
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

MPI/OpenMP-Based Parallel Solver for Imprint Forming Simulation
1 School of Mechanical Engineering, Jiangsu University, Zhenjiang, 212016, China
2 School of Mechanical Engineering, Wuhan Polytechnic University, Wuhan, 430023, China
3 Shenyang Mint Company Limited, Shenyang, 110092, China
* Corresponding Authors: Jiangping Xu. Email: ; Wen Zhong. Email:
(This article belongs to the Special Issue: New Trends on Meshless Method and Numerical Analysis)
Computer Modeling in Engineering & Sciences 2024, 140(1), 461-483. https://doi.org/10.32604/cmes.2024.046467
Received 02 October 2023; Accepted 10 January 2024; Issue published 16 April 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
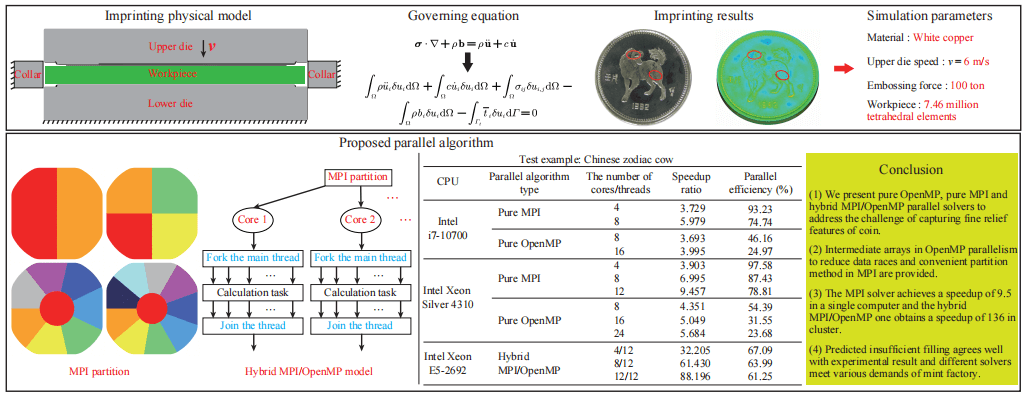
In this research, we present the pure open multi-processing (OpenMP), pure message passing interface (MPI), and hybrid MPI/OpenMP parallel solvers within the dynamic explicit central difference algorithm for the coining process to address the challenge of capturing fine relief features of approximately 50 microns. Achieving such precision demands the utilization of at least 7 million tetrahedron elements, surpassing the capabilities of traditional serial programs previously developed. To mitigate data races when calculating internal forces, intermediate arrays are introduced within the OpenMP directive. This helps ensure proper synchronization and avoid conflicts during parallel execution. Additionally, in the MPI implementation, the coins are partitioned into the desired number of regions. This division allows for efficient distribution of computational tasks across multiple processes. Numerical simulation examples are conducted to compare the three solvers with serial programs, evaluating correctness, acceleration ratio, and parallel efficiency. The results reveal a relative error of approximately 0.3% in forming force among the parallel and serial solvers, while the predicted insufficient material zones align with experimental observations. Additionally, speedup ratio and parallel efficiency are assessed for the coining process simulation. The pure MPI parallel solver achieves a maximum acceleration of 9.5 on a single computer (utilizing 12 cores) and the hybrid solver exhibits a speedup ratio of 136 in a cluster (using 6 compute nodes and 12 cores per compute node), showing the strong scalability of the hybrid MPI/OpenMP programming model. This approach effectively meets the simulation requirements for commemorative coins with intricate relief patterns.Graphic Abstract
Keywords
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools