
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

KSKV: Key-Strategy for Key-Value Data Collection with Local Differential Privacy
1 Artificial Intelligence Development Research Center, Institute of Scientific and Technical Information of China, Beijing, 100038, China
2 Industry Development Department, NSFOCUS Inc., Beijing, China
3 School of Information Science and Technology, Beijing Forestry University, Beijing, 100083, China
4 School of Computer Science and Engineering, University of Electronic Science and Technology of China, Chengdu, 610054, China
5 Institute of Computing Technology, China Academy of Railway Sciences Corporation Limited, Beijing, 10081, China
* Corresponding Authors: Chuanwen Luo. Email: ; Ting Chen. Email:
(This article belongs to the Special Issue: Privacy-Preserving Technologies for Large-scale Artificial Intelligence)
Computer Modeling in Engineering & Sciences 2024, 139(3), 3063-3083. https://doi.org/10.32604/cmes.2023.045400
Received 25 August 2023; Accepted 08 November 2023; Issue published 11 March 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In recent years, the research field of data collection under local differential privacy (LDP) has expanded its focus from elementary data types to include more complex structural data, such as set-value and graph data. However, our comprehensive review of existing literature reveals that there needs to be more studies that engage with key-value data collection. Such studies would simultaneously collect the frequencies of keys and the mean of values associated with each key. Additionally, the allocation of the privacy budget between the frequencies of keys and the means of values for each key does not yield an optimal utility tradeoff. Recognizing the importance of obtaining accurate key frequencies and mean estimations for key-value data collection, this paper presents a novel framework: the Key-Strategy Framework for Key-Value Data Collection under LDP. Initially, the Key-Strategy Unary Encoding (KS-UE) strategy is proposed within non-interactive frameworks for the purpose of privacy budget allocation to achieve precise key frequencies; subsequently, the Key-Strategy Generalized Randomized Response (KS-GRR) strategy is introduced for interactive frameworks to enhance the efficiency of collecting frequent keys through group-and-iteration methods. Both strategies are adapted for scenarios in which users possess either a single or multiple key-value pairs. Theoretically, we demonstrate that the variance of KS-UE is lower than that of existing methods. These claims are substantiated through extensive experimental evaluation on real-world datasets, confirming the effectiveness and efficiency of the KS-UE and KS-GRR strategies.Keywords
Enterprises frequently collect data for analysis with the aim of enhancing the quality of their services. However, such data often contain sensitive information, necessitating robust privacy protection measures. Differential Privacy (DP) [1] has become the de facto standard for privacy preservation, ensuring the security of data irrespective of an adversary's background knowledge or computational power. In environments lacking a trusted aggregator, the Local Differential Privacy (LDP) offers robust privacy assurances during the data collection phase. Under LDP, users independently apply a privacy-preserving mechanism to their data before transmission to the aggregator. Notably, several leading enterprises, including Google [2], Apple [3], and Microsoft [4], have implemented LDP.
Initial research in LDP primarily addressed basic statistical data types, focusing on frequency estimation of discrete variables and mean estimation of continuous variables. Further studies extended the paradigm to more sophisticated structured data, including set values [5–7] and graph data [8,9]. Despite this progress, investigations into key-value data queries remain relatively sparse [10–12]. Key-value data, prevalent in practice, necessitates simultaneous analysis of key frequencies and the means of values associated with each key. The accuracy of multidimensional data collection under LDP is particularly challenging due to the constraints of the privacy budget. Moreover, traditional LDP algorithms can significantly distort the intrinsic associations among multidimensional data. The significance of key-value data in big data analytics cannot be overstated, and the correlation between keys and their associated values is typically strong. Thus, the collection of key-value data within the stringent privacy budget constraints of LDP presents a substantial and noteworthy challenge. For example, as illustrated in Table 1, to accurately determine a movie’s rating, a sufficient number of reviews, or the frequency of keys, is first required. Subsequently, the mean of these key values represents the movie's rating. Accurate key frequencies not only enable more precise value calculations (since the value under each key is derived from the sum of all values divided by the key’s frequency) but also facilitate a more accurate ranking of keys.

Motivations. Effective management of key-value collections critically relies on two principal factors: the frequency of keys and the mean of the values associated with each key. The primary challenge lies in maximizing the utility of key-value data within the LDP framework, while maintaining robust privacy guarantees. In LDP models, the privacy budget parameter, denoted as
Contribution. This paper aims to address the existing challenges by introducing innovative mechanisms that prioritize key strategies, aimed at increasing the utility of key-value data collection in both interactive and non-interactive environments. For non-interactive frameworks, we propose the Key-Strategy Unary Encoding (KS-UE), strategically allocating a predominant portion of the privacy budget to key frequencies to enhance utility. In interactive environments, we employ the Key-Strategy Generalized Randomized Response (KS-GRR), which uses a group-and-iteration approach across various tasks to yield superior estimation results. Furthermore, the paper thoroughly examines the flexibility of these strategies in situations where users hold either single or multiple key-value pairs.
The salient contributions of this work can be summarized as follows:
• Acknowledging the paramountcy of accurate keys in key-value collection, we advance the key-strategy mechanisms KS-UE for non-interactive frameworks and KS-GRR for interactive frameworks within the confines of LDP.
• By leveraging KS-UE and KS-GRR, we formulate algorithms tailored for contexts wherein users hold either singular or multiple key-value pairs, enhancing the adaptability of our approach.
• We provide rigorous theoretical substantiation for the minimal variance of KS-UE. Additionally, empirical evaluations corroborate that strategies KS-UE and KS-GRR can ascertain more precise frequent keys while maintaining the integrity of mean accuracy.
Roadmap. Section 2 will elaborate on related works. Subsequently, Section 3 will provide background information and the theoretical foundation for our study. In Section 4, we introduce our key-strategy algorithms for single and multiple key-value pairs within the framework of Local Differential Privacy. Section 5 will present the experimental results, while Section 6 will conclude the paper.
Local Differential Privacy is a potent technique employed to safeguard sensitive user data during the data collection process. The fundamental mechanism of LDP yields a probability distribution as output rather than revealing authentic statistical information. Randomized Response (RR), first introduced in the 1960s, is recognized as a precursor to LDP methods [13] and was later formalized as a local privacy model by Dwork [14,15]. Subsequent research has led to the development of methodologies such as RAPPOR [2], Optimal-RR (O-RR), Optimal-RAPPOR (O-RAPPOR) [16], Sampled Histogram (SH) [17], Optimal Unary Encoding (OUE), and Optimal Local Hashing (OLH) [18] for singleton frequency estimation. Additional studies [4,19] have focused on mean estimation with numerical attributes. More complex data structures such as set values [5,6], marginal release [20,21], numerical values [19,22], graph data [8,9,23,24], spatiotemporal data [1,25], time-series [26], distribution estimation [27], range queries [28], and machine learning [29,30] have been examined. Further, strategies to counteract attacks have been proposed [31–33]. Nevertheless, only a limited number of studies [10–12,34] have concentrated on key-value data queries.
Ye et al. [10] were the first to formalize two tasks in key-value data collection under LDP: estimating the frequencies of keys and the mean of values under each key. They proposed PrivKV for non-interactive frameworks and later introduced optimized versions, PrivKVM and PrivKVM+, for interactive frameworks. Ye et al. further improved PrivKVM+ in [34]. Sun et al. [11] offered another approach within the PrivKV framework, but they did not analyze the impact of the correlation between perturbations on the tighter budget composition. Gu et al. [12] addressed this issue by proposing an optimized budget allocation and an advanced 'padding-and-sampling' mechanism. They used budget allocation to optimize privacy parameters for better estimation results. In this paper, we propose a more effective scheme, termed key-strategy frameworks, for key-value data collection under LDP.
In this section, we initially delineate the problem, followed by an introduction to the concept of LDP. The notations used in this paper are summarized in Table 2.
3.1 Problem Definition and Challenge
Key-Value Data Collection. The issue of key-value data collection under LDP was first put forth by [10]. Assume there are
• Frequency Estimation: The purpose of this task is to estimate the frequency of each key
• Mean Estimation: The goal of this task is to estimate the mean of values associated with each key
In practical application scenarios, most users possess multiple values
3.2 Local Differential Privacy
LDP is a localized model of DP intended for data collection without a trustworthy aggregator [5,18,35,36]. An LDP algorithm, denoted as
Definition 3.1(
The privacy budget,
We assume the size of domain
Randomized Response(RR)/Generalized Randomized Response(GRR). The perturbation function of GRR [18] is
where RR is the special situation
Unary Encoding (UE). [18] Each user transforms her item into a vector of length
where
When
Optimal Local Hashing (OLH). [18] The OLH protocol was developed to ameliorate the challenges posed by attributes with extensive categories. Initially, the client-side algorithm transforms the user’s actual value
3.4 Padding-and-Sampling Protocol
Originally utilized for itemset data [6], the ‘padding-and-sampling’ protocol was first adopted for key-value data in [12]. In this setup, each user samples a single key-value pair from their set. A crucial parameter, denoted as
PrivKV. Ye et al. [10] proposed PrivKV and improved version PrivKVM and PrivKVM+ on key-value data collection under LDP first time. The primary process comprises: (a) encoding the key-value pair to a position of a vector, leaving all other positions as
PCKV-UE and PCKV-GRR. Gu et al. [12] proposed PCKV-UE and PCKV-GRR, leveraging the privacy budget in a more efficient manner. They employed a joint perturbation strategy, rather than dividing the privacy budget evenly. The value's perturbation is contingent upon the key's perturbation, which optimizes the privacy budget composition. Both methods, theoretically and experimentally, outperform those proposed by Ye et al. Thus, we have excluded the PrivKV series from our experiment. The variances of keys and means in PCKV-UE are as follows:
It is noteworthy that both theoretically and experimentally, Gu et al. have demonstrated that PCKV-UE and PCKV-GRR are superior to the series of PrivKV algorithms under equivalent conditions. Even after the conditions in [34] were collectively altered, PCKV-UE and PCKV-GRR still showcased excellent performance. Therefore, this paper solely compares PCKV-UE and PCKV-GRR.
For multiple key-value. In [12], when PCKV-UE and PCKV-GRR address multiple key-value pairs, they pre-set an average length
Our mechanisms aim to gather the frequencies of keys and the mean of values under each key. If most keys have low frequencies, the mean values corresponding to these keys are largely irrelevant. Hence, if the domain is large, it becomes essential to reduce the domain in order to find top frequent keys. In this section, we introduce two key-strategy mechanisms for a singleton key-value pair under LDP: key-strategy unary encoding (KS-UE) in non-interactive frameworks and key-strategy generalized randomized response (KS-GRR) in interactive frameworks. When each user possesses multiple key-value pairs, padding-sampling is utilized to convert them into a singleton key-value pair. Subsequently, each user can implement the aforementioned two mechanisms.
4.1 KS-UE for Singleton Pair in Non-Interactive Frameworks
In non-interactive frameworks, users transmit their perturbed data to the aggregator using a one-way communication model. Here, the unary encoding (UE) mechanism comes into play, encoding each pair into a bit vector with only the bit corresponding to the key set to a value, and all others to zero. Building upon previous algorithms, KS-UE skews the privacy budget in favor of key frequencies to improve utility. The KS-UE methodology unfolds in three distinct phases: Discretization, Encoding and Perturbation, and Decoding, as delineated in Algorithm 2.
Discretization. To alleviate communication and time complexity, the initial step discretizes the value of the key-value pair from float type to binary
Encoding and Perturbation. The first operation here is to employ UE to create a bit vector b of size

where
Decoding. The aggregator collects b* from each user. Then, the aggregator need to calculate three statistic results
where
Having estimated the frequency of key
4.2 KS-GRR for Singleton Pair in Interactive Frameworks
Within interactive frameworks, users are systematically assembled into random group, and the entirety of the privacy budget is meticulously allocated to facilitate involvement in two distinct tasks for each assembly, as depicted in Fig. 1: (1) the estimation of the most prevalent keys within key-value pairs; (2) the computation of the frequencies of the aforementioned prevalent keys, as well as the mean of the values corresponding to these keys. Then, the aggregator is enabled to process and extrapolate the preliminary results from the initial group, subsequently deriving the conclusive frequencies of the superior keys and the corresponding mean values from the subsequent group. The KS-GRR model employs a sophisticated grouping methodology, aiming to optimize the efficacy of the data collection process, thereby contributing to enhanced accuracy and utility in the realization of key-value collection goals.
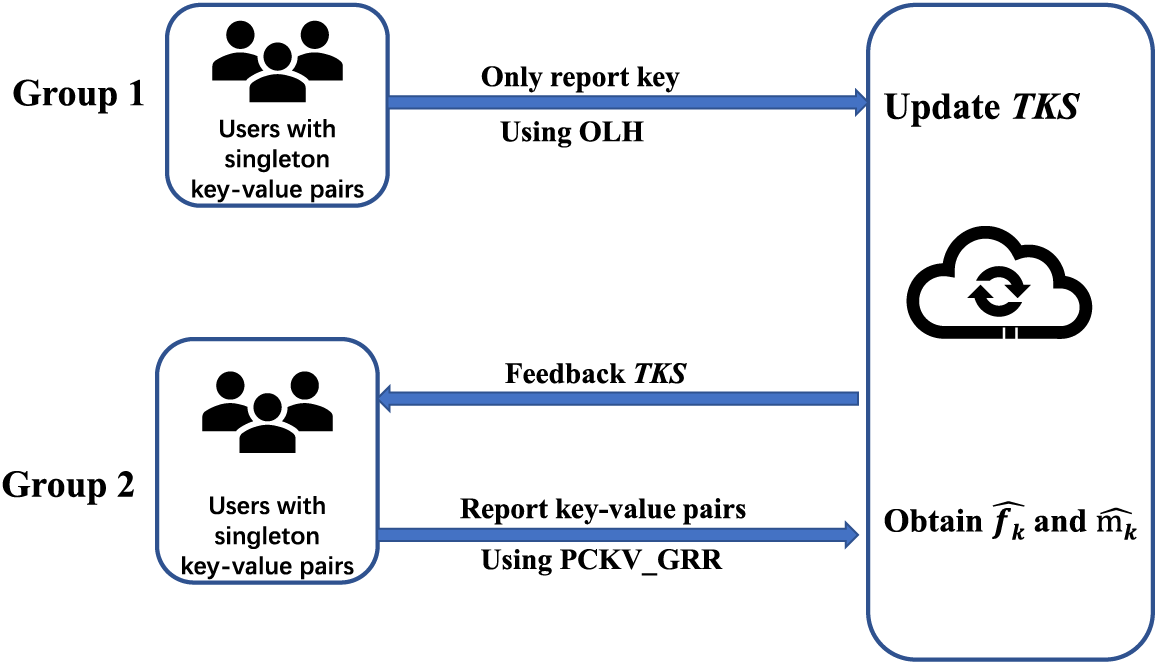
Figure 1: Illustration of KS-GRR for singleton key-value pair
Top frequent keys. In the context of top frequent keys, the value in key-value pairs is deemed irrelevant, as the focus here is solely on estimating the frequencies of keys. Thus, this stage transforms the collection of key-value pairs into a singleton keys collection under LDP, directly utilizing the OLH algorithm. To obtain the top-
Frequency and mean. The aggregator transmits the top-

4.3 KS-UE and KS-GRR for Multiple Key-Value Pairs
The scenario of multiple key-value pairs indicates that each user possesses a set of such pairs. In order to accommodate this situation, we employ an advanced protocol known as ‘padding-and-sampling’ as described in Gu et al. [12], specifically designed to enhance the performance of key-value data analysis.
The ‘padding-and-sampling’ protocol necessitates a global parameter
KS-UE for multiple key-value pairs. In order to allow for a comparison with PCKV-UE, KS-UE employs the same ‘padding-and-sampling' protocol as PCKV-UE. Consequently, following the ‘padding-and-sampling' protocol, each user will have a singleton key-value pair. The KS-UE algorithm (discussed in Section 4.1) is utilized to ascertain the frequencies of the top-
KS-GRR for multiple key-value pairs. The process of KS-GRR is recalibrated for the case of multiple key-value pairs, as depicted in Fig. 2. Given the tripartite tasks involved in KS-GRR, the users are accordingly segmented into three groups, each group catering to a specific task.
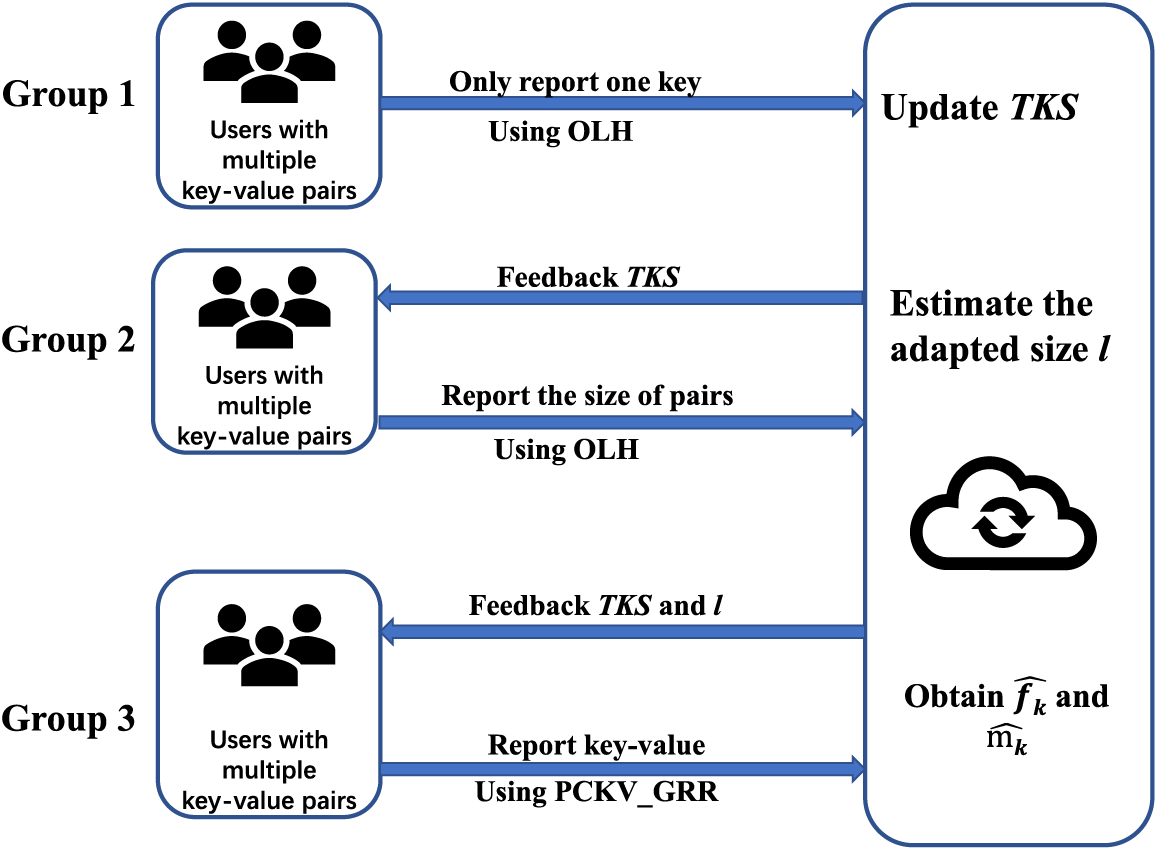
Figure 2: Illustration of KS-GRR for multiple key-value pairs
• Task 1: Users in this group bypass the ‘padding-and-sampling' protocol and opt to randomly select one of their keys to be transmitted to the aggregator via the OLH algorithm. This technique does not ascertain the frequencies of the keys; however, it reliably preserves the ordinal information of the keys. Notably, the estimations remain stable and unaffected by variations in the value of
• Task 2: For the users engaged in this task, the aggregator provides feedback on the top keys set TKS. This task requires a limited number of users to identify an appropriate
• Task 3: For the users participating in this task, the aggregator provides feedback on the top keys set TKS as well as the adjusted
In this section, we will initially provide evidence to confirm that KS-UE satisfies
Theorem 4.1. KS-UE satisfies
Proof. Let
Then,
Theorem 4.2. (Estimation Error Analysis). The expectation and variances of
Proof. For formula (8). For convenience, let
Therefore, the relative frequency
For formula (9). Next, we calculate the variance of
For formulas (10) and (11). We calculate the expectation and variance of mean estimation. From the multivariate Taylor Expansions of functions of random variables, the expectation of quotient of two random variables X and Y can be approximated by
For convenience, we denote
The variances are
The proof is completed.
In this section, we set up experiments on real datasets to validate our analysis with different approaches.
Datasets. We ran experiments on the following datasets:
• E-Commerce (Ecommerce rating dataset)1: This dataset contains the merchant transactions of 23,486 users with 1,206 keys. Each user has only one key-value pair. This dataset is used in both singleton and multiple scenarios.
• Clothing (Clothing fit and rating dataset)2: This dataset contains the merchant transactions of 47,959 users with 5,850 keys. Each user has multiple key-value pair. For singleton key-value pair collection, we treat each key-value pair as a individual record. Thus, clothing-singleton dataset has 82,789 records with 5,850 keys.
Metrics. This study aimed to find the frequent itemsets together with their frequencies, which requires different metrics to evaluate their utilities. We adopted the normalized cumulative rank (NCR) [6,18] and squared error (SE) to assess the frequent itemsets and frequencies, respectively.
1). Normalized Cumulative Rank (NCR). The quality function with the most
2). Squared Error (Var). We measured the estimation accuracy for both frequency and mean by using averaged Mean Squared Error. That is
where
Parameter settings. In KS-GRR for multiple pairs, we use
Selected approaches. We compare our KS-UE and KS-GRR with the following approaches. The approaches used in the evaluation are as follows:
(i) PCKV-UE [12]. PVKV-UE is the state-of-the-art approach for key-value pairs collection.
(ii) PVKV-GRR [12]. PCKV-GRR can obtain benifit from ‘padding-and-sampling’ than PCKV-UE, but only performs well when
(iii) KS-Adap. KS-Adap is a manifestation for multiple key-value pairs of KS-GRR. We use
For KS-UE, PCKV-UE and PCKV-GRR, we set
All experiments were conducted on an Intel Core(TM) i7-6700 3.40 GHz PC with 16 GB RAM. The results are averaged over 10 runs.
Singleton key-value pair. Figs. 3–5depict the metric evaluation on the E-Commerce and Clothing singleton key-value pair datasets.
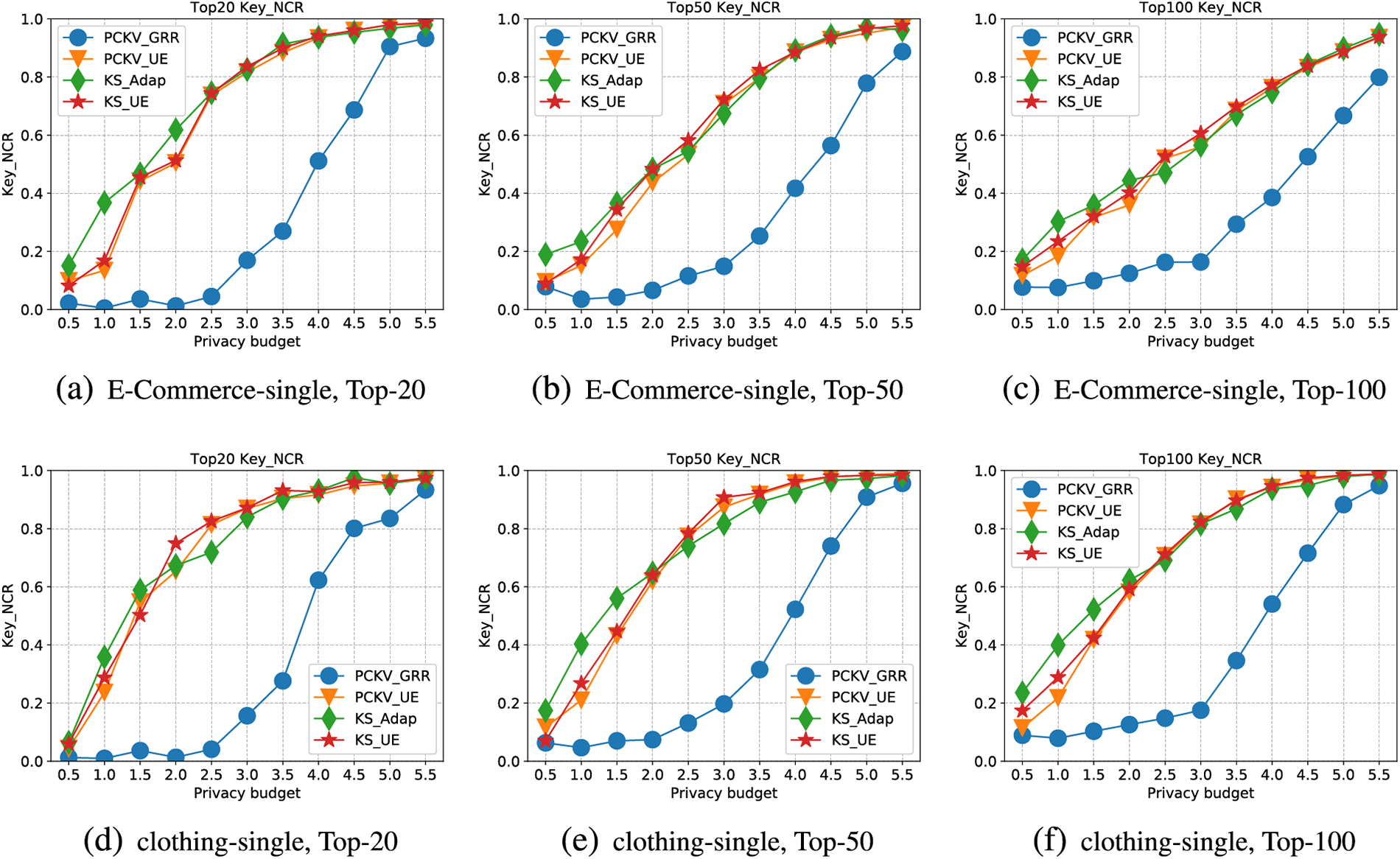
Figure 3: NCR for single dataset
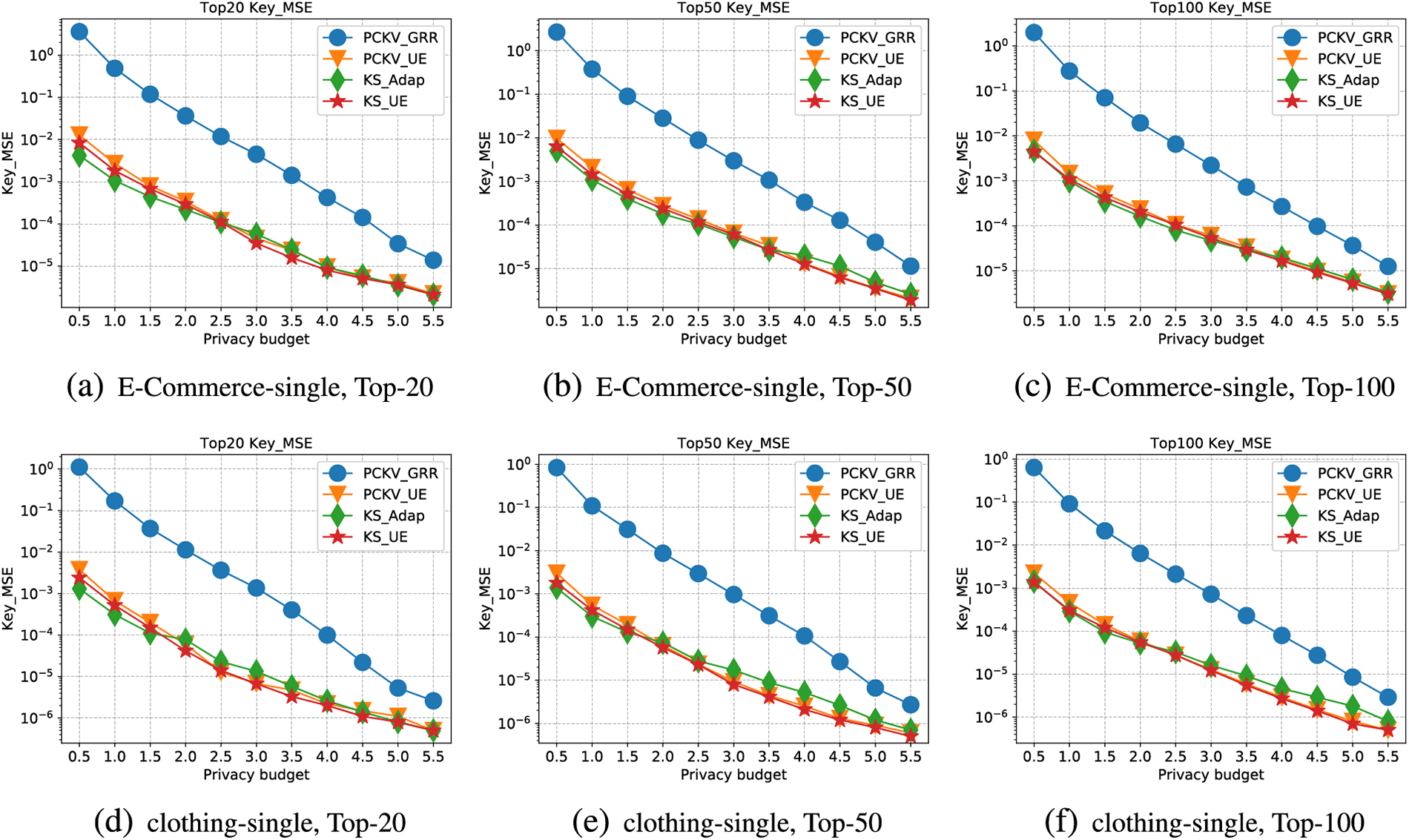
Figure 4: Key-MSE for single dataset
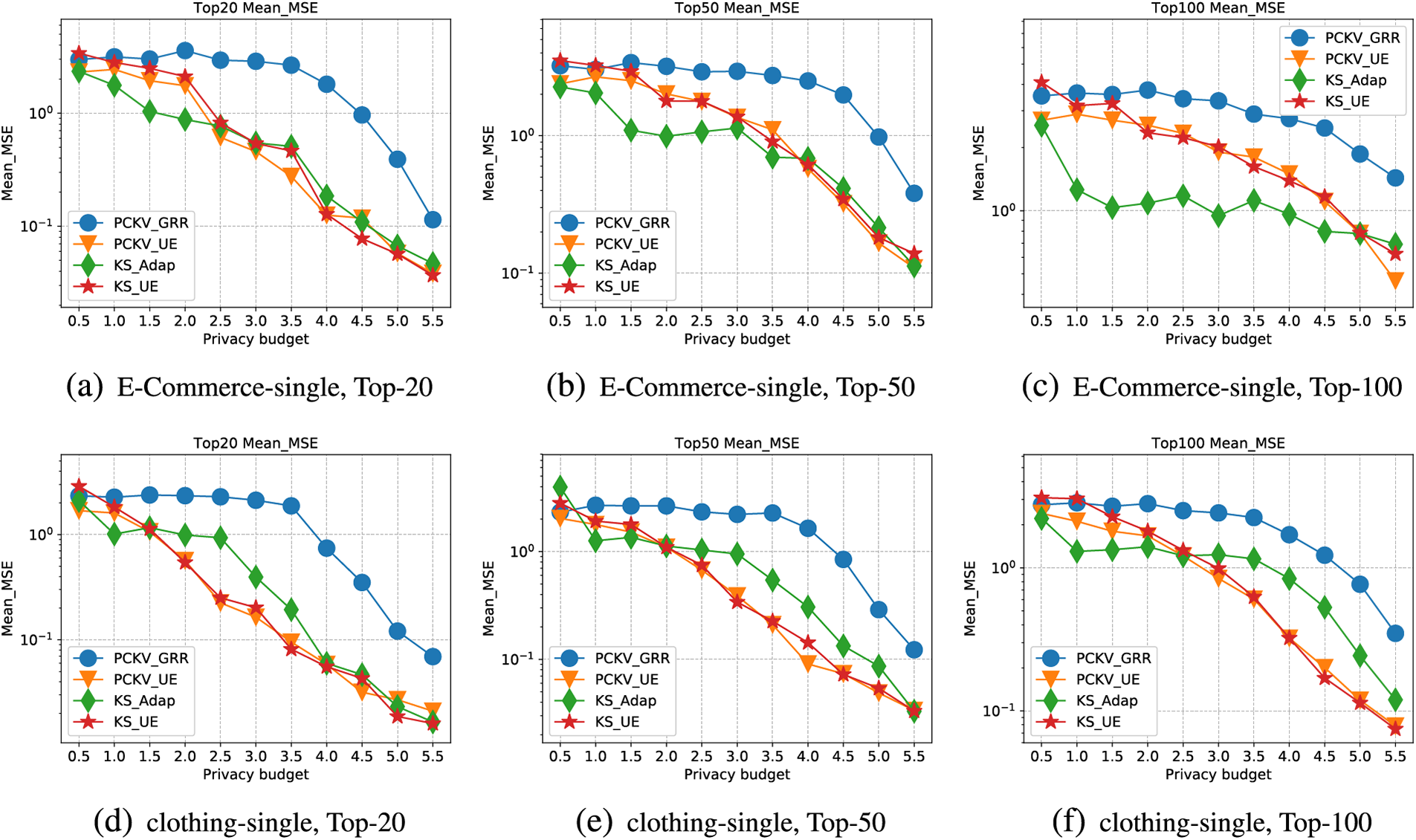
Figure 5: Mean-MSE for single dataset
Firstly, Fig. 3 presents the trendlines of NCR for keys with an increasing privacy budget (
Secondly, Fig. 4 illustrates the trendlines of MSE for keys with an incrementing privacy budget (
Lastly, Fig. 5 demonstrates the trendlines of MSE for the mean values with an increasing privacy budget (
Multiple key-value pairs. Figs. 6–8 present the metric evaluation for the E-Commerce and Clothing datasets featuring multiple key-value pairs.
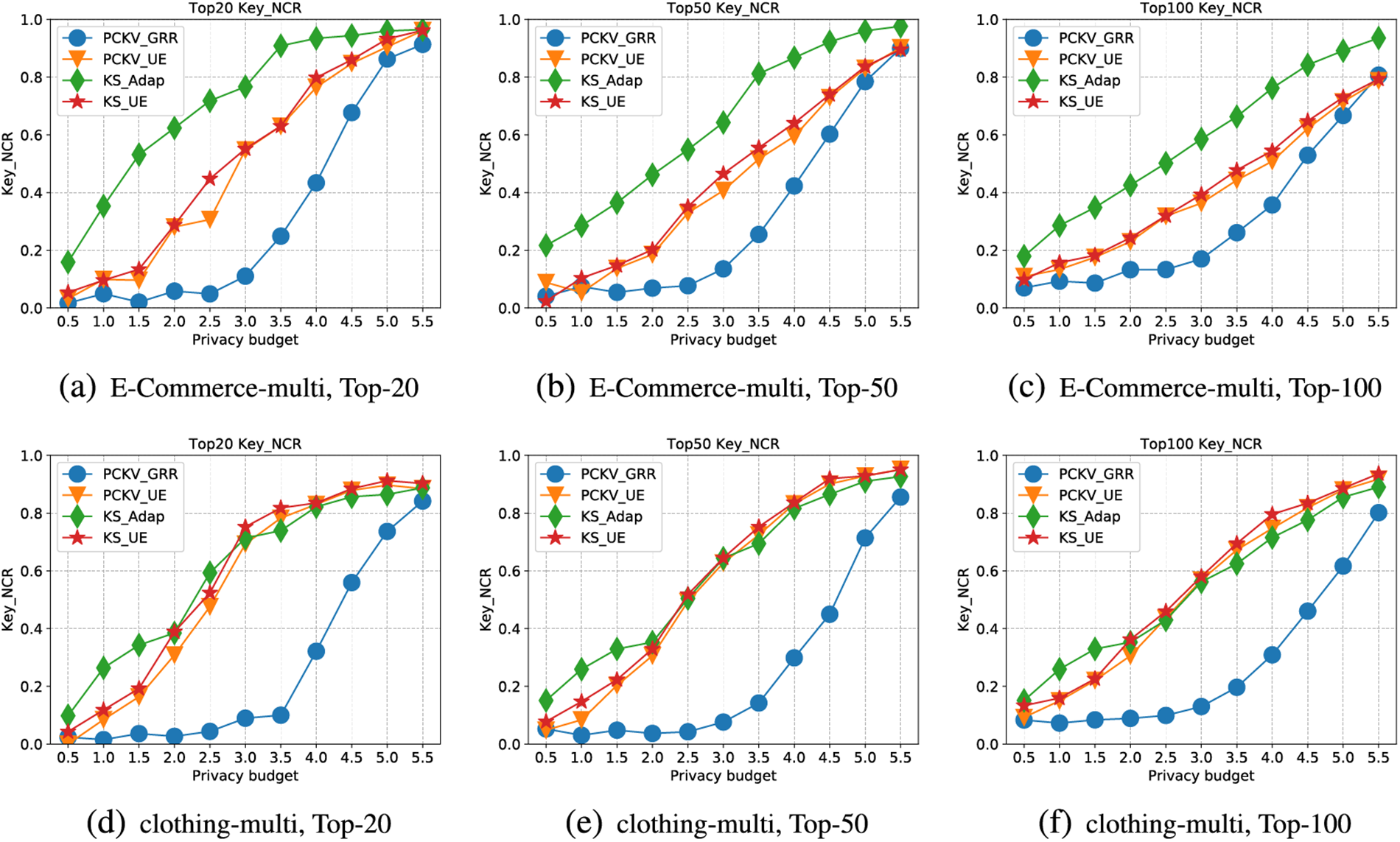
Figure 6: NCR for multiple dataset
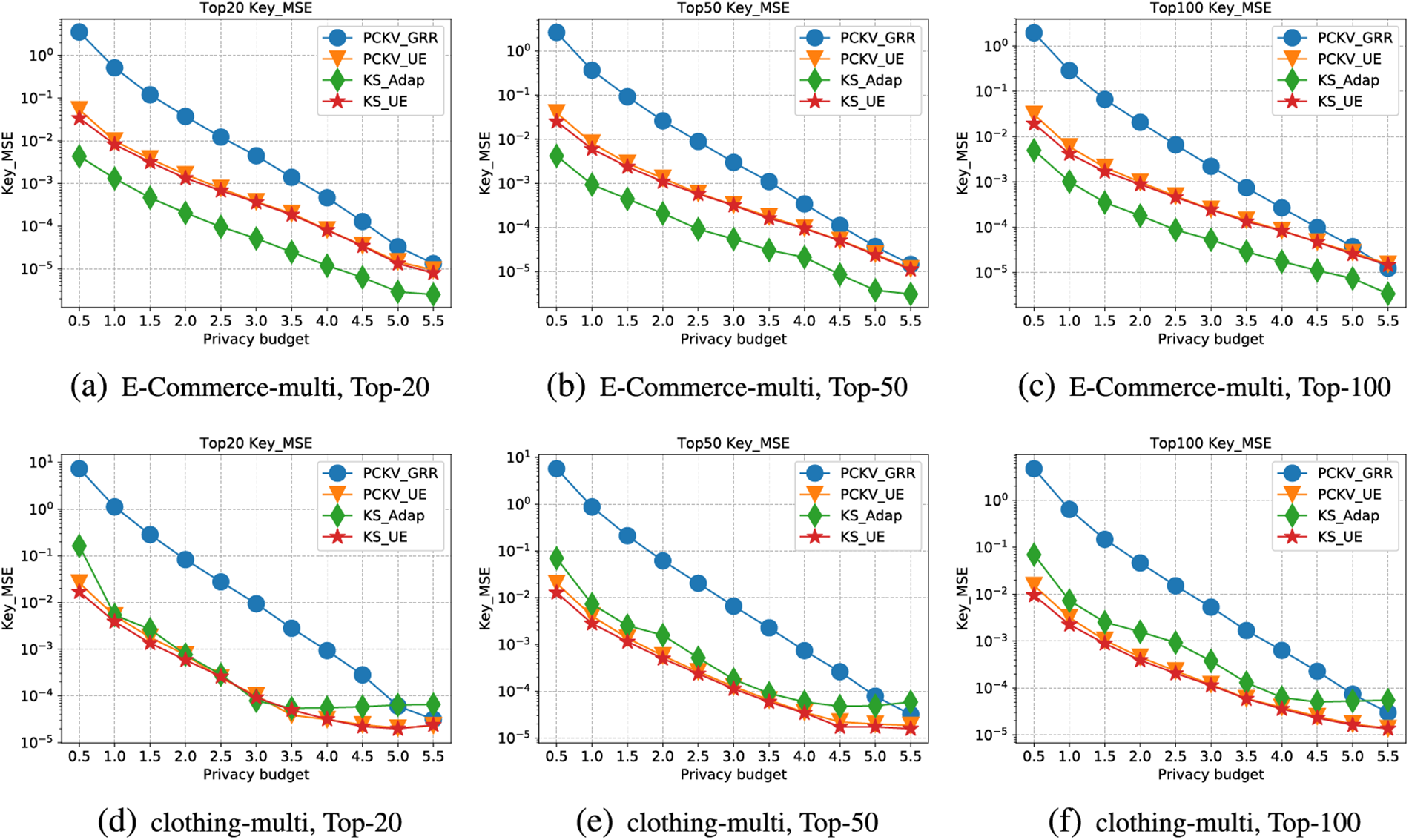
Figure 7: Key-MSE for multiple dataset
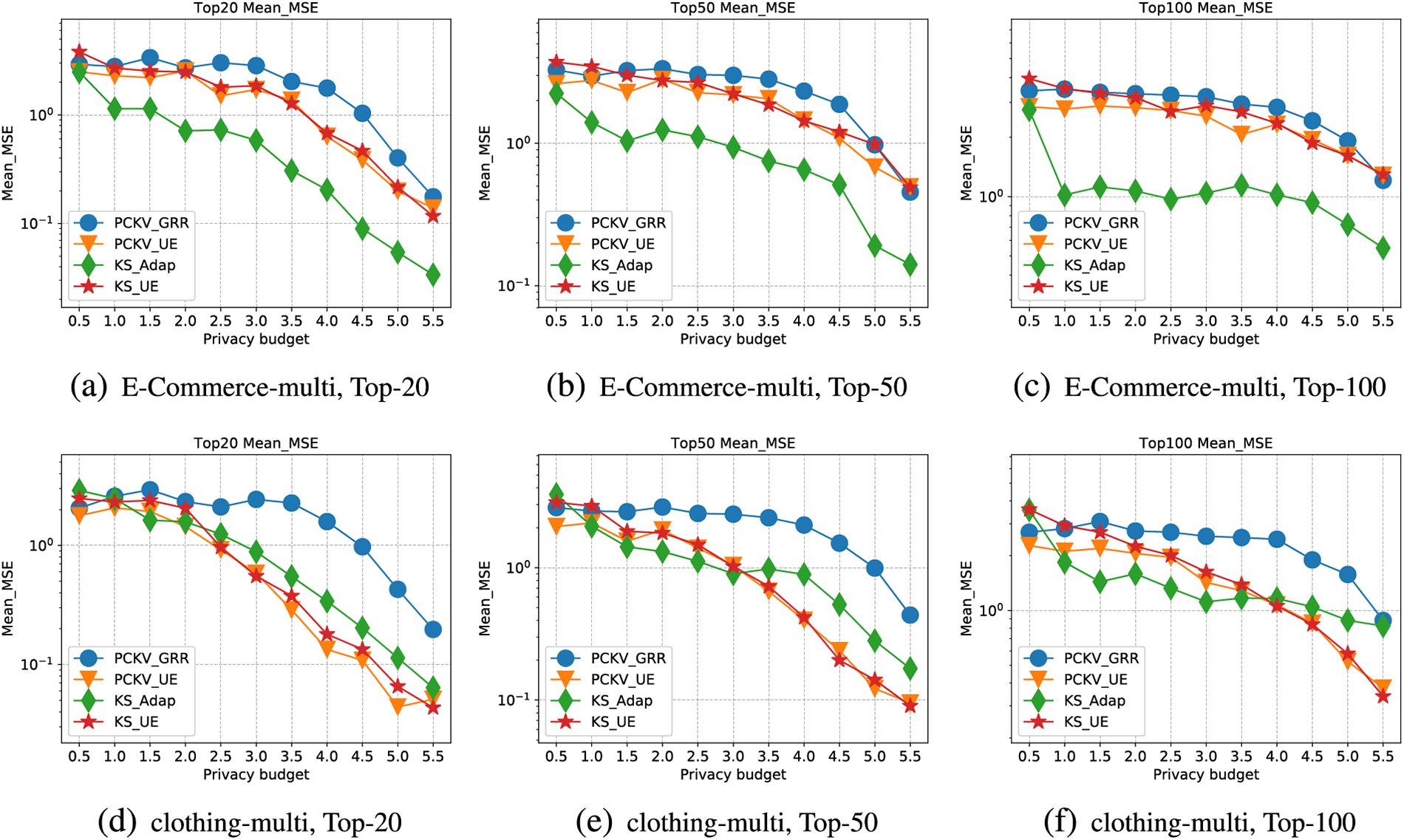
Figure 8: Mean-MSE for multiple dataset
Firstly, Fig. 6 depicts the trendlines for the NCR of keys, corresponding to the increasing privacy budget (
Secondly, Fig. 7 illustrates the MSE trendlines for keys, with respect to the incrementing privacy budget (
Lastly, Fig. 8 presents the MSE trendlines for the mean values with increasing
Analysis. The experimental outcomes reveal that the KS-UE and KS-GRR algorithms predominantly surpass other algorithms in most situations. The advantages of KS-UE have already been discerned in the error analysis in Section 4.4; its Mean Squared Error (MSE) is lower than prior algorithms, thus reflecting more superior results in the experiments. KS-GRR, by adopting a key-priority strategy, ensures the accuracy in collecting keys and the validity of the values under such keys, once accurate keys have been obtained by collecting the frequency of keys.
In this research, we explore methods for key-value data collection under the constraint of local differential privacy to obtain key frequencies and corresponding mean values. We design two innovative strategies, namely, Key Strategy KS-UE and KS-GRR, applicable in interactive and non-interactive frameworks, respectively. Since mean estimation is intrinsically dependent on key frequencies, precise key collection is vitally important not only for estimating key frequencies but also for deriving accurate mean values. KS-UE is specifically designed to tilt the privacy budget towards the key, thereby enhancing the estimation of keys, while KS-GRR implements a group-and-interactive strategy to identify the top frequent keys, subsequently enabling accurate frequency and mean estimation. Empirical validation supports our theoretical analysis, demonstrating the effectiveness of both KS-UE and KS-GRR. In terms of future work, we aim to enhance the efficiency of the candidate domain and reduce both communication and time complexity. These refinements will potentially allow for the broader implementation of these methodologies in practical applications, thereby contributing significantly to the field of privacy protection.
Acknowledgement: This papers logical organisation and content quality have been enhanced, so the authors thank anonymous reviewers and journal editors for assistance.
Funding Statement: This work is supported by a grant from the National Key R&D Program of China.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Dan Zhao, Chuanwen Lu; data collection: Dan Zhao, Yang Liu; analysis and interpretation of results: Dan Zhao, Yang You; draft manuscript preparation: Dan Zhao, Chuanwen Luo, Ting Chen,Yang Liu. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data is from https://www.kaggle.com/nicapotato/womens-ecommerce-clothing-reviews and https://www.kaggle.com/rmisra/clothing-fit-dataset-for-size-recommendation.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1https://www.kaggle.com/nicapotato/womens-ecommerce-clothing-reviews
2https://www.kaggle.com/rmisra/clothing-fit-dataset-for-size-recommendation
References
1. Chen, R., Li, H., Qin, A., Kasiviswanathan, S. P., Jin, H. (2016). Private spatial data aggregation in the local setting. 2016 IEEE 32nd International Conference on Data Engineering (ICDE), pp. 289–300. Helsinki, Finland. [Google Scholar]
2. Erlingsson, Ú., Pihur, V., Korolova, A. (2014). RAPPOR: Randomized aggregatable privacy-preserving ordinal response. Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, pp. 1054–1067. Scottsdale, Arizona, USA. [Google Scholar]
3. Tang, J., Korolova, A., Bai, X., Wang, X., Wang, X. (2017). Privacy loss in apple’s implementation of differential privacy on macos 10.12. arXiv preprint arXiv:1709.02753. [Google Scholar]
4. Ding, B., Kulkarni, J., Yekhanin, S. (2017). Collecting telemetry data privately. Proceedings of the 31stInternational Conference on Neural Information Processing Systems (NIPS), pp. 3571–3580. Long Beach, CA, USA. [Google Scholar]
5. Qin, Z., Yang, Y., Yu, T., Khalil, I., Xiao, X. et al. (2016). Heavy hitter estimation over set-valued data with local differential privacy. Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pp. 192–203. Vienna, Austria. [Google Scholar]
6. Wang, T., Li, N., Jha, S. (2018). Locally differentially private frequent itemset mining. 2018 IEEE Symposium on Security and Privacy (SP), pp. 127–143. San Francisco, CA, USA. [Google Scholar]
7. Zhao, D., Zhao, S., Chen, H., Liu, R., Li, C. et al. (2023). Hadamard encoding based frequent itemset mining under local differential privacy constraints. Journal of Computer Science and Technology, 38(6), 1403–1422. [Google Scholar]
8. Qin, Z., Yu, T., Yang, Y., Khalil, I., Xiao, X. et al. (2017). Generating synthetic decentralized social graphs with local differential privacy. Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pp. 425–438. Dallas, USA. [Google Scholar]
9. Liu, Y., Zhao, S., Liu, Y., Zhao, D., Chen, H. et al. (2022). Collecting triangle counts with edge relationship local differential privacy. 2022 IEEE 38th International Conference on Data Engineering (ICDE), pp. 2008–2020. Kuala Lumpur, Malaysia. [Google Scholar]
10. Ye, Q., Hu, H., Meng, X., Zheng, H. (2019). PrivKV: Key-value data collection with local differential privacy. 2019 IEEE Symposium on Security and Privacy (SP), pp. 317–331. San Francisco, CA, USA. [Google Scholar]
11. Sun, L., Zhao, J., Ye, X., Feng, S., Wang, T. et al. (2019). Conditional analysis for key-value data with local differential privacy. arXiv preprint arXiv:1907.05014. [Google Scholar]
12. Gu, X., Li, M., Cheng, Y., Xiong, L., Cao, Y. (2020). PCKV: Locally differentially private correlated key-value data collection with optimized utility. 29th USENIX Security Symposium (USENIX Security 20), pp. 967–984. Berkeley, CA, USA. [Google Scholar]
13. Warner, S. L. (1965). Randomized response: A survey technique for eliminating evasive answer bias. Journal of the American Statistical Association, 60(309), 63–69. [Google Scholar] [PubMed]
14. Dwork, C. (2008). Differential privacy: A survey of results. International Conference on Theory and Applications of Models of Computation, pp. 1–19. Xi’an, China. [Google Scholar]
15. Dwork, C., Roth, A. (2014). The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science, 9(3–4), 211–407. [Google Scholar]
16. Kairouz, P., Bonawitz, K., Ramage, D. (2016). Discrete distribution estimation under local privacy. arXiv preprint arXiv:1602.07387. [Google Scholar]
17. Bassily, R., Smith, A. (2015). Local, private, efficient protocols for succinct histograms. Proceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing, pp. 127–135. Portland, OR, USA. [Google Scholar]
18. Wang, T., Blocki, J., Li, N., Jha, S. (2017). Locally differentially private protocols for frequency estimation. Proceedings of the 26th USENIX Security Symposium, pp. 729–745. Vancouver, BC, Canada. [Google Scholar]
19. Wang, N., Xiao, X., Yang, Y., Zhao, J., Hui, S. C. et al. (2019). Collecting and analyzing multidimensional data with local differential privacy. 2019 IEEE 35th International Conference on Data Engineering (ICDE), pp. 638–649. Macau, China. [Google Scholar]
20. Kulkarni, T., Cormode, G., Srivastava, D. (2017). Marginal release under local differential privacy. arXiv preprint arXiv:1711.02952. [Google Scholar]
21. Zhang, Z., Wang, T., Li, N., He, S., Chen, J. (2018). CALM: Consistent adaptive local marginal for marginal release under local differential privacy. Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, pp. 212–229. Copenhagen, Denmark. [Google Scholar]
22. Nguyên, T. T., Xiao, X., Yang, Y., Hui, S. C., Shin, H. et al. (2016). Collecting and analyzing data from smart device users with local differential privacy. arXiv preprint arXiv:1606.05053. [Google Scholar]
23. Ye, Q., Hu, H., Au, M. H., Meng, X., Xiao, X. (2020). Towards locally differentially private generic graph metric estimation. 2020 IEEE 36th International Conference on Data Engineering (ICDE), pp. 1922–1925. Dallas, TX, USA. [Google Scholar]
24. Ye, Q., Hu, H., Au, M., Meng, X., Xiao, X. (2020). LF-GDPR: Graph metric estimation with local differential privacy. IEEE Transactions on Knowledge and Data Engineering (TKDE), 10, 4905–4920. [Google Scholar]
25. Cao, Y., Xiao, Y., Xiong, L., Bai, L. (2019). PriSTE: From location privacy to spatiotemporal event privacy. 2019 IEEE 35th International Conference on Data Engineering (ICDE), pp. 1606–1609. Macau, China. [Google Scholar]
26. Ye, Q., Hu, H., Li, N., Meng, X., Zheng, H. et al. (2021). Beyond value perturbation: Local differential privacy in the temporal setting. IEEE INFOCOM 2021–IEEE Conference on Computer Communications, pp. 1–10. Vancouver, BC, Canada. [Google Scholar]
27. Li, Z., Wang, T., Lopuhaä-Zwakenberg, M., Li, N., Škoric, B. (2020). Estimating numerical distributions under local differential privacy. Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, pp. 621–635. Portland, Oregon, USA. [Google Scholar]
28. Kulkarni, T. (2019). Answering range queries under local differential privacy. Proceedings of the 2019 International Conference on Management of Data, pp. 1832–1834. Amsterdam, Netherlands. [Google Scholar]
29. Arachchige, P. C. M., Bertok, P., Khalil, I., Liu, D., Camtepe, S. et al. (2019). Local differential privacy for deep learning. IEEE Internet of Things Journal, 7(7), 5827–5842. [Google Scholar]
30. Liu, R., Wu, F., Wu, C., Wang, Y., Cao, Y. et al. (2022). PrivateRec: Differentially private training and serving for federated news recommendation. arXiv preprint arXiv:2204.08146. [Google Scholar]
31. Chai, Y., Du, L., Qiu, J., Yin, L., Tian, Z. (2022). Dynamic prototype network based on sample adaptation for few-shot malware detection. IEEE Transactions on Knowledge and Data Engineering, 35(5), 4754–4766. [Google Scholar]
32. Qiu, J., Tian, Z., Du, C., Zuo, Q., Su, S. et al. (2020). A survey on access control in the age of internet of things. IEEE Internet of Things Journal, 7(6), 4682–4696. [Google Scholar]
33. Tian, Z., Luo, C., Qiu, J., Du, X., Guizani, M. (2019). A distributed deep learning system for web attack detection on edge devices. IEEE Transactions on Industrial Informatics, 16(3), 1963–1971. [Google Scholar]
34. Ye, Q., Hu, H., Meng, X., Zheng, H., Huang, K. et al. (2023). PrivKVM*: Revisiting key-value statistics estimation with local differential privacy. IEEE Transactions on Dependable and Secure Computing, 1, 17–35. [Google Scholar]
35. Bassily, R., Nissim, K., Stemmer, U., Thakurta, A. G. (2017). Practical locally private heavy hitters. Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), pp. 2288–2296. Long Beach, CA, USA. [Google Scholar]
36. Bun, M., Nelson, J., Stemmer, U. (2018). Heavy hitters and the structure of local privacy. Proceedings of the 35th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, pp. 435–447. New York, USA. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools