
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Distributed Stochastic Optimization with Compression for Non-Strongly Convex Objectives
School of Information Science and Technology, Fudan University, Shanghai, China
* Corresponding Author: Yuedong Xu. Email:
Computer Modeling in Engineering & Sciences 2024, 139(1), 459-481. https://doi.org/10.32604/cmes.2023.043247
Received 26 June 2023; Accepted 20 October 2023; Issue published 30 December 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
We are investigating the distributed optimization problem, where a network of nodes works together to minimize a global objective that is a finite sum of their stored local functions. Since nodes exchange optimization parameters through the wireless network, large-scale training models can create communication bottlenecks, resulting in slower training times. To address this issue, CHOCO-SGD was proposed, which allows compressing information with arbitrary precision without reducing the convergence rate for strongly convex objective functions. Nevertheless, most convex functions are not strongly convex (such as logistic regression or Lasso), which raises the question of whether this algorithm can be applied to non-strongly convex functions. In this paper, we provide the first theoretical analysis of the convergence rate of CHOCO-SGD on non-strongly convex objectives. We derive a sufficient condition, which limits the fidelity of compression, to guarantee convergence. Moreover, our analysis demonstrates that within the fidelity threshold, this algorithm can significantly reduce transmission burden while maintaining the same convergence rate order as its no-compression equivalent. Numerical experiments further validate the theoretical findings by demonstrating that CHOCO-SGD improves communication efficiency and keeps the same convergence rate order simultaneously. And experiments also show that the algorithm fails to converge with low compression fidelity and in time-varying topologies. Overall, our study offers valuable insights into the potential applicability of CHOCO-SGD for non-strongly convex objectives. Additionally, we provide practical guidelines for researchers seeking to utilize this algorithm in real-world scenarios.Keywords
In modern machine learning problems, datasets are frequently too large to be processed by a single machine or may be distributed across multiple computing nodes due to legal restrictions or cost considerations. In such scenarios, distributed learning has emerged as a viable solution to train models in a decentralized fashion. Each computing node trains on its local data samples, and communicates with other nodes to exchange information and update model parameters. This approach can significantly reduce processing time and has gained increasing attention in recent years.
Formally, we consider an optimization problem of the form
where
where
Consensus-based gradient descent algorithms are extensively researched and employed in distributed learning owing to their simplicity and efficiency. These algorithms enable nodes to exchange parameters with neighboring nodes and incorporate new information from received messages to drive the parameters toward the global average parameter value. Meanwhile, each node computes gradients using its local data samples and updates its parameters using the gradient descent methods.
One limitation of these algorithms is the requirement for exact parameter transmission among nodes, which can be challenging in scenarios where there are restrictions on data transmission amount or high communication latency (e.g., with large neural networks [1] or limited network bandwidth). In such cases, compressing the parameters becomes necessary. However, parameter compression usually results in a decrease in the convergence rate. To address this challenge, Koloskova et al. proposed CHOCO-SGD [2], which was a compressed distributed algorithm designed for strongly convex objective functions. CHOCO-SGD allows for both biased and unbiased compression operators and can achieve arbitrary compression precision. Arbitrary compression precision means that any compression fidelity
However, strong convexity is a restrictive assumption that may not hold in various practical applications, such as in operations research and machine learning. For instance, consider the Lasso problem [3] with an objective function represented as
• We establish a compression fidelity bound for CHOCO-SGD, ensuring its convergence over non-strongly convex functions. This criterion serves as a valuable guideline for researchers and engineers when applying CHOCO-SGD in practical scenarios.
• We rigorously prove that within the compression fidelity threshold, CHOCO-SGD achieves the same convergence rate order as DSGD over non-strongly convex objectives, and compression fidelity only affects the higher-order terms in the rate. This means that CHOCO-SGD effectively reduces the transmitted data without compromising training efficiency.
• We conduct comprehensive experiments to validate our theoretical results. The numerical outcomes show that when controlling compression fidelity above the lower bound, CHOCO-SGD effectively reduces communication costs, while remains a comparable convergence rate to that of DSGD. Additionally, our experiments reveal that CHOCO-SGD fails to converge when the fidelity falls below acceptable limits, implying that this algorithm cannot achieve arbitrary compression fidelity on non-strongly convex objectives. Moreover, we also observe that CHOCO-SGD cannot converge in time-varying network topologies.
Notations. In this paper, we use uppercase letters like X, A to denote various matrices, including parameter matrix, gradient matrix, weight matrix, etc. Lowercase letters with subscripts are used to denote vectors, for example,
Consensus algorithm. For the distributed optimization problem, we want every node to reach an agreement on the global parameter value. The agreement means finding the average of
Distributed optimization. On the basis of consensus algorithms, researchers proposed many distributed gradient-based algorithms [7–12]. In undirected topology, Nedic et al. [7] and Yuan et al. [8] analyzed the convergence of Decentralized Stochastic Gradient Descent algorithm (DSGD) on non-strongly convex objective functions. Lian et al. proved that for nonconvex and Lipschitz-smooth objective functions, DSGD can converge to a stationary point with the rate
Parameter/gradient compression. With the rapid growth of learning models, traditional distributed learning faces significant communication pressure. As a result, Researchers have increasingly focused on designing communication-efficient algorithms [2,18–24]. The proposed methods can generally be classified into three main categories. The first category is quantization. Instead of transmitting precise vectors (such as model parameters or gradients), nodes exchange limited bits that approximate the original vectors. The second category is sparsification, where only a few elements of a vector are transmitted accurately, while the remaining elements are forced to be zero. The third category involves transmitting parameters in some iterations rather than in every iteration. This aims to reduce the amount of transmitted information. All these methods aim to find the optimal parameter value by transmitting less information. Therefore, in this paper, we use the term compression to encompass these methods. Kolovaskova et al. proposed the CHOCO-SGD algorithm [2], a distributed stochastic algorithm over undirected graphs. This algorithm allows for arbitrary compression precision and has been proven to converge for strongly convex objectives. Taheri et al. [25] extended this algorithm to directed graphs for both convex and nonconvex objectives based on the SGP algorithm [15]. Different from this work, our study is based on undirected graphs. Table 1 further illustrates the highlights of this work and the differences between the work involved.

In this section, we will introduce the basic knowledge of distributed optimization and present the classic Distributed Stochastic Gradient Descent (DSGD) algorithm. Additionally, we will discuss the fundamental ideas underlying the CHOCO-SGD algorithm.
We assume that the computing nodes are distributed across an undirected graph
where
The second component of the DSGD algorithm involves parameter updates using stochastic gradient descent. Combining these components, the update rule of DSGD is given as follows:
where

However, when dealing with massive training models, the DSGD algorithm encounters a communication bottleneck. To address this limitation, a straightforward yet effective solution is to compress the parameters before transmitting them over the network. For this purpose, We introduce a compression operator denoted as Q, along with the definition of compression fidelity
Assumption 3.1. The compression operator Q satisfies
We take the expectation in this context because there might be inherent randomness in the compression operators, such as in the case of randomized gossip discussed later. It is worth noting that when
Example 3.1. Examples of compression
• randomized gossip:
where
• Top-k sparsification [20]: for a parameter vector
Through conducting simple experiments, one can observe that when integrating compression directly into the transmitted parameter in Algorithm 1 (i.e., replacing the transmission of
Based on Assumption 3.1, CHOCO-SGD was proposed and is presented in Algorithm 2. As the transmitted parameters are compressed and inexact, each node

Koloskova et al. [2] has proved that Algorithm 2 achieved a convergence rate of
4 Convergence Analysis for Non-Strongly Convex Objectives
In this section, we begin by introducing assumptions regarding the underlying graph structure. As mentioned previously, we use
Assumption 4.1. The underlying graph structure
Assumption 4.2. Given the aggregation weights
where A satisfies
Remark 4.1. Under the undirected graph setting, a doubly stochastic matrix can be easily found. Given an undirected graph
We next introduce several basic assumptions on the objective function and its gradients. Note that these assumptions are common in first-order continuous optimization.
Assumption 4.3. Each local objective function
and L-smooth, i.e., there exists a constant
The definition of L-smooth is equivalent to the following inequality:
Assumption 4.4. There exists a constant M, such that
Assumption 4.5. There exists a constant
Assumptions 4.4 and 4.5 bound the local gradients and variance with respect to data samples, respectively. The latter assumption can be easily satisfied when the dataset across nodes is independent and identically distributed. Besides, the following asymptotic property of A implies that all the elements in
Lemma 4.1. If
where
This lemma states that as matrix multiplication progresses, all elements of
Theorem 4.1. Under Assumptions 3.1 and 4.1–4.5, and assume
where
and
Let
Furthermore, the expression
Proof. For simplicity, we let
and then the updating rule of Algorithm 2 can be expressed as
Note that when we use the compression operator Q on a matrix, we mean compressing every column of that matrix. Since the underlying topology is fixed, node
Dividing both sides by
The second term can be processed as follows:
where the inequality comes from Cauchy-Schwarz inequality. The two terms in the right-hand side (RHS) of the last equation can be bounded as follows:
where the last inequality applies Assumption 4.5. And for the second term, we have
where the last inequality comes from Assumption 4.3 and the following result related to
Plugging the results in Eqs. (12) and (13) back into Eq. (11) yields the bound for
Now we handle the third term in the RHS of Eq. (10) as follows:
In the first equation, we use
Arranging this inequality and choosing
By summing both sides for
where we apply
Since A is doubly stochastic, we get
Therefore, after
where we use
and
Now, substituting Eqs. (23) and (24) to Eq. (22), we have
We process the first term of RHS of Eq. (25) in the following way:
where the last inequality comes from
where the last inequality applies Assumption 4.5. Then Eq. (25) can be written as
This motivates us to bound
where the second and the last inequalities come from Eq. (8) and
Next we use induction to prove that when
When
By setting
the RHS of Eq. (31) will be less than
With
By substituting this result to Eq. (19), we can get Theorem 4.1.
Testbed setting and topology. Our experiments are conducted on a testbed of 8 servers, each with an 8-core Intel Xeon W2140b CPU at 3.20 GHz, a 32 GB DDR4 RAM and a Mellanox Connect-X3 NIC supporting 10 GbE links. We use PyTorch as the experiment platform and employ its Distributed Data-Parallel Training (DDP) paradigm to realize parameter communication among the 8 servers. The main topology in experiments is a ring topology, as shown in Fig. 1a. Ring topology can be used in Local Area Network (LAN) or Wide Area Network (WAN) networks, and is also commonly used [28] in distributed learning.
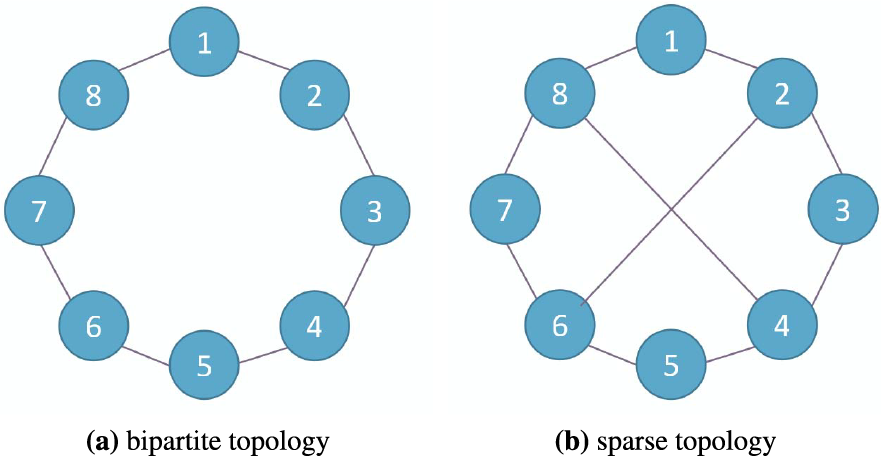
Figure 1: Undirected topologies with 8 nodes
We consider a task where all nodes aim to classify images in the MNIST or CIFAR-10 dataset into 10 classes using a linear neural network. The key features of both datasets are listed in Table 2. The objective function for this task is cross-entropy loss. The cross-entropy loss of a data batch is defined as
where
We evaluate the performance of the CHOCO-SGD algorithm in comparison to the DSGD baseline. In CHOCO-SGD, we examine the efficacy of two compression operators outlined in Example 1: randomized gossip with
The results in Fig. 2a demonstrate that CHOCO-SGD and DSGD exhibit comparable convergence rates, with similar reductions in loss after the same number of episodes. To distinguish the curves, we scale the loss values to the range
where
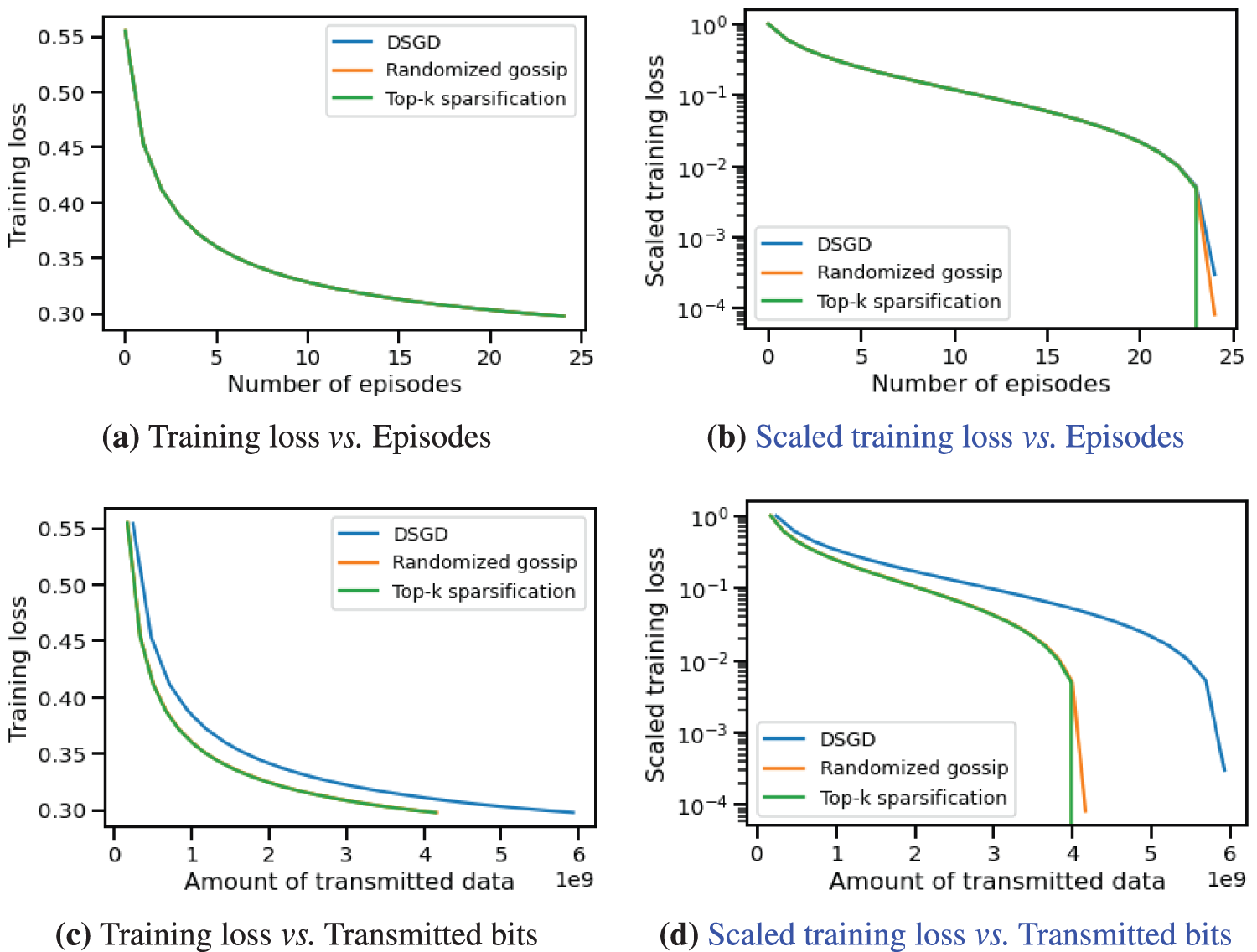
Figure 2: Training loss vs. episodes/transmitted data amount of CHOCO-SGD and DSGD on MNIST Dataset
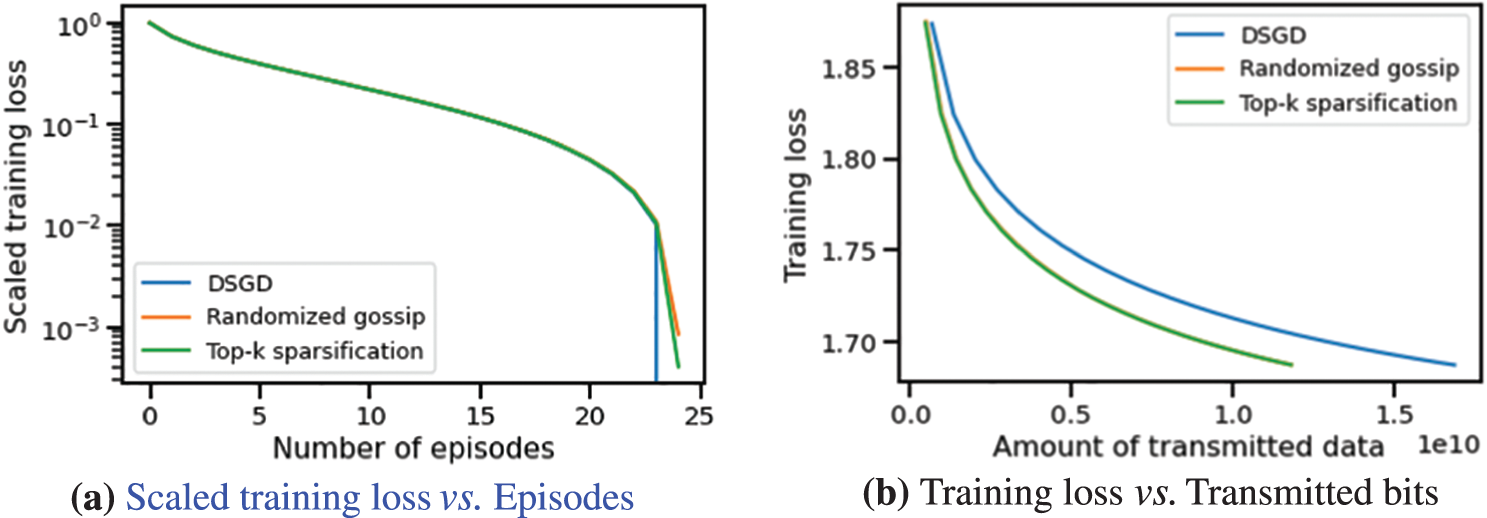
Figure 3: Training loss vs. episodes/transmitted data amount of CHOCO-SGD and DSGD on CIFAR-10 Dataset
5.3 Sensitivity to Compression Fidelity
To further investigate the impact of compression fidelity, we conduct several experiments by controlling the values of
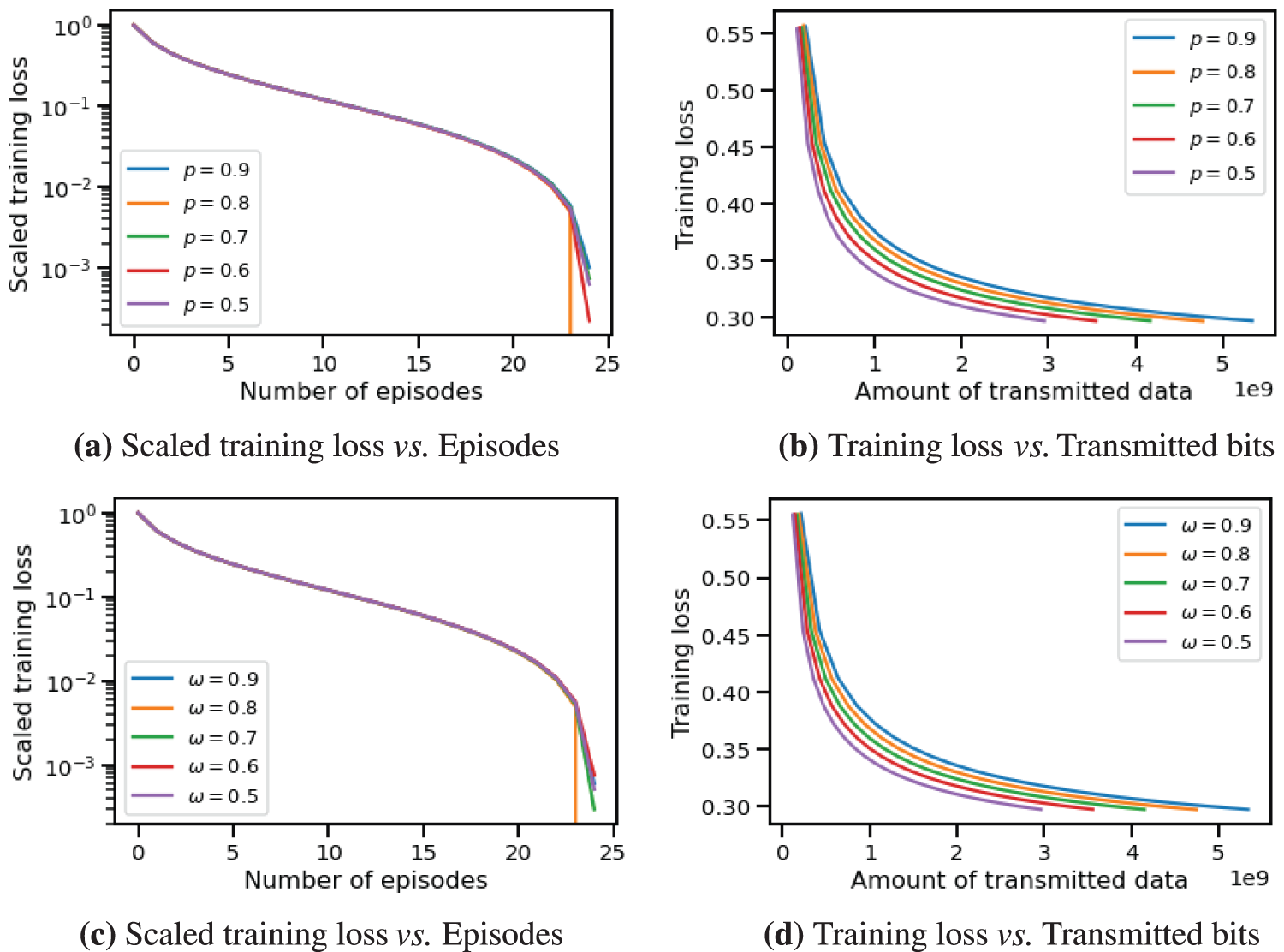
Figure 4: Training loss of CHOCO-SGD with randomized gossip (a), (b) and with Top-k sparsification (c), (d) on MNIST dataset. Both
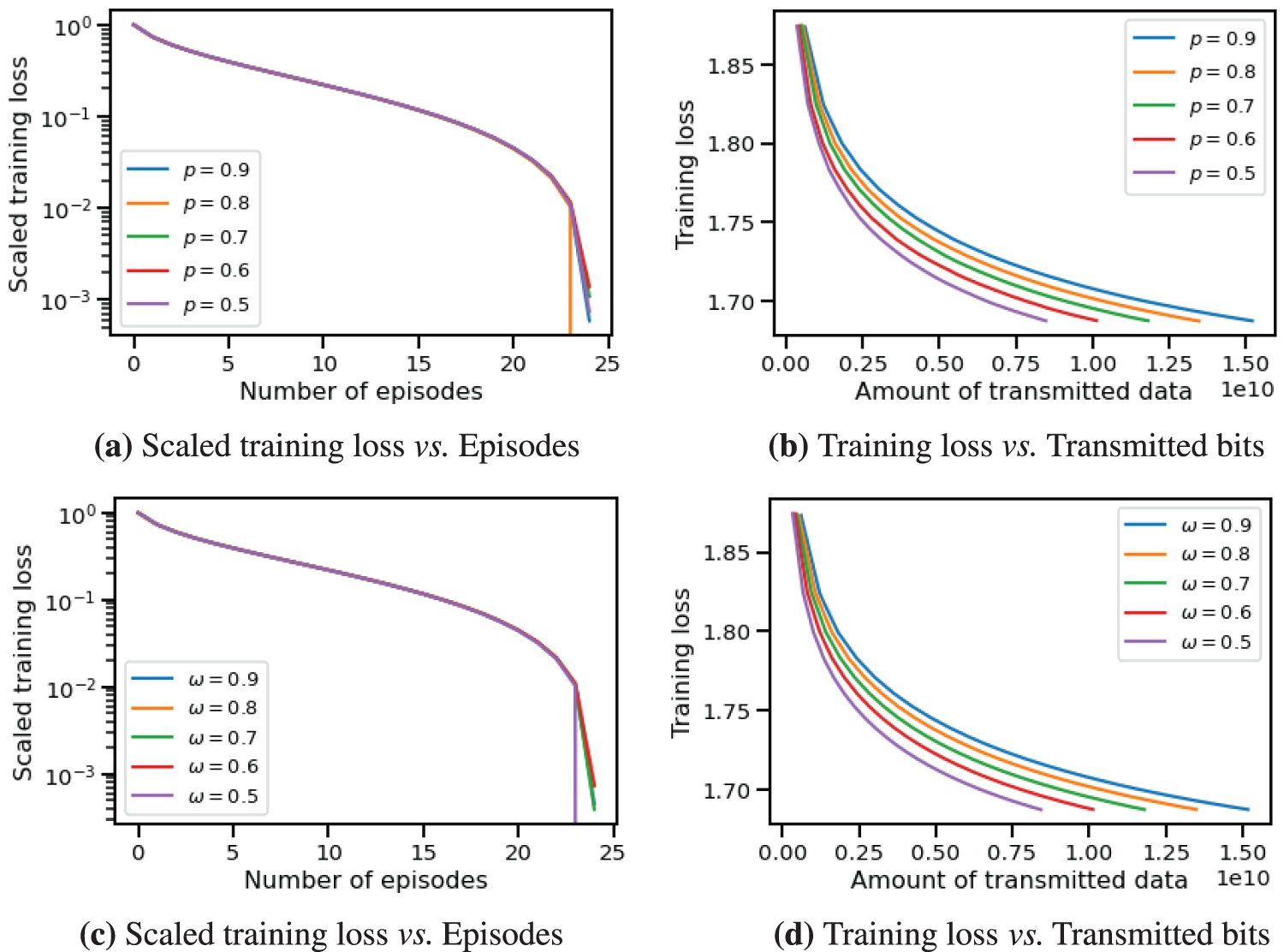
Figure 5: Training loss of CHOCO-SGD with randomized gossip (a), (b) and with Top-k sparsification (c), (d) on CIFAR-10 dataset. Both
Furthermore, we conduct experiments to determine if CHOCO-SGD fails to converge when the compression fidelity is small for non-strongly convex objectives, as stated in Eq. (6). Specifically, for randomized gossip and Top-k sparsification, we set both
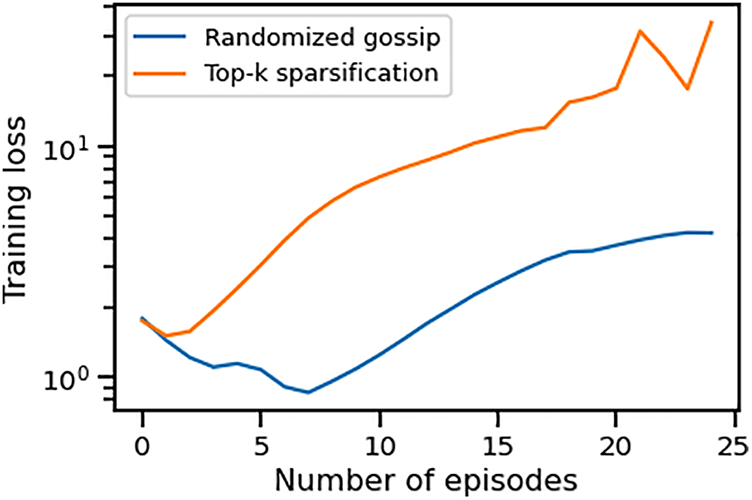
Figure 6: Convergence of CHOCO-SGD with low compression fidelity on MNIST dataset
5.4 Robustness towards Learning Hyperparameters
In this section, we study the influence of hyperparameters (learning rate
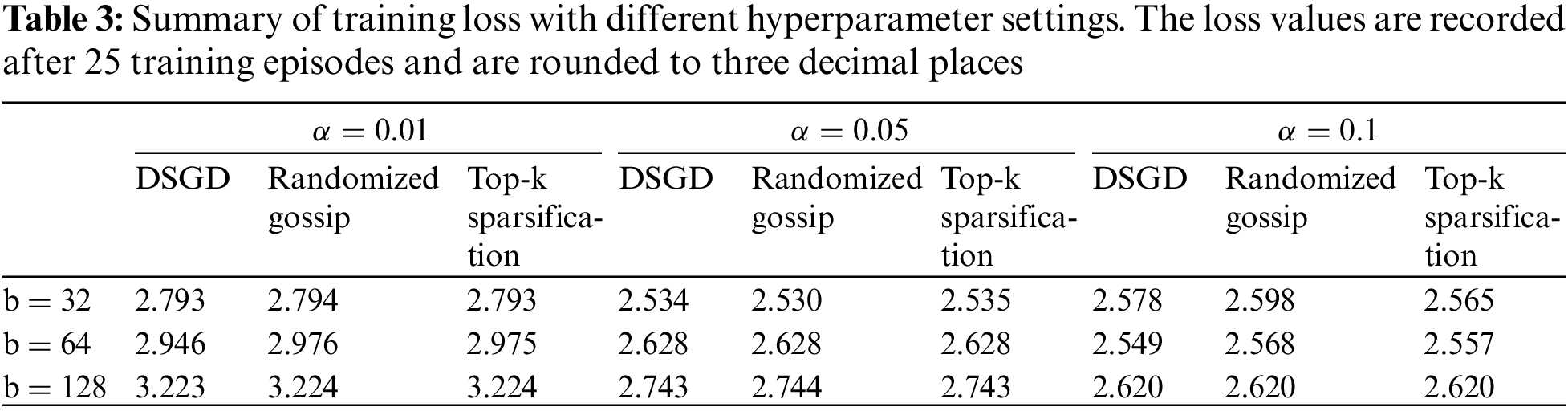
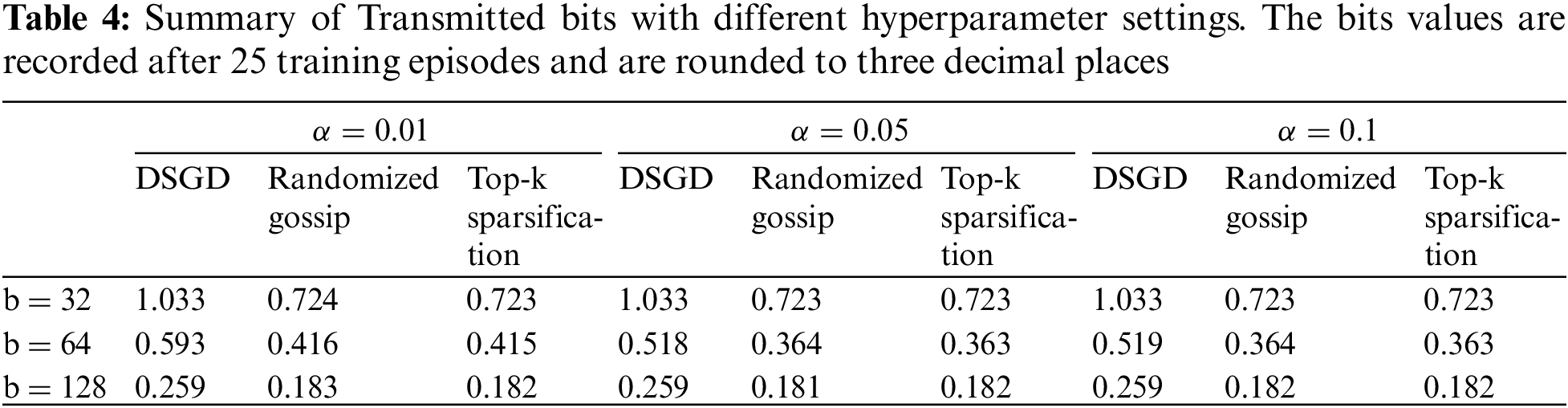
5.5 Applicability to Various Topologies
5.5.1 Investigating Different Fixed Topologies
To explore the algorithm’s applicability for non-strongly convex objectives, we test the convergence performance of CHOCO-SGD on two different topologies, as displayed in Fig. 7. Fig. 7a shows a bipartite topology, where nodes
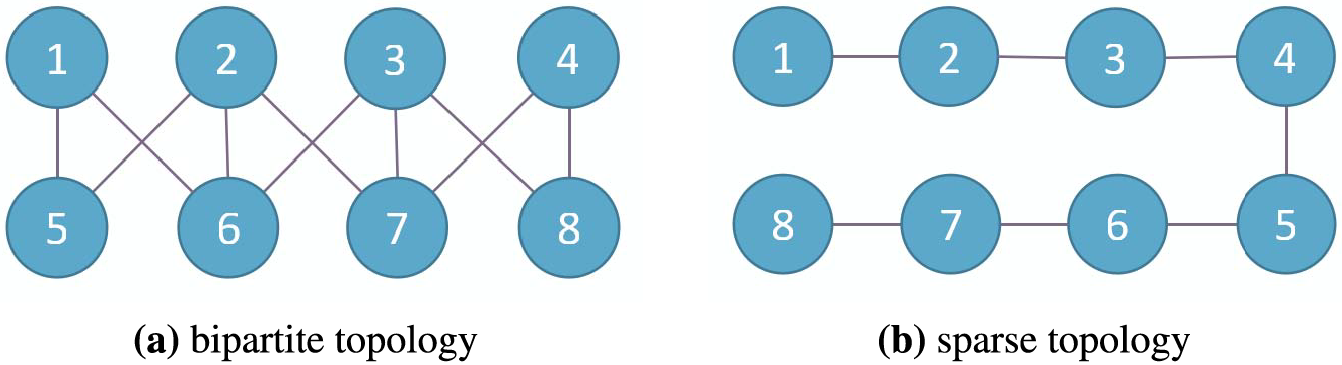
Figure 7: Different undirected and connected topologies
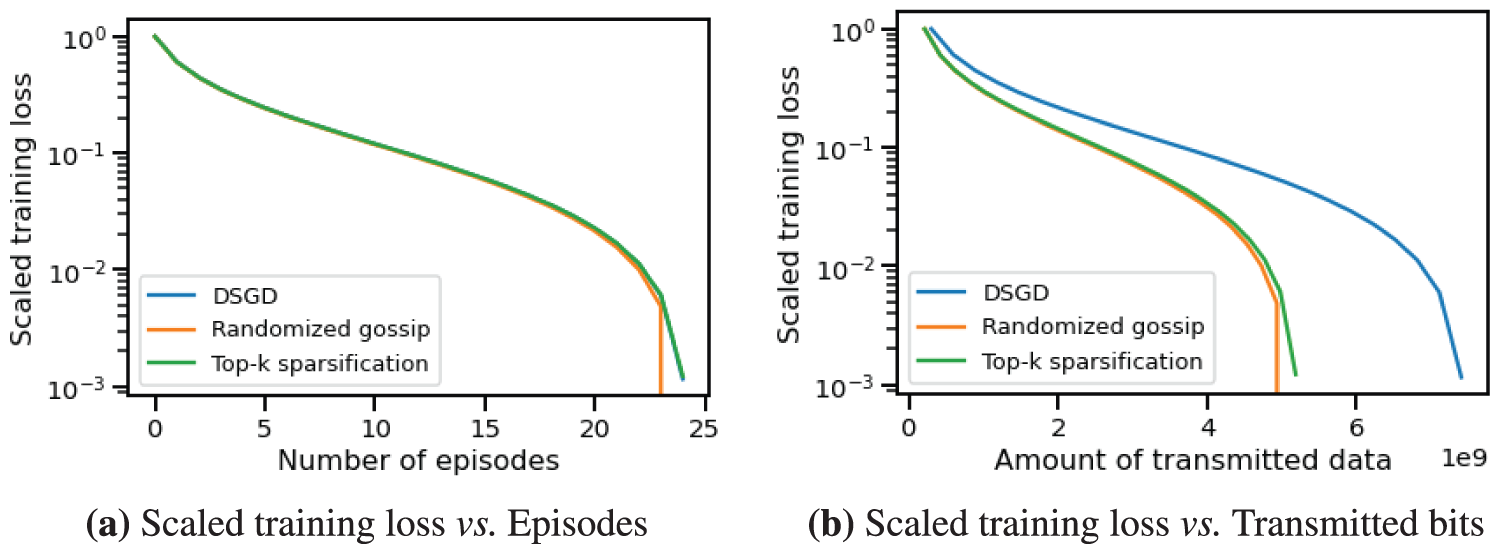
Figure 8: Training loss vs. episodes/transmitted data amount of CHOCO-SGD and DSGD on bipartite topology Fig. 7a
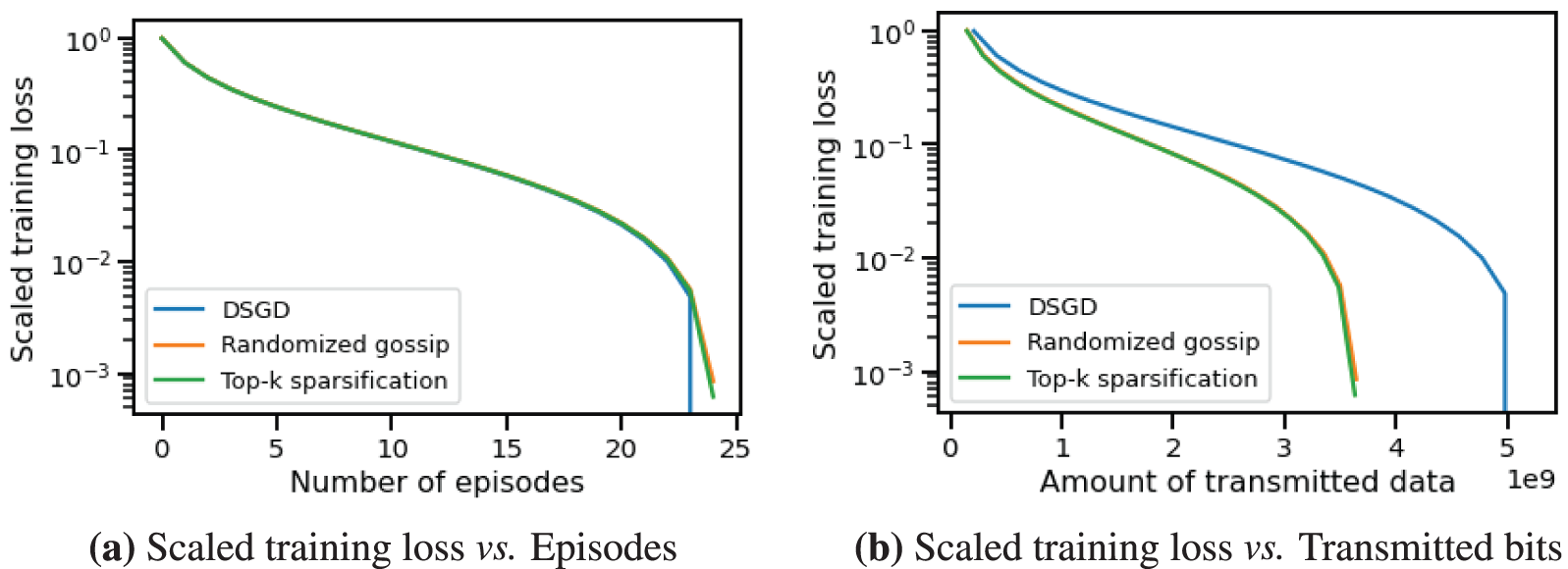
Figure 9: Training loss vs. episodes/transmitted data amount of CHOCO-SGD and DSGD on sparse topology Fig. 7b
We further explore the impact of time-varying topologies on the convergence of CHOCO-SGD. The training topology alternates between the two graphs in Fig. 1. For instance, if the nodes are initially distributed over the left topology, in the next iteration, they will be connected according to the right topology. It is important to note that this setup still ensures connectivity (as stated in Assumption 4.1). We set the compression coefficients to
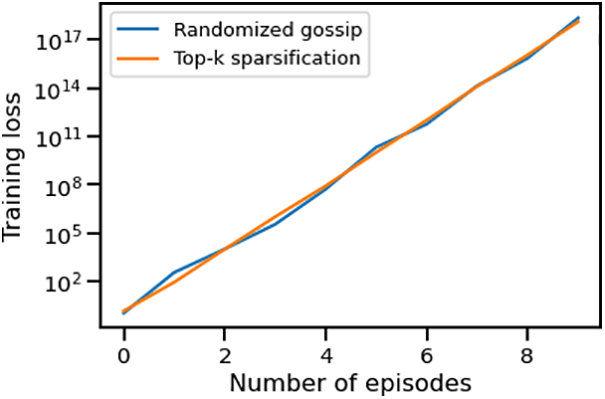
Figure 10: Convergence of CHOCO-SGD on time-varying topologies
In this work, we study CHOCO-SGD algorithm in the case that the objective function is non-strongly convex. We provide the first theoretical analysis of this situation and prove that when controlling compression fidelity within a certain threshold, it has the same convergence rate order as DSGD. Experimental results validate the theoretical analysis by demonstrating that CHOCO-SGD converges more quickly than DSGD when transmitting the same data amount. Besides, a low compression fidelity and time-varying topology can make CHOCO-SGD not converge in the end.
There are several open topics worthy of investigating in our future work. The first one is to explore CHOCO-SGD’s performance in more complex non-convex scenarios, which can provide a deeper understanding of its capabilities. Besides, it will be meaningful to improve this algorithm to achieve arbitrary compression fidelity for non-strongly convex functions, since most real-world problems are non-strongly convex and such improvement can enhance CHOCO-SGD’s durability and applicability.
Acknowledgement: The authors are grateful for the theoretical support by Simiao Jiao. Besides, this paper’s logical rigor, integrity, and content quality have been greatly enhanced, so the authors also wish to express their appreciation to anonymous reviewers and journal editors for assistance.
Funding Statement: This work was supported in part by the Shanghai Natural Science Foundation under the Grant 22ZR1407000.
Author Contributions: The authors’ contributions to this manuscript are as follows: study conception: X.L., Y.X.; experiment design and data collection: X.L.; theoretical analysis, interpretation of results, and draft manuscript preparation: X.L., Y.X. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data, including MNIST and CIFAR-10 datasets, used in this manuscript is accessible via the following link: https://www.kaggle.com/datasets.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1aij represents the entry in the ith row and the jth column of A.
References
1. Jiang, X., Hu, Z., Wang, S., Zhang, Y. (2023). A survey on artificial intelligence in posture recognition. Computer Modeling in Engineering & Sciences, 137(1), 35–82. https://doi.org/10.32604/cmes.2023.027676 [Google Scholar] [PubMed] [CrossRef]
2. Koloskova, A., Stich, S., Jaggi, M. (2019). Decentralized stochastic optimization and gossip algorithms with compressed communication. International Conference on Machine Learning, Long Beach, California, USA. [Google Scholar]
3. Allen-Zhu, Z., Yuan, Y. (2016). Improved SVRG for non-strongly-convex or sum-of-non-convex objectives. International Conference on Machine Learning, New York, NY, USA. [Google Scholar]
4. Rajalakshmi, M., Rengaraj, R., Bharadwaj, M., Kumar, A., Naren Raju, N. et al. (2018). An ensemble based hand vein pattern authentication system. Computer Modeling in Engineering & Sciences, 114(2), 209–220. https://doi.org/10.3970/cmes.2018.114.209 [Google Scholar] [CrossRef]
5. Saber, R. O., Murray, R. M. (2003). Consensus protocols for networks of dynamic agents. Proceedings of the 2003 American Control Conference, pp. 951–956. Denver, CO, USA. [Google Scholar]
6. Xiao, L., Boyd, S. (2004). Fast linear iterations for distributed averaging. Systems & Control Letters, 53(1), 65–78. [Google Scholar]
7. Nedic, A., Ozdaglar, A. (2009). Distributed subgradient methods for multi-agent optimization. IEEE Transactions on Automatic Control, 54(1), 48–61. [Google Scholar]
8. Yuan, K., Ling, Q., Yin, W. (2016). On the convergence of decentralized gradient descent. SIAM Journal on Optimization, 26(3), 1835–1854. [Google Scholar]
9. Sun, H., Lu, S., Hong, M. (2020). Improving the sample and communication complexity for decentralized non-convex optimization: Joint gradient estimation and tracking. International Conference on Machine Learning, pp. 9154–9165. International Machine Learning Society (IMLS). [Google Scholar]
10. Tang, H., Gan, S., Zhang, C., Zhang, T., Liu, J. (2018). Communication compression for decentralized training. In: Advances in neural information processing systems 31, pp. 7652–7662. [Google Scholar]
11. Sun, Y., Scutari, G., Daneshmand, A. (2022). Distributed optimization based on gradient tracking revisited: Enhancing convergence rate via surrogation. SIAM Journal on Optimization, 32(2), 354–385. [Google Scholar]
12. Jiang, X., Zeng, X., Sun, J., Chen, J. (2023). Distributed proximal gradient algorithm for non-convex optimization over time-varying networks. IEEE Transactions on Control of Network Systems, 10(2), 1005–1017. [Google Scholar]
13. Lian, X., Zhang, C., Zhang, H., Hsieh, C. J., Zhang, W. et al. (2017). Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent. In: Advances in neural information processing systems. Long Beach, California, USA. [Google Scholar]
14. Shi, W., Ling, Q., Wu, G., Yin, W. (2015). Extra: An exact first-order algorithm for decentralized consensus optimization. SIAM Journal on Optimization, 25(2), 944–966. [Google Scholar]
15. Assran, M., Loizou, N., Ballas, N., Rabbat, M. (2019). Stochastic gradient push for distributed deep learning. International Conference on Machine Learning, Long Beach, California, USA, PMLR. [Google Scholar]
16. Nedić, A., Olshevsky, A., Rabbat, M. G. (2018). Network topology and communication-computation tradeoffs in decentralized optimization. Proceedings of the IEEE, 106(5), 953–976. [Google Scholar]
17. Nedic, A. (2020). Distributed gradient methods for convex machine learning problems in networks: Distributed optimization. IEEE Signal Processing Magazine, 37(3), 92–101. [Google Scholar]
18. Li, Z., Richtárik, P. (2021). Canita: Faster rates for distributed convex optimization with communication compression. In: Advances in neural information processing systems 34, pp. 13770–13781. [Google Scholar]
19. Tang, Z., Shi, S., Li, B., Chu, X. (2022). GossipFL: A decentralized federated learning framework with sparsified and adaptive communication. IEEE Transactions on Parallel and Distributed Systems, 34(3), 909–922. [Google Scholar]
20. Stich, S. U., Cordonnier, J. B., Jaggi, M. (2018). Sparsified sgd with memory. In: Advances in neural information processing systems. Montréal, Canada. [Google Scholar]
21. Wangni, J., Wang, J., Liu, J., Zhang, T. (2018). Gradient sparsification for communication-efficient distributed optimization. In: Advances in neural information processing systems 31, pp. 1299–1309. [Google Scholar]
22. Bernstein, J., Wang, Y. X., Azizzadenesheli, K., Anandkumar, A. (2018). signSGD: Compressed optimisation for non-convex problems. International Conference on Machine Learning, Stockholm, Sweden. [Google Scholar]
23. Reisizadeh, A., Mokhtari, A., Hassani, H., Pedarsani, R. (2019). An exact quantized decentralized gradient descent algorithm. IEEE Transactions on Signal Processing, 67(19), 4934–4947. [Google Scholar]
24. Karimireddy, S. P., Rebjock, Q., Stich, S., Jaggi, M. (2019). Error feedback fixes signsgd and other gradient compression schemes. International Conference on Machine Learning, Long Beach, California, USA. [Google Scholar]
25. Taheri, H., Mokhtari, A., Hassani, H., Pedarsani, R. (2020). Quantized decentralized stochastic learning over directed graphs. International Conference on Machine Learning, vol. 119, pp. 9324–9333. [Google Scholar]
26. DeGroot, M. H. (1974). Reaching a consensus. Journal of the American Statistical Association, 69(345), 118–121. [Google Scholar]
27. Merris, R. (1997). Doubly stochastic graph matrices. Publikacije Elektrotehničkog fakulteta. Serija Matematika, (8), 64–71. [Google Scholar]
28. Wang, Z., Hu, Y., Yan, S., Wang, Z., Hou, R. et al. (2022). Efficient ring-topology decentralized federated learning with deep generative models for medical data in ehealthcare systems. Electronics, 11(10), 1548. [Google Scholar]
Appendix A. Proof of Lemma 4.1
We firstly prove that for any matrix
and
We can obtain
where
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools