
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

IRMIRS: Inception-ResNet-Based Network for MRI Image Super-Resolution
1
Department of Electrical Engineering, Balochistan University of Engineering and Technology, Khuzdar, 89100, Pakistan
2
Department of Computer Systems Engineering, Balochistan University of Engineering and Technology, Khuzdar, 89100, Pakistan
3
Department of Mechanical Engineering, Balochistan University of Engineering and Technology, Khuzdar, 89100, Pakistan
4
Department of Mechanical Engineering, National Taiwan University of Science and Technology, 10607, Taiwan
5
Department of Information Systems, Kyungsung University, Busan, 613010, South Korea
* Corresponding Author: Zuhaibuddin Bhutto. Email:
Computer Modeling in Engineering & Sciences 2023, 136(2), 1121-1142. https://doi.org/10.32604/cmes.2023.021438
Received 14 January 2022; Accepted 24 June 2022; Issue published 06 February 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Medical image super-resolution is a fundamental challenge due to absorption and scattering in tissues. These challenges are increasing the interest in the quality of medical images. Recent research has proven that the rapid progress in convolutional neural networks (CNNs) has achieved superior performance in the area of medical image super-resolution. However, the traditional CNN approaches use interpolation techniques as a preprocessing stage to enlarge low-resolution magnetic resonance (MR) images, adding extra noise in the models and more memory consumption. Furthermore, conventional deep CNN approaches used layers in series-wise connection to create the deeper mode, because this later end layer cannot receive complete information and work as a dead layer. In this paper, we propose Inception-ResNet-based Network for MRI Image Super-Resolution known as IRMRIS. In our proposed approach, a bicubic interpolation is replaced with a deconvolution layer to learn the upsampling filters. Furthermore, a residual skip connection with the Inception block is used to reconstruct a high-resolution output image from a low-quality input image. Quantitative and qualitative evaluations of the proposed method are supported through extensive experiments in reconstructing sharper and clean texture details as compared to the state-of-the-art methods.Keywords
One of the most important and demanding imaging procedures is magnetic resonance imaging (MRI). MRI provides detailed, high-resolution images of human tissues. Super-resolution (SR) has proven to be very good for image quality, both in terms of peak signal-to-noise ratio and image acquisition time [1]. The main purpose of image SR is to generate a high-resolution (HR) output image from a degraded low-resolution version of the input image, which is common in the field of digital image processing, especially satellite imaging, medical image enhancement, facial recognition, and security surveillance. In the area of medical images, MRI is used to expose anatomical and cellular information and plays a vital contribution for both clinical and preclinical studies. Higher-resolution of MRI images are always used in imaging modalities. In addition, the physics of MRI severely attempts, that how high image resolution can be obtained within a specific time frame of the scanner because the MRI scanning process requires more time than the computerized tomography (CT) scanning process. Generally, for clinical MRI scanning process typically take 20 min at millimeter-size image resolution compared to a typical CT scan, which can be performed in seconds [2]. At present, innumerable approaches are available in the literature for MRI image super-resolution. The image SR can mainly be categorized into three: (1) interpolation, (2) reconstruction, and (3) learning based. Interpolation-based is a simple method of estimating neighboring values of a pixel’s intensity, this technique creates the extra noise in the model and induces ringing-like jagged artifacts. Reconstruction-based methods have mainly two domains, namely space-based and frequency-based domains. Spatial-based domain methods have reasonable potential for constraining priori information, whereas frequency-based approaches typically improve image resolution by removing spectral aliasing. Application of Maximum a Posteriori (MAP) method, the Projection onto Convex Sets (POCS) method, the hybrid MAP/POCS method, and the Iterative back-projection (IBP) method [3,4] are the most representative reconstruction-based methods. Irani et al. [5–7] proposed reconstruction-based algorithms in the field of medical MRI images to reconstruct the SR image. These approaches are very easy to implement, but do not yield unique solutions due to the ill-posed nature of the inverse problem. Sparse Representation method proposed by Ismail et al. [8] and Sparse-coding-based SR MRI algorithm suggested by Wang et al. [9] to find the sparse representation through a dictionary learning process. This algorithm has a little bit of improvement in the MRI low-resolution image, but still, the result is not satisfactory due to the limited resolution improvement, and it turns very slowly for 3D MRI images. The third category of image SR is deep learning-based algorithms into MR image super-resolution [10–18]. They have achieved a tremendous improvement due to their ability to self-learn from the large amount of data quickly and accurately. Furthermore, its design architecture is very simple and has an excellent reconstruction quality of the low-resolution MRI image. A shallow three CNN layers model was introduced by Dong et al. [19]. The first CNN layer is used to extract features from the original LR input image, the second CNN layer is used to nonlinearly map the HR patches, and the third layer is used to rebuild the HR image from the resultant patches. Kim et al. [20] presented an extremely accurate SR technique based on a VDSR convolutional neural network motivated by ImageNet classification model of Visual Geometry Group Network (VGG-net) [21]. The Fast-Super-Resolution Convolutional Neural Network (FSRCNN) [22] used an hourglass-shaped CNN with more layers but fewer parameters to speed up SR reconstruction. The Efficient Sub-Pixel Convolutional Neural Network (ESPCN) [23] completely extracts features in the LR image space and replaced the bicubic up-scaling procedure [24] with an efficient sub-pixel convolutional layer. To reduce the computational cost in terms of several parameters, Kim et al. [25] suggested a new type of network architecture with deeply recursive layers (DRCN). Lai et al. [26] presented a deep Laplacian pyramid network up to 27 convolutional layers of network depth, which dramatically improved accuracy and speed. To producing plausible-appearing HR images with acceptable perceptual quality, Ledig et al. [27] offered a generative adversarial networks method. Even though the above CNN-based SR techniques have achieved excellent reconstruction quality and efficiency, they still have some deficiencies that need to be addressed. The most recent CNN-based approaches face the challenging of vanishing gradient problem during the training by stacking CNN layers side by side to build a deeper network architecture. Besides that, the bicubic interpolation approach is utilized as a pre-processing step, which increases the extra burden on the model during the training. Therefore, the reconstructed SR images have the jagged ringing effect and blurring problem. In this paper, to address the aforementioned issues, we present a new approach named as Inception-ResNet-based Network for MRI Image super-resolution, which employs well-designed residual with inception blocks to generate the required HR output images from the observed input LR images.
The main contribution of our proposed work can be summarized as:
• A lightweight skip connection block is used to avoid the problem of vanishing gradients during the training. These blocks extract the features information with the help of local as well as global skip connections.
• The PReLU activation function is utilized to resolve the issue of dying of the ReLU activation function.
• The pre-processing step of bicubic interpolation is replaced with a deconvolution layer to extract the features information from the low-resolution domain.
The remainder of the paper is formatted in the following manner. In Section 2, a concise overview of related work is given. Our proposed network design is presented in Section 3. The experimental qualitative/quantitative results, implementation details, and ablation study are provided in Section 4. In Section 5, the conclusion of our work is presented.
Single Image Super-resolution (SISR) approaches have been used for a wide variety of real-world applications, including remote sensing [28,29], computer vision tasks [22,23,30], face-related applications [31,32], and medical image analysis-based applications [33,34]. Recently, deep CNN-based approaches have been widely employed for image SR tasks. Dong et al. [19] published the groundbreaking shallow type three-layer network for image super-resolution. In this approach authors produced better quantitative results than earlier approaches. The main flaws of this approach [19] has a very low number of layers. After that, Kim et al. [20] proposed a 20-layer deeper CNN architecture network with a global residual learning connection. To increase the performance of very deep SR (VDSR), authors used a faster convergence rate. The main problem with VDSR is to utilize the pre-processed bicubic upscaled version of an input image to the network, so it had an increase in the computation burden on the model. Subsequently, SR Generative Adversarial Networks was proposed in [27], which include a combination of a generator part and a discriminator part. To overcome the vanishing gradient problem, the generator part of the network has B residual blocks with short-cut skip connections [35]. Small down-sampled images are used as inputs to this method, which reduces the computing cost. This network, however, proved unable to produce SR images at all enlargement factors in a single network, which was the disadvantage of this approach. Lim et al. [36] were inspired by SRResNet and gave the idea of an Enhanced Deep Residual SR network abbreviated as EDSR approach, which won the SR NITRE 2017 challenge. Batch normalization layers were removed in this strategy, resulting in a network that has low memory consumption. Some of the methods described above are used for natural image super-resolution tasks and other MRI-related images are described below.
The use of a high-dose tracer is one of the strategies for obtaining a superior quality of the Positron Emission Tomography (PET) image and can raise the risk of radiation damage. As a result, several efforts have been made to evaluate PET images (high-dose) from a low-dose [37–40]. Xiang et al. [38] attempted to apply this kind of approach to calculate the fast and better estimation of PET images (high-dose) due to the achievement of neural networks, particularly SRCNN [19] in image super-resolution. One of the recent works has been proposed by Song et al. [41], for obtaining HR PET images through a multi-channel input. Hong et al. [42] provided another approach for image enhancement, especially for PET images. Malczewski [43] proposed super-resolution with compressively sensed MR/PET signals as an input to obtain excellent performance in boosting the quality of PET images. Moreover, deep learning-based algorithms have proven to be useful tools for various MRI image enhancement applications including MRI reconstruction and super-resolution [44–49]. For static brain MRI, various deep learning-based image super-resolution MRI concepts have been proposed. Deep convolutional neural network approaches have been used to tackle the Spatio-temporal trade-off [50] and used for dynamic cardiac MRI image reconstruction [51,52]. A tight-frame UNet architecture using wavelet decomposition was proposed by Han et al. [53], which enhances the performance of UNet for inverse issues of the 2D view of CT images. Qiu et al. [54] proposed a multi-window back-projection residual network model known as (MWSR). In this approach, the authors used the multi-window technique to improve the similar features mapping to reconstruct the richer high as well as low features information. Qiu et al. [55] suggested a novel method of multiple improved residual networks (MIRN) based on image SR reconstruction. In this approach, ResNet blocks are coupled through multi-level skip connections to build up different improved ResNet blocks. For training purposes, they used the stochastic gradient descent method. GAN network for medical image SR proposed by Ma et al. [56]. The proposed network architecture is divided into five different stages, namely sub-pixel as a pre-processing stage, and others are feature extraction, mapping stage (nonlinear, which consists of 128 residual blocks), sub-pixel convolution, and final summation of pixel mean as a post-processing stage. Feng et al. [57] proposed the concept of multi-modal based MRI technique with transformer concept. In this paper, the author initially used the transformers which are used to extract the global features. Additionally, the same author improved the performance of MRI images with the concept of Multi-contrast MRI image SR with the help of a multi-stage integration network [58]. This work explores the response of multi-contrast with fusion at various phases. In the field of deep convolutional neural networks, attention mechanism plays a crucial role to reconstruct the high-quality MRI images. In this regard, Feng et al. [59] suggested the idea of separable attention for Multi-contrast MRI image SR. Separable attention mechanism is used to extract the contrast anatomical information such as blood vessels, tissues, and bones. Chen et al. [60] proposed trusted deep CNN based SR model known as feedback adaptive weighted dense network (FWDN) to reconstruct the high-resolution medical image from the low-resolution medical input image. All the low-level features information is transmitted through a feedback connection.
Our proposed method designed a novel network architecture, which depends on the capabilities of deep learning-based CNN architecture such as GoogLeNet Inception block-based network architecture. In the fields of image SR and classification tasks, GoogLeNet Inception blocks are considered a successful approach to reducing the number of parameters. Furthermore, rather than relying on hand-designed features, deep learning-based networks can extract rich feature information from the training set of samples automatically, which is better for MRI image reconstruction. Although there have been reported significant performance, still there are many flaws. For example, the vanishing gradient problem occurs in the deeper CNN model during the training and causes the overfitting and underfitting in the model. Though the short, as well as dense skip connections, were used to overcome a vanishing gradient problem. To solve the issues mentioned above, we offer a unique deep neural network-based approach for reconstructing an HR MRI image from an LR.
As we know, the fact that low-resolution MRI images are very hard for doctors to identify the disease and do not take the proper decision about the health of the patient. To alleviate this problem, we proposed a very fast and robust network architecture for MRI images, especially brain MRI low-resolution images, which is based on ResNet and Inception blocks. Our proposed methodology used two CNN layers, 4 ResNet with 4 Inception blocks, one deconvolution layer, and one bottleneck layer. All layers in our proposed network architecture are followed by the PReLU activation function except the last layer. For initial low-level features are extracted from the original LR domain by using two CNN layers with 4 ResNet blocks. The resultant low-level features are sent to the Inception blocks for multiscale feature reconstruction purposes. To update the features information using local, as well as global skip connections simultaneously. The cumulative sum of features is used by the deconvolution layer to transform LR features into HR features. During training, the proposed design solves the problem of vanishing gradients [20] with the support of local as well as global skip connections. The complete framework of our proposed method as shown in Fig. 1. Furthermore, our proposed algorithm depends on the learning-based approach, but earlier deep learning-based CNN algorithms used interpolation (bicubic) as a pre-processing step to enlarge the LR image.
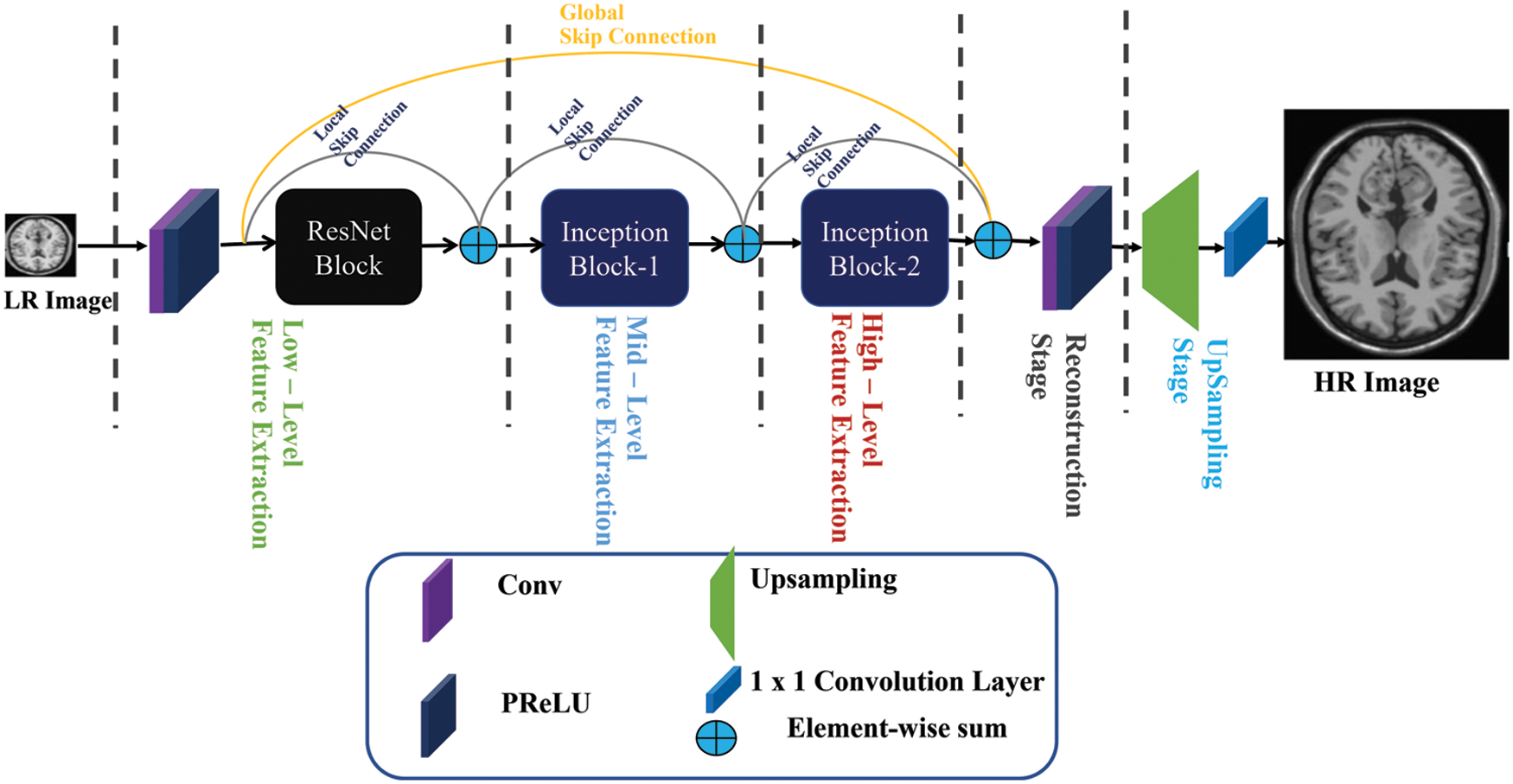
Figure 1: Proposed inception-ResNet-based network for MRI image super-resolution
3.1 Low-Level Feature Extraction
Feature extraction is the first and most important stage in every image analysis method. Initially, for low-level feature extraction purposes, the researcher community used traditional approaches like a hand-designed filter. Our approach replaces the conventional hand-designed approach with deep convolutional neural network-based approach, which automatically learns the features from the training dataset. In addition, earlier approaches were used the interpolation technique as a pre-processing step to upsample the LR image. Wang et al. [61] claimed that bicubic interpolation is not intended for this purpose and even damages the most critical LR image information, which is crucial in reconstructing the HR image. Our proposed approach applies an alternative strategy to extract the features information from the original input low-resolution image. Our low-level feature extraction stage depends on two convolution layers with four ResNet blocks both are followed by Parametric Rectified Linear Unit (PReLU) acting as nonlinear mappings. The Convolutional neural network layers can be expressed as:
where
One of the keystones to recent deep learning achievements has been due to the involvement of Rectified Linear Unit (ReLU) [62] activation function. It performs a better operation than the sigmoid activation function. In the case of sigmoid activations, this is partly related to the vanishing gradient problem. To resolve the difficulty of the computational complexity of the deep CNN model with the introduction of the ReLU activation function. Since it poses no restriction on positive inputs, gradients have more chances to reach deeper layers in backpropagation, thus enabling learning in deeper layers. In addition, the computation of the gradient in backpropagation learning is reduced to multiplication with a constant, which is far more computationally efficient. The one main drawback of the ReLU is that it does not activate for non-positive inputs, causing the deactivation of several neurons during the training, which can view again as a vanishing gradient problem for negative values.
Mathematically, ReLU can be explained as:
This issue is resolved by the derivative of ReLU known as Parametric Rectified Linear Unit (PReLU) [63], which has a learnable parameter α, controlling the leakage of the negative values, as shown in Eq. (3). In other words, PReLU is a Leaky ReLU, because the slope of the curve for the negative value of
From the comparison, as shown in Fig. 2 below in the negative portion, and the positive portion of ReLU is introduced by PReLU as a learnable parameter, which making it slightly symmetric. Additionally, earlier research has shown that PReLU converges quicker than ReLU and achieves improved performance [64]. Thus, our proposed method adopts PReLU as an activation function to provide a more powerful representational ability.
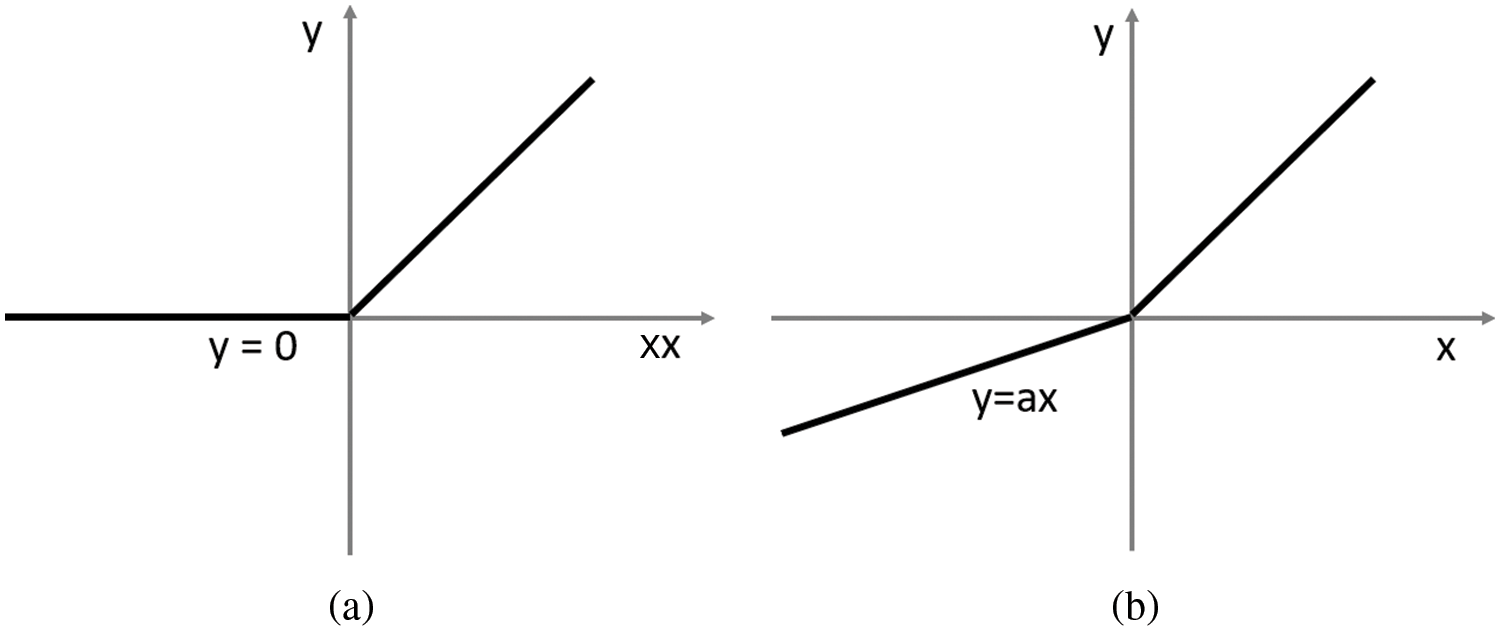
Figure 2: Comparison of ReLU (a) vs. PReLU (b). The PReLU includes a learnable parameter that can slightly symmetrically counterbalance the ReLU’s positive mean
Inspired by He et al. [35] which was initially proposed a residual network in 2016. In this approach, a series of feature maps of the first input layer is skipped, and output is added to the third layer with identity mapping. According to [35], shortcut skip connections can efficiently enable gradient flow through numerous layers, hence increasing the efficiency of deeper network architecture during the training. The structural diagrams of the original ResNet [35], SRResNet [27], and proposed ResNet block as shown in Fig. 3. In the proposed block remove the batch normalization (BN) layers, as suggested by Nah et al. [65] in image deblurring work. The proposed block used the dense skip connection with two kernels of size 3 × 3 followed by PReLU with a shrinking layer of size 1 × 1.
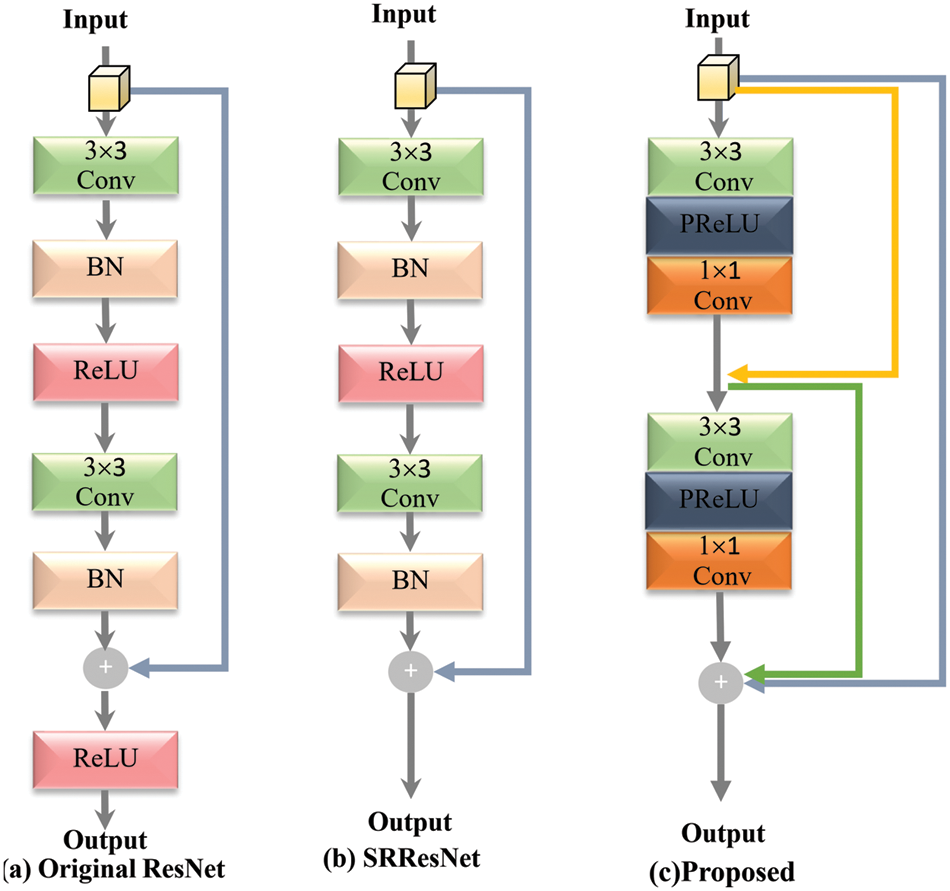
Figure 3: Comparison of basic skip connection blocks, such as original ResNet [35], SRResNet [27], and our proposed ResNet block
3.4 Inception (GoogLeNet) Block
Inception-V1 is another name for GoogLeNet, which won the 2014 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) competition. The GoogLeNet architecture’s primary goal was to achieve excellent accuracy at a low cost of computing [66–69]. Inception block is a novel concept from CNN that combines split, transform, and merge techniques with multi-scale convolutional transformations. The proposed design of the inception block is shown in Fig. 4. The proposed block has filters of different kernel size of the order 1 × 1, 3 × 3, 5 × 5, and 7 × 7 for capturing spatial information at various enlargement factors. GoogLeNet divide, transform, and merge concepts help to solving different resolution problems in the images. To reduce the computation burden, GoogLeNet first adds a bottleneck layer of 1 × 1 convolutional filter. To prevent redundant features and cut costs by eliminating pointless feature map, it also uses sparse connections (not all the output feature maps are connected to all the input feature maps).
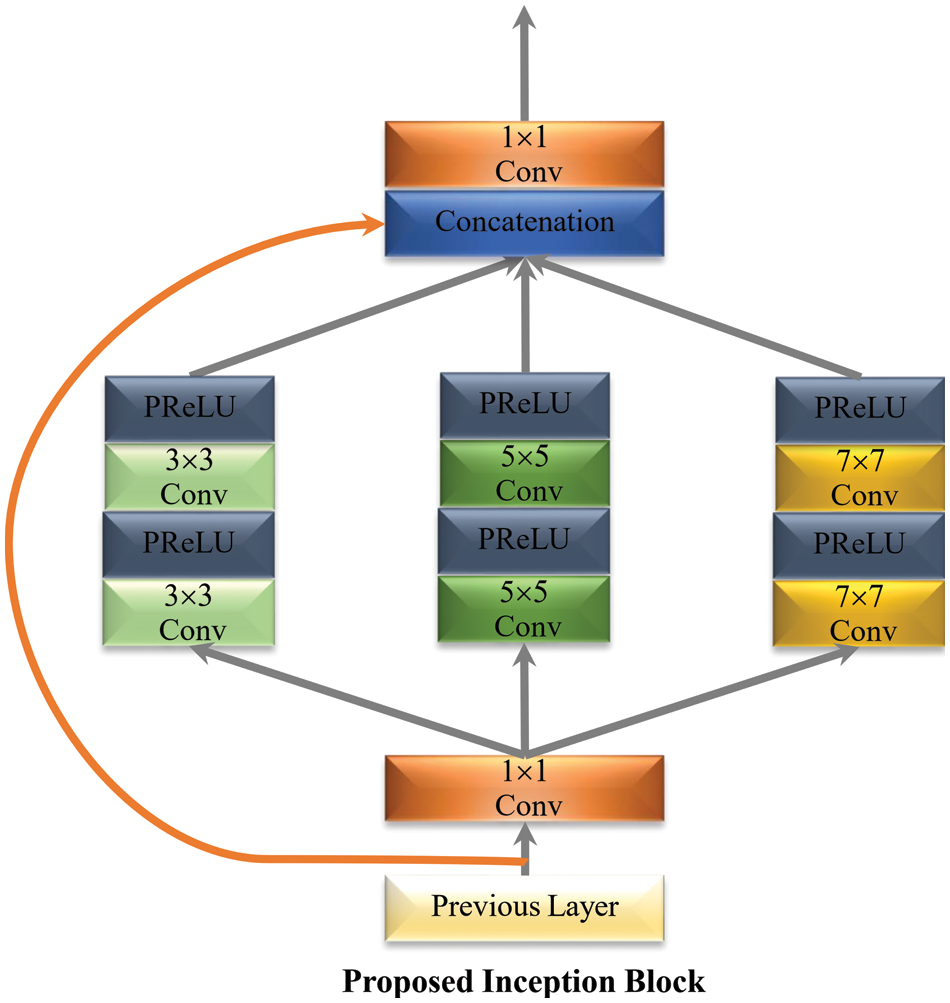
Figure 4: Proposed multi-path inception block
3.5 Deconvolution Layer (UpSampling Stage)
Different from the earlier proposed models in [19,20], we replaced the hand-designed interpolation technique with a Deconvolution layer to upscale the low-resolution MRI image. For reconstructing a high-resolution MRI image adding a deconvolution layer is a very popular choice. This approach has been successfully used in [70] and in [71].
The experimental results were carried out using the Windows 10 operating system. The deep learning library ran on an NVIDIA GeForce RTX2070 GPU with a 2.6 GHz Ci7-9750H CPU and 16 GB RAM, PyTorch version 1.6.0, and Python version 3.6. The training phase and testing phase were used as the divisions for the proposed network design. In the training phase, we used the data augmentation technique in terms of flipping, rotation, and cropping. The difference in value between the predicted value and the desired value is calculated using the mean-square loss function. The formula for calculating Mean Squared Error (MSE) is as follows:
where
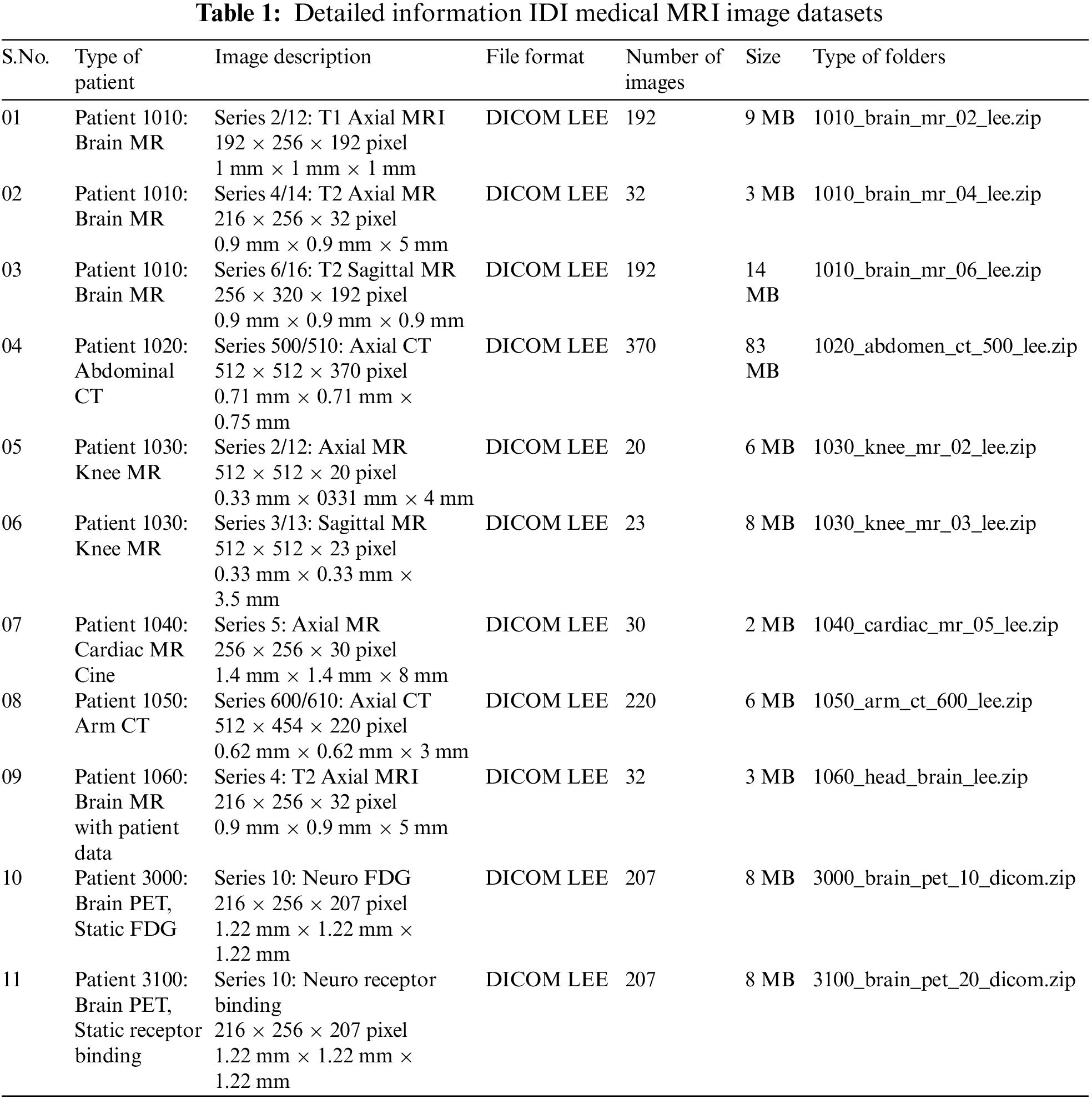
There are many datasets available to train the proposed model, but we used the same training datasets that are commonly used by well-known image Super-Resolution methods, like VDSR, DRCNN, and LapSRN. So, for the first proposed model is trained on Natural image datasets. To further illustrate our proposed method, authors separately trained another model using a purely MRI image dataset which is obtained from I DO Imaging (IDI) [72,73]. The Knee MR dataset contains 23 sagittal MRIs, each with a size of 512 × 512 × 23 pixels, 0.33 mm × 0.33 mm × 3.5 mm, and the heart MR dataset contains 30 axial MRIs, each with a size of 256 × 256 × 30 pixels, 1.4 mm × 1.4 mm × 8 mm. The IDI medical image dataset contains 192 axial MRIs, each with a size of 192 × 256 × 192 pixels, 1 mm × 1 mm × 1 mm. The complete dataset is divided into 80% and 20% percent ratios for training and validation datasets. Further complete details of image dataset are available in Table 1.
4.2 Training and Testing Image Generation Model
The main purpose of image generation in super-resolution is to generate the realistic training datasets to improve the SR performance. The detailed experimental scheme is shown in Fig. 5. For image generation purpose, initially we apply the bicubic interpolation technique to generate the LR patches. The generated LR patches apply the data augmentation technique in terms of rotation, flipping, and cropping to increase the training data size as well as reduce the overfitting chances of the model. Afterward, the generated dataset is used to minimize the training loss and optimize the model efficiency. Finally, evaluate the performance of the proposed model on different testing image datasets to reconstruct the HR image.
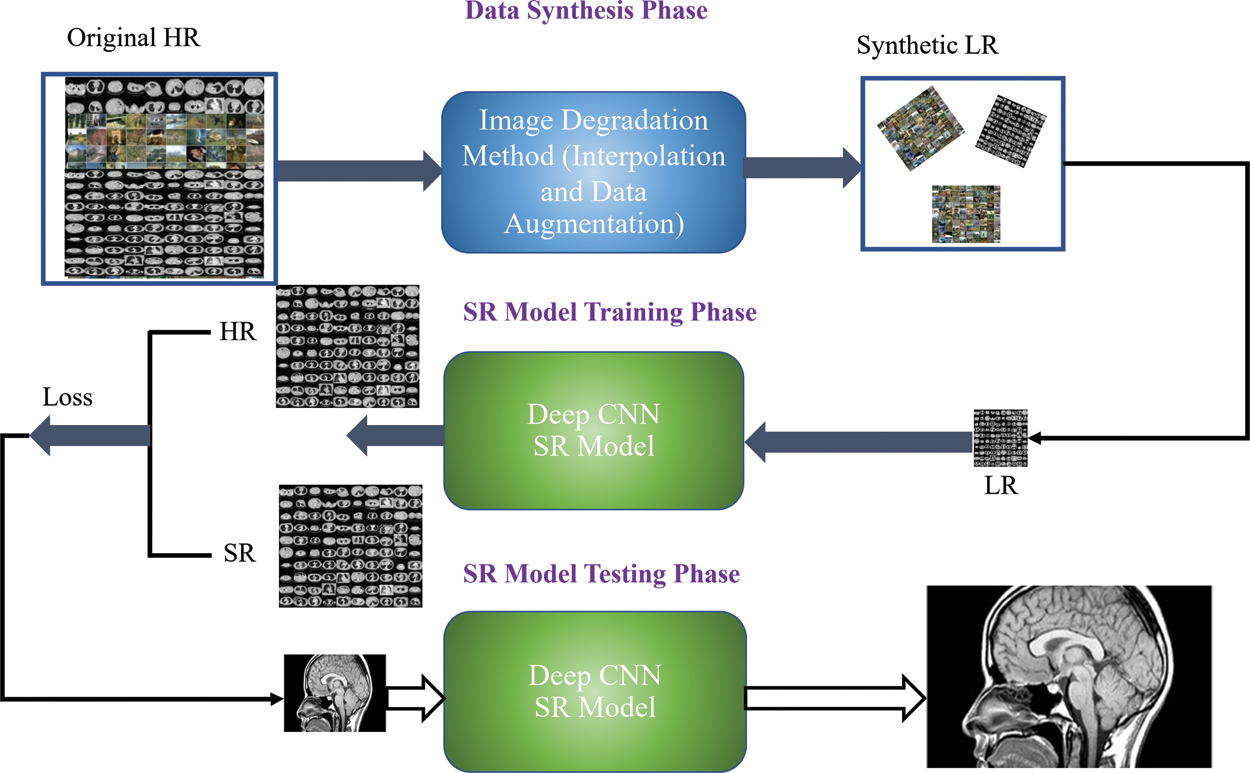
Figure 5: Training and testing image generation model scheme for image super-resolution model
Our proposed model is implemented in PyTorch version 1.6.0, Keras backend as a TensorFlow. The other image processing libraries like OpenCV, Scikit-image, and SciPy were used before and after the training. Our model is trained on 200 epochs, with an initial learning rate is 0.0001 of a mini-batch size is 32. Initially, the model was trained with the following parameters: epoch = 10, learning rate = 0.001, Batch size = 32, and filter size impacts spread velocity. Large batch sizes will result in increased complexity and memory costs for training but less loss.
For quantitative measurement, the higher value of PSNR indicates the better reconstruction of HR image and is generally obtained from the MSE function:
The PSNR is expressed as:
where the terms
Mathematically, the terms SSIM are expressed as:
where
4.4 Comparison with the State-of-the-Art Method
To evaluate the comparison quality of image SR methods with the proposed approach, particularly Bicubic, A+, SelfExSR, RFL, SRCNN, FSRCNN, VDSR, DRCN, LapSRN, DRRN, and IDN techniques. Table 2 presents the quantitative results of different algorithms on the Set5, Set14, BSDS100, and Urban100 test data sets, with an enlargement factor of 2×, 3×, and 4× accordingly. Fig. 6 shows the quantitative performance of state-of-the-art approaches in terms of PSNR vs. network parameters. Our proposed model (IRMRIS) has fewer parameters than the VDSR, DRCN, and LapSRN. Despite having a lower footprint as compared to CNN-based approaches, the performance of the proposed model was demonstrated to be state-of-the-art. As compared to the Bicubic, A+, SelfExSR, RFL, SRCNN, FSRCNN, VDSR, DRCN, and LapSRN. Furthermore, our IRMRIS model has about 1.87, 0.78, 0.79, 0.86, 0.67, 0.56, 0.56, 0.29, and 0.27 dB improvement on the BSDS100 dataset for enlargement factor 3× image SR. Figs. 7–10 present a visual performance comparison of the brain MRI images at enlargement factor 4× SR. The result of the baseline method (bicubic) and SRCNN clearly shows blurry MRI image, but our proposed IRMRIS reconstruct the best results as compared to another state-of-the-art methods MRI image SR.
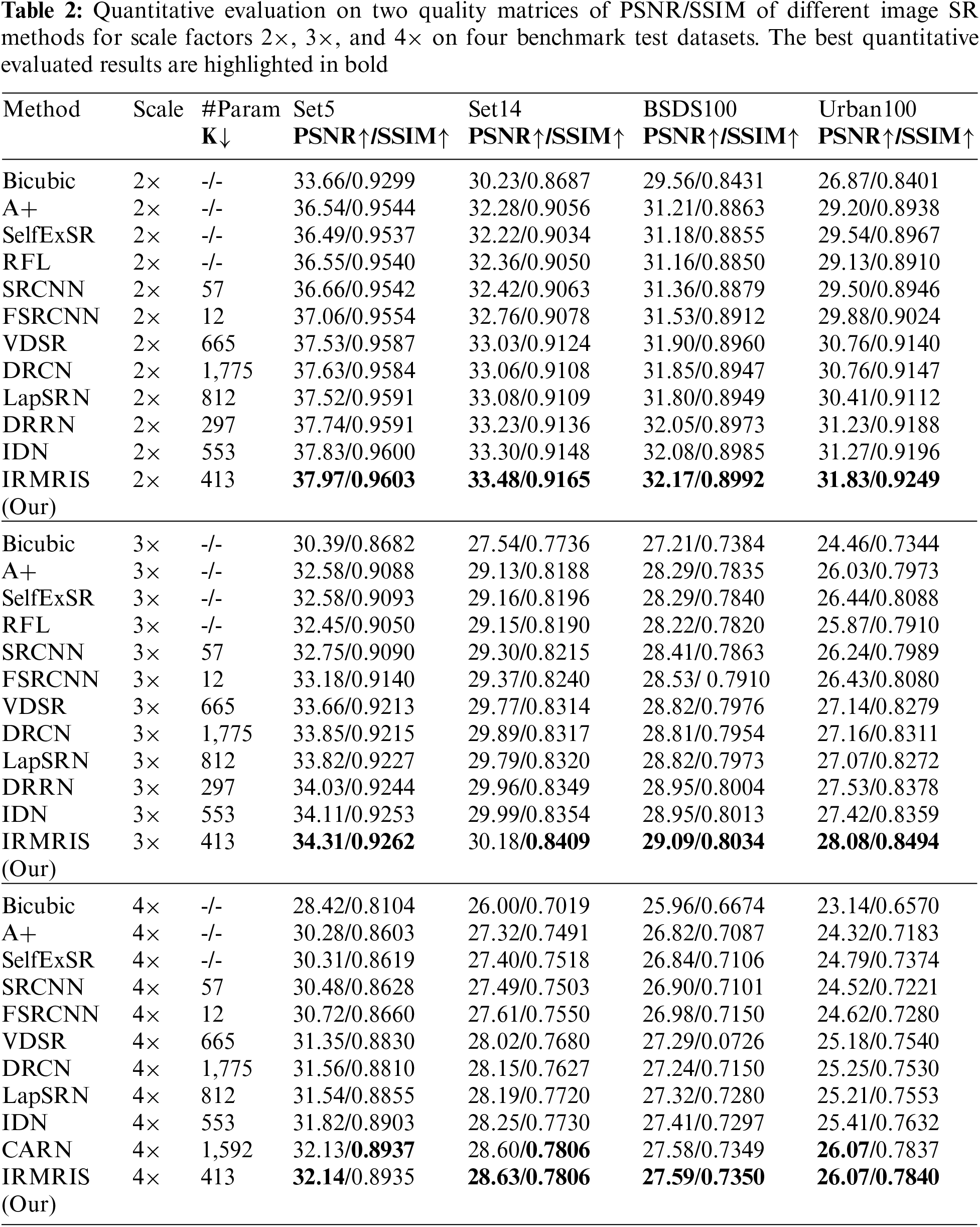
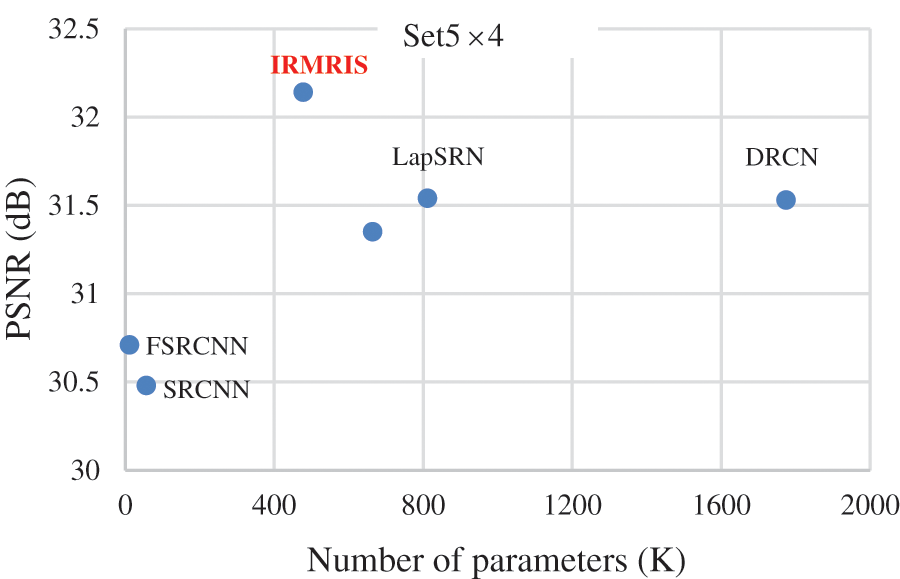
Figure 6: Comparison of computational cost (number of K parameters) vs. PSNR (dB)
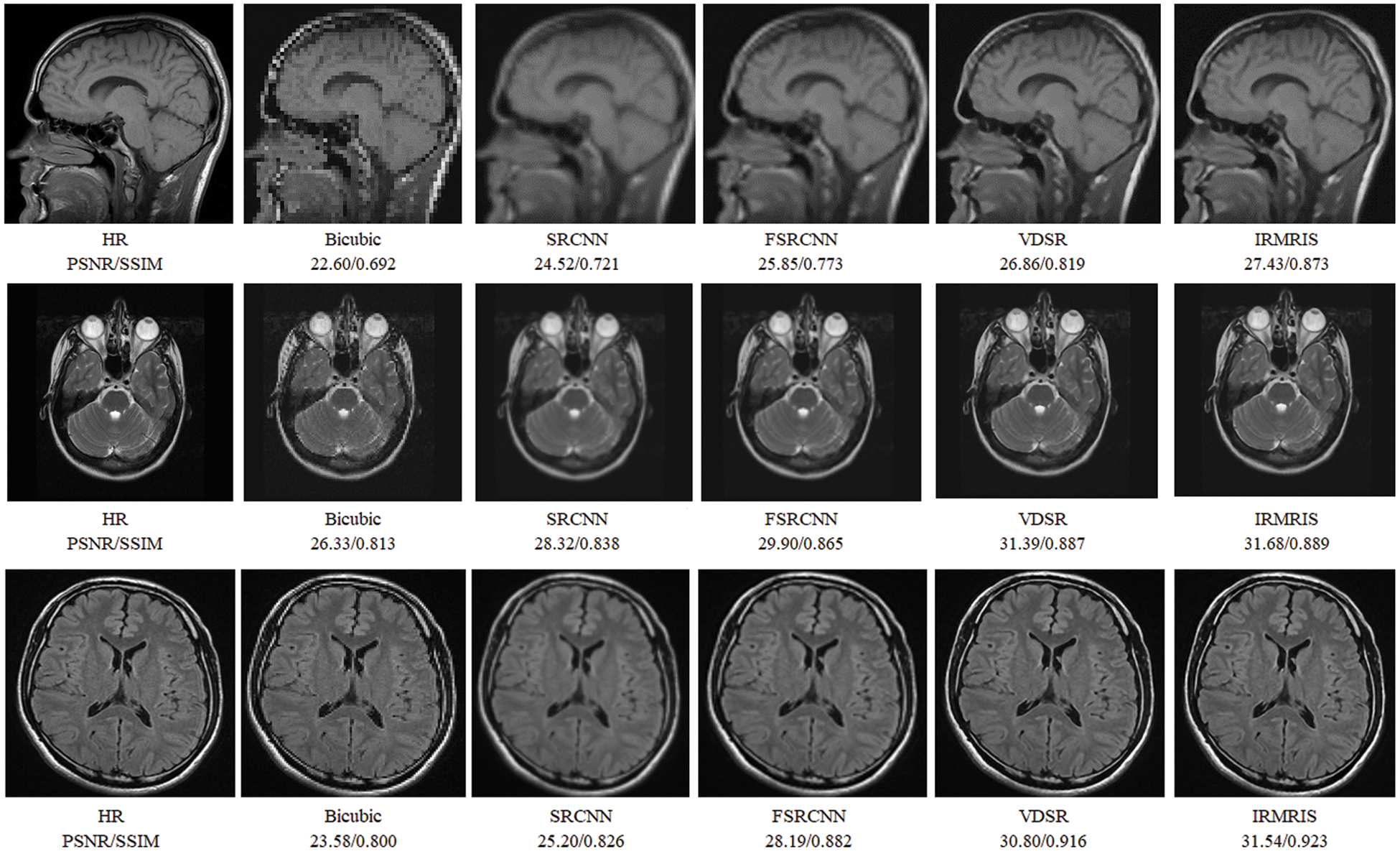
Figure 7: Perceptual quality comparison of our method with other deep learning-based methods using MRI images at 4× super-resolution
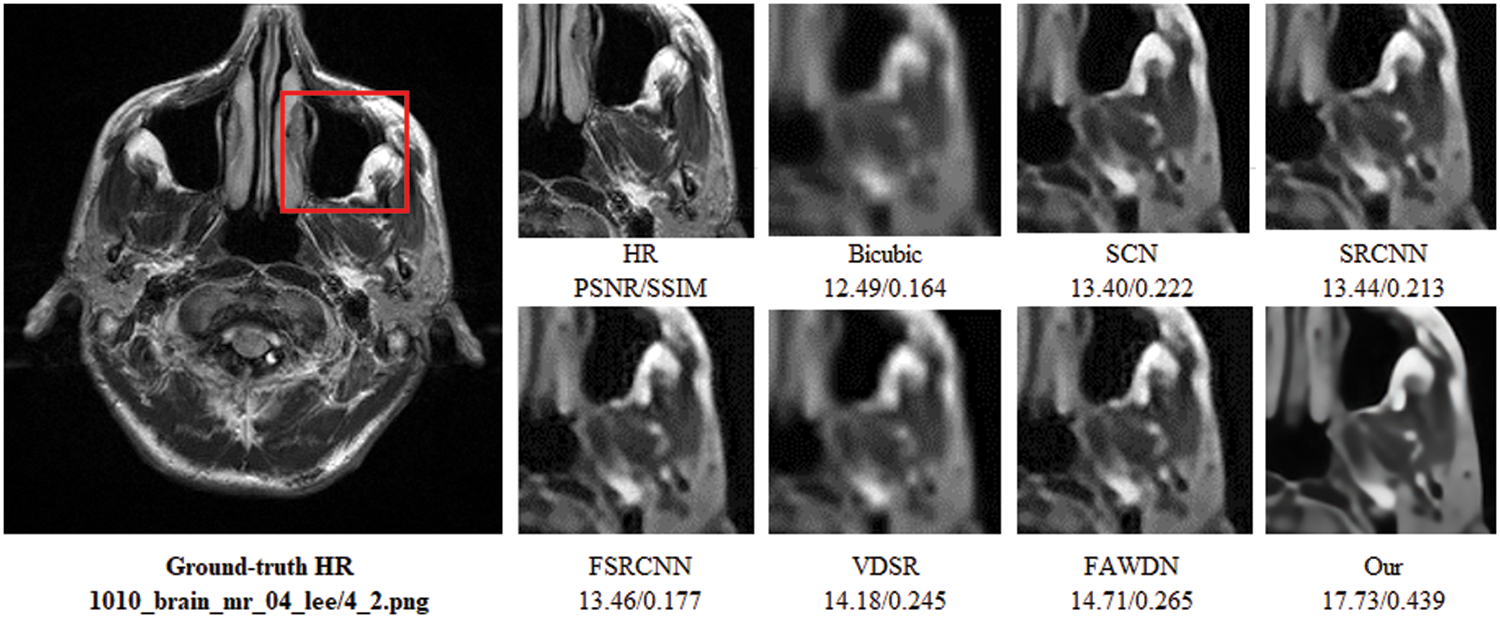
Figure 8: Perceptual quality comparison of our method with other deep learning-based methods using MRI images at 4× super-resolution. The image is obtained from “1010_brain_mr_04_lee/4_2.png” dataset
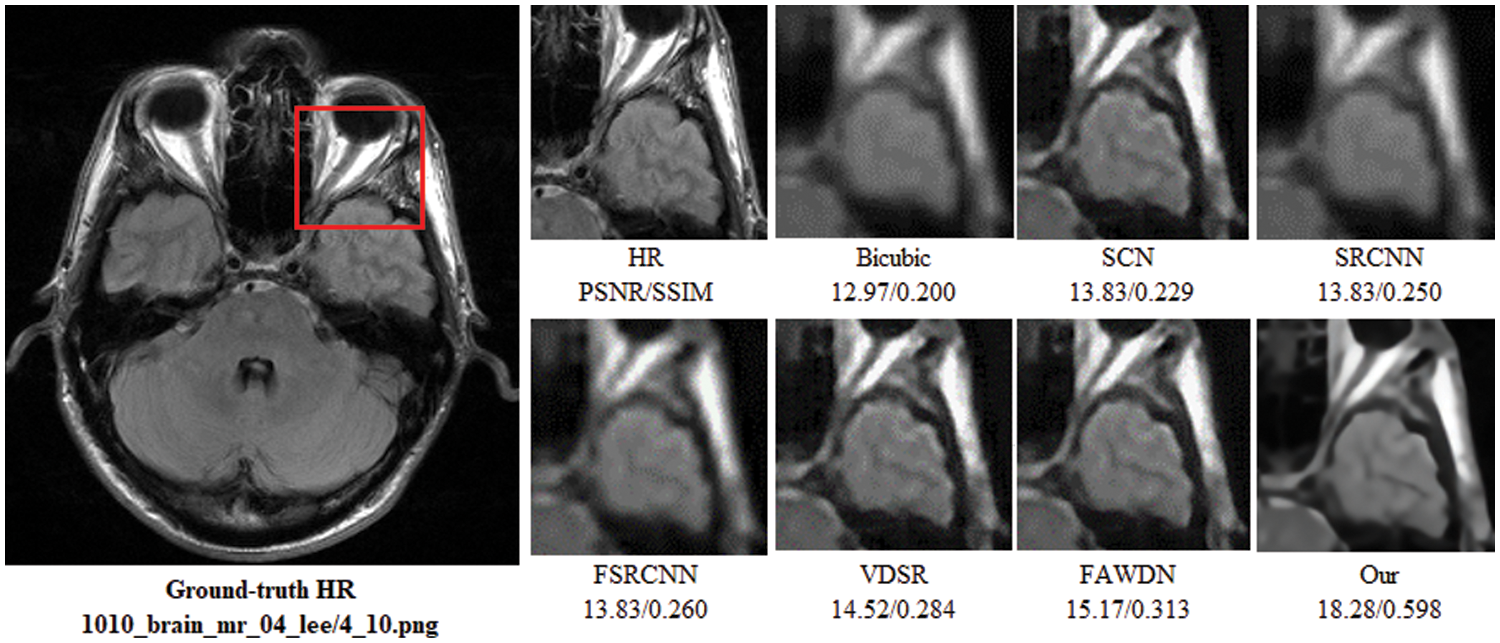
Figure 9: Perceptual quality comparison of our method with other deep learning-based methods using MRI images at 4× super-resolution. The image is obtained from “1010_brain_mr_04_lee/4_10.png” dataset
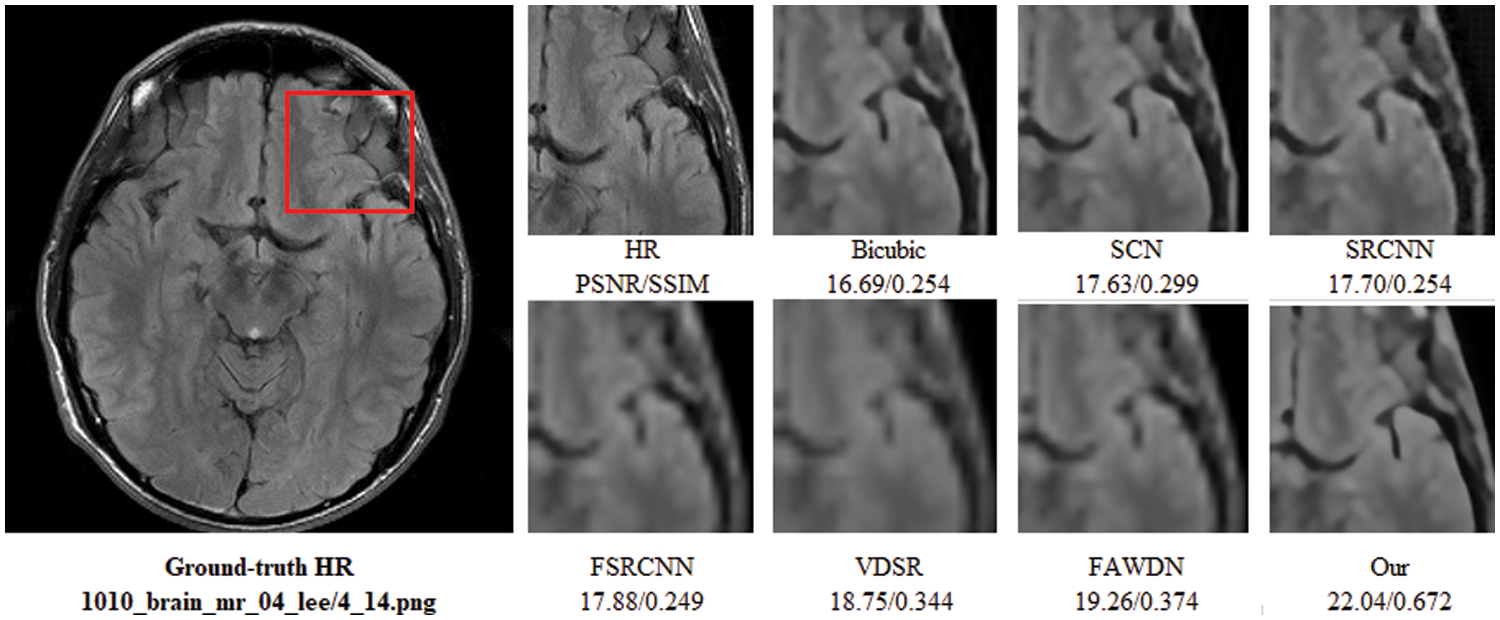
Figure 10: Perceptual quality comparison of our method with other deep learning-based methods using MRI images at 4× super-resolution. The image is obtained from “1010_brain_mr_04_lee/4_14.png” dataset
We further evaluate the importance of skip connections in the image reconstruction process. In this section, we will discuss four cases of skip connection such as network without skip connection, network that includes only local skip connection, other is a network only involves global skip connection and finally, we used the local as global skip connection in the network. All simulation results are performed on MRI image IDI [72,73] dataset with enlargement factor 2× in terms of PSNR/SSIM as shown in Table 3. Initially, we evaluate our model without skip connection. The result is satisfactory, but training have some issues and is not stable. In our local and global skip connections, results are satisfactory. All simulation results are conducted on 30 epochs with 4 medical images obtained from medical IDI [72,73] image dataset. All other hyper-parameters are the same during the ablation study. Finally, we confirmed that only local skip connection mainly drops the value of the quality matrix. In conclusion, our conducted study shows that global with local skip connection plays a vital role in the overall image reconstruction process in the field of image super-resolution.
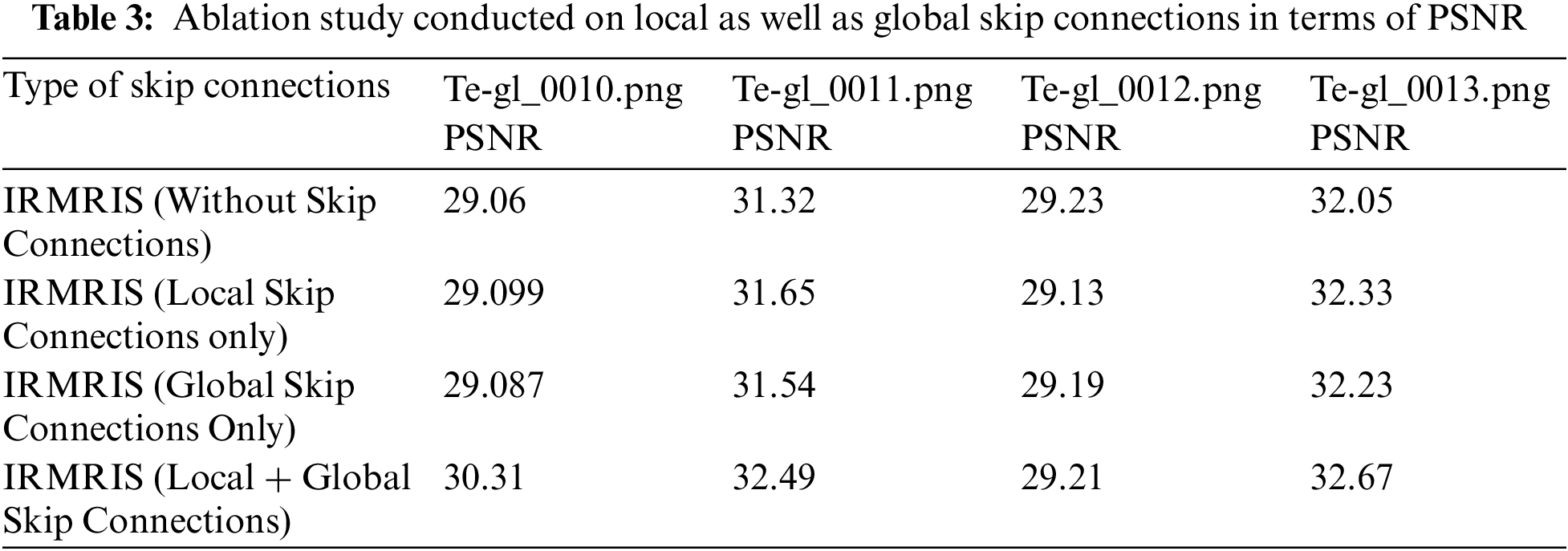
The visualization of the convergence process is presented in Figs. 11–13. The curves verify the analyses to show that the proposed model with PReLU activation function stabilizes the training process and accelerates the model convergence. From these curves, we can see that the ReLU activation function reduces the performance, but PReLU based activation function provides better performance.
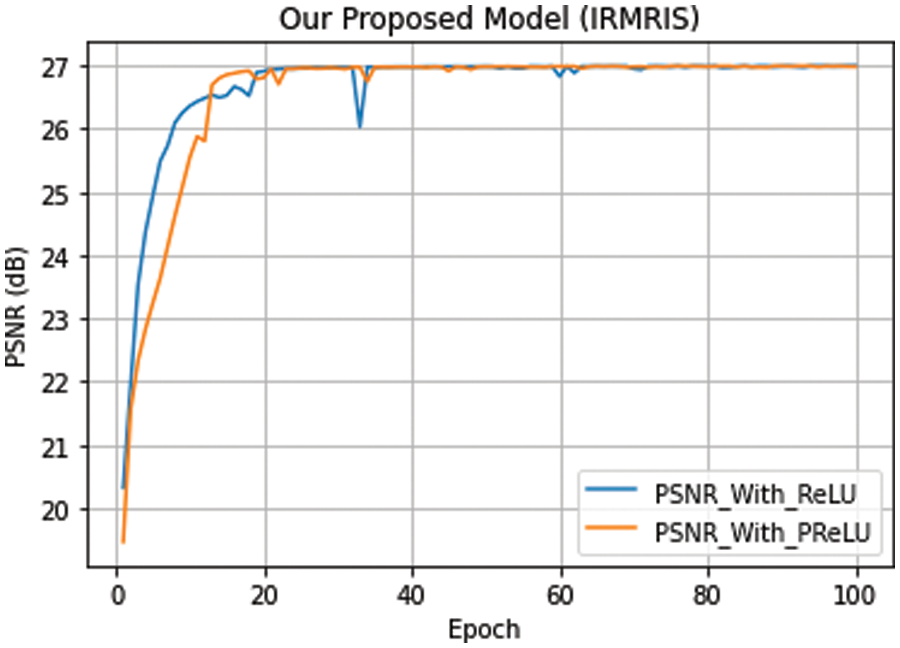
Figure 11: Our model convergence with different activation functions. The curves of PSNR vs. epoch were performed on a very small MRI test dataset (5 images) with enlargement factor 4×. Remaining other setting of models is similar to an original IRMRIS model discussed in experimental sections
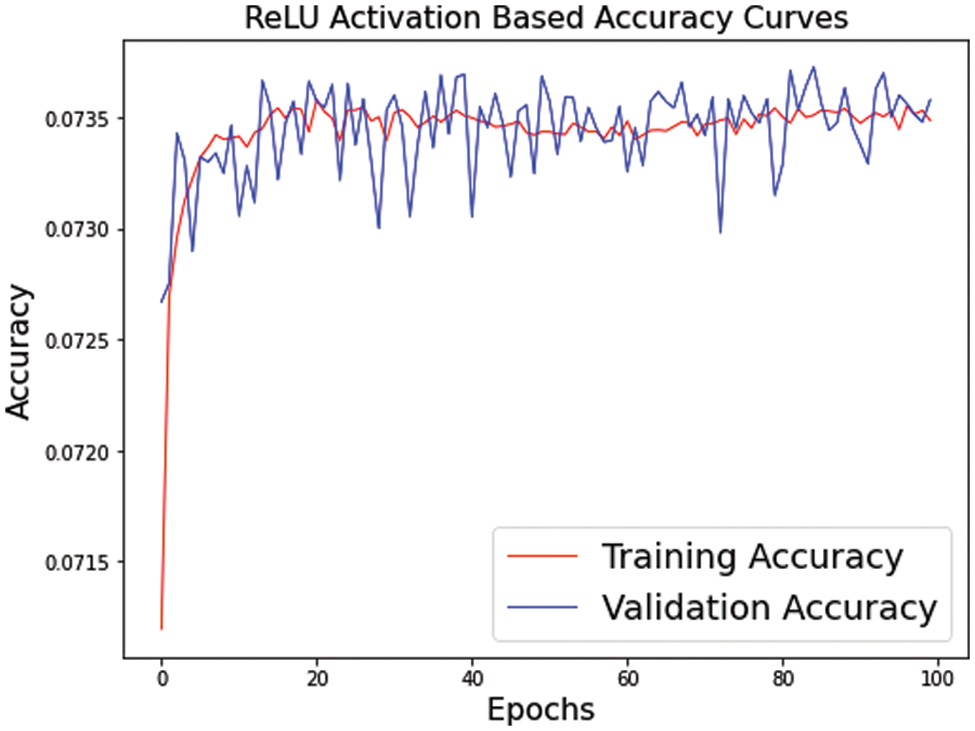
Figure 12: Our model convergence with ReLU activation functions. The curves of ReLU accuracy vs. epoch were performed on a very small MRI test dataset (5 images) with enlargement factor 4×. Remaining other setting of models is similar to an original IRMRIS model discussed in experimental sections
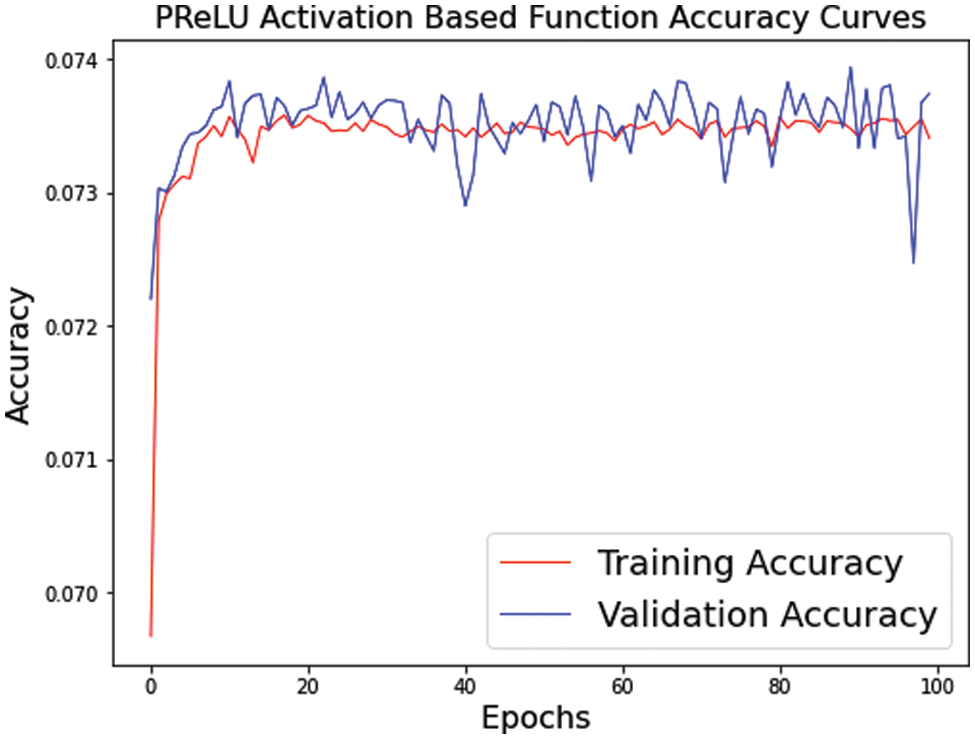
Figure 13: Our model convergence with PReLU activation functions. The curves of PReLU accuracy vs. epoch were performed on a very small MRI test dataset (5 images) with enlargement factor 4×. Remaining other setting of models is similar to an original IRMRIS model discussed in experimental sections
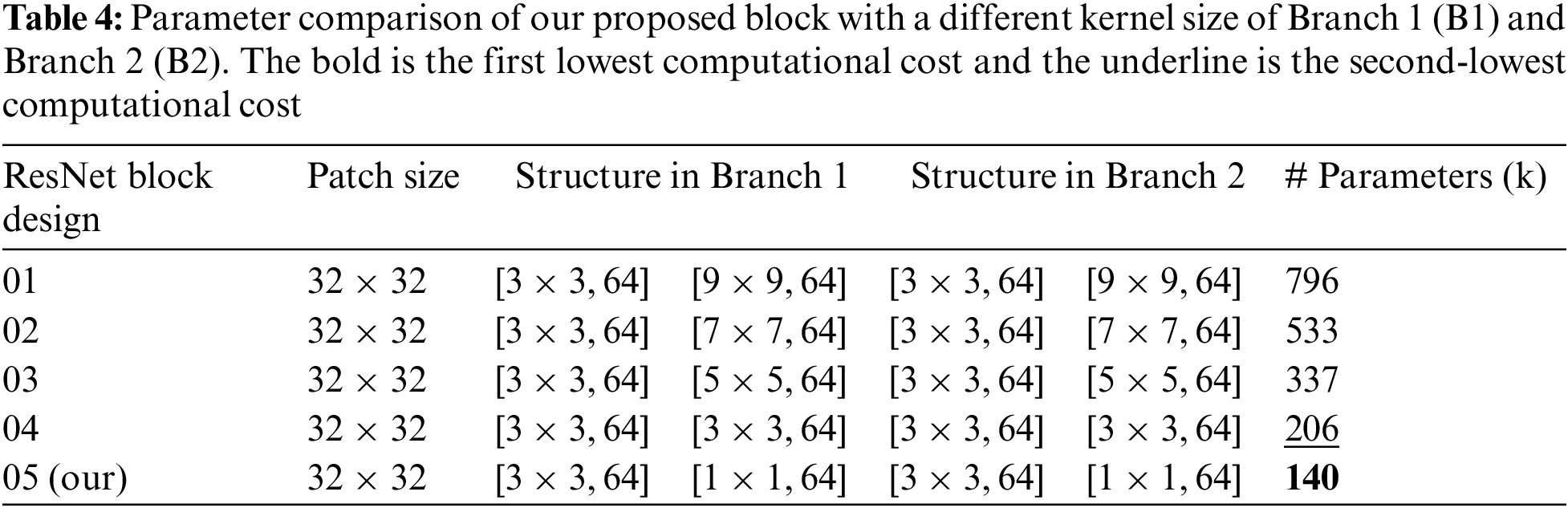
4.5.3 Kernel Size in ResNet Block
The selection of kernel size plays a crucial role in the design of network architecture as well as handle the issue of overfitting during the training. Initially, we evaluate the complexity of our block with the supporting of two different kernel size in the order of 3 × 3 and 9 × 9 with same number of filters 64 in both branches. The resultant output parameter of such arrangement is 796 K. Next. We replace the kernel size is 3 × 3 with 7 × 7, 3 × 3 with 5 × 5 and finally our proposed kernels in the order of 3 × 3 with 1 × 1. Table 4 clearly observes that our proposed ResNet block has a smaller number of parameters, so we reduce the computational burden on the model during the training and avoid the vanishing gradient problem.
In this paper, we have proposed a novel Inception-ResNet-based Network for MRI Image Super-Resolution. The model architecture of our proposed method is primarily composed of two ResNet and Inception blocks with end-to-end connections followed by the PReLU non-linear activation operation. These blocks use many skip/short connections to resolve the vanishing gradient problem. Our proposed method firstly reduces the computational cost in terms of several parameters by an efficient ResNet with the Inception block technique. A low-quality or LR image is an input into the model via the proposed ResNet and Inception block. The reconstructed MRI image is upscaled through a deconvolution layer to generate the high-resolution MRI image. The suggested model was evaluated against current state-of-the-art methodologies such as Bicubic, VDSR, DRCN, FSRCNN, SRCNN, LapSRN, DRRN, and IDN methods. Extensive quantitative and qualitative results on public datasets support the superiority and effectiveness of our proposed IRMRIS in terms of various quality metrics. In future work, we will develop a fast and more robust model to generate the MRI image SR and increase computational efficiency.
Funding Statement: Our work was supported by Balochistan University of Engineering and Technology, Khuzdar, Balochistan, Pakistan.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Plenge, E., Poot, D., Bernsen, H. M., Kotek, G., Houston, G. et al. (2012). Super-resolution methods in MRI: Can they improve the trade-off between resolution, signal-to-noise ratio, and acquisition time? Magnetic Resonance in Medicine, 68(6), 1983–1993. DOI 10.1002/mrm.24187. [Google Scholar] [CrossRef]
2. Shi, F., Cheng, J., Wang, L., Yap, P. T., Shen, D. (2015). LRTV: MR image super-resolution with low-rank and total variation regularizations. IEEE Transactions on Medical Imaging, 34(12), 2459–2466. DOI 10.1109/TMI.2015.2437894. [Google Scholar] [CrossRef]
3. Nguyen, N., Milanfar, P. (2000). A wavelet-based interpolation-restoration method for superresolution (wavelet superresolution). Circuits, Systems and Signal Processing, 19(4), 321–338. DOI 10.1007/BF01200891. [Google Scholar] [CrossRef]
4. Stark, H., Oskoui, P. (1989). High-resolution image recovery from image-plane arrays, using convex projections. Journal of the Optical Society of America, 6(11), 1715–1726. DOI 10.1364/JOSAA.6.001715. [Google Scholar] [CrossRef]
5. Irani, M., Peleg, S. (1990). Super resolution from image sequences. Proceedings 10th International Conference on Pattern Recognition, pp. 115–120. Atlantic City, NJ, USA. DOI 10.1109/ICPR.1990.119340. [Google Scholar] [CrossRef]
6. Irani, M., Peleg, S. (1991). Improving resolution by image registration. CVGIP: Graphical Models and Image Processing, 53(3), 231–239. DOI 10.1016/1049-9652(91)90045-L. [Google Scholar] [CrossRef]
7. Irani, M., Peleg, S. (1993). Motion analysis for image enhancement: Resolution, occlusion, and transparency. Journal of Visual Communication and Image Representation, 4(4), 324–335. DOI 10.1006/jvci.1993.1030. [Google Scholar] [CrossRef]
8. Ismail, I., Eltoukhy, M. M., Eltaweel, G. (2022). Super-resolution based on curvelet transform and sparse representation. Computer Systems Science and Engineering, 45(1), 167–181. DOI 10.32604/csse.2023.028906. [Google Scholar] [CrossRef]
9. Wang, Y. H., Qiao, J., Li, J. B., Fu, P., Chu, S. C. et al. (2014). Sparse representation-based MRI super-resolution reconstruction. Measurement, 47, 946–953. DOI 10.1016/j.measurement.2013.10.026. [Google Scholar] [CrossRef]
10. Sánchez, I., Vilaplana, V. (2018). Brain MRI super-resolution using 3D generative adversarial networks. DOI 10.48550/arXiv.1812.11440. [Google Scholar] [CrossRef]
11. Mardani, M., Gong, E., Cheng, J. Y., Vasanawala, S., Zaharchuk, G. et al. (2017). Deep generative adversarial networks for compressed sensing automates MRI. arXiv preprint arXiv:1706.00051. [Google Scholar]
12. Shi, J., Li, Z., Ying, S., Wang, C., Liu, Q. et al. (2018). MR image super-resolution via wide residual networks with fixed skip connection. IEEE Journal of Biomedical and Health Informatics, 23(3), 1129–1140. DOI 10.1109/JBHI.2018.2843819. [Google Scholar] [CrossRef]
13. Giannakidis, A., Oktay, A., Keegan, J., Spadotto, V., Voges, I. et al. (2017). Super-resolution reconstruction of late gadolinium cardiovascular magnetic resonance images using a residual convolutional neural network. Proceedings 25th Scientific Meeting of the International Society for Magnetic Resonance in Medicine, Honolulu, HI, USA. [Google Scholar]
14. Pham, C. H., Ducournau, A., Fablet, R., Rousseau., F. (2017). Brain MRI super-resolution using deep 3D convolutional networks. Proceedings IEEE 14th International Symposium on Biomedical Imaging (ISBI), pp. 197–200. Melbourne, VIC, Australia. [Google Scholar]
15. Tanno, R., Worrall, D. E., Ghosh, A., Kaden, E., Sotiropoulos, S. N. et al. (2017). Bayesian image quality transfer with CNNs: Exploring uncertainty in DMRI super-resolution. International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 611–619. Quebec City, Quebec, Canada. [Google Scholar]
16. McDonagh, S., Hou, B., Alansary, A., Oktay, O., Kamnitsas, K. et al. (2017). Context-sensitive super-resolution for fast fetal magnetic resonance imaging. In: Molecular imaging, reconstruction and analysis of moving body organs, and stroke imaging and treatment, pp. 116–126. Québec City, QC, Canada. [Google Scholar]
17. Shi, J., Liu, Q., Wang, C., Zhang, Q., Ying, S. et al. (2018). Super-resolution reconstruction of MR image with a novel residual learning network algorithm. Physics in Medicine & Biology, 63(8), 085011. DOI 10.1088/1361-6560/aab9e9. [Google Scholar] [CrossRef]
18. Oktay, O., Bai, W., Lee, M., Guerrero, R., Kamnitsas, K. et al. (2016). Multi-input cardiac image super-resolution using convolutional neural networks. Proceedings International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 246–254. Athens, Greece. [Google Scholar]
19. Dong, C., Loy, C. C., He, K., Tang., X. (2015). Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(2), 295–307. DOI 10.1109/TPAMI.2015.2439281. [Google Scholar] [CrossRef]
20. Kim, J., Lee, J. K., Lee., K. M. (2016). Accurate image super-resolution using very deep convolutional networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1646–1654. Las Vegas, NV, USA. [Google Scholar]
21. Simonyan, K., Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. [Google Scholar]
22. Dong, C., Loy, C. C., Tang, X. (2016). Accelerating the super-resolution convolutional neural network. European Conference on Computer Vision (ECCV), pp. 391–407. Amsterdam, The Netherlands. [Google Scholar]
23. Shi, W., Caballero, J., Huszár, F., Totz, J., Aitken, A. P. et al. (2016). Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1874–1883. Las Vegas, NV, USA. [Google Scholar]
24. Keys, R. (1981). Cubic convolution interpolation for digital image processing. IEEE Transactions on Acoustics, Speech, and Signal Processing, 29(6), 1153–1160. DOI 10.1109/TASSP.1981.1163711. [Google Scholar] [CrossRef]
25. Kim, J., Lee, J. K., Lee, K. M. (2016). Deeply-recursive convolutional network for image super-resolution. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1637–1645. Las Vegas, NV, USA. [Google Scholar]
26. Lai, W. S., Huang, J. B., Ahuja, N., Yang., M. H. (2017). Deep laplacian pyramid networks for fast and accurate super-resolution. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 624–632. Honolulu, HI, USA. [Google Scholar]
27. Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A. et al. (2017). Photo-realistic single image super-resolution using a generative adversarial network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4681–4690. Honolulu, HI, USA. [Google Scholar]
28. Ran, Q., Xu, X., Zhao, S., Li, W., Du, Q. (2020). Remote sensing images super-resolution with deep convolution networks. Multimedia Tools and Applications, 79(13–14), 8985–9001. DOI 10.1007/s11042-018-7091-1. [Google Scholar] [CrossRef]
29. Zhang, H., Yang, Z., Zhang, L., Shen, H. (2014). Super-resolution reconstruction for multi-angle remote sensing images considering resolution differences. Remote Sensing, 6(1), 637–657. DOI 10.3390/rs6010637. [Google Scholar] [CrossRef]
30. Sajjadi, M. S., Scholkopf, B., Hirsch, M. (2017). Enhancenet: Single image super-resolution through automated texture synthesis. Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 4491–4500. Venice, Italy. [Google Scholar]
31. Yu, X., Fernando, B., Ghanem, B., Porikli, F., Hartley, R. (2018). Face super-resolution guided by facial component heatmaps. Proceedings of the European Conference on Computer Vision (ECCV), pp. 217–233. Munich, Germany. [Google Scholar]
32. Tappen, M. F., Liu, C. (2012). A Bayesian approach to alignment-based image hallucination. European Conference on Computer Vision (ECCV), pp. 236–249. Springer, Berlin, Heidelberg. [Google Scholar]
33. Huang, Y., Shao, L., Frangi, A. F. (2017). Simultaneous super-resolution and cross-modality synthesis Of 3D medical images using weakly-supervised joint convolutional sparse coding. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6070–6079. Honolulu, HI, USA. [Google Scholar]
34. Isaac, J. S., Kulkarni, R. (2015). Super resolution techniques for medical image processing. Proceedings 2015 International Conference on Technologies for Sustainable Development (ICTSD), pp. 1–6. Mumbai, India. DOI 10.1109/ICTSD.2015.7095900. [Google Scholar] [CrossRef]
35. He, K., Zhang, X., Ren, S., Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778. Las Vegas, NV, USA. [Google Scholar]
36. Lim, B., Son, S., Kim, H., Nah, S., Lee, K. M. (2017). Enhanced deep residual networks for single image super-resolution. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR), pp. 136–144. Honolulu, HI, USA. DOI 10.48550/arXiv.1707.02921. [Google Scholar] [CrossRef]
37. Xu, J., Gong, E., Pauly, J., Zaharchuk, G. (2017). 200× low-dose PET reconstruction using deep learning. arXiv preprint arXiv:1712.04119. [Google Scholar]
38. Xiang, L., Qiao, Y., Nie, D., An, L., Lin, W. et al. (2017). Deep auto-context convolutional neural networks for standard-dose PET image estimation from low-dose PET/MRI. Neurocomputing, 267(1), 406–416. DOI 10.1016/j.neucom.2017.06.048. [Google Scholar] [CrossRef]
39. Wang, Y., Zhang, P., An, L., Ma, G., Kang, J. et al. (2016). Predicting standard-dose PET image from low-dose PET and multimodal MR images using mapping-based sparse representation. Physics in Medicine & Biology, 61(1), 791–812. DOI 10.1088/0031-9155/61/2/791. [Google Scholar] [CrossRef]
40. Kang, J., Gao, Y., Shi, F., Lalush, D. S., Lin, W. et al. (2015). Prediction of standard-dose brain PET image by using MRI and low-dose brain [18F] FDG PET images. Medical Physics, 42(9), 5301–5309. DOI 10.1118/1.4928400. [Google Scholar] [CrossRef]
41. Song, T. A., Chowdhury, S. R., Yang, F., Dutta, J. (2020). Super-resolution PET imaging using convolutional neural networks. IEEE Transactions on Computational Imaging, 6, 518–528. DOI 10.1109/TCI.2020.2964229. [Google Scholar] [CrossRef]
42. Hong, X., Zan, Y., Weng, F., Tao, W., Peng, Q. et al. (2018). Enhancing the image quality via transferred deep residual learning of coarse PET sinograms. IEEE Transactions on Medical Imaging, 37(10), 2322–2332. DOI 10.1109/TMI.2018.2830381. [Google Scholar] [CrossRef]
43. Malczewski, K. (2020). Super-resolution with compressively sensed MR/PET signals at its input. Informatics in Medicine Unlocked, 18(S1), 100302. DOI 10.1016/j.imu.2020.100302. [Google Scholar] [CrossRef]
44. Chatterjee, S., Breitkopf, M., Sarasaen, C., Rose, G., Nürnberger, A. et al. (2019). A deep learning approach for reconstruction of under sampled cartesian and radial data. ESMRMB, Rotterdam, The Netherlands. [Google Scholar]
45. Hammernik, K., Klatzer, T., Kobler, E., Recht, M. P., Sodickson, D. K. et al. (2018). Learning a variational network for reconstruction of accelerated MRI data. Magnetic Resonance in Medicine, 79(6), 3055–3071. DOI 10.1002/mrm.26977. [Google Scholar] [CrossRef]
46. Hyun, C. M., Kim, H. P., Lee, S. M., Lee, S., Seo, J. K. (2018). Deep learning for under sampled MRI reconstruction. Physics in Medicine & Biology, 63(13), 135007. DOI 10.1088/1361-6560/aac71a. [Google Scholar] [CrossRef]
47. Wang, S., Su, Z., Ying, L., Peng, X., Zhu, S. et al. (2016). Accelerating magnetic resonance imaging via deep learning. Proceedings 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), pp. 514–517. Prague, Czech Republic. DOI 10.1109/ISBI.2016.7493320. [Google Scholar] [CrossRef]
48. Muhammad, W., Bhutto, Z., Shah, S. A. R., Shah, J., Shaikh, M. H. et al. (2022). Deep transfer learning CNN based approach for COVID-19 detection. International Journal of Advanced and Applied Sciences, 9(4), 44–52. DOI 10.21833/ijaas.2022.04.006. [Google Scholar] [CrossRef]
49. El-Shafai, W., Mohamed, E., Zeghid, M., Magdy, A., Aly, M. (2022). Hybrid single image super-resolution algorithm for medical images. Computers, Materials & Continua, 72(3), 4879–4896. DOI 10.32604/cmc.2022.028364. [Google Scholar] [CrossRef]
50. Liang, M., Du, J., Li, L., Xue, Z., Kou, F. et al. (2022). Video super-resolution reconstruction based on deep learning and spatio-temporal feature self-similarity. IEEE Transactions on Knowledge and Data Engineering, 34(9), 4538–4553. DOI 10.1109/TKDE.2020.3034261. [Google Scholar] [CrossRef]
51. Lyu, Q., Shan, H., Xie, Y., Kwan, A. C., Otaki, Y. et al. (2021). Cine cardiac MRI motion artifact reduction using a recurrent neural network. IEEE Transactions on Medical Imaging, 40(8), 2170–2181. DOI 10.1109/TMI.2021.3073381. [Google Scholar] [CrossRef]
52. Qin, C., Schlemper, J., Caballero, J., Price, A. N., Hajnal, J. V. et al. (2018). Convolutional recurrent neural networks for dynamic MR image reconstruction. IEEE Transactions on Medical Imaging, 38(1), 280–290. DOI 10.1109/TMI.2018.2863670. [Google Scholar] [CrossRef]
53. Han, Y., Ye, J. C. (2018). Framing U-Net via deep convolutional framelets: Application to sparse-view CT. IEEE Transactions on Medical Imaging, 37(6), 1418–1429. DOI 10.1109/TMI.2018.2823768. [Google Scholar] [CrossRef]
54. Qiu, D., Cheng, Y., Wang, X., Zhang, X. (2021). Multi-window back-projection residual networks for reconstructing COVID-19 CT super-resolution images. Computer Methods and Programs in Biomedicine, 200(8), 105934. DOI 10.1016/j.cmpb.2021.105934. [Google Scholar] [CrossRef]
55. Qiu, D., Zheng, L., Zhu, J., Huang, D. (2021). Multiple improved residual networks for medical image super-resolution. Future Generation Computer Systems, 116(1), 200–208. DOI 10.1016/j.future.2020.11.001. [Google Scholar] [CrossRef]
56. Ma, Y., Liu, K., Xiong, H., Fang, P., Li, X. et al. (2021). Medical image super-resolution using a relativistic average generative adversarial network. Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, 992(11), 165053. DOI 10.1016/j.nima.2021.165053. [Google Scholar] [CrossRef]
57. Feng, C. M., Yan, Y., Chen, G., Fu, H., Xu, Y. et al. (2022). Accelerated multi-modal MR imaging with transformers. DOI 10.48550/arXiv.2106.14248. [Google Scholar] [CrossRef]
58. Feng, C. M., Fu, H., Yuan, S., Xu, Y. (2021). Multi-contrast MRI super-resolution via a multi-stage integration network. Proceedings International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 140–149. Strasbourg, France. DOI 10.1007/978-3-030-87231-1_14. [Google Scholar] [CrossRef]
59. Feng, C. M., Yan, Y., Liu, C., Fu, H., Xu, Y. et al. (2021). Exploring separable attention for multi-contrast MR image super-resolution. DOI 10.48550/arXiv.2109.01664. [Google Scholar] [CrossRef]
60. Chen, L., Yang, X., Jeon, G., Anisetti, M., Liu, K. (2020). A trusted medical image super-resolution method based on feedback adaptive weighted dense network. Artificial Intelligence in Medicine, 106(2), 101857. DOI 10.1016/j.artmed.2020.101857. [Google Scholar] [CrossRef]
61. Wang, Y., Wang, L., Wang, H., Li, P. (2019). End-to-end image super-resolution via deep and shallow convolutional networks. IEEE Access, 7, 31959–31970. DOI 10.1109/ACCESS.2019.2903582. [Google Scholar] [CrossRef]
62. Nair, V., Hinton, G. E. (2010). Rectified linear units improve restricted boltzmann machines. Proceedings of the 27th International Conference on International Conference on Machine Learning, pp. 807–814. Haifa, Israel. [Google Scholar]
63. He, K., Zhang, X., Ren, S., Sun, J. (2015). Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. Proceedings of the IEEE International Conference on Computer Vision (ICCV), vol. 2015, pp. 1026–1034. Santiago, Chile. [Google Scholar]
64. Zhang, Y., Sun, L., Yan, C., Ji, X., Dai, Q. (2018). Adaptive residual networks for high-quality image restoration. IEEE Transactions on Image Processing, 27(7), 3150–3163. DOI 10.1109/TIP.2018.2812081. [Google Scholar] [CrossRef]
65. Nah, S., Kim, T. H., Lee, K. M. (2017). Deep multi-scale convolutional neural network for dynamic scene deblurring. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3883–3891. Honolulu, HI, USA. [Google Scholar]
66. Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z. (2016). Rethinking the inception architecture for computer vision. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2818–2826. Las Vegas, NV, USA. [Google Scholar]
67. Muhammad, W., Bhutto, Z., Ansari, A., Memon, M. L., Kumar, R. et al. (2021). Multi-path deep CNN with residual inception network for single image super-resolution. Electronics, 10(16), 1979. DOI 10.3390/electronics10161979. [Google Scholar] [CrossRef]
68. Muhammad, W., Bhutto, Z., Shah, J., Shaikh, M. H., Shah, S. A. R. et al. (2022). RIMS: Residual-inception multiscale image super-resolution network. International Journal of Computer Science and Network Security, 22(1), 588–592. DOI 10.22937/IJCSNS.2022.22.1.77. [Google Scholar] [CrossRef]
69. Muhammad, W., Hussain, A., Shah, S. A. R., Shah, J., Bhutto, Z. et al. (2021). SDCN: Synchronized depthwise separable convolutional neural network for single image super-resolution. International Journal of Computer Science and Network Security, 21(11), 17–22. DOI 10.22937/IJCSNS.2021.21.11.3. [Google Scholar] [CrossRef]
70. Zeiler, M. D., Fergus, R. (2014). Visualizing and understanding convolutional networks. European Conference on Computer Vision (ECCV), pp. 818–833. Zurich, Switzerland. DOI 10.1007/978-3-319-10590-1_53. [Google Scholar] [CrossRef]
71. Long, J., Shelhamer, E., Darrell, T. (2015). Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3431–3440. Boston, MA, USA. [Google Scholar]
72. https://wiki.idoimaging.com/. [Google Scholar]
73. Qiu, D., Zhang, S., Zheng, L., Liu, Y., Zhu, J. (2020). Super-resolution reconstruction method of knee MRI based on deep learning. Computer Methods and Programs in Biomedicine, 187(12), 105059. DOI 10.1016/j.cmpb.2019.105059. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools