
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
EfficientShip: A Hybrid Deep Learning Framework for Ship Detection in the River
1 School of Computer Engineering, Jingchu University of Technology, Jingmen, 448000, China
2 School of Computer Science, Yangtze University, Jingzhou, 434023, China
3 School of Computing and Mathematic Sciences, University of Leicester, Leicester, LE1 7RH, UK
* Corresponding Author: Yudong Zhang. Email:
Computer Modeling in Engineering & Sciences 2024, 138(1), 301-320. https://doi.org/10.32604/cmes.2023.028738
Received 05 January 2023; Accepted 05 May 2023; Issue published 22 September 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Optical image-based ship detection can ensure the safety of ships and promote the orderly management of ships in offshore waters. Current deep learning researches on optical image-based ship detection mainly focus on improving one-stage detectors for real-time ship detection but sacrifices the accuracy of detection. To solve this problem, we present a hybrid ship detection framework which is named EfficientShip in this paper. The core parts of the EfficientShip are DLA-backboned object location (DBOL) and CascadeRCNN-guided object classification (CROC). The DBOL is responsible for finding potential ship objects, and the CROC is used to categorize the potential ship objects. We also design a pixel-spatial-level data augmentation (PSDA) to reduce the risk of detection model overfitting. We compare the proposed EfficientShip with state-of-the-art (SOTA) literature on a ship detection dataset called Seaships. Experiments show our ship detection framework achieves a result of 99.63% (mAP) at 45 fps, which is much better than 8 SOTA approaches on detection accuracy and can also meet the requirements of real-time application scenarios.Keywords
With the continuous advancement of technology and the rapid development of industrial production, international trade is gradually increasing. The market of the shipping industry is also flourishing. In order to ensure the safety of ships and promote the orderly management of ships, satellites (generate SAR images) are used to monitor ships at sea [1] and surveillance cameras (generate optical images) are adopted for tracking ships in offshore waters [2,3]. At the technical level, with the maturity of artificial intelligence technology [4], computer-aided methods of ship classification, ship instance segmentation and ship detection from images are studied to reduce the burden on human monitors [5]. We focus on ship detection based on optical images generated by surveillance cameras in this paper.
In recent years, deep learning-based ship detection has become a hot research area [6–8]. Sea ship detection is one of the general object detections [9]. Researches on deep learning based object detection can be roughly split into two classifications: One-stage detectors and two-stage detectors [10]. One-stage detectors combine object location and classification in one deep learning framework, while two-stage detectors find object location in the first place and classify the potential objects secondly. Representative one-stage detection algorithms are RetinaNet [11], FCOS [12], CenterNet [13], ATSS [14], PAA [15], BorderDet [16], and YOLO series [17–21]. Mainstream two-stage object detection approaches are R-CNN [22], SPPNet [23], Fast RCNN [24], Faster RCNN [25], FPN [26], Cascade RCNN [27], Grid RCNN [28], and CenterNet2 [29].
Generally, the one-stage detector is considered to have a faster detection speed, while the two-stage detection algorithm has higher detection accuracy. While recent methods of ship detection [3,30–37] focus on improving one-stage detectors for real-time ship detection, they sacrifice the accuracy of detection. In this paper, we present a real-time two-stage ship detection algorithm, which improves detection accuracy while ensuring real-time performance. The algorithm includes two parts: the DLA-backboned object location (DBOL) and the CascadeRCNN-guided object classification (CROC). To further improve the accuracy of ship detection, we design a novel pixel-spatial-level data augmentation (PSDA) for increasing the number of samples at a high multiple and effectively. The PSDA, DBOL and CROC make up the proposed hybrid deep learning framework of EfficientShip.
The contributions of this study can be summarized as follows:
(1) The DBOL is presented for finding potential ship objects in real time. We integrate DLA [38], ResNet-50 [39] and CenterNet [13] into DBOL for evaluating object likelihoods quickly and accurately.
(2) The CROC is put forward to real-time categorize the potential ship objects. We calculate the category scores of suspected objects based on conditional probability and extrapolate the final detection.
(3) The PSDA is proposed to reduce the risk of the model overfitting. We amplify the original data by 960 times based on pixel and spatial image augmentation.
(4) Our EfficientShip (includes PSDA, DBOL and CROC) gets the best performance compared with 8 existing SOTA methods: 99.63% (accuracy) with 45 fps (speed).
Ship detection can be divided into SAR image-based [5,40] and optical image-based ship detection [2,3]. Here we focus on reviewing optical image-based ship detection. Traditional optical image-based ship detection use hand-crafted features which sliding window to obtain the candidate area of the ship target based on the saliency map algorithm or the visual attention mechanism. The features of the candidate target are extracted for training to obtain the detection model [41,42].
Recently, deep learning-based ship detection has attracted researchers’ attention. Shao et al. [3] introduced a CNN framework on the basis of saliency-aware for ship detection. Based on YOLOv2, the ship’s location and classification under a complex environment were inferred by CNN firstly and were refined through saliency detection. Sun et al. [32] presented an algorithm named NSD-SSD for real-time ship detection. They combined dilated convolution and multiscale feature to promote knockdown performance in detecting a small object of a ship. For getting the inferring score of every class and the variation of every prior bounding box, they also designed a batch of convolution filters at every trenchant feature layer. They finally reconstructed prior boxes with K-means clustering to advance visual accuracy and the ship-detecting efficiency.
Liu et al. [31] have designed an advanced CNN-enabled learning method for promoting ship detection under different weather conditions. On the basis of YOLOv3, they devised new scale of anchor boxes, localization probability of bounding boxes, soft non-maximum suppression, and medley loss function for advancing the CNN capacities of learning and expression. On the other hand, they introduced an agile DA tactics through produce synthetically-degraded pictures to enlarge the capacity and diversity of rudimentary ship detection dataset. Considering the influence of meteorological factors on ship detection accuracy, Nie et al. [30] synthesized foggy images and low visibility pictures via exploiting physical models separately. They trained YOLOv3 on the expanded dataset, including both composite and original ship pictures and illustrated that the trained model achieved excellent ship detection accuracy within a variety of weather conditions. For real-time ship detection, Li et al. [33] concentrated the network of YOLOv3 by training predetermined anchors based on the annotations of Seaship, instead max-pooling layer with convolution layer, expanding channels of prediction network to promote the detection ability of tiny object, and embedding CBAM attention module into the backbone network to facilitate the model focusing on the object. Liu et al. [43] proposed two new anchor-setting methods, the average method and the select-all method, for detecting ship targets on the basis of YOLOv3. Additionally, they adopt the feature fusion structure of cross PANet for combining the different anchor-setting methods. Chen et al. [35] introduced the AE-YOLOv3 for real-time end-to-end ship identification. AE-YOLOv3 was merged in the feature attention module, embedded with the feature extraction network, and fused through multiscale feature enhancement model.
Liu et al. [34] presented a method of RDSC on the basis of YOLOv4 by reducing more than 40% weights compared to the original one. The improved lightweight algorithm achieved a tinier network volume and preferable real-time performance on ship detection. Zhang et al. [36] presented a lightweight CNN named Light-SDNet for detecting ships under various weather conditions. Based on YOLOv5, they modificated CA-Ghost, C3Ghost, and DWConv to decrease the model parameters size. They designed a hybrid training tactic by deriving jointly-degraded pictures to expand the number of the primitive dataset. Zhou et al. [37] improved YOLOv5 for ship target detection, and named it as YOLO-Ship, which adopted MixConv to update classical convolution operation and concordant attention framework. At decision stage, they employed Focal Loss and CIoU Loss for optimizing raw cost functions.
In order to reach the goal of real-time application while obtaining detection accuracy, most of the above algorithms choose a one-stage detection algorithm as the basis for improvement. Different from these methods, we present a real-time approach of two-stage detection as the main ship detection framework and verify its accuracy and real-time performance through experiments.
Image data collection and labeling are very labor-intensive. Due to funding constraints, ship detection datasets usually have only thousands of annotated images [2]. But the deep learning model has many parameters and requires tens of thousands of data for training. While a deep convolutional neural network (CNN) learns a function that has a very high correlation with the small training data, it is poorly generalizable to testing set (overfitting). Data augmentation technology can simulate training image data through lighting variations, occlusion, scale and orientation variations, background clutter, object deformatio, etc., so that the deep learning model is robust to these disturbances and reducing overfitting on testing data [44,45].
Image DA algorithms can be split into basic image manipulations and deep learning approaches [44]. Basic image manipulations change original image pixels while the image label is conserved. Basic image manipulations include geometric transformations, color space transformations, kernel filters and random erasing. Image geometric transformations shift the geometry of image without altering its actual pixel values. Simple geometric transformations cover flipping, cropping, rotation and translation. Color space transformations will shift pixel values through an invariable number, separate RGB color channel or limit pixel values into a range. The methods of kernel filter sharpen or blur original images via sliding of filter matrix across training image. Inspired by CNN dropout regularization, random erasing does the operation of masking training image patch with the values 0, 255, or random number. Taylor et al. proved the effectiveness of geometric and color space transformations [46], while Zhong et al. verified the performance of random erasing through experiments [47]. Xu et al. presented a novel shadow enhancement named SBN-3D-SD for higher detection-tracking accuracy [48].
Deep learning-based augmentation adopts learning methods to produce synthetic examples for training data. It can be divided into adversarial training based DA, GAN-based DA, neural transfer based DA, and meta-learning-based DA [44]. Adversarial training based DA generates adversarial samples and inserts them into the training set so that the inferential model can learn from the adversarial samples during training [49]. Method of GAN is an unsupervised generative model that can generate synthetic data given a random noise vector. Adding the data generated by GAN-based DA into the training set can optimize deep learning model parameters [50]. The idea of neural style transfer is to manipulate sequential features across a CNN so that the image pattern can be shifted into other styles while retaining its primitive substance. Meta-learning-based DA uses a pre-prepared neural network to learn DA parameters from medley images, Neural Style Transfer, and geometric transfigurations. The image generated by deep learning-based augmentation is abstract and cannot pinpoint target bounding boxes. So it is not suitable for ship detection.
In this section, we describe the method of EfficientShip for ship detection. It includes proposed PSDA, DBOL and CROC (as shown in Fig. 1).

Figure 1: The architecture of the proposed EfficientShip. PSDA is used for expanding the amount of image sample; DBOL is responsible for detecting potential objects; CROC tries to identify the potential objects
The ship detection dataset is small for the current study. Therefore, we present a method named PSDA to counteract the overfitting of the ship detection model. PSDA includes pixel level DA (PDA), spatial level DA (SDA), and their combination. PDA will change the content of the input image at the pixel level, and SDA is to perform geometric transformations on it.
Suppose the number of DA methods we used is
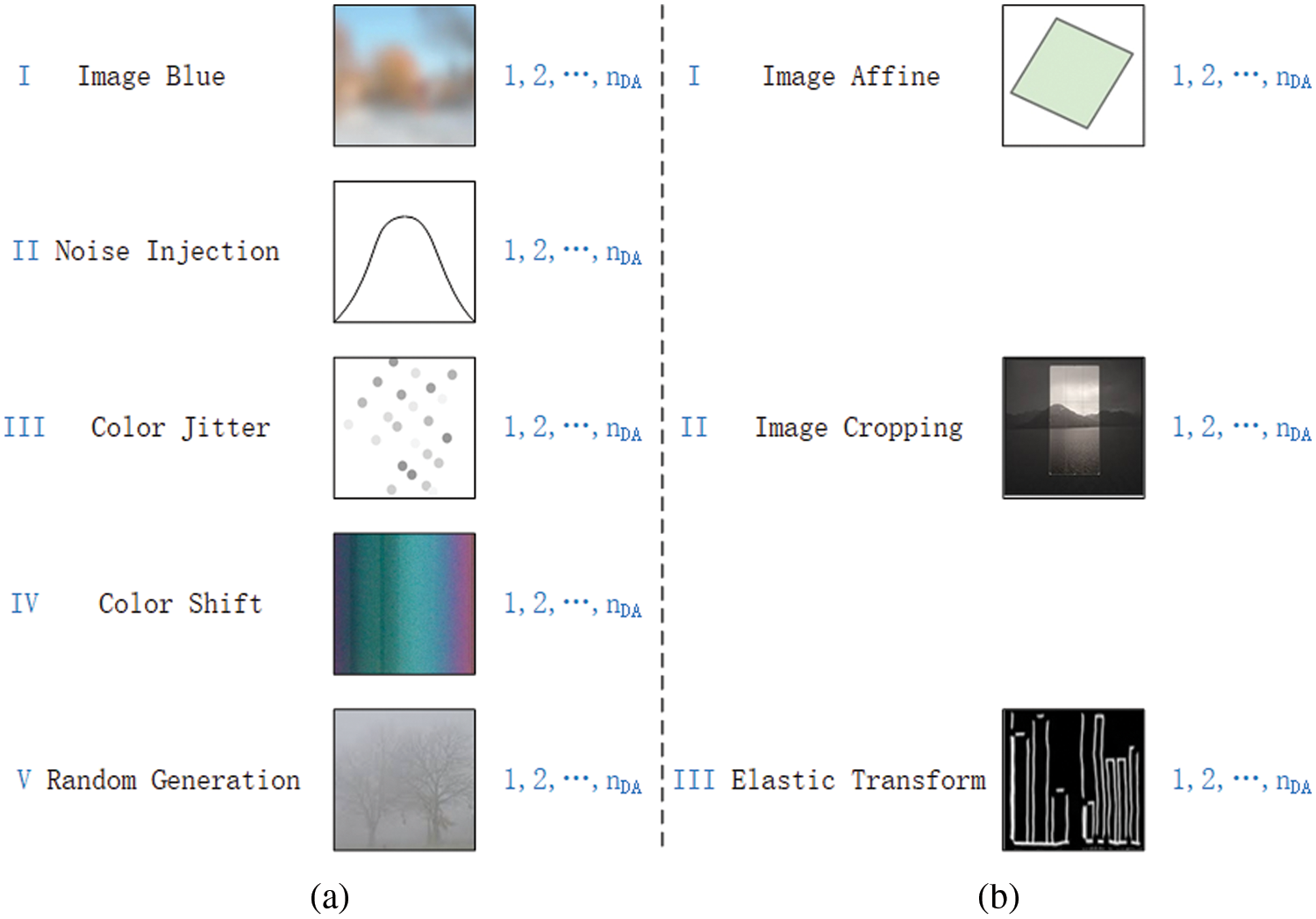
Figure 2: Schematic of proposed PSDA. (a) PDA is used for expanding the amount of image sample at pixel level; (b) SDA is used for expanding the amount of image sample at spatial level
(I) Image Blur
Applying an image blur algorithm to a raw image can generate
where
(II) Noise Injection
New
where
(III) Color Jitter
Color jitter generates a minor variations of color values in the training image.
where
(IV) Color Shift
Color shift is color variation caused by different fade rates of dyes or imbalance of dyes within a picture patch.
where
(V) Random Generation
Random generation method can generate new images by performing multiple operations on original image pixels, such as brightness, contrast, gamma correction, curve, fog, rain, shadow, snow, sun flare, etc. Each training image in
where
where
At the spatial level, the image transformation will not change the original image content, but the object bounding box will be transformed along with the transformation. The main transformations are:
(I) Image Affine
Image affine is a common geometric transformation that preserves the collinearity between pixels. It includes translation, rotation, scaling, shear and their combination.
where
(II) Image Cropping
Image cropping can freely crop the input image to any size.
where
(III) Elastic Transform
Elastic transformation alters the silhouette of the input picture upon the application of a force within its elastic limit. It is controlled by the parameters of the Gaussian filter and affine.
where
Algorithm 1 shows the pseudocode of PSDA on one training image

3.2 Proposed DLA-Backboned Object Location (DBOL)
The main task in the first step of two-stage object detection is to produce a number of patch bounding boxes with different proportions and sizes according to the characteristic features such as texture, color and other details of the image. Some of the patches represented by bounding boxes contain target, while others only involve background.
As Fig. 1 illustrated, the first step of two-stage ship detection is to generate a set of K ship detections as bounding boxes
where
The network architecture of the proposed DBOL is shown n Fig. 3. We select compact DLA [38] as CNN backbone for inferring
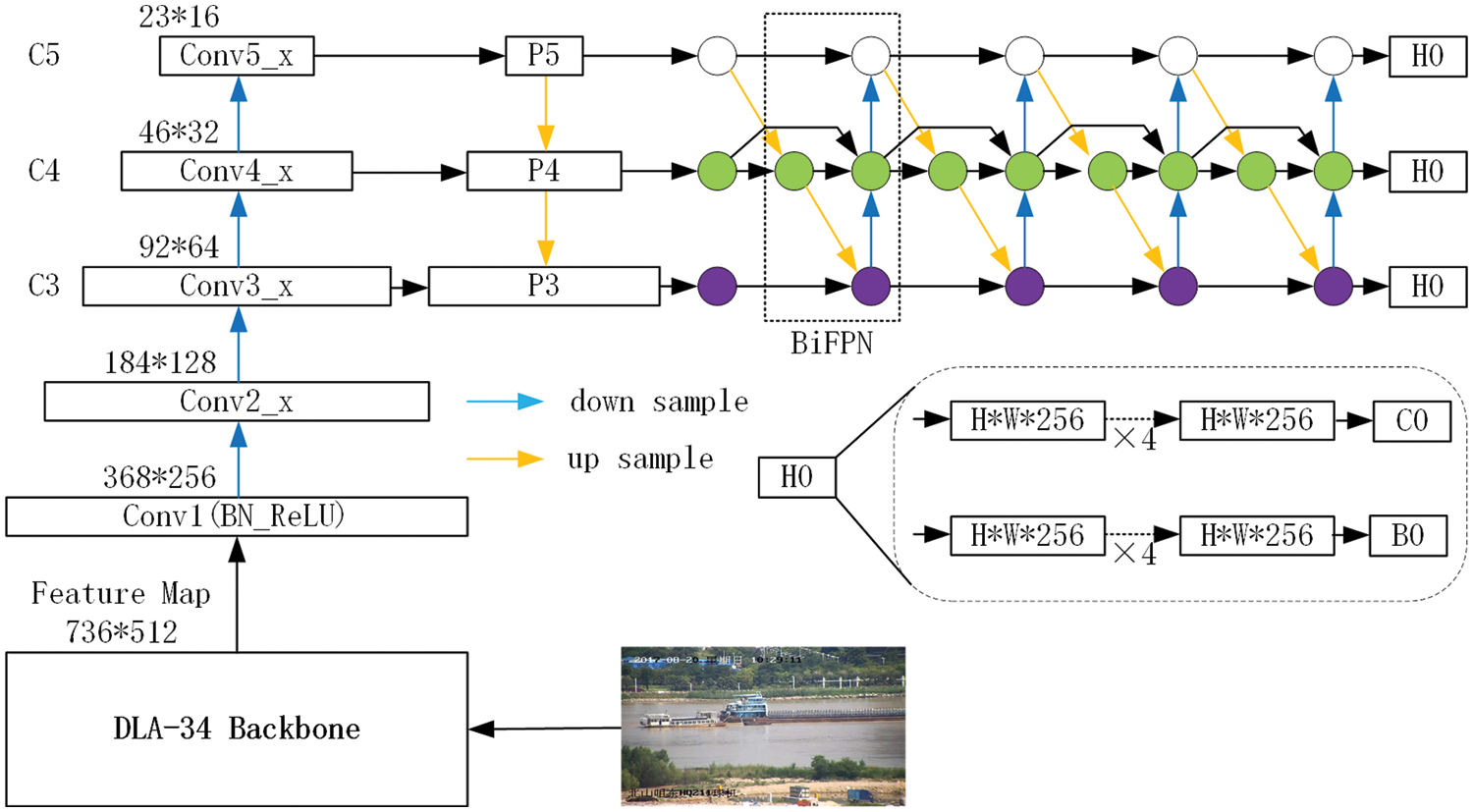
Figure 3: The architecture of the proposed DBOL. “Conv*” is convolution operation, “C3, C4, C5” denote the feature maps of the backbone network, “P3, P4, P5” are the feature levels used for the final prediction, “H*” is network head, “B*” is bouding box of proposals, “C0” is object classification
3.3 Proposed CascadeRCNN-Guided Object Classification (CROC)
For every ship target
The conjoint category distribution of the ship detection is
where
to decrease to conjoint maximum likelihood objects of the two stages, respectively [29]. The maximum-likelihood objective of the background class is
The architecture of the proposed CROC is shown in Fig. 4. In this stage of detection, we select CascadeRCNN [27] for inferring
where

Figure 4: The architecture of the proposed CROC. The Feature Map is generated from DLA-34 backbone network, “H*” is the network head, “B*” is the bouding box of proposals, “B0” is the bounding box of proposals produced in Fig. 3
Algorithm 2 shows the pseudocode of the CROC training process.

4 Experimental Result and Analysis
In this section, we evaluate the proposed EfficientShip on Seaships [2] dataset. The experiments use Pytorch (1.11.0) library which is installed in Ubuntu 20.04. The model parameters are trained on an NVIDIA GeForce RTX 3090 GPU with 24 GB RAM. And the CPU is Intel(R) Xeon(R) Platinum 8255C with 45 GB RAM.
4.1 Dataset and Evaluation Metrics
The dataset we selected in this paper is SeaShips [2]. The dataset has 7000 images and includes six categories: bulk cargo carrier, container ship, fishing boat, general cargo ship, ore carrier, and passenger ship. Fig. 5 shows the appearance of different ships in SeaShips. The resolution of images is 1920 × 1080. All pictures in the dataset are selected from 5400 real-world video segments generated by 156 monitoring cameras in the coastline surveillance system. It covers targets of different backgrounds, scales, hull parts, illumination, occlusions and viewpoints. We randomly divide the dataset into a training set and a test set with proportion of 9:1 for the experiments followed by [35].

Figure 5: Illustration of different ship samples and their labels in the SeaShips dataset. (a) bulk cargo carrier; (b) container ship; (c) fishing boat; (d) general cargo ship; (e) ore carrier; (f) passenger ship
Experimental evaluation metrics include ship detection accuracy and runtime. The runtime is reported by fps, and the detection accuracy is evaluated by standard mAP which defined as
where
PSDA. For PDA, we select 33 augmentation methods (with 40 adjustable parameters) for every original training image. There are 15 parameter variations for each adjustable parameter setting shown in Table 1. For one raw image, 600 new images can be augmented at this stage. Fig. 6 displays the augmentation results of methods RandomFog and ColorJitter(in brightness). We choose 24 augmentation algorithms at the stage of SDA which generates


Figure 6: Illustration of pixel level DA. Upper: Augmentation with RandomFog; Under: Augmentation with ColorJitter(brightness)

Figure 7: Illustration of space level DA. Upper: Augmentation with Affine(rotate); Under: Augmentation with PixelDropout
DBOL & CROC. The method of DLA [38] is selected as the backbone of the first ship detection stage. We extend DLA through a 4-layer BiFPN [53] with 160 feature channels. We reduce the output FPN levels to 3 levels with strides 8-32. The model parameters in the first stage are trained with a long schedule that repetitively fine-tunes. The amount of object proposals is reduced to 128 in the target-detecting stage. For the second stage, the detection part of CascadeRcNN [27] is adopted for recognizing the proposals. We raise the positive IoU threshold value from 0.6 to 0.8 for the method of CascadeRcNN to reimburse the IoU distribution variation.
(I) Ablation Study
We design the different experiments on the modules of the proposed framework to find their effectiveness. We first select the EfficientShip with non-DA as a baseline. Then we add pixel-level and spatial-level DA separately on the basis of the ship detection. Finally, we test the whole hybrid ship detection framework which includes three complete steps. Details of the experimental results are presented in Table 3. We can observe that the basic EfficientShip with non-DA yields the lowest mAP value of 98.85%, and the baseline plus SDA can get a 0.43% boost. The baseline plus PDA yields a 0.62% improvement which shows PDA is much better than SDA. The whole proposed EfficientShip achieves a detection accuracy of 99.63%.
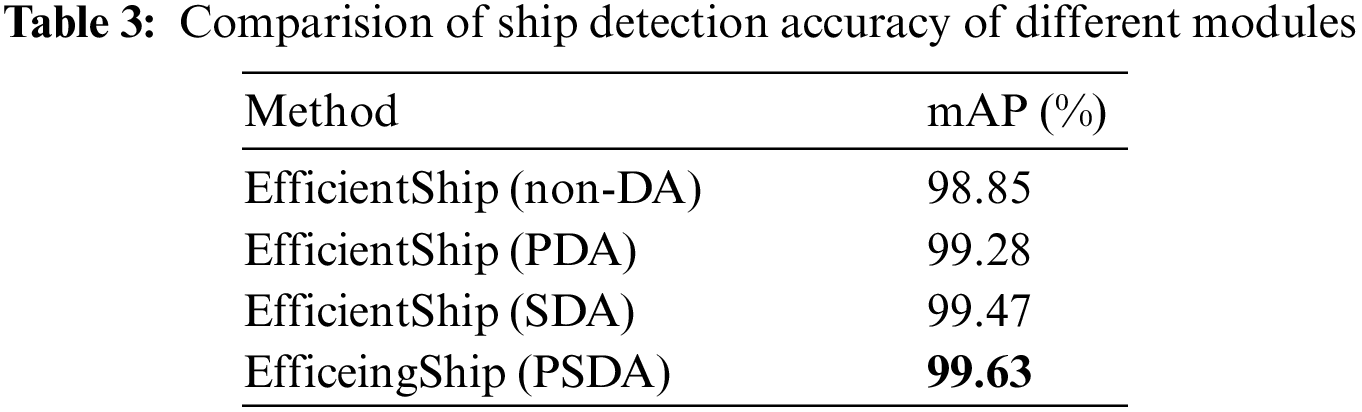
Fig. 8 shows the mAP comparison chart of different modules. It also indicates the changes in detection accuracy among various categories of the SeaShips dataset. Relatively, the bulk cargo carrier is the most recognizable object, while the passenger ship is the most difficult target to identify. After superimposing DA on the basis of two-stage detection, each category of detection accuracy is gradually approaching 100%.

Figure 8: Comparison of AP curves of different modules: (a) EfficientShip (non-DA); (b) EfficientShip (PDA); (c) EfficientShip (SDA); (d) EfficeingShip (PSDA)
(II) Comparison to State-of-the-Art Approaches
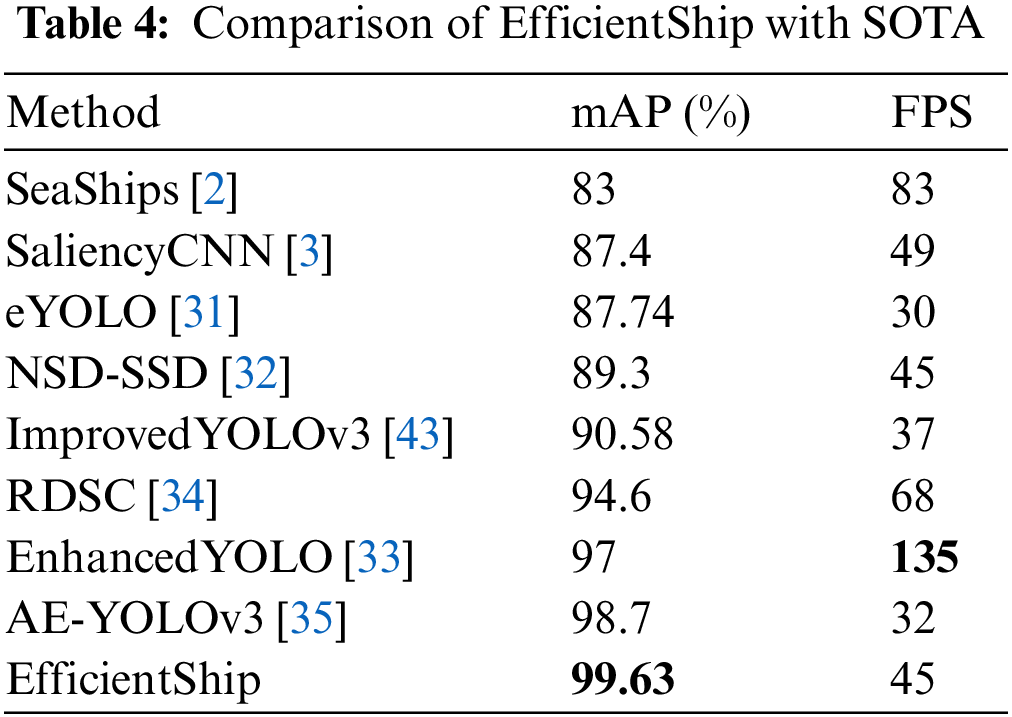
We compare the proposed approach with 8 SOTA methods [2,3,31–35,43] from accuracy and efficiency of ship detection, as shown in Table 4. The data values of all SOTA algorithms are derived from their original papers. Although the algorithm speed is not comparable because of the difference in the platform on which the algorithm runs. However, it can be seen from Table 4 that the speeds of all methods meet the requirements of real-time application scenarios. Compared with the earliest sea ship detection algorithm [2], the accuracy of our method has improved detection accuracy by 16.63%. The accuracy of proposed algorithm is 99.63%, which has a 0.93% increase over the best SOTA-performing algorithm [35].
Different from the traditional one-stage real-time ship detection methods, we fully utilized the latest real-time algorithms of object detection to construct a novel two-stage ship detection named EfficientShip. It includes DBOL, CROC, and PSDA. The DBOL is responsible for producing high-quality bounding boxes of the potential ship, and the CROC undertakes object recognition. We train the two stages jointly to boost the log-likelihood of actual objects. We also designed the PSDA to make further efforts of promoting the accuracy of target detection. Experiments on the dataset SeaShips show that the proposed EfficientShip has the highest ship detection accuracy among SOTA methods on the premise of achieving real-time performance. In the future, we will further verify the proposed algorithm on some new larger datasets, such as LS-SSDD-v1.0 and Official-SSDD [54].
Acknowledgement: The authors wish to express their appreciation to the reviewers for their helpful suggestions which greatly improved the presentation of this paper.
Funding Statement: This work was supported by the Outstanding Youth Science and Technology Innovation Team Project of Colleges and Universities in Hubei Province (Grant No. T201923), Key Science and Technology Project of Jingmen (Grant Nos. 2021ZDYF024, 2022ZDYF019), LIAS Pioneering Partnerships Award, UK (Grant No. P202ED10), Data Science Enhancement Fund, UK (Grant No. P202RE237), and Cultivation Project of Jingchu University of Technology (Grant No. PY201904).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Huafeng Chen; data collection: Junxing Xue; analysis and interpretation of results: Huafeng Chen, Junxing Xue, Yudong Zhang; draft manuscript preparation: Huafeng Chen, Hanyun Wen, Yurong Hu, Yudong Zhang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data can be download from http://www.lmars.whu.edu.cn/prof_web/shaozhenfeng/datasets/SeaShips(7000).zip.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Zhang, T., Zhang, X. (2019). High-speed ship detection in SAR images based on a grid convolutional neural network. Remote Sensing, 11(10), 1206. [Google Scholar]
2. Shao, Z., Wu, W., Wang, Z., Du, W., Li, C. (2018). SeaShips: A large-scale precisely annotated dataset for ship detection. IEEE Transactions on Multimedia, 20(10), 2593–2604. [Google Scholar]
3. Shao, Z., Wang, L., Wang, Z., Du, W., Wu, W. (2019). Saliency-aware convolution neural network for ship detection in surveillance video. IEEE Transactions on Circuits and Systems for Video Technology, 30(3), 781–794. [Google Scholar]
4. Tutsoy, O. (2021). Pharmacological, non-pharmacological policies and mutation: An artificial intelligence based multi-dimensional policy making algorithm for controlling the casualties of the pandemic diseases. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(12), 9477–9488. [Google Scholar]
5. Zhang, T., Zhang, X., Ke, X., Liu, C., Xu, X. et al. (2021). HOG-ShipCLSNet: A novel deep learning network with hog feature fusion for SAR ship classification. IEEE Transactions on Geoscience and Remote Sensing, 60, 1–22. [Google Scholar]
6. Dai, W., Mao, Y., Yuan, R., Liu, Y., Pu, X. et al. (2020). A novel detector based on convolution neural networks for multiscale SAR ship detection in complex background. Sensors, 20(9), 2547. [Google Scholar] [PubMed]
7. Cao, C., Wu, J., Zeng, X., Feng, Z., Wang, T. et al. (2020). Research on airplane and ship detection of aerial remote sensing images based on convolutional neural network. Sensors, 20(17), 4696. [Google Scholar] [PubMed]
8. Zou, Z., Shi, Z., Guo, Y., Ye, J. (2019). Object detection in 20 years: A survey. arXiv preprint arXiv:1905.05055. [Google Scholar]
9. Rao, Y., Mu, H., Yang, Z., Zheng, W., Wang, F. et al. (2022). B-PesNet: Smoothly propagating semantics for robust and reliable multi-scale object detection for secure systems. Computer Modeling in Engineering & Sciences, 132(3), 1039–1054. https://doi.org/10.32604/cmes.2022.020331 [Google Scholar] [CrossRef]
10. Soviany, P., Ionescu, R. T. (2018). Optimizing the trade-off between single-stage and two-stage deep object detectors using image difficulty prediction. 2018 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Piscataway, IEEE. [Google Scholar]
11. Lin, T. Y., Goyal, P., Girshick, R., He, K., Dollár, P. (2017). Focal loss for dense object detection. Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy. [Google Scholar]
12. Tian, Z., Shen, C., Chen, H., He, T. (2019). FCOS: Fully convolutional one-stage object detection. Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea. [Google Scholar]
13. Zhou, X., Wang, D., Krähenbühl, P. (2019). Objects as points. arXiv preprint arXiv:1904.07850. [Google Scholar]
14. Zhang, S., Chi, C., Yao, Y., Lei, Z., Li, S. Z. (2020). Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA. [Google Scholar]
15. Kim, K., Lee, H. S. (2020). Probabilistic anchor assignment with IoU prediction for object detection. European Conference on Computer Vision, Glasgow, UK, Springer. [Google Scholar]
16. Qiu, H., Ma, Y., Li, Z., Liu, S., Sun, J. (2020). BorderDet: Border feature for dense object detection. European Conference on Computer Vision, Glasgow, UK, Springer. [Google Scholar]
17. Redmon, J., Divvala, S., Girshick, R., Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA. [Google Scholar]
18. Redmon, J., Farhadi, A. (2017). YOLO9000: Better, faster, stronger. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA. [Google Scholar]
19. Redmon, J., Farhadi, A. (2018). YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767. [Google Scholar]
20. Bochkovskiy, A., Wang, C. Y., Liao, H. Y. M. (2020). YOLOv4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934. [Google Scholar]
21. Glenn, J., Alex, S., Jirka, B., NanoCode012, Ayush, C. et al. (2021). ultralytics/yolov5: v5.0-yolov5-p6 1280 models. https://github.com/ultralytics/yolov5 [Google Scholar]
22. Girshick, R., Donahue, J., Darrell, T., Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA. [Google Scholar]
23. He, K., Zhang, X., Ren, S., Sun, J. (2015). Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(9), 1904–1916. [Google Scholar] [PubMed]
24. Girshick, R. (2015). Fast R-CNN. Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile. [Google Scholar]
25. Ren, S., He, K., Girshick, R., Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 28, 1–9. [Google Scholar]
26. Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B. et al. (2017). Feature pyramid networks for object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA. [Google Scholar]
27. Cai, Z., Vasconcelos, N. (2018). Cascade R-CNN: Delving into high quality object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA. [Google Scholar]
28. Lu, X., Li, B., Yue, Y., Li, Q., Yan, J. (2019). Grid R-CNN. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA. [Google Scholar]
29. Zhou, X., Koltun, V., Krähenbühl, P. (2021). Probabilistic two-stage detection. arXiv preprint arXiv:2103.07461. [Google Scholar]
30. Nie, X., Yang, M., Liu, R. W. (2019). Deep neural network-based robust ship detection under different weather conditions. 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, IEEE. [Google Scholar]
31. Liu, R. W., Yuan, W., Chen, X., Lu, Y. (2021). An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system. Ocean Engineering, 235, 109435. [Google Scholar]
32. Sun, J., Xu, Z., Liang, S. (2021). NSD-SSD: A novel real-time ship detector based on convolutional neural network in surveillance video. Computational Intelligence and Neuroscience, 2021, 1–16. [Google Scholar]
33. Li, H., Deng, L., Yang, C., Liu, J., Gu, Z. (2021). Enhanced YOLO v3 tiny network for real-time ship detection from visual image. IEEE Access, 9, 16692–16706. [Google Scholar]
34. Liu, T., Pang, B., Zhang, L., Yang, W., Sun, X. (2021). Sea surface object detection algorithm based on YOLO v4 fused with reverse depthwise separable convolution (RDSC) for USV. Journal of Marine Science and Engineering, 9(7), 753. [Google Scholar]
35. Chen, D., Sun, S., Lei, Z., Shao, H., Wang, Y. (2021). Ship target detection algorithm based on improved YOLOv3 for maritime image. Journal of Advanced Transportation, 2021, 1–11. [Google Scholar]
36. Zhang, M., Rong, X., Yu, X. (2022). Light-SDNet: A lightweight CNN architecture for ship detection. IEEE Access, 10, 86647–86662. [Google Scholar]
37. Zhou, S., Yin, J. (2022). YOLO-ship: A visible light ship detection method. 2022 2nd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, IEEE. [Google Scholar]
38. Yu, F., Wang, D., Shelhamer, E., Darrell, T. (2018). Deep layer aggregation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA. [Google Scholar]
39. He, K., Zhang, X., Ren, S., Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA. [Google Scholar]
40. Zhang, T., Zhang, X., Ke, X., Zhan, X., Shi, J. et al. (2020). LS-SSDD-v1.0: A deep learning dataset dedicated to small ship detection from large-scale sentinel-1 SAR images. Remote Sensing, 12(18), 2997. [Google Scholar]
41. Chen, Z., Li, B., Tian, L. F., Chao, D. (2017). Automatic detection and tracking of ship based on mean shift in corrected video sequences. 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, IEEE. [Google Scholar]
42. Zhang, Y., Li, Q. Z., Zang, F. N. (2017). Ship detection for visual maritime surveillance from non-stationary platforms. Ocean Engineering, 141, 53–63. [Google Scholar]
43. Liu, T., Pang, B., Ai, S., Sun, X. (2020). Study on visual detection algorithm of sea surface targets based on improved YOLOv3. Sensors, 20(24), 7263. [Google Scholar] [PubMed]
44. Shorten, C., Khoshgoftaar, T. M. (2019). A survey on image data augmentation for deep learning. Journal of Big Data, 6(1), 60. [Google Scholar]
45. Buslaev, A., Iglovikov, V. I., Khvedchenya, E., Parinov, A., Druzhinin, M. et al. (2020). Albumentations: Fast and flexible image augmentations. Information, 11(2), 125. [Google Scholar]
46. Taylor, L., Nitschke, G. (2018). Improving deep learning with generic data augmentation. 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bengaluru, India, IEEE. [Google Scholar]
47. Zhong, Z., Zheng, L., Kang, G., Li, S., Yang, Y. (2020). Random erasing data augmentation. Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34. New York, USA. [Google Scholar]
48. Xu, X., Zhang, X., Zhang, T., Yang, Z., Shi, J. et al. (2022). Shadow-background-noise 3D spatial decomposition using sparse low-rank gaussian properties for video-SAR moving target shadow enhancement. IEEE Geoscience and Remote Sensing Letters, 19, 1–5. [Google Scholar]
49. Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A. (2018). Towards deep learning models resistant to adversarial attacks. International Conference on Learning Representations. https://openreview.net/forum?id=rJzIBfZAb [Google Scholar]
50. Huang, S. W., Lin, C. T., Chen, S. P., Wu, Y. Y., Hsu, P. H. et al. (2018). AugGAN: Cross domain adaptation with GAN-based data augmentation. Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany. [Google Scholar]
51. Wang, S. H., Govindaraj, V. V., Górriz, J. M., Zhang, X., Zhang, Y. -D. (2021). COVID-19 classification by FGCNet with deep feature fusion from graph convolutional network and convolutional neural network. Information Fusion, 67, 208–229. [Google Scholar] [PubMed]
52. Zhang, Y., Zhang, X., Zhu, W. (2021). ANC: Attention network for COVID-19 explainable diagnosis based on convolutional block attention module. Computer Modeling in Engineering & Sciences, 127(3), 1037–1058. https://doi.org/10.32604/cmes.2021.015807 [Google Scholar] [CrossRef]
53. Tan, M., Pang, R., Le, Q. V. (2020). EfficientDet: Scalable and efficient object detection. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA. [Google Scholar]
54. Zhang, T., Zhang, X., Li, J., Xu, X., Wang, B. et al. (2021). SAR ship detection dataset (SSDDOfficial release and comprehensive data analysis. Remote Sensing, 13(18), 3690. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools