
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

An Intelligent Sensor Data Preprocessing Method for OCT Fundus Image Watermarking Using an RCNN
1 College of Biomedical Information and Engineering, Hainan Medical University, Haikou, 571199, China
2 TJ-YZ School of Network Science, Haikou University of Economics, Haikou, 571127, China
3 Department of Earth System Science, Ministry of Education Key Laboratory for Earth System Modeling, Institute for Global Change Studies, Tsinghua University, Beijing, 100084, China
* Corresponding Author: Qiong Chen. Email:
(This article belongs to the Special Issue: AI-Driven Intelligent Sensor Networks: Key Enabling Theories, Architectures, Modeling, and Techniques)
Computer Modeling in Engineering & Sciences 2024, 138(2), 1549-1561. https://doi.org/10.32604/cmes.2023.029631
Received 28 February 2023; Accepted 29 May 2023; Issue published 17 November 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Watermarks can provide reliable and secure copyright protection for optical coherence tomography (OCT) fundus images. The effective image segmentation is helpful for promoting OCT image watermarking. However, OCT images have a large amount of low-quality data, which seriously affects the performance of segmentation methods. Therefore, this paper proposes an effective segmentation method for OCT fundus image watermarking using a rough convolutional neural network (RCNN). First, the rough-set-based feature discretization module is designed to preprocess the input data. Second, a dual attention mechanism for feature channels and spatial regions in the CNN is added to enable the model to adaptively select important information for fusion. Finally, the refinement module for enhancing the extraction power of multi-scale information is added to improve the edge accuracy in segmentation. RCNN is compared with CE-Net and MultiResUNet on 83 gold standard 3D retinal OCT data samples. The average dice similarly coefficient (DSC) obtained by RCNN is 6% higher than that of CE-Net. The average 95 percent Hausdorff distance (95HD) and average symmetric surface distance (ASD) obtained by RCNN are 32.4% and 33.3% lower than those of MultiResUNet, respectively. We also evaluate the effect of feature discretization, as well as analyze the initial learning rate of RCNN and conduct ablation experiments with the four different models. The experimental results indicate that our method can improve the segmentation accuracy of OCT fundus images, providing strong support for its application in medical image watermarking.Keywords
The application of optical coherence tomography (OCT) images can impact the privacy of patients because they record important information about patients with fundus diseases [1]. Watermarks can provide reliable and secure copyright protection for OCT fundus images [2,3]. Moreover, image segmentation, an essential computer-aided diagnosis technology, has extensive applications and research value in medical image processing [4]. Image segmentation can extract regions of interest and measure the size, volume, or capacity of organs, tissues, and lesions, enabling 3D reconstruction and visualization of medical images [5]. Therefore, effective image segmentation is helpful for promoting OCT image watermarking.
Deep learning is an efficient method for data analysis [6,7]. Jiang et al. addressed the reliability concerns of zeroing neural networks using a robust neural dynamic model [8]. Wu et al. developed an unsupervised generative adversarial network to effectively fuse panchromatic and multispectral images [9]. Recently, deep learning technology has attracted much attention in medical image segmentation owing to its success in vision applications [10–13]. Kepp et al. used the convolutional neural network (CNN) to produce robust and topologically correct retinal segmentation [14]. Masood et al. used deep learning and morphological operations to accurately segment the choroid layer and Bruch’s membrane [15].
Although deep learning technology can improve the efficiency of segmentation, it still faces performance bottlenecks caused by poor data quality [16,17]. Feature discretization is an effective image preprocessing technology [18]. It can convert continuous attributes in OCT images into discrete attributes, weakening the negative effects of low-quality data. Moreover, feature discretization can analyze incomplete data [19]. Therefore, feature discretization is a feasible scheme to raise the accuracy of segmentation methods based on deep learning technology.
Current mainstream discretization methods are based on information entropy [20], class-attribute correlation [21], Chi-square [22], and rough sets [18]. Rough sets can mine important knowledge through quantifying the uncertainty of data. Phophalia et al. used rough set theory to denoise Magnetic Resonance Imaging (MRI) data [23]. Huang et al. utilized rough sets to enhance the overall performance of the denoising algorithms [24]. Chen et al. combined rough sets and fuzzy sets to discretize mixed pixels [18]. The rough-set-based discretization methods can adapt to most application scenarios because they do not need prior knowledge. However, the optimal discretization of continuous attributes is an NP-hard problem [25]. Swarm intelligence algorithms are often used to solve such problems [26]. The genetic algorithm (GA), an efficient global optimization algorithm, has the characteristic of parallelism and is independent of gradient calculation [27]. It has been shown to have clear advantages in solving discretization problems [25].
OCT images have a lot of low-quality data, which seriously affects the performance of segmentation methods. In addition, there is a lack of expert knowledge in the medical field. To this end, we propose an effective segmentation method for OCT fundus image watermarking using a rough convolutional neural network (RCNN). Our work is as follows:
• We design the rough-set-based feature discretization module to preprocess the input data;
• We add a dual attention mechanism for feature channels and spatial regions in the CNN, enabling the model to adaptively select important information for fusion;
• We add the refinement module to enhance the extraction power of multi-scale information, improving the edge accuracy in segmentation.
We compare RCNN with the mainstream OCT fundus image segmentation algorithms. Experiments show that RCNN can weaken the negative effects of low-quality data in OCT fundus images without any prior knowledge and can accurately segment lesions, which provides strong support for its application in medical image watermarking.
The remaining part of this article is arranged as follows: the relevant concepts are introduced in Section 2; Section 3 demonstrates our method; Section 4 analyzes and discusses the experimental results; and Section 5 concludes the whole work.
We introduce the basic concepts of an informed decision table and feature discretization and provide a description of the rough set and the GA. In addition, we illustrate the deep attention mechanism.
2.1 Information Decision Table
The information decision table is a quadruple
Industrial big data contain a lot of noise and redundant information [28–30]. Feature discretization technology divides continuous features in the data into subintervals associated with a group of discrete values [18]. Feature discretization can not only greatly reduce the data size but can also weaken the negative effects of low-quality data, improving the efficiency of medical image processing. Brightness is a continuous condition attribute of OCT fundus image. The execution order of discretization algorithm includes top-down and bottom-up. In top-down discretization, the entire value domain is regarded as an original interval, and the discrete subintervals are obtained by iteratively splitting intervals. In bottom-up discretization, starting from a series of intervals formed by all attribute values, discretization result is derived by continuously merging adjacent intervals. Fig. 1 depicts the top-down feature discretization of OCT fundus image. First, all brightness values are sorted and de-duplicated to generate initial breakpoints. Second, a subset of the initial breakpoint set is chosen to split intervals according to the adopted discretization criterion, and the temporary discretization result generated by each breakpoint selection is evaluated. Finally, the discretization result satisfying the termination condition is output.

Figure 1: Top-down feature discretization of optical coherence tomography fundus image
Rough set can efficiently deal with the uncertainty information [31]. Rough set uses knowledge to classify data. Two-tuple
The feature discretization based on rough sets evaluates the discretization scheme by the dependence of X with respect to R. The dependence of X with respect to R is given by
where
GA is a global optimization algorithm [25]. It can achieve satisfactory performance on many complex optimization problems. Fig. 2 shows the implementation process of GA. First, the parameter set of the given problem is encoded, and the fitness function is constructed. Individuals with smaller fitness are more likely to be eliminated in the evolutionary process. Second, the population is initialized, and the population is evaluated by calculating the fitness function values of all individuals. If the quality of the contemporary population does not meet the requirements, genetic operations are carried out to produce the next generation of population. This loops until the termination conditions have been satisfied. Finally, the solution corresponding to the optimal individual is output.

Figure 2: Implementation process of GA
There are three basic operations in GA: selection, crossover, and mutation. The selection operation retains the superior individuals with large fitness and eliminates the inferior individuals with small fitness in the population. In this way, high-quality genes can be inherited by the next generation of the population. The crossover operation refers to the exchange and recombination of the partial segments of two paternal chromosomes to produce new chromosomes. The mutation operation refers to the modification of values at certain loci of a chromosome. GA conducts the above three basic operations on each generation of the population to optimize the population by simulating the laws of inheritance and evolution for a biological gene.
To facilitate modeling of the discretization problem, we encode the candidate breakpoint set through binary encoding. The length of a binary code string is the number of elements in the set of candidate breakpoints. The value 1 means that the corresponding breakpoint is chosen, while the value 0 means that the corresponding breakpoint is discarded. The binary code string represents a discretization scheme.
2.5 Deep Supervised Attention Mechanism
The attention mechanism enables neural networks to focus on important information, thus improving the learning efficiency of networks [32]. The deep supervised attention mechanism has a stronger ability to extract important features, as shown in Fig. 3. The rough segmentation map is formed by deep supervision. The relationship between area objects and pixels is constructed by the rough segmentation map and the raw input, which attains the mapping of the representation of pixels to area objects. Then, the representation of pixels with respect to their categories is enhanced by reverse mapping [33]. This way, the segmentation performance can be optimized.
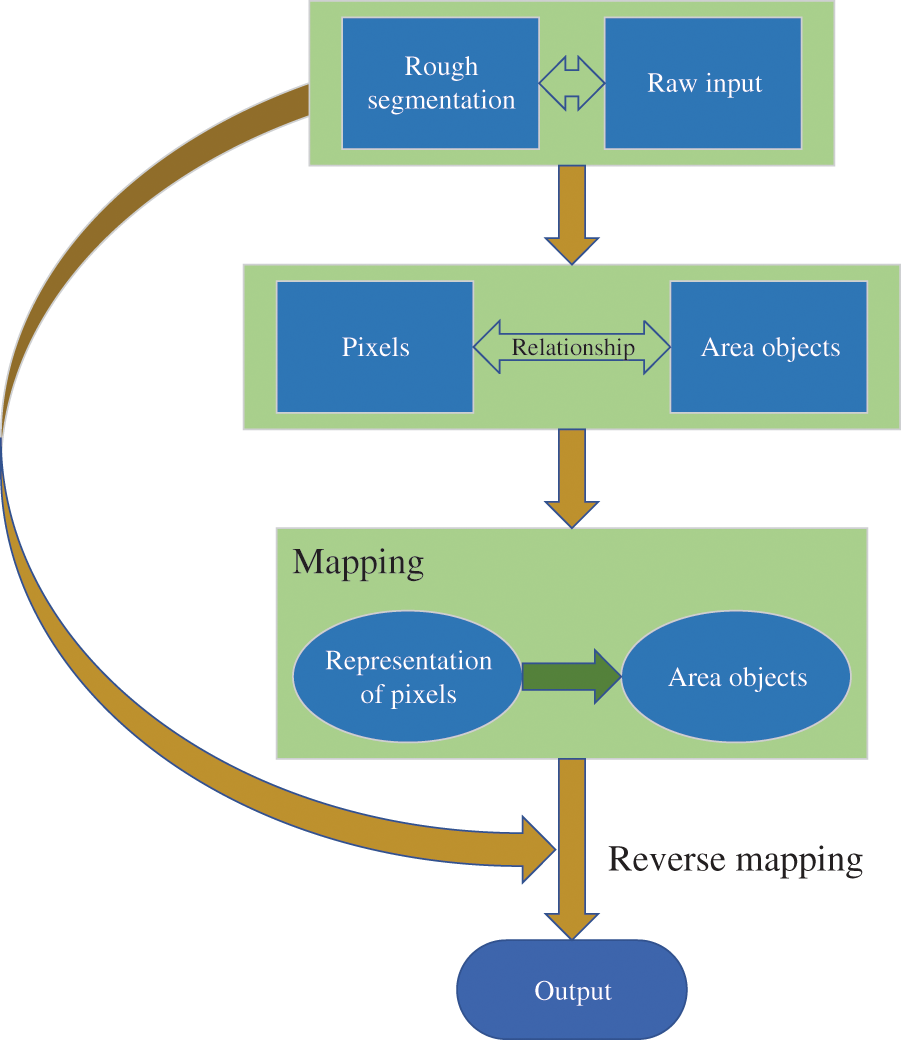
Figure 3: Working principle of the deep supervised attention mechanism
3 OCT Fundus Image Segmentation Based on RCNN
First, we establish the fitness function based on rough sets. We then design the loss function of the proposed RCNN. Finally, we expound on the flow of RCNN.
3.1 Fitness Function Based on Rough Sets
Let U be the set of pixels in an OCT image, k be the number of segmentation categories, B be the feature of brightness, and
The quality of discretization is determined by the average dependence and breakpoints. Assuming that
where
Our main function consists of dice similarity coefficient (DSC) loss
where k is the number of segmentation categories,
Our network handles 3D blocks of size 64 × 64 × 64. For each input 3D patch, the network outputs an SRF probability map of the same size as the input in an end-to-end manner. In the beginning, a series of feature maps with different resolutions are extracted. The shallow feature maps contain the high-resolution details used to accurately delineate the SRF boundary, while the deep feature maps contain coarse and high-level information, which are helpful in predicting the overall profile of SRF. Our backbone network uses the residual structure with forward skip connections as the underlying convolutional module of the segmentation model, which is conducive to the propagation of gradient information. We add a dual attention mechanism of spatial regions and feature channels in the CNN and use the refinement module to enhance the extraction power of multi-scale information. The size of convolution kernel is 3 × 3 × 3. ReLU is chosen as the activation function [34].
Fig. 4 presents the basic framework of RCNN. We add the rough-set-based feature discretization module to the improved CNN. Discretizing the brightness values of all pixels can eliminate redundant information and can also weaken the interference of noise. RCNN combines rough sets and the CNN organically to raise the segmentation accuracy of the network while considering both interpretability and computational efficiency.

Figure 4: OCT fundus image segmentation based on RCNN
We explain the source of experimental data and the experimental platform. We then compare RCNN with the mainstream segmentation methods and analyze the results.
We use 83 gold standard 3D retinal OCT data with a resolution of 1024 × 512 × 128 for the experiments. The dataset contains 10624 2D slices with a resolution of 1024 × 512, of which 7680 comprise the training set, 1280 comprise the validation data, and 1664 comprise the test set. OCT fundus images contain the four types of regions: background, retinal edema area (REA), pigment epithelium detachment (PED), and SRF, which account for about 38.27%, 61%, 0.03%, and 0.7% of the total area, respectively.
The experimental equipment is a server with Intel Xeon CPU processor, 16 GB memory, and an NVIDIA Tesla V100 PCIe GPU (11 GB video memory). The design and testing of the algorithm and the visualization of the experimental results are implemented in the environment of Python 3.8 [35].
The initial learning rate of the network is 1e-3. When the program runs to the 3000th iteration, the initial learning rate is updated to 0.1 times the current learning rate. When the program runs to the 4500th iteration, the initial learning rate is updated again to 0.1 times the current learning rate. The batch size is 4. The network stops training after 6000 iterations.
We compare RCNN with two mainstream OCT image segmentation methods, CE-Net [10] and MultiResUNet [36]. We use DSC, 95 percent Hausdorff distance (95HD), and average symmetric surface distance (ASD) as evaluation indicators. Table 1 shows the comparison results of segmentation algorithms.
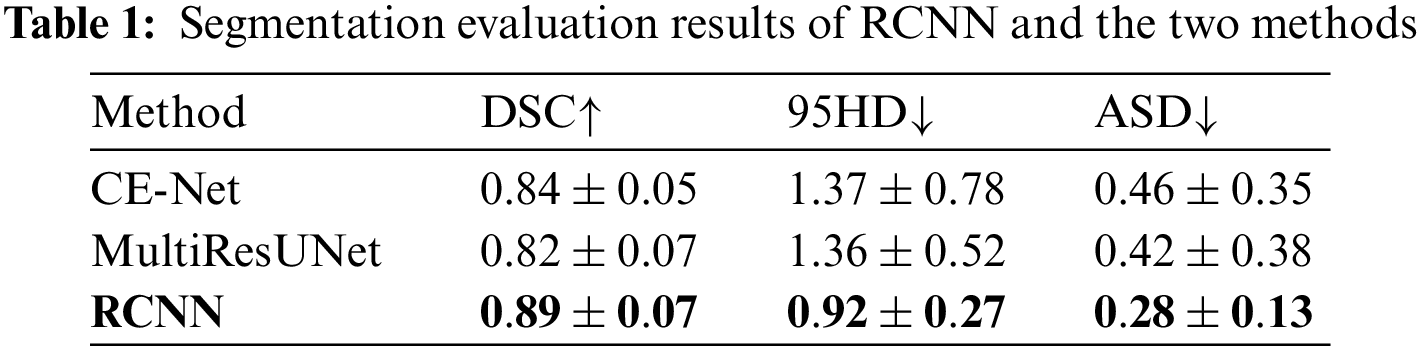
RCNN is superior to CE-Net and MultiResUNet in all evaluation indicators. The average DSC, average 95HD, and average ASD obtained by RCNN are 0.89, 0.92, and 0.28, respectively. The average DSC obtained by CE-Net is second only to RCNN. The average DSC obtained by RCNN is 6% higher than that of CE-Net. The average 95HD and average ASD obtained by MultiResUNet are second only to RCNN. The average 95HD and average ASD obtained by RCNN are 32.4% and 33.3% lower than those of MultiResUNet, respectively. Then, we compare RCNN-based discretization with information-entropy-based discretization [20], class-attribute correlation-based discretization [21], and Chi-square-based discretization [22] in terms of the average data inconsistency and the average number of breakpoints. Table 2 shows the comparison results of discretization algorithms.
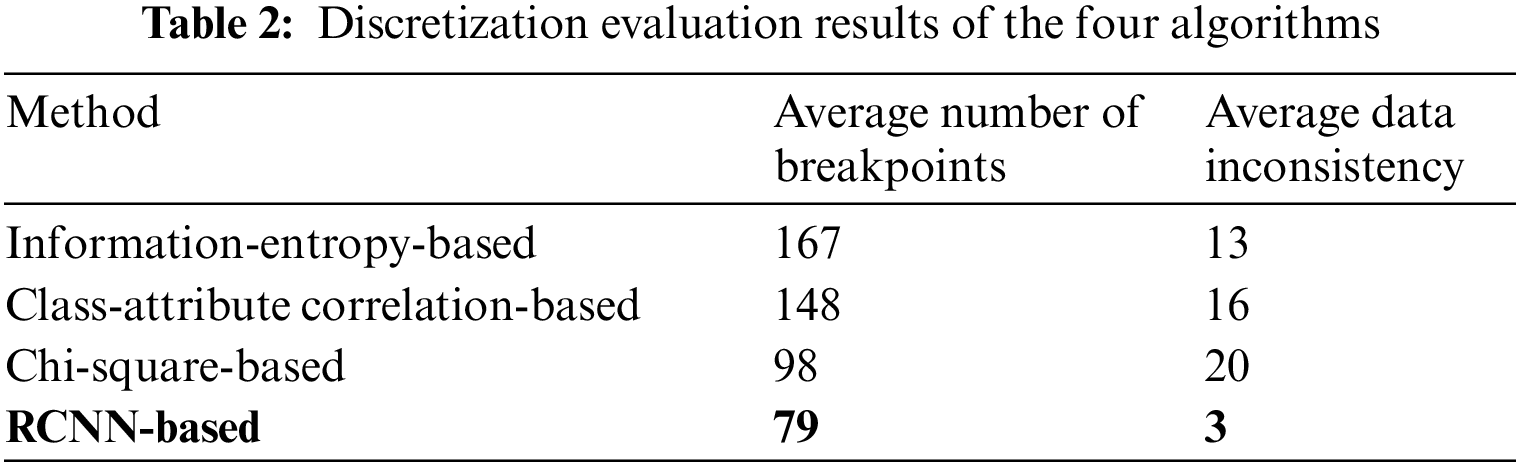
The RCNN-based discretization method obtains the lowest average data inconsistency and the smallest average number of breakpoints. Table 3 shows the effect of feature discretization.
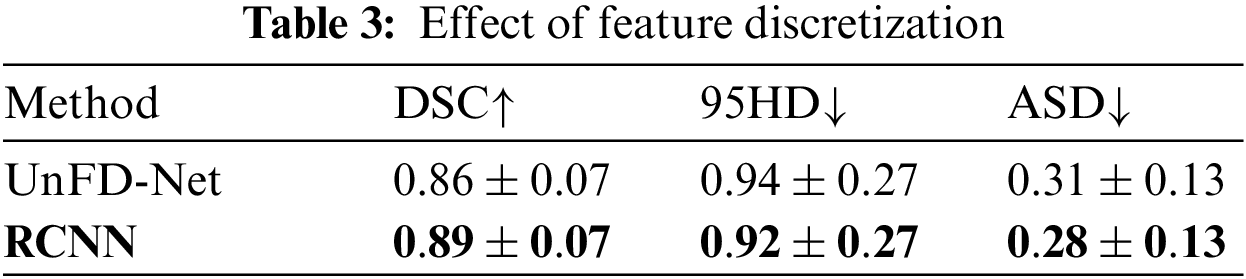
UnFD-Net is an RCNN that does not perform feature discretization. The average DSC obtained by RCNN is 3.5% higher than that of UnFD-Net. The average 95HD and average ASD obtained by RCNN are 2.1% and 9.7% lower than those of UnFD-Net, respectively. RCNN significantly weakens the negative effects of low-quality data by feature discretization to improve the segmentation performance.
4.5 Hyperparameter Analysis and Ablation Study
In general, the initial learning rate affects the learning efficiency of the network. Table 4 shows the comparison results of initial learning rates.
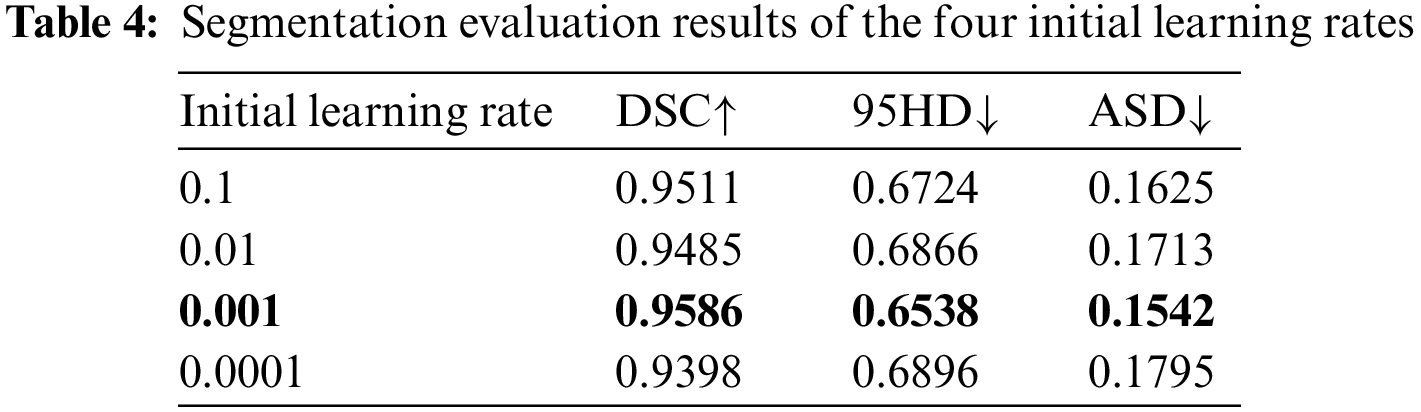
The segmentation results of the four initial learning rates show little difference, indicating that RCNN is stable. Table 5 shows the comparison results of Baseline, deep supervision (DS), dual attention block (DAB), attention refinement block (ARB), and RCNN.
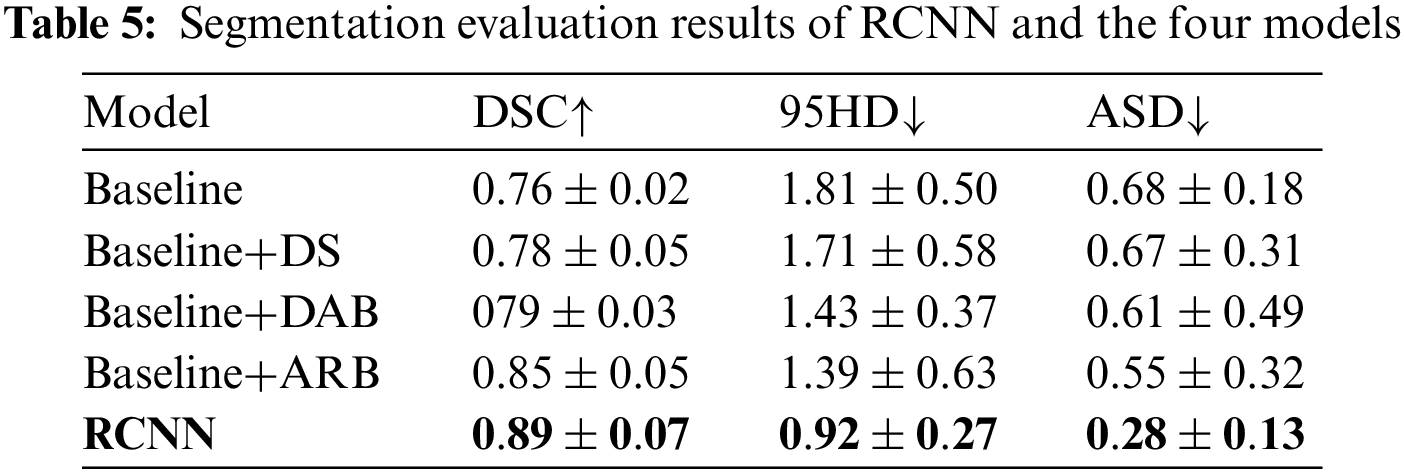
Baseline has the lowest average DSC and the highest average 95HD and average ASD. Although DS has the ability to deal with imbalanced data, its overall segmentation performance is still poor. The attention mechanism enables DAB and ARB to achieve better segmentation performance than Baseline and DS. The average DSC obtained by RCNN is 4.7% higher than that of ARB. The average 95HD and average ASD obtained by RCNN are 33.8% and 49.1% lower than those of ARB, respectively. Fig. 5 shows the visualization of segmentation results.
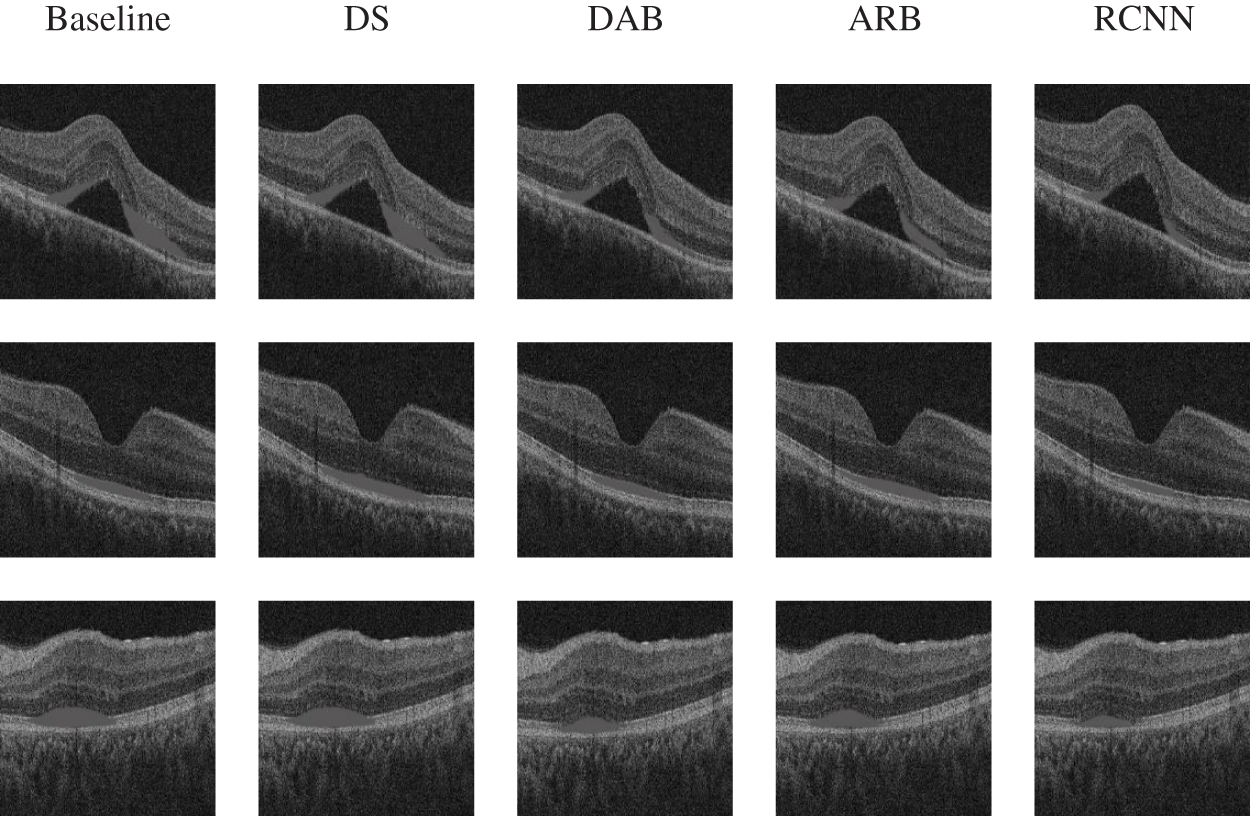
Figure 5: Visualization of the ablation experiment
The segmentation effect of Baseline is the worst. DS lacks the ability to extract important features, which may lead to wrong segmentation results. Although the segmentation results of DAB and ARB are better than those of Baseline and DS, these two models are still challenging to deal with regions with boundaries. Obviously, RCNN has the best segmentation effect.
None of CE-Net and MultiResUNet have a special preprocessing module for dealing with noise and redundant information. Moreover, CE-Net and MultiResUNet have limited capabilities in capturing important features and multi-scale information. RCNN eliminates redundant information and weakens the interference of noise by discretizing the brightness attribute. On this basis, RCNN employs the attention mechanism to improve the feature extraction ability of the network. Therefore, RCNN can obtain better segmentation result.
We have proposed an OCT fundus image segmentation method based on an RCNN. Our work is as follows: (1) we have designed the rough-set-based feature discretization module to preprocess the input data; (2) we have added a dual attention mechanism for feature channels and spatial regions in the CNN, enabling the model to adaptively select important information for fusion; (3) we have added the refinement module to enhance the extraction power of multi-scale information, improving the edge accuracy in segmentation. We have compared RCNN with CE-Net and MultiResUNet on 83 gold standard 3D retinal OCT data with a resolution of 1024 × 512 × 128. The average DSC obtained by RCNN is 6% higher than that of CE-Net. The average 95HD and average ASD obtained by RCNN are 32.4% and 33.3% lower than those of MultiResUNet, respectively. We have also evaluated the effect of feature discretization. In addition, we have analyzed the initial learning rate of RCNN and have conducted ablation experiments with the four different models. The experiments have shown that RCNN achieves the best segmentation results, which is helpful for promoting OCT image watermarking.
Although RCNN has achieved impressive segmentation results, discretization based on rough sets is difficult to effectively depict the boundaries between different regions. Therefore, our future work will include (1) introducing fuzzy sets to optimize the feature discretization module of RCNN to strengthen the anti-noise ability; (2) applying RCNN to more datasets for testing to enhance the reliability.
Acknowledgement: The authors would like to thank Prof. Mengxing Huang and Ms. Lirong Zeng from Hainan University for their assistance and constructive comments.
Funding Statement: This work was supported in part by the China Postdoctoral Science Foundation under Grant 2021M701838, the Natural Science Foundation of Hainan Province of China under Grants 621MS042 and 622MS067, and the Hainan Medical University Teaching Achievement Award Cultivation under Grant HYjcpx202209.
Author Contributions: JL and QC contributed equally to method design, experimental analysis, and manuscript writing. JL and QC were responsible for data provision and funding acquisition. All authors have reviewed the final version of the manuscript and have consented to its publication.
Availability of Data and Materials: The datasets used and analyzed in the current study are available from the corresponding author upon reasonable request.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding this study.
References
1. Dahrouj, M., Miller, J. B. (2021). Artificial intelligence (AI) and retinal optical coherence tomography (OCT). Seminars in Ophthalmology, 36(4), 341–345. [Google Scholar] [PubMed]
2. Singh, A., Dutta, M. K. (2022). An integrity control system for retinal images based on watermarking. Multimedia Tools and Applications, 81(2), 2429–2452. [Google Scholar]
3. Zeng, C., Liu, J., Li, J., Cheng, J., Zhou, J. et al. (2022). Multi-watermarking algorithm for medical image based on KAZE-DCT. Journal of Ambient Intelligence and Humanized Computing, 1–9. https://doi.org/10.1007/s12652-021-03539-5 [Google Scholar] [CrossRef]
4. He, Y., Carass, A., Liu, Y., Jedynak, B. M., Solomon, S. D. et al. (2021). Structured layer surface segmentation for retina OCT using fully convolutional regression networks. Medical Image Analysis, 68, 101856. https://doi.org/10.1016/j.media.2020.101856 [Google Scholar] [PubMed] [CrossRef]
5. Bogunović, H., Venhuizen, F., Klimscha, S., Apostolopoulos, S., Bab-Hadiashar, A. et al. (2019). RETOUCH: The retinal OCT fluid detection and segmentation benchmark and challenge. IEEE Transactions on Medical Imaging, 38(8), 1858–1874. [Google Scholar] [PubMed]
6. Xu, G., He, C., Wang, H., Zhu, H., Ding, W. (2023). DM-Fusion: Deep model-driven network for heterogeneous image fusion. IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2023.3238511 [Google Scholar] [PubMed] [CrossRef]
7. Xu, G., Wang, H., Pedersen, M., Zhao, M., Zhu, H. (2023). SSP-Net: A siamese-based structure-preserving generative adversarial network for unpaired medical image enhancement. IEEE/ACM Transactions on Computational Biology and Bioinformatics. https://doi.org/10.1109/TCBB.2023.3256709 [Google Scholar] [PubMed] [CrossRef]
8. Jiang, C., Wu, C., Xiao, X., Lin, C. (2022). Robust neural dynamics with adaptive coefficient applied to solve the dynamic matrix square root. Complex & Intelligent Systems, 9, 4213–4226. https://doi.org/10.1007/s40747-022-00954-9 [Google Scholar] [CrossRef]
9. Wu, Y., Li, Y., Feng, S., Huang, M. (2023). Pansharpening using unsupervised generative adversarial networks with recursive mixed-scale feature fusion. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 16, 3742–3759. https://doi.org/10.1109/JSTARS.2023.3259014 [Google Scholar] [CrossRef]
10. Gu, Z., Cheng, J., Fu, H., Zhou, K., Hao, H. et al. (2019). CE-Net: Context encoder network for 2D medical image segmentation. IEEE Transactions on Medical Imaging, 38(10), 2281–2292. [Google Scholar] [PubMed]
11. Feng, S., Liu, Q., Patel, A., Bazai, S. U., Jin, C. K. et al. (2022). Automated pneumothorax triaging in chest X-rays in the New Zealand population using deep-learning algorithms. Journal of Medical Imaging and Radiation Oncology, 66(8), 1035–1043. https://doi.org/10.1111/1754-9485.13393 [Google Scholar] [PubMed] [CrossRef]
12. Li, Y., Wu, Y., Huang, M., Zhang, Y., Bai, Z. (2022). Automatic prostate and peri-prostatic fat segmentation based on pyramid mechanism fusion network for T2-weighted MRI. Computer Methods and Programs in Biomedicine, 223. https://doi.org/10.1016/j.cmpb.2022.106918 [Google Scholar] [PubMed] [CrossRef]
13. Li, Y., Lin, C., Zhang, Y., Feng, S., Huang, M. et al. (2023). Automatic segmentation of prostate MRI based on 3D pyramid pooling Unet. Medical Physics, 50(2), 906–921. [Google Scholar] [PubMed]
14. Kepp, T., Ehrhardt, J., Heinrich, M. P., Hüttmann, G., Handels, H. (2019). Topology-preserving shape-based regression of retinal layers in OCT image data using convolutional neural networks. IEEE 16th International Symposium on Biomedical Imaging (ISBI), pp. 1437–1440. Venice, Italy. [Google Scholar]
15. Masood, S., Fang, R., Li, P., Li, H., Sheng, B. et al. (2019). Automatic choroid layer segmentation from optical coherence tomography images using deep learning. Scientific Reports, 9(1), 3058. https://doi.org/10.1038/s41598-019-39795-x [Google Scholar] [PubMed] [CrossRef]
16. Hesamian, M. H., Jia, W., He, X., Kennedy, P. (2019). Deep learning techniques for medical image segmentation: Achievements and challenges. Journal of Digital Imaging, 32(4), 582–596. [Google Scholar] [PubMed]
17. Minaee, S., Boykov, Y., Porikli, F., Plaza, A., Kehtarnavaz, N. et al. (2022). Image segmentation using deep learning: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7), 3523–3542. [Google Scholar] [PubMed]
18. Chen, Q., Ding, W., Huang, X., Wang, H. (2023). Generalized interval type II fuzzy rough model based feature discretization for mixed pixels. IEEE Transactions on Fuzzy Systems, 31(3), 845–859. [Google Scholar]
19. Huang, P., Chen, Q., Wang, D., Wang, M., Wu, X. et al. (2022). Tripleconvtransformer: A deep learning vessel trajectory prediction method fusing discretized meteorological data. Frontiers in Environmental Science, 1720. https://doi.org/10.3389/fenvs.2022.1012547 [Google Scholar] [CrossRef]
20. de Sá, C. R., Soares, C., Knobbe, A. (2016). Entropy-based discretization methods for ranking data. Information Sciences, 329, 921–936. [Google Scholar]
21. Yan, D., Liu, D., Sang, Y. (2014). A new approach for discretizing continuous attributes in learning systems. Neurocomputing, 133, 507–511. [Google Scholar]
22. Rosati, S., Balestra, G., Giannini, V., Mazzetti, S., Russo, F. et al. (2015). ChiMerge discretization method: Impact on a computer aided diagnosis system for prostate cancer in MRI. IEEE International Symposium on Medical Measurements and Applications (MeMeA) Proceedings, pp. 297–302. Torino, Italy. [Google Scholar]
23. Phophalia, A., Mitra, S. K. (2017). 3D MR image denoising using rough set and kernel PCA method. Magnetic Resonance Imaging, 36, 135–145. [Google Scholar] [PubMed]
24. Huang, W., Wang, H. H., Liu, Z., Wang, L. (2017). Image denoising and enhancement based on rough set and principal component analysis. International Conference on Inventive Computing and Informatics (ICICI), pp. 536–539. Coimbatore, India. [Google Scholar]
25. Chen, Q., Huang, M., Wang, H., Xu, G. (2022). A feature discretization method based on fuzzy rough sets for high-resolution remote sensing big data under linear spectral model. IEEE Transactions on Fuzzy Systems, 30(5), 1328–1342. [Google Scholar]
26. Zhang, J., Cui, Y., Ren, J. (2022). Dynamic mission planning algorithm for UAV formation in battlefield environment. IEEE Transactions on Aerospace and Electronic Systems. https://doi.org/10.1109/TAES.2022.3231244 [Google Scholar] [CrossRef]
27. Ramírez-Gallego, S., García, S., Benítez, J. M., Herrera, F. (2016). Multivariate discretization based on evolutionary cut points selection for classification. IEEE Transactions on Cybernetics, 46(3), 595–608. [Google Scholar]
28. Wang, H., Xu, L., Yan, Z., Gulliver, T. A. (2021). Low complexity MIMO-FBMC sparse channel parameter estimation for industrial big data communications. IEEE Transactions on Industrial Informatics, 17(5), 3422–3430. [Google Scholar]
29. Chen, Q., Huang, M., Wang, H. (2021). A feature discretization method for classification of high-resolution remote sensing images in coastal areas. IEEE Transactions on Geoscience and Remote Sensing, 59(10), 8584–8598. [Google Scholar]
30. Chen, Q., Xie, L., Zeng, L., Jiang, S., Ding, W. et al. (2023). Neighborhood rough residual network–based outlier detection method in IoT-enabled maritime transportation systems. IEEE Transactions on Intelligent Transportation Systems. [Google Scholar]
31. Zeng, L., Chen, Q., Huang, M. (2022). RSFD: A rough set-based feature discretization method for meteorological data. Frontiers in Environmental Science, 1734. https://doi.org/10.3389/fenvs.2022.1013811 [Google Scholar] [CrossRef]
32. Niu, Z., Zhong, G., Yu, H. (2021). A review on the attention mechanism of deep learning. Neurocomputing, 452, 48–62. [Google Scholar]
33. Chen, Q., Zeng, L., Lin, C. (2023). A deep network embedded with rough fuzzy discretization for OCT fundus image segmentation. Scientific Reports, 13(1), 328. https://doi.org/10.1038/s41598-023-27479-6 [Google Scholar] [PubMed] [CrossRef]
34. Zeng, L., Huang, M., Li, Y., Chen, Q., Dai, H. N. (2022). Progressive feature fusion attention dense network for speckle noise removal in OCT images. IEEE-ACM Transactions on Computational Biology and Bioinformatics. https://doi.org/10.1109/TCBB.2022.3205217 [Google Scholar] [PubMed] [CrossRef]
35. Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J. et al. (2019). Pytorch: An imperative style, high-performance deep learning library. 33rd Conference on Neural Information Processing Systems (NeurIPS), vol. 32, pp. 1–12. Vancouver, Canada. [Google Scholar]
36. Ibtehaz, N., Rahman, M. S. (2020). MultiResUNet: Rethinking the U-net architecture for multimodal biomedical image segmentation. Neural Networks, 121, 74–87. [Google Scholar] [PubMed]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools