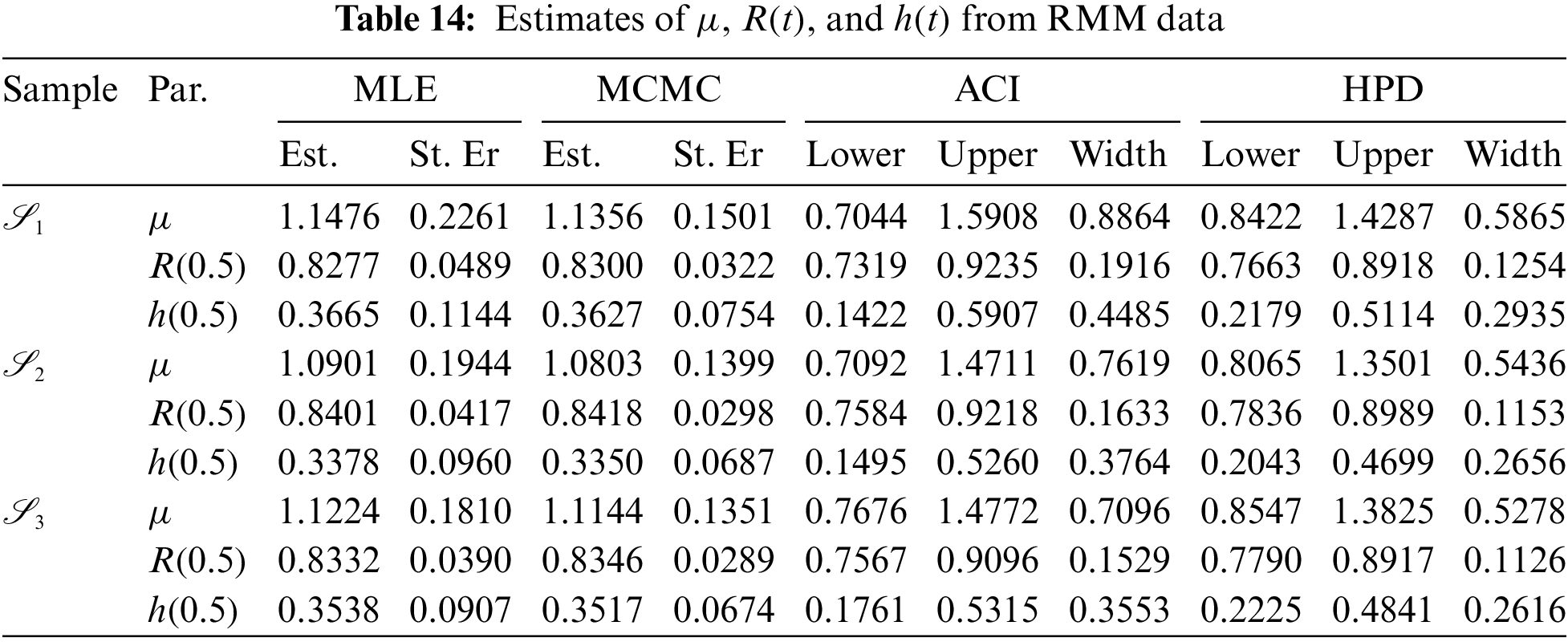
At varying options of
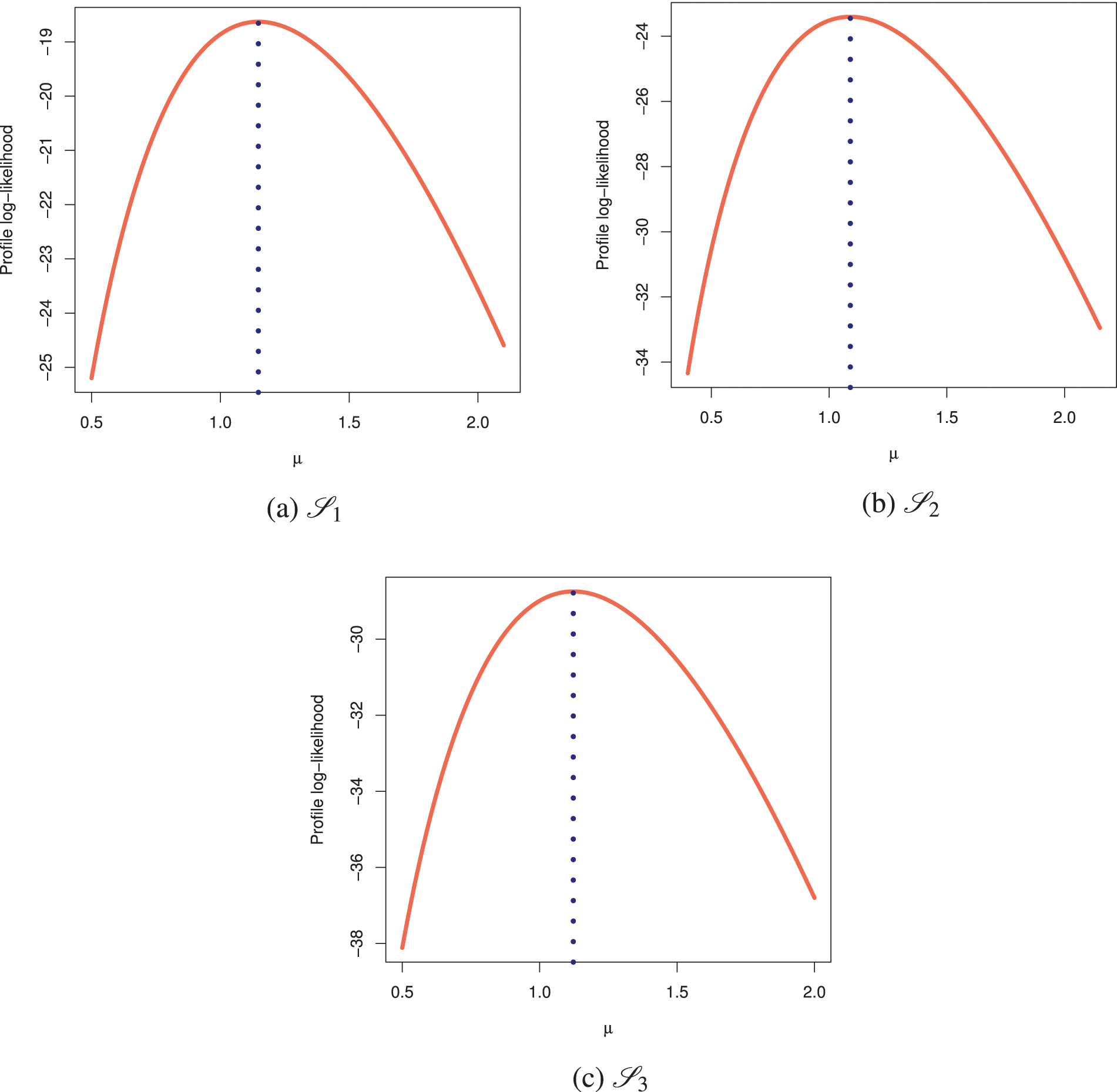
Figure 6: Profile log-likelihoods of
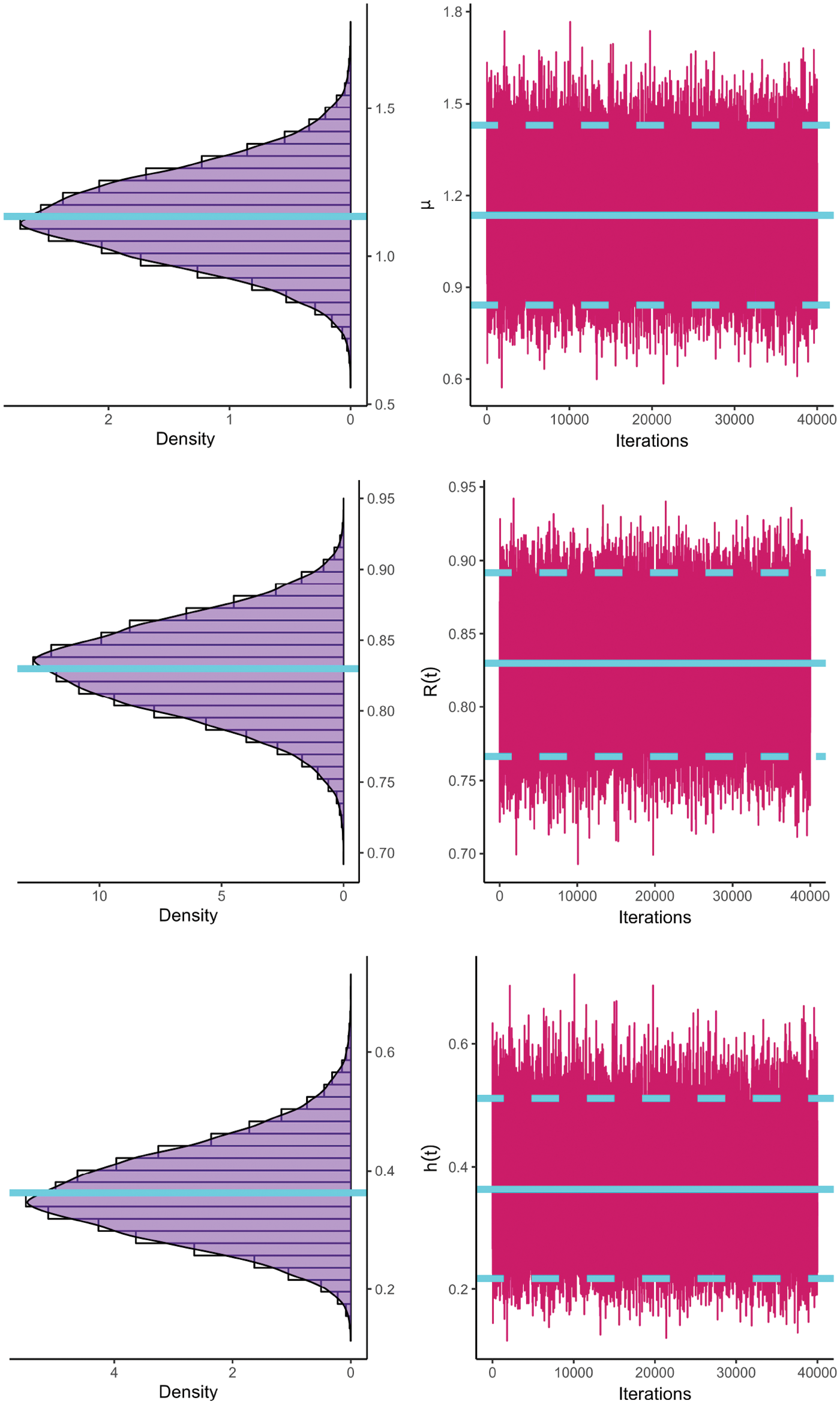
Figure 7: The MCMC plots of
In this part, we analyze real data representing the times 22 ball bearings (BBs) rotated before they stopped after one million rotations; see Table 15. Caroni [30] and Elshahhat et al. [31] examined this dataset. To examine the superiority of the CJ model, using the BBs data set, the suggested CJ distribution will be compared to the XL, XG, M, L, and E lifetime models. Table 16 indicates that the CJ model is the best compared to others due to having the smallest values for all fitted criteria except the highest p-value. Fig. 8 supports this conclusion also.

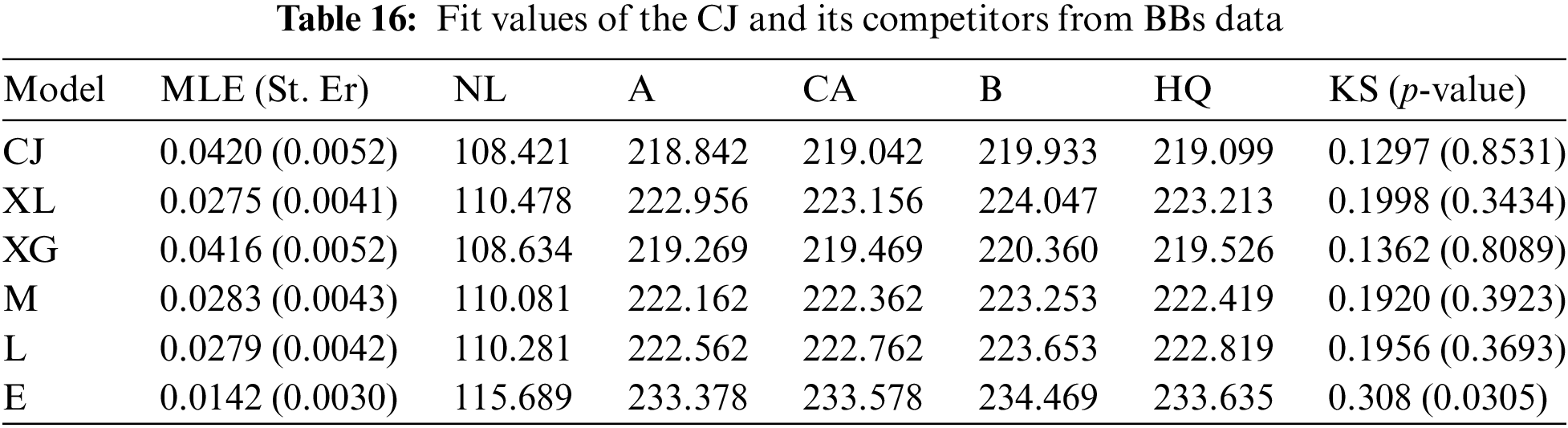
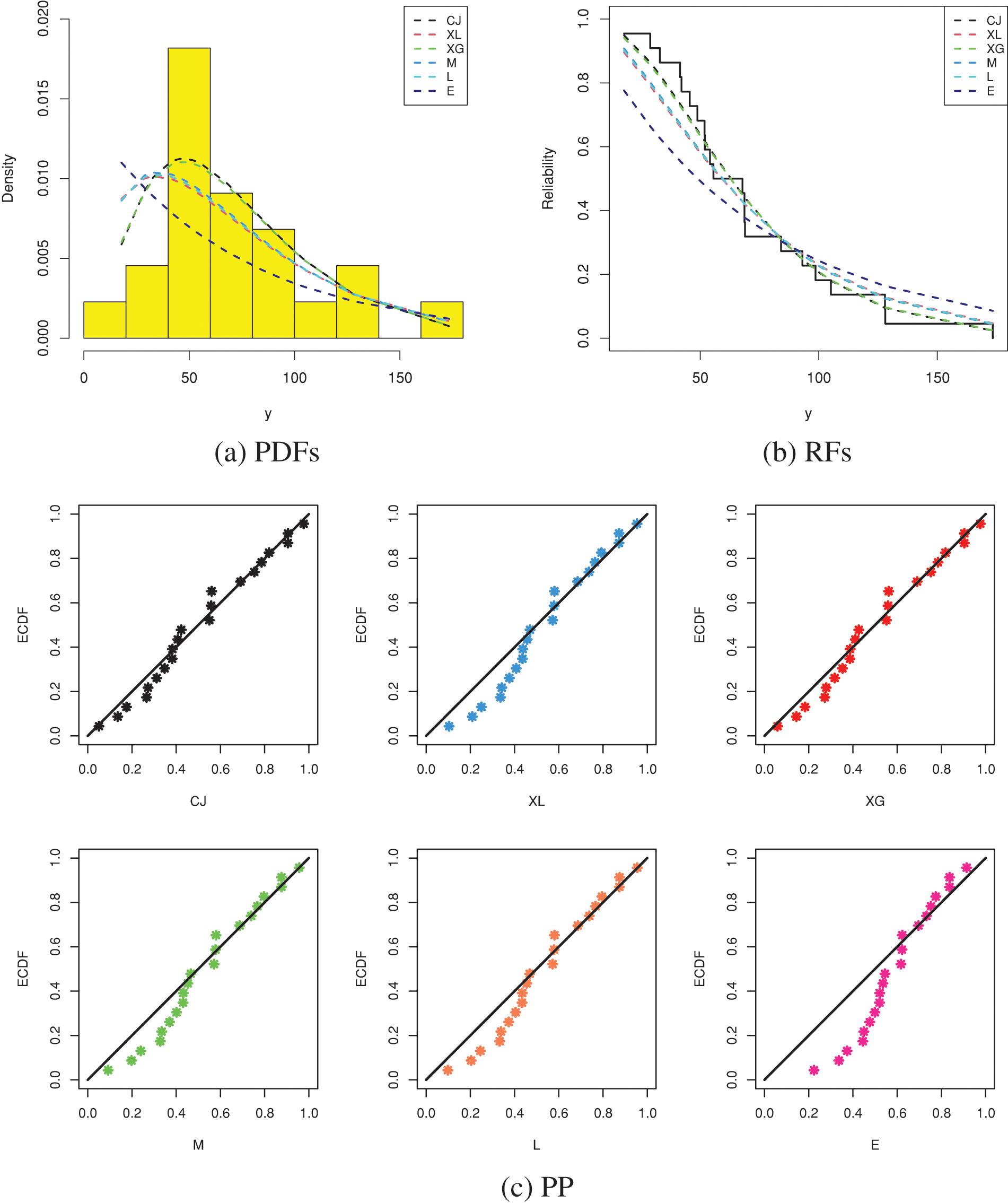
Figure 8: Fitting plots from BBs data
Just like the same estimation scenarios illustrated in Subsection 6.1, from the complete BBs data, different G-PHC samples with fixed
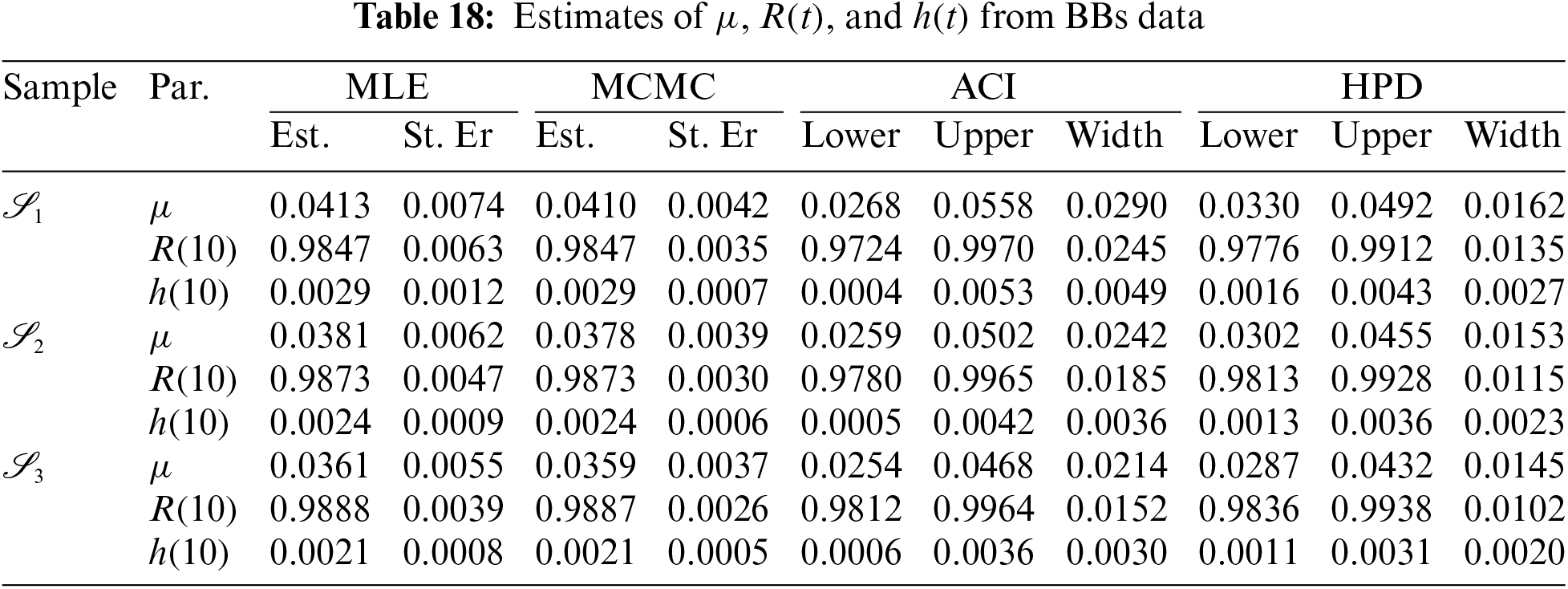
Fig. 9 indicates that the acquired estimates
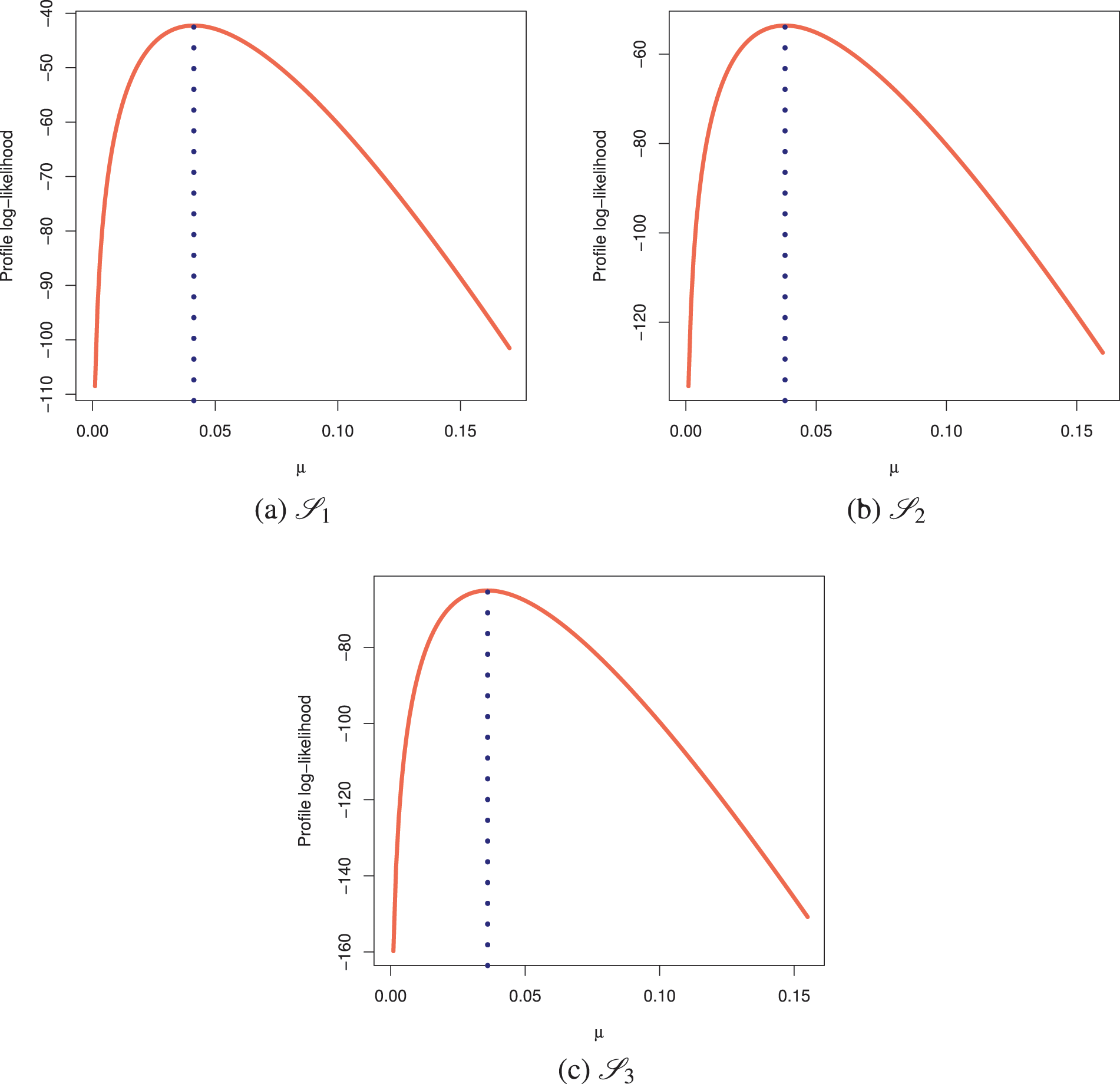
Figure 9: Profile log-likelihoods of
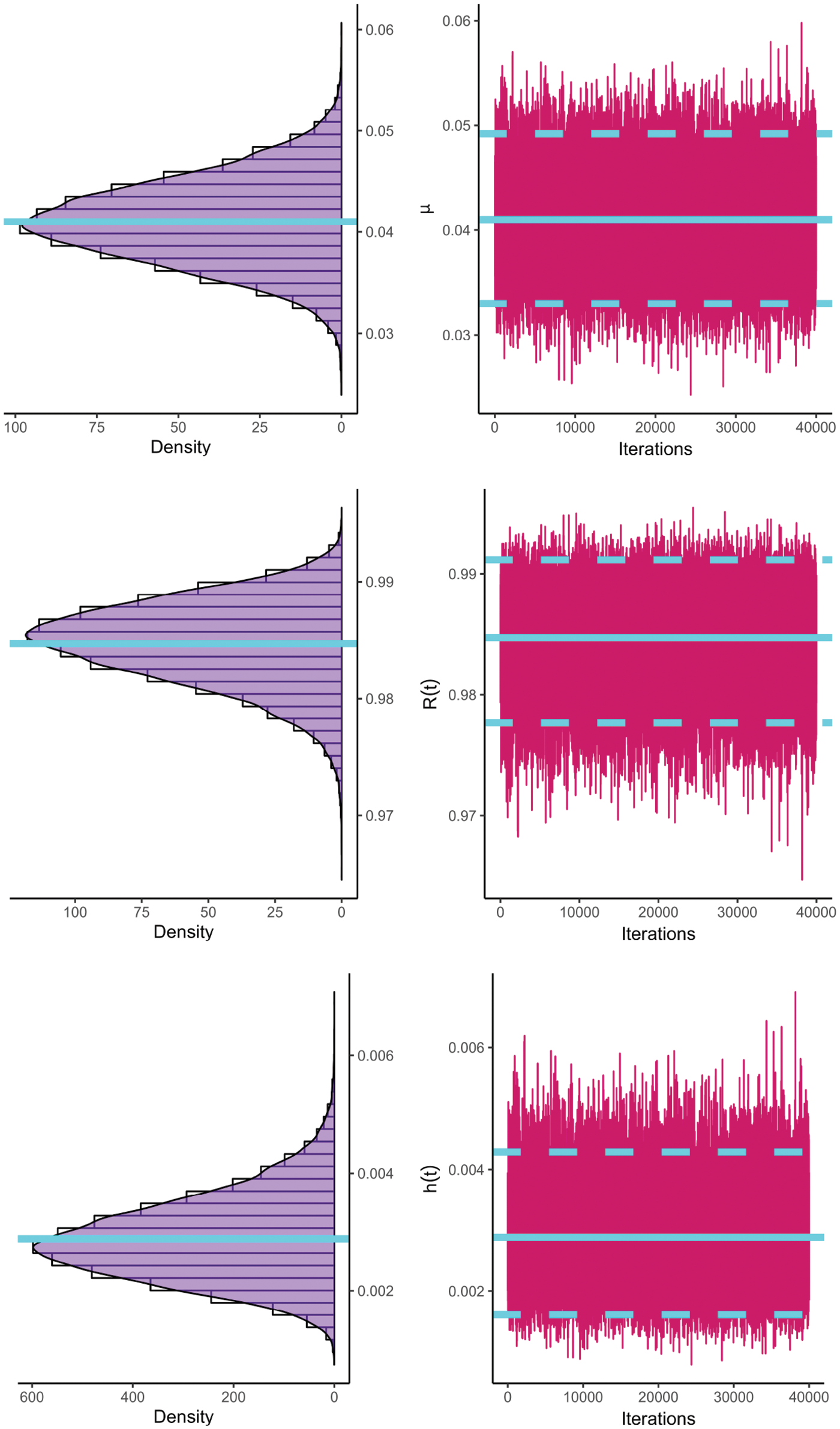
Figure 10: The MCMC plots of
As a result of the G-PHC mechanism, the analysis outcomes from the RMM and BBs data sets comprehensively investigate the Chris-Jerry lifetime model, support the simulation results, and demonstrate the feasibility of the proposed operations in the context of an engineering scenario.
In this study, we investigated different statistical operations for a novel Chris-Jerry distribution using generalized progressively hybrid censored data. Using both maximum likelihood and Bayesian techniques, we explore the model parameter, reliability, and hazard rate functions. The asymptotic characteristics of the frequentist estimates are used to estimate their asymptotic confidence intervals. The gamma prior distribution and squared error loss are incorporated to provide Bayesian estimation. It comes to light that the posterior distribution cannot be directly determined. Therefore, to get the Bayes’ point/interval investigations, the Markov Chain Monte Carlo approach is used. Various scenarios in an extensive Monte Carlo simulation are used to see the behavior of the various approaches and illustrate their applicability. We noticed that the proposed sampling strategy improves conventional and progressive hybrid censoring processes by allowing an examination to go beyond a predetermined inspection time if scarce failures are collected. The simulation findings revealed that, based on such censored data, the Bayesian technique should be used to estimate Chris-Jerry parameters of life. Real data analysis based on repairable mechanical equipment and ball bearing data sets demonstrated that the suggested model behaved better than numerous other traditional models, including XLindley, Lindley, Xgamma, Muth, and exponential distributions. We focused primarily on the Chris-Jerry lifespan in the context of generalized progressively hybrid data. It would also be interesting to look into the estimate of the same distribution parameters in the presence of a competing risk framework or an accelerated life test. The maximum product of the spacing technique and Bayes’ inference through the spacing-based function may also be considered in future research. Further, it is important to compare the proposed symmetric Bayesian method with the asymmetric Bayesian method against Linex, entropy losses, or others. Moreover, the proposed strategy can be discussed in the presence of fault identification and ball bearing diagnosis data; for further details, we refer to Wu et al. [32]. We believe that the findings and techniques presented in this study will be useful to researchers when the recommended strategy is required.
Acknowledgement: None.
Funding Statement: This research was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2024R50), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: R. A., H. R., A. E.; data collection: R. A., A. E.; analysis and interpretation of results: A. E.; draft manuscript preparation: R. A., H. R. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available within the paper.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Onyekwere CK, Obulezi OJ. Chris-Jerry distribution and its applications. Asian J Probability Stat. 2022;20(1):16–30. doi:10.9734/AJPAS/2022/v20i130480 [Google Scholar] [CrossRef]
2. Balakrishnan N, Kundu D. Hybrid censoring: models, inferential results and applications. Comput Stat Data Anal. 2013;57(1):166–209. doi:10.1016/j.csda.2012.03.025 [Google Scholar] [CrossRef]
3. Balakrishnan N, Cramer E. The art of progressive censoring. Birkhäuser, New York, USA: Springer; 2014. [Google Scholar]
4. Kundu D, Joarder A. Analysis of Type-II progressively hybrid censored data. Comput Stat Data Anal. 2006;50(10):2509–28. doi:10.1016/j.csda.2005.05.002 [Google Scholar] [CrossRef]
5. Cho Y, Sun H, Lee K. Exact likelihood inference for an exponential parameter under generalized progressive hybrid censoring scheme. Stat Methodol. 2015;23:18–34. doi:10.1016/j.stamet.2014.09.002 [Google Scholar] [CrossRef]
6. Henningsen A, Toomet O. maxLik: a package for maximum likelihood estimation in R. Comput Stat. 2011;26:443–58. doi:10.1007/s00180-010-0217-1 [Google Scholar] [CrossRef]
7. Plummer M, Best N, Cowles K, Vines K. CODA: convergence diagnosis and output analysis for MCMC. R News. 2006;6:7–11. [Google Scholar]
8. Koley A, Kundu D. On generalized progressive hybrid censoring in presence of competing risks. Metrika. 2017;80:401–26. doi:10.1007/s00184-017-0611-6 [Google Scholar] [CrossRef]
9. Elshahhat A. Parameters estimation for the exponentiated Weibull distribution based on generalized progressive hybrid censoring schemes. Am J Appl Math Stat. 2017;5(2):33–48. doi:10.12691/ajams-5-2-1 [Google Scholar] [CrossRef]
10. Wang L. Inference for Weibull competing risks data under generalized progressive hybrid censoring. IEEE Trans Reliab. 2018;67(3):998–1007. doi:10.1109/TR.2018.2828436 [Google Scholar] [CrossRef]
11. Lee SO, Kang SB. Estimation for the half-logistic distribution based on generalized progressive hybrid censoring. J Korean Data Inf Sci Soc. 2018;29(4):1049–59. doi:10.7465/jkdi.2018.29.4.1049 [Google Scholar] [CrossRef]
12. Lee K. Bayesian and maximum likelihood estimation of entropy of the inverse Weibull distribution under generalized Type-I progressive hybrid censoring. Commun Stat Appl Methods. 2020;27(4):469–86. doi:10.29220/CSAM.2020.27.4.469 [Google Scholar] [CrossRef]
13. Zhu T. Statistical inference of Weibull distribution based on generalized progressively hybrid censored data. J Computat Appl Math. 2020;371:112705. doi:10.1016/j.cam.2019.112705 [Google Scholar] [CrossRef]
14. Singh DP, Lodhi C, Tripathi YM, Wang L. Inference for two-parameter Rayleigh competing risks data under generalized progressive hybrid censoring. Qual Reliab Eng Int. 2021;37(3):1210–31. doi:10.1002/qre.2791 [Google Scholar] [CrossRef]
15. Elshahhat A, Abu El Azm WS. Statistical reliability analysis of electronic devices using generalized progressively hybrid censoring plan. Qual Reliab Eng Int. 2022;38(2):1112–30. doi:10.1002/qre.3058 [Google Scholar] [CrossRef]
16. Maswadah M. Improved maximum likelihood estimation of the shape-scale family based on the generalized progressive hybrid censoring scheme. J Appl Stat. 2022;49(11):2825–44. doi:10.1080/02664763.2021.1924638 [Google Scholar] [PubMed] [CrossRef]
17. Alotaibi R, Elshahhat A, Nassar M. Analysis of Muth parameters using generalized progressive hybrid censoring with application to sodium sulfur battery. J Radiat Res Appl Sci. 2023;16(3):100624. doi:10.1016/j.jrras.2023.100624 [Google Scholar] [CrossRef]
18. Greene WH. Econometric analysis. 4th ed. New York, NY, USA: Prentice-Hall; 2000. [Google Scholar]
19. Arnold BC, Press SJ. Bayesian inference for Pareto populations. J Econ. 1983;21(3):287–306. doi:10.1016/0304-4076(83)90047-7 [Google Scholar] [CrossRef]
20. Asadi S, Panahi H, Anwar S, Lone SA. Reliability estimation of Burr Type III distribution under improved adaptive progressive censoring with application to surface coating. Maintenance Reliability/Eksploatacja i Niezawodnosc. 2023;25(2):163054. doi:10.17531/ein/163054 [Google Scholar] [CrossRef]
21. Nagy M, Bakr ME, Alrasheedi AF. Analysis with applications of the generalized Type-II progressive hybrid censoring sample from Burr Type-XII model. Math Probl Eng. 2022;2022:1–21. doi:10.1155/2022/1241303 [Google Scholar] [CrossRef]
22. Chen MH, Shao QM. Monte Carlo estimation of Bayesian credible and HPD intervals. J Comput Graph Stat. 1999;8:69–92. doi:10.2307/1390921 [Google Scholar] [CrossRef]
23. Nassar M, Elshahhat A. Estimation procedures and optimal censoring schemes for an improved adaptive progressively type-II censored Weibull distribution. J Appl Stat. 2023. doi:10.1080/02664763.2023.2230536 [Google Scholar] [PubMed] [CrossRef]
24. Murthy DP, Xie M, Jiang R. Weibull models. In: Wiley series in probability and statistics. Hoboken, NJ, USA: Wiley; 2004. [Google Scholar]
25. Chouia S, Zeghdoudi H. The XLindley distribution: properties and application. J Stat Theory Appl. 2021;20(2):318–27. doi:10.2991/jsta.d.210607.001 [Google Scholar] [CrossRef]
26. Sen S, Maiti SS, Chandra N. The xgamma distribution: statistical properties and application. J Mod Appl Stat Methods. 2016;15(1):774–88. doi:10.22237/jmasm/1462077420 [Google Scholar] [CrossRef]
27. Irshad MR, Maya R, Arun SP. Muth distribution and estimation of a parameter using order statistics. Stat. 2021;81(1):93–119. doi:10.6092/issn.1973-2201/9432 [Google Scholar] [CrossRef]
28. Ghitany ME, Atieh B, Nadarajah S. Lindley distribution and its application. Math Comput Simul. 2008;78(4):493–506. doi:10.1016/j.matcom.2007.06.007 [Google Scholar] [CrossRef]
29. Tomy L, Jose M, Veena G. A review on recent generalizations of exponential distribution. Biometr Biostat Int J. 2020;9(4):152–6. doi:10.15406/bbij.2020.09.00313 [Google Scholar] [CrossRef]
30. Caroni C. The correct “ball bearings” data. Lifetime Data Anal. 2002;8:395–9. doi:10.1023/A:1020523006142 [Google Scholar] [PubMed] [CrossRef]
31. Elshahhat A, Bhattacharya R, Mohammed HS. Survival analysis of Type-II Lehmann Fréchet parameters via progressive Type-II censoring with applications. Axioms. 2022;11(12):700. doi:10.3390/axioms11120700 [Google Scholar] [CrossRef]
32. Wu Y, Liu X, Wang YL, Li Q, Guo Z, Jiang Y. Improved deep PCA and Kullback-Leibler divergence based incipient fault detection and isolation of high-speed railway traction devices. Sustain Energy Technol Assess. 2023;57:103208. doi:10.1016/j.seta.2023.103208 [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools