
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Proactive Caching at the Wireless Edge: A Novel Predictive User Popularity-Aware Approach
1 College of Computer Science, Chongqing University, Chongqing, 400044, China
2 School of Computer and Software Engineering, Xihua University, Chengdu, 610039, China
3 School of Computer and Information Engineering, Jiangxi Normal University, Nanchang, 330022, China
4 Electric Power Research Institute of State Grid Ningxia Electric Power Co., Ltd., Yinchuan, 750002, China
5 College of Mechanical and Vehicle Engineering, Chongqing University, Chongqing, 400030, China
6 School of Computer Science and Technology, Beijing Institute of Technology, Beijing, 100083, China
7 School of Computer Science and Technology, Dongguan University of Technology, Dongguan, 523808, China
8 School of Emergency Management, Xihua University, Chengdu, 610039, China
9 College of Computer and Information Science, Chongqing Normal University, Chongqing, 401331, China
* Corresponding Author: Yunni Xia. Email:
(This article belongs to the Special Issue: Machine Learning Empowered Distributed Computing: Advance in Architecture, Theory and Practice)
Computer Modeling in Engineering & Sciences 2024, 140(2), 1997-2017. https://doi.org/10.32604/cmes.2024.048723
Received 16 December 2023; Accepted 07 March 2024; Issue published 20 May 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Mobile Edge Computing (MEC) is a promising technology that provides on-demand computing and efficient storage services as close to end users as possible. In an MEC environment, servers are deployed closer to mobile terminals to exploit storage infrastructure, improve content delivery efficiency, and enhance user experience. However, due to the limited capacity of edge servers, it remains a significant challenge to meet the changing, time-varying, and customized needs for highly diversified content of users. Recently, techniques for caching content at the edge are becoming popular for addressing the above challenges. It is capable of filling the communication gap between the users and content providers while relieving pressure on remote cloud servers. However, existing static caching strategies are still inefficient in handling the dynamics of the time-varying popularity of content and meeting users’ demands for highly diversified entity data. To address this challenge, we introduce a novel method for content caching over MEC, i.e., PRIME. It synthesizes a content popularity prediction model, which takes users’ stay time and their request traces as inputs, and a deep reinforcement learning model for yielding dynamic caching schedules. Experimental results demonstrate that PRIME, when tested upon the MovieLens 1M dataset for user request patterns and the Shanghai Telecom dataset for user mobility, outperforms its peers in terms of cache hit rates, transmission latency, and system cost.Keywords
The rapid growth of the Internet of Things (IoT) [1] has spurred the development of MEC [2], a field that has garnered significant attention in the domains of information technology and communication. Traditional mobile networks are ineffective in meeting crucial requirements, such as minimizing latency and content transmission costs due to the distance between service providers and users. The MEC paradigm addresses these challenges by providing robust computing capabilities at Internet access points close to users and offloading computing tasks from remote cloud servers to physical network edge nodes. This approach significantly reduces data transmission latency and achieves high energy efficiency, enabling real-time responsive applications and sensitivity-requiring services.
Edge content caching is an important component of MEC, which further improves the efficiency of resource storage and delivery. The core idea of this technology is to cache frequently accessed content on edge servers close to users to guarantee high responsiveness when content requests arrive and alleviate the traffic from/to remote cloud data centers. This approach improves systems responsiveness and guarantees low latency in content delivery. Consequently, it achieves high quality of experience (QoE) for content requestors as well as a significant portion of requested content can be delivered from nearby storage.
However, existing solutions to edge content caching still need to be improved in several ways. On one hand, the storage capacity of edge servers is usually limited. Given the high user mobility in mobile edge networks [3], previously in-demand content can quickly become outdated. Consequently, static caching schemes often fail to meet content requests when users in MEC are with high mobility. On the other hand, the users’ preference for content demand can also be time-varying in spatial and temporal domains. Content providers are thus supposed to smartly change the caching schemes over time to accommodate such changes to guarantee high hit rates of content.
To address the above challenges, we propose a novel predictive popularity-aware approach for proactive MEC caching, PRIME. PRIME aims to predict the popularity of content among users and cache content over MEC servers in a dynamic MEC environment. PRIME is featured by:
(i) It synthesizes a content popularity prediction model with a deep reinforcement learning model for capturing user mobility and content popularity.
(ii) It is capable of forecasting future content popularity and yield dynamic caching schedules accordingly.
The structure of this paper is organized into the following sections: Section 2 provides a review of related research, Section 3 introduces the system model and problem definition, Section 4 describes the proposed method, and Section 5 presents the performance evaluation results.
With the booming of 5G and MEC technologies, content caching has gained significant attention in academic research in recent years. Particularly in 5G infrastructures using mmWave Massive MIMO systems [4], the constraints on storage, communication, and computational capacities at base stations pose significant challenges due to the increase in latency-sensitive applications. Content caching reduces data access latency, enhances service quality, and decreases core network load by storing popular content closer to users at network edges, thereby improving overall network energy efficiency. The most widely used methods are Least Recently Used (LRU) [5] and Least Frequently Used (LFU) [6], which optimize content storage and management by intelligently deciding caching schedules in terms of plans of content deployment and replacement, at run time.
To further improve storage efficiency in MEC, recently, proactive caching strategies have gained attention [7]. These strategies aim to proactively cache popular content near users by analyzing user preferences. For instance, Garg et al. [8] proposed a strategy for handling unknown and changing content popularity. It utilizes an online prediction method for analyzing the difference in average successful probability (ASP) and an online learning method for minimizing mean squared error and ASP regret. Li et al. [9] considered user mobility by distinguishing between fast and slow-moving users and used a Long Short-Term Memory (LSTM) network for predicting content popularity. Yu et al. [10] leveraged a federated learning model for identifying user interests. Similarly, Qi et al. [11] leveraged a federated learning framework for handling weighted aggregation of personal preferences. Zhang et al. [12] introduced the PSAC algorithm, which employs a self-attention mechanism for reducing network load. It pre-caches content at network edges based on user preferences and further analyzes sequential characteristics of user requests for predicting and re-caching content at the edge. Gao et al. [13] developed a token bucket-based dynamic batching (TBDB) algorithm that dynamically adjusts the maximum batch size (MBS) of cached content for optimizing device utilization and reducing system load. Additionally, Uthansakul et al. [14] designed a hybrid analog/digital precoder and decoder, proposing an alternating optimization algorithm to improve system energy efficiency and compute optimal system parameters. Wei et al. [15] proposed the SAPoC algorithm efficiently manages energy use by determining content popularity based on historical requests and similarities to popular existing content. Gao et al. [16] introduced a neural collaborative sequential learning mechanism deriving sequential information from biased user behavior sequences. Tang et al. [17] developed the Caser method. It transforms user interactions into low-dimensional embeddings and utilizes Convolutional Neural Networks (CNNs) for analyzing local interaction patterns of content requests.
Recently, learning-based methods and algorithms are becoming popular in related works [18]. These models learn to yield intelligent caching schedules through interaction with the environment. For instance, Cai et al. [19] considered user mobility by preemptively transferring user information to the next base station. They employed a Deep Q-Network (DQN) for content caching when such transferring is undergoing. Wu et al. [20] proposed a collaborative caching scheme using an asynchronous federated learning method to gather popular content information and determine the optimal collaborative caching strategy. He et al. [21] introduced a Multi-Agent Actor-Critic (MAAC) strategy empowered by a learning algorithm, where each Road Side Unit (RSU) decides its own caching schedules, enhancing caching efficiency. Somesula et al. [22] proposed a collaborative caching update method based on Multi-Agent Reinforcement Learning and Continuous Deep Deterministic Policy Gradient (MADDPG). Chen et al. [23] developed a collaborative edge caching algorithm that adopts an actor-critic framework for reducing data exchange between agents. Kong et al. [24] aimed to minimize the long-term energy consumption of a caching system by leveraging a DDPG for determining the schedules of computation offloading, service caching, and resource allocation.
3 System Models and Problem Formulation
In this paper, we consider an MEC environment with a central cloud server
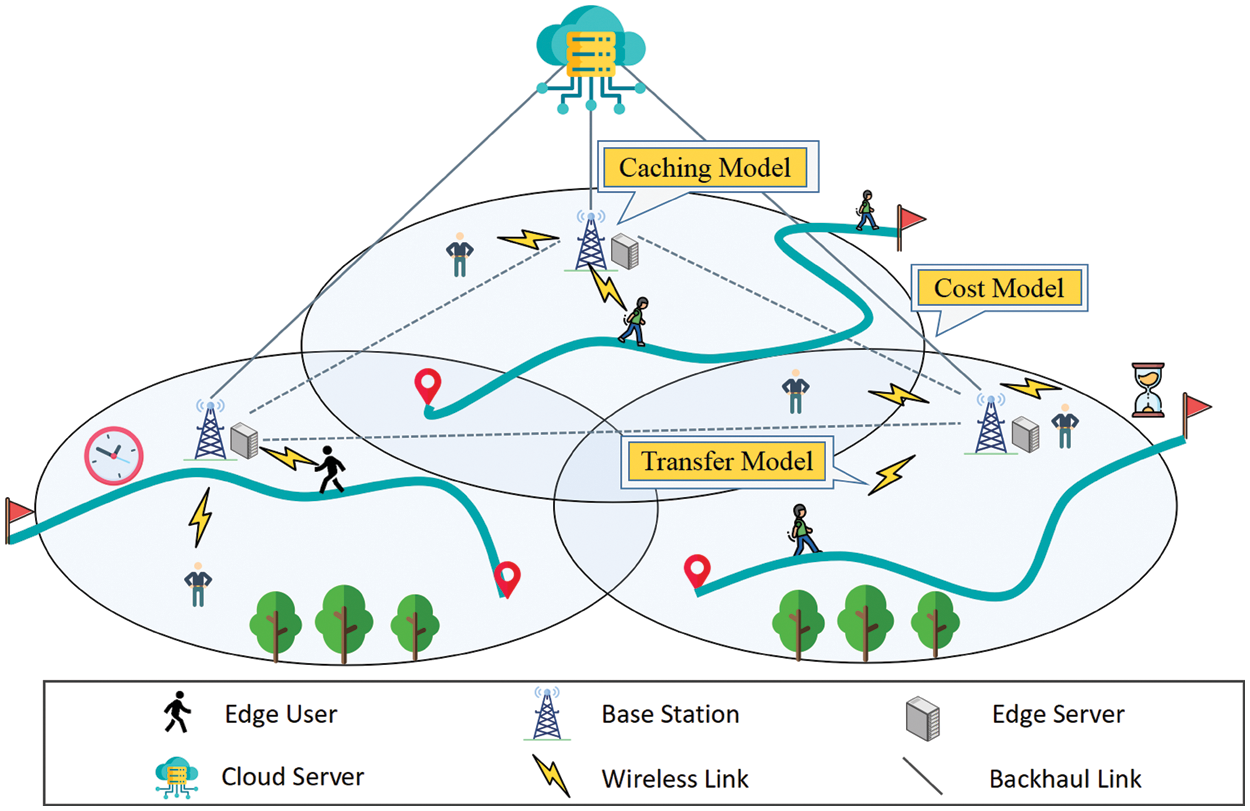
Figure 1: Edge computing system model
The central cloud server

Given edge servers’ limited storage capacity, it is impossible to cache all available content simultaneously. We use
As the caching capacity of a base station is often limited by its total size:
where
At time
According to Shannon’s formula [25], We have the delay of user
where
Therefore, the average request delay for base station
where
The cost model comprises two main components: the cost of proactive caching and the cost of content delivery. In order to improve cache hit rates and minimize user request latency, base stations proactively cache a portion of popular content in the current server and replace unpopular content.
When base station
where
The average cost of proactively caching content at the base station is:
where
The cost of the request,
where BCH represents the basic cost for handling user requests, and
The average system cost of base station
As mentioned earlier, latency is a leading factor in deciding the effectiveness of the caching system. Nevertheless, the goal of reducing latency can usually conflict with other goals, e.g., reducing cost [26]. The objective of this work is thus to reconcile conflicting goals:
where
This chapter provides a comprehensive introduction to the PRIME model, which utilizes content popularity prediction for forecasting the popularity ranking
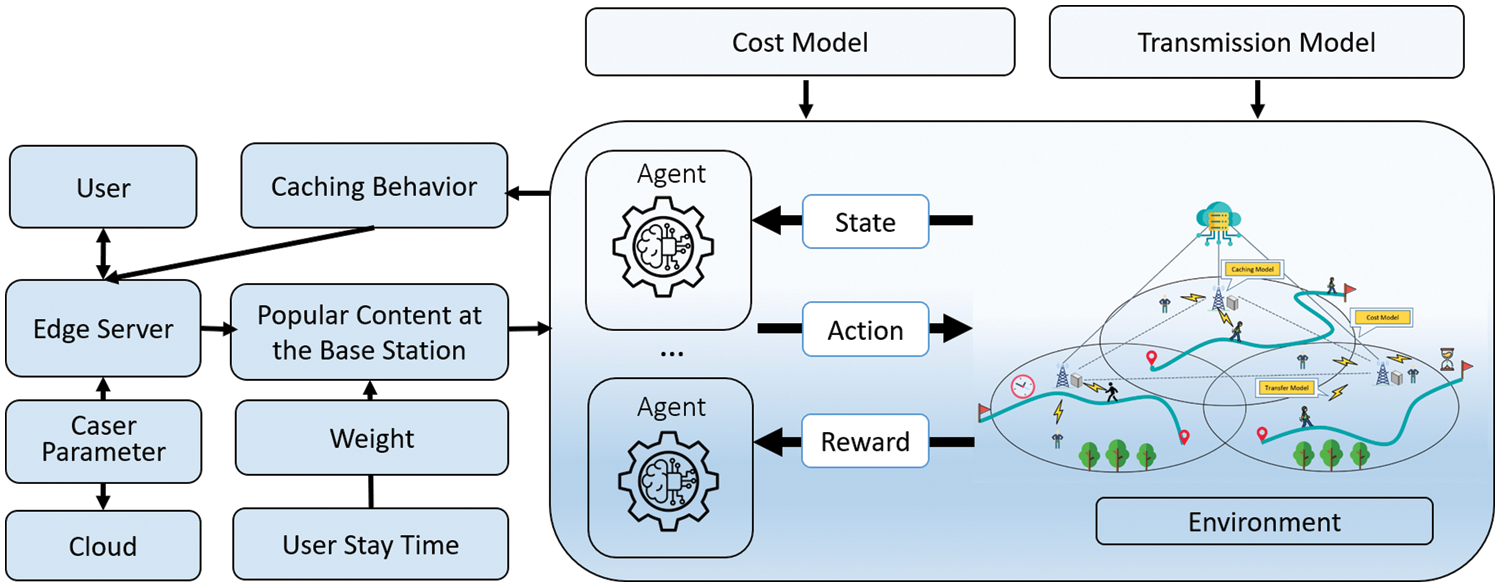
Figure 2: Framework of PRIME for yielding the caching strategy
4.1 Content Popularity Prediction Model
The popularity prediction model takes into account users’ stay time and their request traces, as illustrated in Fig. 3. The model comprises four sequential steps:
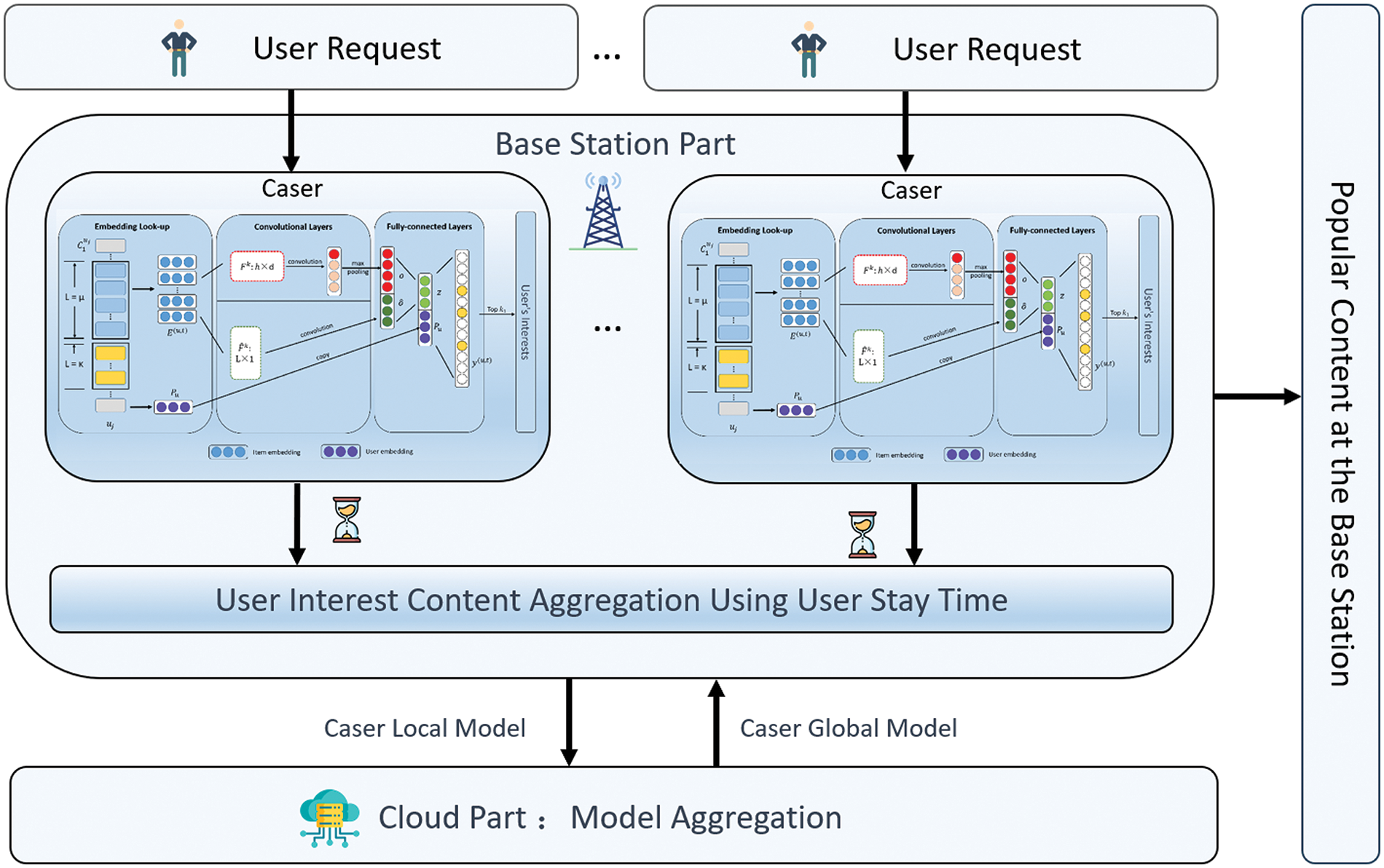
Figure 3: Framework of PRIME for yielding the caching strategy
Global Model Download: At the beginning of each time
Acquiring User-Interest Content: Upon receiving the Caser global model parameters
where
Retrieving Currently Popular Content at the Base Stations: Once the base station obtains the content of interest for all users within its coverage, it weighs these contents to determine the most popular content (Line 11). In this process, the base station employs the stay time of users as an aggregation weight for content, where content requested by users with higher weight is more likely to be cached, according to the stay times of users. This mechanism helps avoid caching content requested by users with short stay times, thus bringing in a high overhead of cache replacement. The stay time of users is estimated according to the coverage radius of the corresponding base station and its mobile trajectory, which falls into such coverage area. The weight is thus:
where
Each base station maintains the weights
Model Aggregation: Upon receiving the local models
where
4.2 Deep Reinforcement Learning for Cache Decision Making
Increasing caching capacity helps improve the user-experienced QoS in terms of cache hit rate but can increase caching cost and energy. Due to capacity limitations, not all popular content can be cached at the base station [29]. It is thus clear that the objectives of minimizing system cost and improving user QoS are conflicting and should be reconciled. To address this challenge, we leverage a DQN, a type of deep reinforcement learning model, to yield high-quality caching plans according to the optimization formulation given in Eq. (10). This approach allows for dynamic adjustment of caching strategies based on learning from user demands and system constraints, as illustrated in Fig. 4. The model comprises the following components:
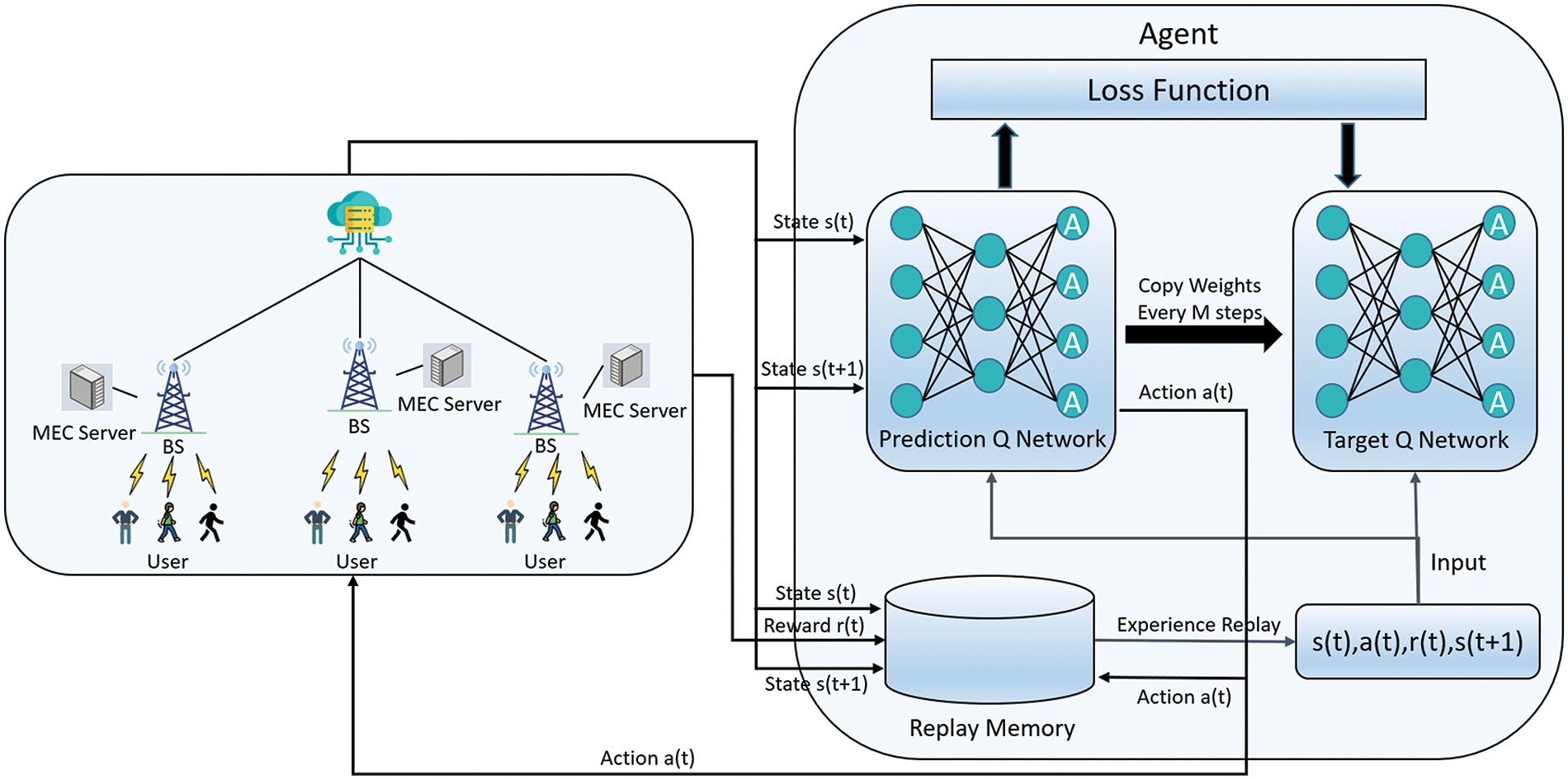
Figure 4: Framework of PRIME for yielding the caching strategy

State: The state space
Actions: We define actions as
Reward: It aims to minimize the cost for each base station with the constraints of user QoS. The reward function is:
where
We employed the DQN reinforcement learning algorithm to dynamically adjust cache content based on users’ historical data and behavior, aiming to optimize system performance. The DQN algorithm, an amalgamation of deep learning and reinforcement learning, utilizes deep neural networks to approximate the Q-function, denoted as
In our study, within the DQN framework, each base station functions as an agent. At each base station
where
where
At the end of time
where

At each time step
In this experiment, we employed two datasets: MovieLens 1M [31] and Shanghai Telecom [32]. The Shanghai Telecom dataset was used to analyze user mobility, which features over 7.2 million content access event records from 9,481 mobile users and 3,233 edge base stations. This dataset also includes detailed mobile trajectory information, as shown in Fig. 5. For training and testing user request patterns for interesting content, we utilized the MovieLens 1M dataset, which comprises around one million ratings from 6,040 anonymous users.
Figure 5: Sample user trajectories of Shanghai Telecom
To simulate user content request processes, we regarded user movie ratings as requests for the corresponding movies [33]. The distribution of users and edge servers is shown in Fig. 6. We selected 3,350 users with at least 80 ratings from MovieLens and paired them with corresponding trajectories from the Shanghai Telecom dataset. The key criterion for this pairing was ensuring that the trajectories in the study area were longer than the users’ rating records, thereby aligning user requests with the study area. The Caser algorithm was pre-trained using the remaining data. Users send requests to the nearest base station when they are within the coverage of multiple edge servers. Other parameters are valued according to [20,34], and are given in Table 2.
Figure 6: Partially selected user trajectory and base station deployment locations
We compare our method against four baselines:
1) Baseline Algorithm 1 (BA1) [19]: A wireless edge caching method based on deep reinforcement learning. This method determines content to be cached according to the uneven distribution of file popularity and user mobility.
2) Baseline Algorithm 2 (BA2) [9]: A cooperative caching method that utilizes LSTM networks for predicting content popularity. It leverages the content size-based weights for trading off content popularity and size’s impact. It takes the mobility of users as inputs for yielding caching schedules.
3) First-In-First-Out Scheme (FIFO): Base stations cache content in the order of content requests and discard the earliest cached content when the cache space is exhausted.
4) Random: Base stations randomly cache a portion of the content.
Fig. 7 compares cache hit rates of different methods with varying cache capacities. As the edge server capacity increases, base stations can cache more content, thereby enhancing the opportunities for users to access resources from local edge servers and neighboring edge servers. Consequently, the hit rates increase with the capacity. PRIME outperforms FIFO, BA1, and BA2 strategies in terms of edge cache hit rate by 45.11%, 15.69%, and 9.08% on average, respectively.
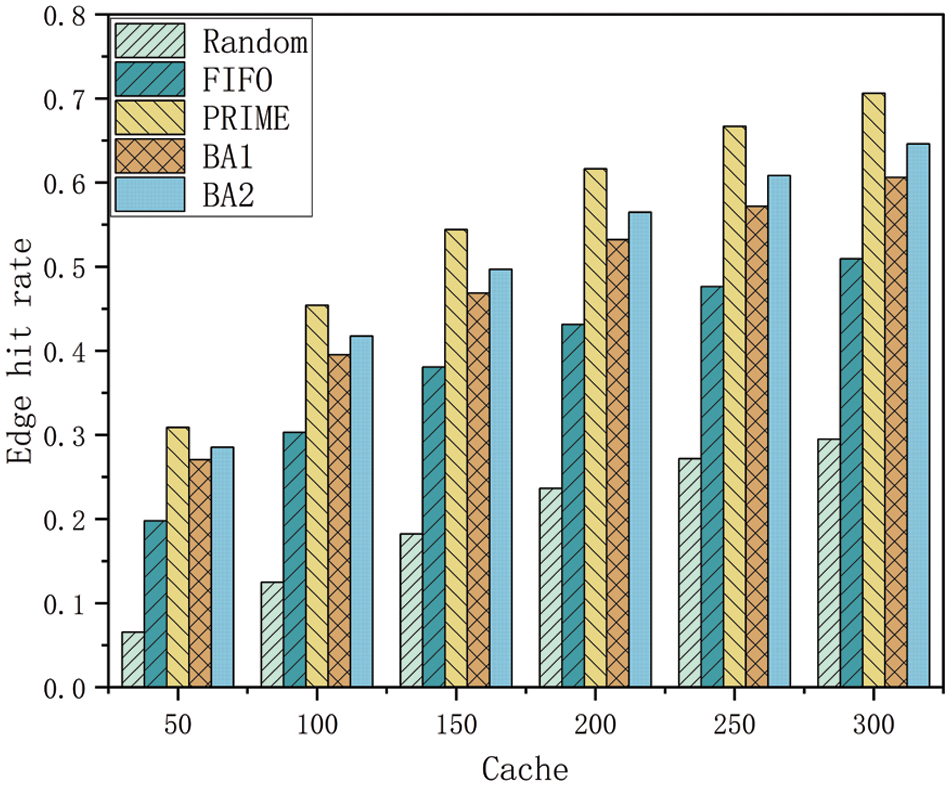
Figure 7: Capacity and edge hit rate
Fig. 8 displays the average request latency for different cache strategies with varying cache capacities. It is clear that PRIME achieves lower latency than its peers. As the cache capacity of the edge server increases, the request latency decreases for all cache strategies. This is because a larger cache capacity increases the likelihood of mobile users accessing content from local and nearby servers, thereby reducing the request latency. PRIME outperforms Random, FIFO, BA1, and BA2 by 30.24%, 17.28%, 8.43%, and 5.31%, respectively.
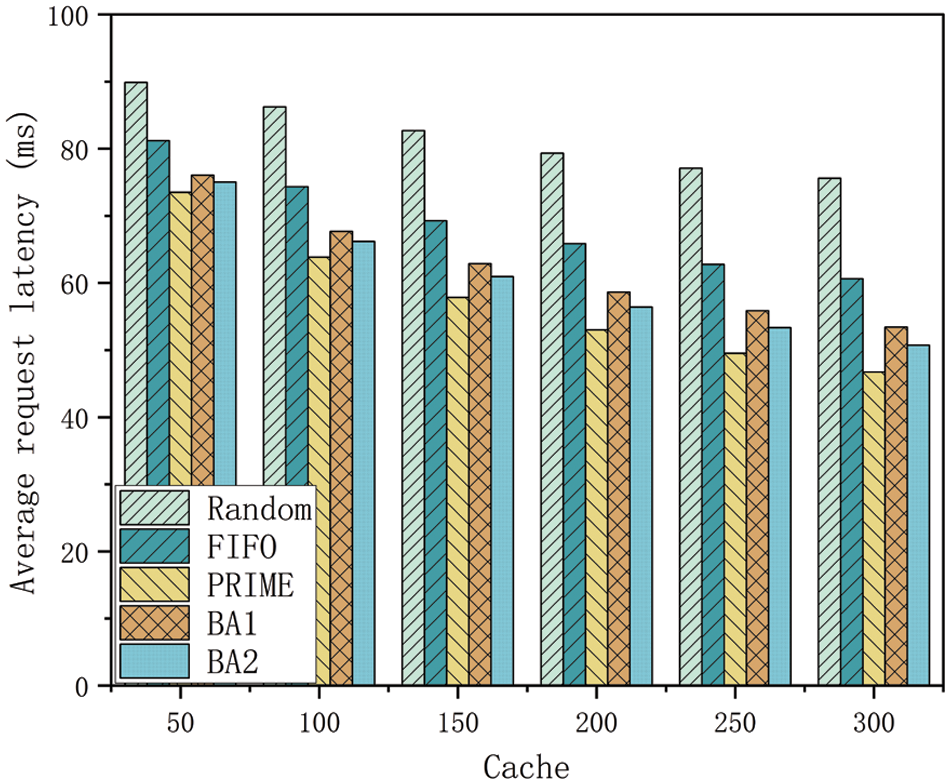
Figure 8: Capacity and average request latency
Fig. 9 shows the average cost of proactive caching for different methods at varying cache capacities. As cache capacity increases, the cost of proactive caching also rises. This increase is attributed to the server’s enhanced ability to store more content, which reduces user latency but increases caching costs. Furthermore, its growth tends to decrease with capacity because higher hit rates help to alleviate the cost of communication with the remote cloud. It is important to note that since FIFO recommends only one content per user at a time, when the cache capacity reaches 150, the content that needs to be proactively cached by the base station no longer increases. In contrast, PRIME saves proactive caching cost by 72.59%, 36.71%, 23.19%, and 17.41% in comparison with Random, LRU, BA1 and BA2, respectively.
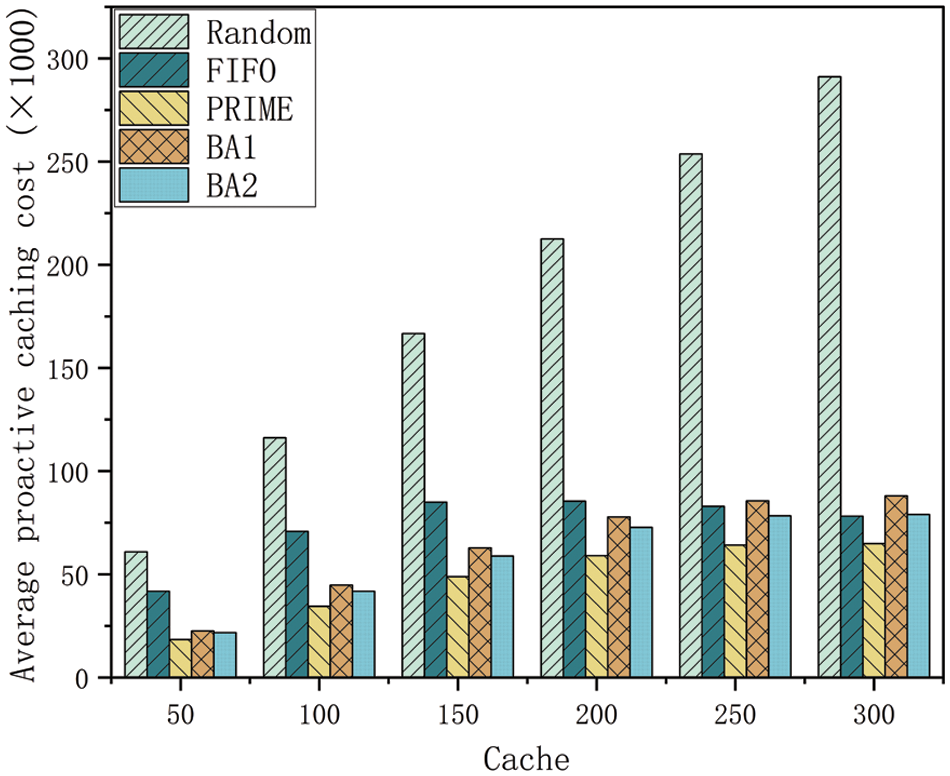
Figure 9: Capacity and average cost of proactive caching
Fig. 10 displays the system’s average cost with different methods and varying cache capacities. As is evident from all methods, the system’s cost comprises two primary components: the cost of proactive caching at the base stations and the cost of user requests. As server cache capacity increases, the proactive cache cost at base stations gradually rises. However, the cost of user requests decreases due to the gradual reduction in user request latency. Thus, the system’s average cost does not necessarily increase with the increased capacity. PRIME demonstrates a lower system cost than FIFO, BA1, and BA2 by 54.85%, 26.02%, 15.31%, and 10.62%, respectively.
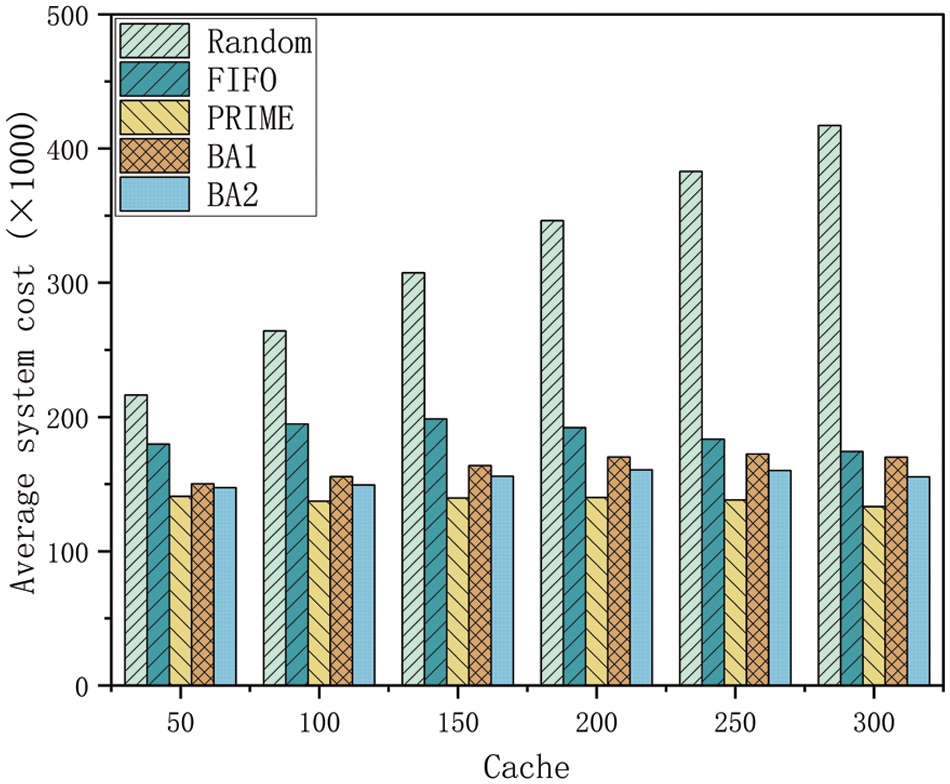
Figure 10: Capacity and average system cost
In this paper, we introduced PRIME, a predictive user popularity-aware approach for proactive content caching in MEC. PRIME synthesizes a content popularity prediction model and a deep reinforcement learning procedure for yielding dynamic caching schedules. It generates accurate and evolving popularity score estimates for cached content, leading to superior predictive and proactive caching plans. Our experiments show that PRIME surpasses existing methods in various performance metrics.
In the future, we plan to incorporate anomaly detection models to refine content caching strategies and deepen our analysis of user behavior. This will involve examining temporal patterns in user requests and mobility to enhance PRIME’s predictive precision. Furthermore, we aim to explore PRIME’s scalability in more extensive and complex network settings and its adaptability to different user densities and mobility scenarios. Integrating edge computing with emerging technologies like 5G and IoT devices is another exciting direction to improve MEC content caching efficiency. These focused efforts will progressively advance proactive caching in MEC environments.
Acknowledgement: The authors wish to express their gratitude to the reviewers for their insightful suggestions, which have significantly enhanced the clarity and presentation of this paper, and extend their thanks to the editors for their invaluable support and guidance.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Yunni Xia; data collection: Yunye Wan, Peng Chen; analysis and interpretation of results: Yunye Wan, Yong Ma, Dongge Zhu; draft manuscript preparation: Yunye Wan, Xu Wang, Hui Liu; manuscript review and editing: Yunni Xia, Weiling Li, Xianhua Niu, Lei Xu, Yumin Dong. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The datasets used in this study are publicly available. The MovieLens dataset is detailed in [31] and can be accessed as described therein. The Shanghai Telecom dataset is elaborated in [32], with acquisition information provided in the respective publication. Both datasets have been utilized by their respective usage guidelines and terms of service.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Sahoo, S., Mukherjee, A., Halder, R. (2021). A unified blockchain-based platform for global e-waste management. International Journal of Web Information Systems, 17(5), 449–479. https://doi.org/10.1108/IJWIS-03-2021-0024 [Google Scholar] [CrossRef]
2. Liu, J., Wu, Z., Liu, J., Zou, Y. (2022). Cost research of Internet of Things service architecture for random mobile users based on edge computing. International Journal of Web Information Systems, 18(4), 217–235. https://doi.org/10.1108/IJWIS-02-2022-0039 [Google Scholar] [CrossRef]
3. Gao, H., Yu, X., Xu, Y., Kim, J. Y., Wang, Y. (2024). MonoLI: Precise monocular 3D object detection for next-generation consumer electronics for autonomous electric vehicles. IEEE Transactions on Consumer Electronics, 1. [Google Scholar]
4. Uthansakul, P., Khan, A. A. (2019). On the energy efficiency of millimeter wave massive MIMO based on hybrid architecture. Energies, 12(11), 2227. https://doi.org/10.3390/en12112227 [Google Scholar] [CrossRef]
5. Ioannou, A., Weber, S. (2016). A survey of caching policies and forwarding mechanisms in information-centric networking. IEEE Communications Surveys & Tutorials, 18(4), 2847–2886. https://doi.org/10.1109/COMST.2016.2565541 [Google Scholar] [CrossRef]
6. Ahlehagh, H., Dey, S. (2012). Video caching in radio access network: Impact on delay and capacity. 2012 IEEE Wireless Communications and Networking Conference (WCNC), pp. 2276–2281. Paris, France. [Google Scholar]
7. Shuja, J., Bilal, K., Alasmary, W., Sinky, H., Alanazi, E. (2021). Applying machine learning techniques for caching in next-generation edge networks: A comprehensive survey. Journal of Network and Computer Applications, 181, 103005. https://doi.org/10.1016/j.jnca.2021.103005 [Google Scholar] [CrossRef]
8. Garg, N., Sellathurai, M., Bhatia, V., Bharath, B. N., Ratnarajah, T. (2019). Online content popularity prediction and learning in wireless edge caching. IEEE Transactions on Communications, 68(2), 1087–1100. [Google Scholar]
9. Li, L., Kwong, C. F., Liu, Q., Kar, P., Ardakani, S. P. (2021). A novel cooperative cache policy for wireless networks. Wireless Communications and Mobile Computing, 2021, 1–18. [Google Scholar]
10. Yu, Z., Hu, J., Min, G., Zhao, Z., Miao, W. et al. (2020). Mobility-aware proactive edge caching for connected vehicles using federated learning. IEEE Transactions on Intelligent Transportation Systems, 22(8), 5341–5351. [Google Scholar]
11. Qi, K., Yang, C. (2020). Popularity prediction with federated learning for proactive caching at wireless edge. IEEE Wireless Communications and Networking Conference (WCNC), pp. 1–6. Seoul, Korea (South). [Google Scholar]
12. Zhang, Y., Li, Y., Wang, R., Lu, J., Ma, X. et al. (2020). PSAC: Proactive sequence-aware content caching via deep learning at the network edge. IEEE Transactions on Network Science and Engineering, 7(4), 2145–2154. https://doi.org/10.1109/TNSE.6488902 [Google Scholar] [CrossRef]
13. Gao, H., Qiu, B., Wang, Y., Yu, S., Xu, Y. et al. (2023). TBDB: Token bucket-based dynamic batching for resource scheduling supporting neural network inference in intelligent consumer electronics. IEEE Transactions on Consumer Electronics, 1. [Google Scholar]
14. Uthansakul, P., Khan, A. A. (2019). Enhancing the energy efficiency of mmWave massive MIMO by modifying the RF circuit configuration. Energies, 12(22), 4356. https://doi.org/10.3390/en12224356 [Google Scholar] [CrossRef]
15. Wei, X., Liu, J., Wang, Y., Tang, C., Hu, Y. (2021). Wireless edge caching based on content similarity in dynamic environments. Journal of Systems Architecture, 115, 102000. https://doi.org/10.1016/j.sysarc.2021.102000 [Google Scholar] [CrossRef]
16. Gao, H., Wu, Y., Xu, Y., Li, R., Jiang, Z. (2023). Neural collaborative learning for user preference discovery from biased behavior sequences. IEEE Transactions on Computational Social Systems, 1–11. [Google Scholar]
17. Tang, J., Wang, K. (2018). Personalized top-N sequential recommendation via convolutional sequence embedding. Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, pp. 565–573. New York, USA. [Google Scholar]
18. Zhu, H., Cao, Y., Wang, W., Jiang, T., Jin, S. (2018). Deep reinforcement learning for mobile edge caching: Review, new features, and open issues. IEEE Network, 32(6), 50–57. https://doi.org/10.1109/MNET.2018.1800109 [Google Scholar] [CrossRef]
19. Cai, Y., Chen, Y., Ding, M., Cheng, P., Li, J. (2021). Mobility prediction-based wireless edge caching using deep reinforcement learning. 2021 IEEE/CIC International Conference on Communications in China, pp. 1036–1041. Xiamen, China. [Google Scholar]
20. Wu, Q., Zhao, Y., Fan, Q., Fan, P., Wang, J. et al. (2022). Mobility-aware cooperative caching in vehicular edge computing based on asynchronous federated and deep reinforcement learning. IEEE Journal of Selected Topics in Signal Processing, 17(1), 66–81. [Google Scholar]
21. He, P., Cao, L., Cui, Y., Wang, R., Wu, D. (2023). Multi-agent caching strategy for spatial-temporal popularity in IoV. IEEE Transactions on Vehicular Technology, 72(10), 13536–13546. https://doi.org/10.1109/TVT.2023.3277191 [Google Scholar] [CrossRef]
22. Somesula, M. K., Rout, R. R., Somayajulu, D. V. (2022). Cooperative cache update using multi-agent recurrent deep reinforcement learning for mobile edge networks. Computer Networks, 209, 108876. https://doi.org/10.1016/j.comnet.2022.108876 [Google Scholar] [CrossRef]
23. Chen, S., Yao, Z., Jiang, X., Yang, J., Hanzo, L. (2020). Multi-agent deep reinforcement learning-based cooperative edge caching for ultra-dense next-generation networks. IEEE Transactions on Communications, 69(4), 2441–2456. [Google Scholar]
24. Kong, X., Duan, G., Hou, M., Shen, G., Wang, H. et al. (2022). Deep reinforcement learning-based energy-efficient edge computing for internet of vehicles. IEEE Transactions on Industrial Informatics, 18(9), 6308–6316. https://doi.org/10.1109/TII.2022.3155162 [Google Scholar] [CrossRef]
25. Gao, H., Wang, X., Wei, W., Al-Dulaimi, A., Xu, Y. (2024). Com-DDPG: Task offloading based on multiagent reinforcement learning for information-communication-enhanced mobile edge computing in the internet of vehicles. IEEE Transactions on Vehicular Technology, 73(1), 348–361. https://doi.org/10.1109/TVT.2023.3309321 [Google Scholar] [CrossRef]
26. Jiang, W., Feng, D., Sun, Y., Feng, G., Wang, Z. et al. (2021). Proactive content caching based on actor-critic reinforcement learning for mobile edge networks. IEEE Transactions on Cognitive Communications and Networking, 8(2), 1239–1252. [Google Scholar]
27. Zulfa, M. I., Hartanto, R., Permanasari, A. E. (2020). Caching strategy for Web application-a systematic literature review. International Journal of Web Information Systems, 16(5), 545–569. https://doi.org/10.1108/IJWIS-06-2020-0032 [Google Scholar] [CrossRef]
28. Zhang, R., Yu, F. R., Liu, J., Huang, T., Liu, Y. (2020). Deep reinforcement learning (DRL)-based device-to-device (D2D) caching with blockchain and mobile edge computing. IEEE Transactions on Wireless Communications, 19(10), 6469–6485. https://doi.org/10.1109/TWC.7693 [Google Scholar] [CrossRef]
29. Tang, C., Zhu, C., Wu, H., Li, Q., Rodrigues, J. J. P. C. (2021). Toward response time minimization considering energy consumption in caching-assisted vehicular edge computing. IEEE Internet of Things Journal, 9(7), 5051–5064. [Google Scholar]
30. Mu, S., Wang, F., Xiong, Z., Zhuang, X., Zhang, L. (2020). Optimal path strategy for the web computing under deep reinforcement learning. International Journal of Web Information Systems, 16(5), 529–544. https://doi.org/10.1108/IJWIS-08-2020-0055 [Google Scholar] [CrossRef]
31. Harper, F. M., Konstan, J. A. (2015). The movielens datasets: History and context. ACM Transactions on Interactive Intelligent Systems, 5(4), 1–19. [Google Scholar]
32. Li, Y., Zhou, A., Ma, X., Wang, S. (2021). Profit-aware edge server placement. IEEE Internet of Things Journal, 9(1), 55–67. [Google Scholar]
33. AlNagar, Y., Hosny, S., El-Sherif, A. A. (2019). Towards mobility-aware proactive caching for vehicular ad hoc networks. 2019 IEEE Wireless Communications and Networking Conference Workshop (WCNCW), pp. 1–6. Marrakech, Morocco. [Google Scholar]
34. Li, J., Zhao, J., Chen, P., Xia, Y., Li, F. et al. (2023). A multi-armed bandits learning-based approach to service caching in edge computing environment. International Conference on Web Services, pp. 3–17. Honolulu, USA. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools