
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Non-Cooperative Behavior Management in Large-Scale Group Decision-Making Considering the Altruistic Behaviors of Experts and Its Application in Emergency Alternative Selection
Business School, Sichuan University, Chengdu, 610064, China
* Corresponding Author: Mingjun Jiang. Email:
(This article belongs to the Special Issue: Linguistic Approaches for Multiple Criteria Decision Making and Applications)
Computer Modeling in Engineering & Sciences 2023, 136(1), 487-515. https://doi.org/10.32604/cmes.2023.024014
Received 20 May 2022; Accepted 29 August 2022; Issue published 05 January 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Emergency decision-making problems usually involve many experts with different professional backgrounds and concerns, leading to non-cooperative behaviors during the consensus-reaching process. Many studies on non-cooperative behavior management assumed that the maximum degree of cooperation of experts is to totally accept the revisions suggested by the moderator, which restricted individuals with altruistic behaviors to make more contributions in the agreement-reaching process. In addition, when grouping a large group into subgroups by clustering methods, existing studies were based on the similarity of evaluation values or trust relationships among experts separately but did not consider them simultaneously. In this study, we introduce a clustering method considering the similarity of evaluation values and the trust relations of experts and then develop a consensus model taking into account the altruistic behaviors of experts. First, we cluster experts into subgroups by a constrained K-means clustering algorithm according to the opinion similarity and trust relationship of experts. Then, we calculate the weights of experts and clusters based on the centrality degrees of experts. Next, to enhance the quality of consensus reaching, we identify three kinds of non-cooperative behaviors and propose corresponding feedback mechanisms relying on the altruistic behaviors of experts. A numerical example is given to show the effectiveness and practicality of the proposed method in emergency decision-making. The study finds that integrating altruistic behavior analysis in group decision-making can safeguard the interests of experts and ensure the integrity of decision-making information.Keywords
Over the past decades, emergencies have frequently occurred in China, causing irreversible damage. For example, the massive explosion in Tianjin, China, resulted in the death of 154 people1 ; the liquefied gas tanker explosion in Jinyu Petrochemical, resulted in the death of 10 people2. When such an emergency occurs, a high-quality emergency decision-making process can effectively reduce potentially adverse impacts [1]. Usually, emergency decision-making problems have three typical characteristics: time limitation, incomplete information, and decision pressure resulting from potentially serious effects [2,3]. Thus, solving emergency decision-making problems efficiently is definitely a great challenge for both the government and society. Because of the complexity and uncertainty of emergency events, it is necessary to invite experts from different fields and specialties to evaluate alternatives. When the number of experts exceeds 11, it can be regarded as a large-scale group decision-making (LSGDM) problem [4].
Compared with conventional group decision-making problems, LSGDM problems are more complicated, facing many challenges not only in the scale of experts but also in experts’ relationships [5]. To cope with the scale of an LSGDM problem, the dimensionality reduction which divides a large-scale expert team into several subgroups is deemed essential. Clustering analysis is known as one of the most useful dimensionality reduction methods. In this regard, traditional clustering algorithms such as the K-means clustering algorithm [6], fuzzy equivalence relation (FER) [7] and grey clustering [8] have been widely used. However, these methods cluster experts into subgroups based on the opinion similarity of experts but fail to consider the relationships among experts. With the advancement of technology and society, people can communicate and transmit information conveniently, and experts involved in decision-making problems are no more independent individuals. Social network analysis (SNA) has become a common technique for LSGDM problems. To this point, Tian et al. [9] extended the community detection method proposed by Newman et al. [10] to divide large-scale experts in a social network into different communities. Using the trust values between experts, Xu et al. [4] applied the Louvain method [11] based on the idea of modularity to classify experts into different communities in a social network. The above SNA models clustered experts according to the relationships between experts. However, the similarity of evaluation values of alternatives and the trust values between experts both play important roles in grouping experts. Du et al. [12] proposed a trust-similarity analysis (TSA)-based clustering method to manage the clustering operation in LSGDM events. Yu et al. [13] developed a trust-constrained K-means clustering algorithm in a social network large-scale decision-making model. However, in their studies, they only considered a single constraint to overcome the defect of grouping low-trust experts into the same cluster caused by traditional clustering algorithms based on preference similarity, but failed to overcome other problems, for example, high-trust experts may be assigned to different clusters. In this sense, this paper proposes a pairwise trust constrained K-means (PTC-Kmeans) clustering algorithm to cluster experts which considers the similarity of evaluation information of alternatives and the trust values between experts, simultaneously.
Besides, due to different backgrounds and interests, experts in a group may show non-cooperative behaviors in the decision-making process. How to effectively manage the non-cooperative behaviors of experts is another challenge in LSGDM problems [5]. To date, many studies [14–18] have considered the non-cooperative behaviors of experts based on the implicit assumption that the full degree of cooperation of experts is to totally accept the revisions proposed by the moderator. However, in actual situations, due to deep trust or close relationships, some individuals may incorporate the well-being of others into their own decision even at their own expense. This behavior is named altruistic behavior [19]. If an expert has a high degree of trust in another person, he/she may contribute more than a recommendation to protect that person’s interest. In other words, the existence of altruistic behavior may make up for the loss caused by the non-cooperative behaviors of experts [20]. Existing literature on non-cooperative behavior management assumes that no one would make more change than the suggested value, which essentially restricts experts with altruistic behaviors from making more contributions to the group consensus. Tang et al. [20] proposed a multi-attribute group decision-making (MAGDM) model which utilized the altruistic behaviors of experts to compensate for the adverse effects caused by the non-cooperative behaviors of other experts. However, they only focused on one type of non-cooperative behaviors in their model and did not take the whole problem into account, leading to a lack of integrity. How to incorporate altruistic behavior analysis into the process of consensus reaching and compensate for different types of non-cooperative behaviors are challenges for LSGDM.
Bear all the above analysis in mind, this paper introduces a clustering method considering the similarity of attribute values and the trust relations of experts and then develops a consensus model taking into account the altruistic behaviors of experts. A PTC-Kmeans clustering algorithm is presented to cluster experts into subgroups. After reducing the group size to small communities, we then identify three types of non-cooperative behaviors of experts: 1) experts refuse to adjust their preferences or adjust them slightly, or even change their preferences in an opposite direction; 2) hesitant experts randomly provide their preferences to avoid revealing their true intentions; 3) expert deliberately decrease/increase the evaluation value of alternatives. We propose three kinds of feedback mechanisms with respect to three types of non-cooperative behaviors, which allow experts to have altruistic behaviors to compensate for the loss caused by non-cooperative behaviors. The main contributions can be summarized as follows:
(1) This study proposes a PTC-Kmeans clustering algorithm to cluster experts, which considers the similarity of evaluation information given by experts and the trust values between experts, simultaneously.
(2) This study fully considers three kinds of non-cooperative behaviors of experts and distinguishes non-cooperative behaviors based on the differences between expert preferences and cluster preferences.
(3) This paper proposes three kinds of feedback mechanisms with respect to the non-cooperative behaviors of experts, which allows experts to have altruistic behaviors to compensate for the loss caused by non-cooperative behaviors and applies weight penalty mechanisms to decrease the weights of experts with non-cooperative behaviors and increases the consensus level.
The rest of this paper is organized as follows: Section 2 performs a literature review about emergency decision-making and LSGDM methods. In Section 3, we introduce the PTC-Kmeans clustering algorithm to classify a large group of experts into subgroups. Section 4 discusses the management of non-cooperative and altruistic behaviors. We utilize an application example to illustrate the usefulness of the proposed model in Section 5. Concluding remarks are given in Section 6. To better understand this study, the mathematical symbols used in this study are presented in Table S1 in Appendix.
In this part, we present the literature review of LSGDM problems. In Section 2.1, we give a snapshot of emergency LSGDM problems. In Section 2.2, we present a short review of clustering algorithms. The review of the advance of SNA for LSGDM is shown in Section 2.3.
2.1 A Snapshot of Emergency LSGDM Problems
When emergencies occur, we often need to make effective decisions in a short period of time. Because of the complexity of emergency problems, time limitations and potential risks, it is difficult for a single expert to solve the emerging problems. Related studies have shown that in emergency decision-making, the decision made by concentrating the wisdom of a group is more reliable than that made by an individual [21,22]. Thus, it is necessary to assemble experts with different backgrounds, experiences and knowledge to make a decision with a high level of consensus. Li et al. [23] proposed an LSGDM model, which adopted fuzzy cluster analysis to integrate heterogeneous information of experts to select the best rescue plan in an emergency situation. Cao et al. [21] proposed a novel opinion formation model that considered psychological factors and relevant opinions in the emergency decision-making process. Liu et al. [24] proposed a method for GDM that introduced an expected multiplicative consistency of incomplete probabilistic linguistic preference relations to avoid the loss of evaluation information of experts and applied the method to address a forest fire rescue problem. Xu et al. [4] proposed a consensus model that considered trust relations and preference risks to manage non-cooperative behaviors in large-group emergency decision-making.
From the above analysis, we can see that current studies have considered different ways to deal with emergency decision-making problems, but seldom considered the non-cooperative behaviors of experts in emergency decision-making problems, and the existing models, which are used to manage non-cooperative behaviors of experts, do not consider the altruistic behaviors of experts. In this study, we shall introduce the altruistic behavior to compensate for the loss caused by the non-cooperative behaviors of experts.
2.2 A Short Review on Clustering Algorithms to Reduce the Dimension of a Large-Scale Group
Clustering analysis has been commonly used to reduce the dimension of many experts in LSGDM problems. A clustering process can divide a large group of experts into several subgroups so that the data in the same cluster is more similar than that from other clusters [25].
As an unsupervised machine learning algorithm, the K-means clustering algorithm is one of the most widely used clustering algorithms. It works by classifying all data objects into k clusters based on k initial clustering centroids and then iteratively refining them. Wu et al. [26] adopted the K-means clustering algorithm to classify experts with fuzzy preference relations based on the Euclidean distance. Liu et al. [27] introduced the probability K-means clustering algorithm to overcome the weakness that the K-means clustering algorithm is sensitive to the initially selected centroid points, and detected sub-groups from the preferences of all experts. In the heterogeneous LSGDM environment, Tang et al. [28] proposed the ordinal K-means clustering algorithm to classify experts into several subgroups. From the above studies, we can see that the traditional K-means clustering algorithm classifies experts mainly based on the similarity among data objects, but ignores the background knowledge from real decision scenarios.
Some experiments have proved that the prior knowledge of objects is helpful for obtaining good clustering results [29]. In this regard, Wagstaff et al. [30] proposed a semi-supervised clustering algorithm, the constrained K-means clustering algorithm, which can integrate the background knowledge into the framework of the K-means clustering algorithm. Compared with the traditional K-means clustering algorithm, the constrained K-means clustering algorithm considers two types of constraints, namely, must-link constraints and cannot-link constraints. The must-link constraints specify that two instances must be assigned into the same cluster while the cannot-link constraints indicate that two instances must be in different clusters. Considering the importance of the similarity of experts’ evaluation information and the trust values among experts in a clustering process, in this study, we propose the PTC-Kmeans clustering algorithm to cluster the experts into subgroups, which utilizes the trust relations of experts to form must-link and cannot-link constraints.
With the advancement of technology and information, GDM is often conducted within the context of a social network, in which individuals have trust relationships with each other. A social network is composed of a set of nodes and a set of edges, where the nodes represent experts in society and the edges represent the trust relationships among experts. In this study, the nodes are set as
In real LSGDM problems, it is probable that some experts are unable to accurately provide the trust values for other experts. Thus, some studies [31] classify the trust relationships into three types in SNA: direct, indirect and irrelevant trust. The types of trust relationships are shown in Fig. 1. In this figure, ‘direct trust’ means expert
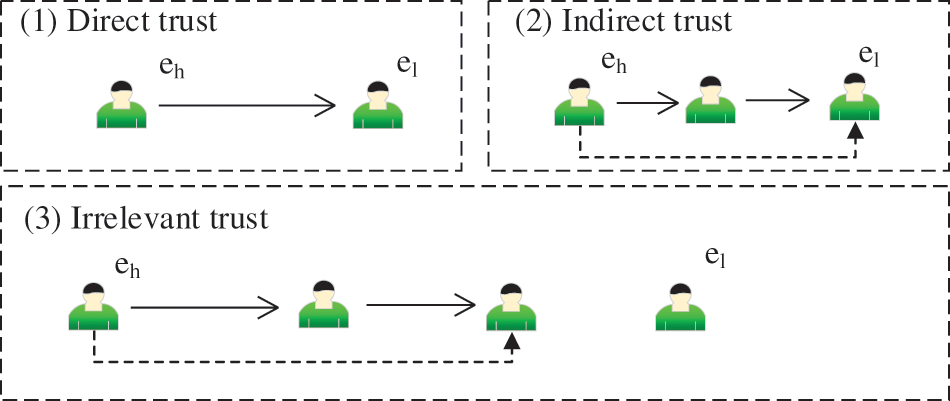
Figure 1: The types of relationship
As a new type of decision-making problem, group decision-making with SNA integrates the trust relations of experts in the process of clustering, consensus reaching and alternative selection [12]. Due to the increasing number of experts in LSGDM, it is difficult to adjust the inconsistent elements and reach a consensus. Experts who come from different fields and represent different interests are likely to display non-cooperative behaviors. The existence of non-cooperative behaviors of experts greatly affects the efficiency of decision-making. Thus, some studies proposed methods to manage non-cooperative behaviors of experts based on the social network. Zhang et al. [18] defined three types of non-cooperative behaviors: 1) dishonest behavior; 2) disobedient behavior; 3) divergent behavior, and proposed an SNA-based consensus framework to manage non-cooperative behaviors. Gao et al. [33] developed a consensus reaching algorithm with non-cooperative behavior management for personalized individual semantics-based social network GDM problem. Li et al. [34] introduced a novel framework based on the WeChat-like interaction social network to manage non-cooperative behaviors of experts. Xu et al. [4] proposed a consensus model based on interval-valued intuitionistic fuzzy numbers, which considered the trust relations of experts in a social network and the preference risks of experts to manage non-cooperative behaviors of experts.
From the above analysis we can see that: 1) the trust relationships of experts in a social network are usually used in the clustering process to cluster experts but seldom used in the CRP, 2) few studies refine the non-cooperative behaviors into different types, 3) most studies analyze non-cooperative behaviors of experts based on the assumption that the greatest degree of cooperation of experts is to totally accept the revisions proposed by the moderator. In this study, to improve the consensus level, we introduce the altruistic behaviors which allow experts to make more contributions than the recommendation proposed by the moderator to compensate for the loss caused by the experts’ different types of non-cooperative behaviors. What’s more, the trust relationship of experts in a social network serves as a condition to judge whether the experts have altruistic behaviors in the CRP.
3 Grouping Experts by a Semi-Supervised Clustering Processing
To solve an LSGDM problem, it is vital to divide the large group of experts into small communities, so as to simplify the decision process. As justified in the introduction, it is essential to consider the similarity of evaluation information of alternatives given by different experts and the trust values between experts simultaneously when grouping experts. Thus, motivated by the constrained K-means clustering algorithm [3], we introduce the PTC-Kmeans clustering algorithm to cluster experts in Section 3.1. Then, the method to determine the weights of experts and clusters is presented in Section 3.2.
3.1 Expert Clustering by the PTC-Kmeans Clustering Algorithm
In typical LSGDM problems, the degree of consistency of experts’ preferences is usually regarded as a clustering criterion [35,36]. Such a type of clustering method performs clustering based on group opinions but ignores the trust relationships between experts. In this study, we extend the trust-constrained K-means clustering algorithm [13] and utilize the trust values of experts as constraints to cluster experts. Assume that a set of experts,
The PTC-Kmeans clustering algorithm is mainly a constraint-based K-means clustering algorithm. So, we firstly consider two types of constraints, namely must-link constraint and cannot-link constraint.
In this study, we set constraints based on the trust relationship between experts. Because the trust value provided by an expert is directional, which means the trust value between two experts may be unequal. In other words, expert
Let
where
To simplify, we denote the aggregated social-matrix as
The trust constraints formulate that a pair of experts with a low average trust value cannot be allocated in the same cluster and a pair of experts with a high average trust value must be allocated in the same cluster.
Let the threshold of trust constraints be
Let
If
Let
If
3.1.2 The PTC-Kmeans Clustering Algorithm
Once the constraints are defined, experts can be clustered into subgroups according to the similarity degrees of experts’ evaluation information based on the constraints.
Definition 1 [13]: Measure the similarity degree of evaluation information between expert
where
Determine the value of k according to the management experience. Denote the clustering centroid of each cluster as
where
The main steps of the PTC-Kmeans clustering algorithm are presented in Algorithm 1.

3.2 Weight Determination of Experts and Clusters
After the large-scale experts are divided into several clusters, the weights of experts and clusters should be determined. Centrality is an essential indicator to judge the influence, status and importance of an expert in a social network. We gain the weights of experts using the concept of centrality. The degree of centrality of
The weight
Clearly,
The weight of a cluster is calculated based on the sum of the weights of the experts in the cluster. The weight
4 Feedback Mechanism Based on Non-Cooperative and Altruistic Behaviors
Section 4.1 presents the process of measuring the consensus degree of clusters and the whole group. In Section 4.2, we discuss the methods to identify three types of non-cooperative behaviors of experts, and altruistic behavior is introduced to reduce the degree of uncooperativeness of experts in Section 4.3. Then, a feedback mechanism is shown in Section 4.4. A punishment mechanism is used to decrease the influence of non-cooperative behaviors of experts in Section 4.5. Finally, we present the algorithm of the proposed LSGDM model in Section 4.6.
Let
where
Similarly, let
The distance between
Then, the degree of consensus of the expert
The degree of consensus of the cluster
The degree of consensus of the whole group
A threshold
4.2 Non-Cooperative Behaviors Identification
4.2.1 Non-Cooperative Behavior Caused by Expert Who Refuse to Follow the Revision Proposals
In the CRP, in order to achieve the ideal consensus level among experts, experts need to modify their individual preferences based on the suggestions received. However, some experts may refuse to adjust their preference information or adjust them slightly, or even change their preference information in the opposite direction. In this study, this type of behavior can be defined as the first kind of non-cooperative behavior (NCB-I).
Let
where
where
The non-cooperative index
Clearly,
(1)
(2)
(3)
(4)
Let
4.2.2 Non-Cooperative Behavior Caused by Experts Deliberately Concealing Their True Intentions
In the CRP, some hesitant experts may randomly provide their preferences to avoid revealing their true intentions, which can make experts’ adjusted opinions further away from the opinion of the subgroup. In this study, this type of behavior can be defined as the second kind of non-cooperative behavior (NCB-II).
Let
The non-cooperative index
Clearly,
(1)
(2)
In this study, if
4.2.3 Non-Cooperative Behavior Caused by Experts Who Deliberately Lower the Ranking of the Optimal Alternative Obtained in the Whole Group
In the CRP, some experts may be purposed to decrease the evaluation value of the most preferred collective alternative in the whole group and lead to a drop in the ranking of the optimal alternative in the whole group. In this study, this type of behavior can be defined as the third kind of non-cooperative behavior (NCB-III).
Let
Clearly,
4.3 Altruistic Behavior Analysis
Because of some intimate relationships, some individuals may consider the well-being of others in the decision-making process even at their own expense [20]. In this study, we allow the expert to have altruistic behavior, which means he/she can contribute more than the recommended modification provided by the moderator. Because the consensus level of the cluster is obtained by aggregating the consensus levels of all the experts in the cluster, the altruistic behaviors of some experts can compensate for the loss caused by others’ non-cooperative behaviors in the same cluster. In other words, altruistic behavior can reduce the adverse effect of the non-cooperative behaviors of experts on decision-making results.
Suppose that expert
If
4.5 The Punishment Mechanism for Non-Cooperative Behaviors
If no expert in cluster
Let
And let
Suppose that the experts in the cluster
The altruistic index is defined as:
We determine the coefficient of the weight penalty based on the non-cooperative index and the altruistic index, with a step size of 0.2. Because
(1) if the expert
(2) if the expert
(3) if the expert
If expert
where
4.6 Algorithm of the Proposed LSGDM Model
For better understanding, we provide the detailed steps of the proposed model as Algorithm 2. Fig. 2 shows the flow chart of the proposed method.

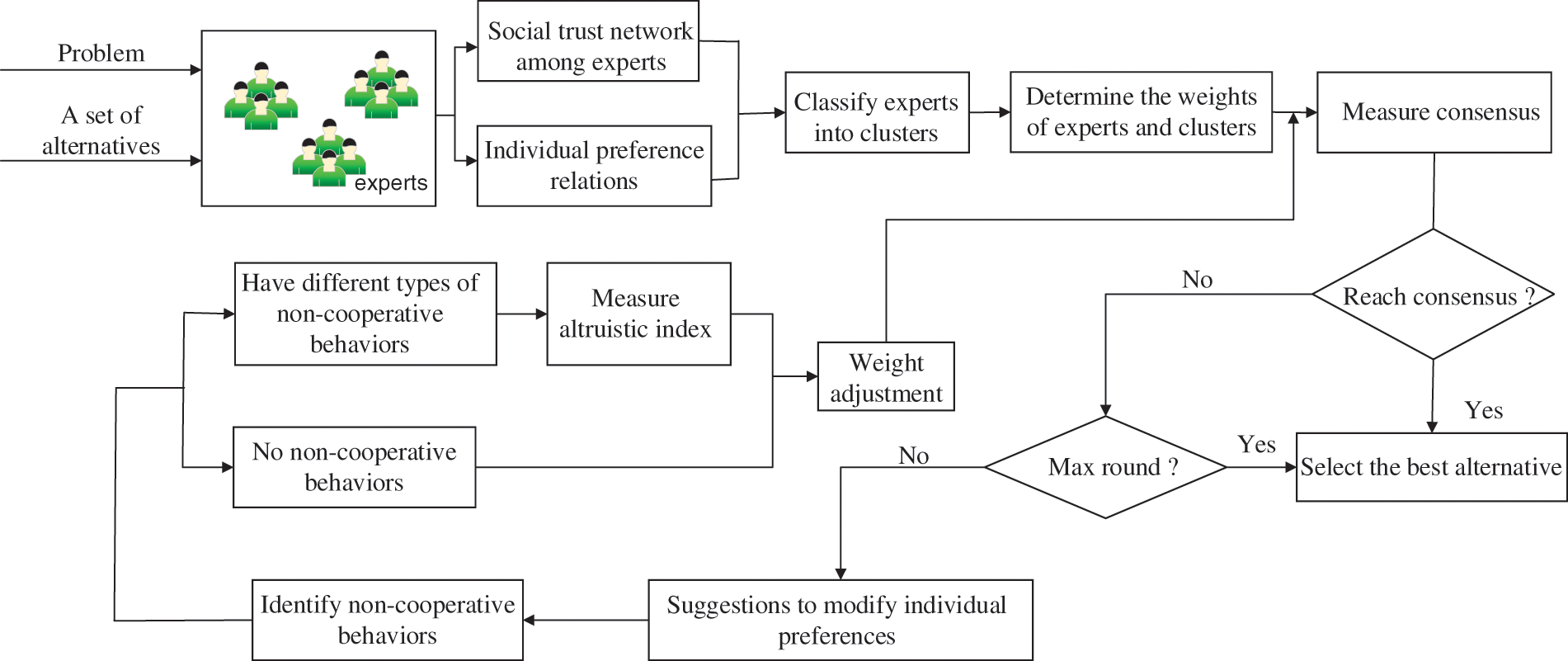
Figure 2: The flow chart of the proposed model
5 Case Study: Emergency Alternative Selection after the Flood
In this section, to demonstrate the usefulness of the proposed model, we apply the model into a case study regarding the selection of emergency alternative after the flood in Henan, China in 2021.
From July 16 to July 2021, heavy rainfall affected 287,713 people in 140 towns and villages in 31 counties and districts in Henan, China. It caused directed economic losses of RMB 104.6047 million, resulted in 302 deaths and 50 missing3. In order to reduce the damage caused by the disaster, Henan Province Flood Control and Drought Relief Headquarters reacted quickly, made saving people a priority, and initiated the second-level response of flood control emergency plan. More than 28,000 rescue teams in Henan Province, 19 city-level commando teams for fire-fighting and flood rescue, 157 station-level attack teams which has a total of 3790 firefighters and 366 rescue boats assembled in advance, and strived to rush to the scene as soon as the disaster occurred4. An emergency headquarters composed of 15 experts was established. After analysis, three alternatives were initially identified:
Step 1: Obtain the experts’ evaluation information, trust relationship and establish a complete social network.
The initial FPRs of the 15 experts are shown as follows:
The direct and indirect trust relationships of experts are presented in Fig. 3.
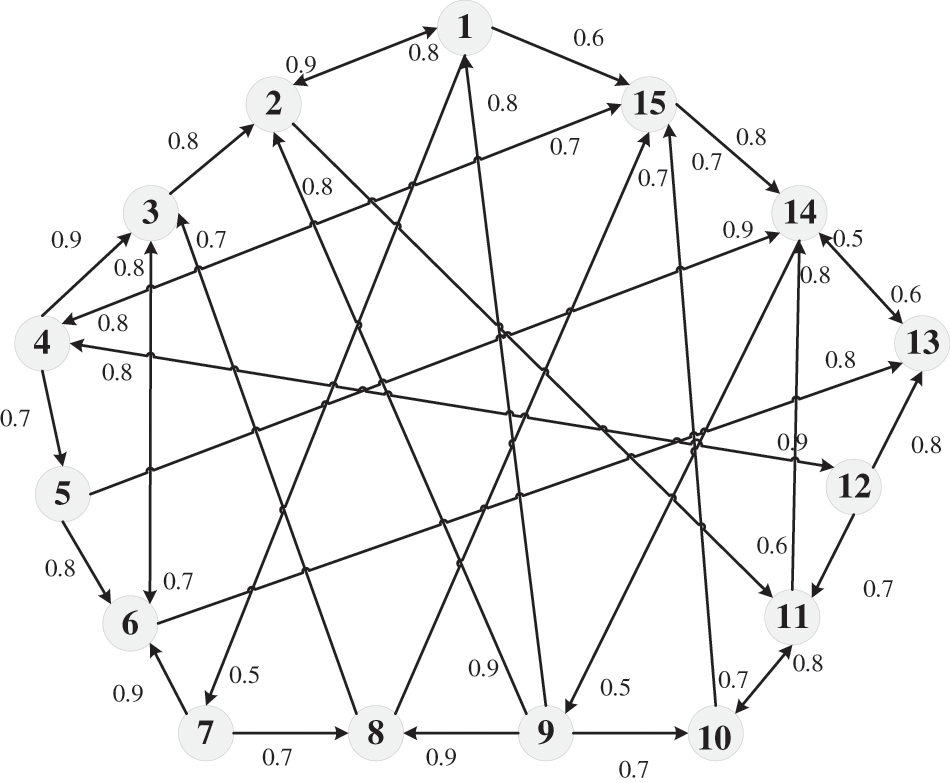
Figure 3: The social network of 15 experts
According to Eqs. (1)–(6) in the article by Liao et al. [32], we can struct a complete social network. The social-matrix among 15 experts is:
Step 2: Classify the large group of experts into subgroups.
According to Eq. (1), we calculated the aggregated social-matrix
The PTC-Kmeans algorithm is used to cluster the experts. In this case, we assign the cannot-link constraint threshold
Step 3: Calculate the weights of experts and clusters.
According to Eq. (7), we can obtain the weights of experts and the results are shown in Table 1.

According to Eq. (8), we can obtain the weights of the clusters:
According to Eq. (9), we can obtain the FPRs of clusters:
According to Eq. (10), we can obtain the FPR of the whole group:
Step 4: Consensus measurement. Eq. (13) are used to compute the degree of consensus of each cluster. The initial consensus levels are shown in Table 2. We set the clusters’ consensus threshold as

From Table 2, we can see that the consensus levels of cluster
Step 5: Apply the feedback mechanism.
The first consensus round
Since the consensus levels of experts

Let the parameter

It can be seen from Table 4 that
After investigation by the moderator, expert
According to Eq. (25), the altruistic index of experts
The consensus levels of clusters are:
The second consensus round
From the first consensus round, we know that the consensus level of cluster
The adjusted FPRs of experts
The actual adjusted FPRs of experts
Then, the non-cooperative indexes are calculated. The non-cooperative indexes of the experts with non-cooperative behaviors are calculated according to Eqs. (15)–(21). The results are shown in Table 5.

Due to
The consensus levels of clusters are calculated as:
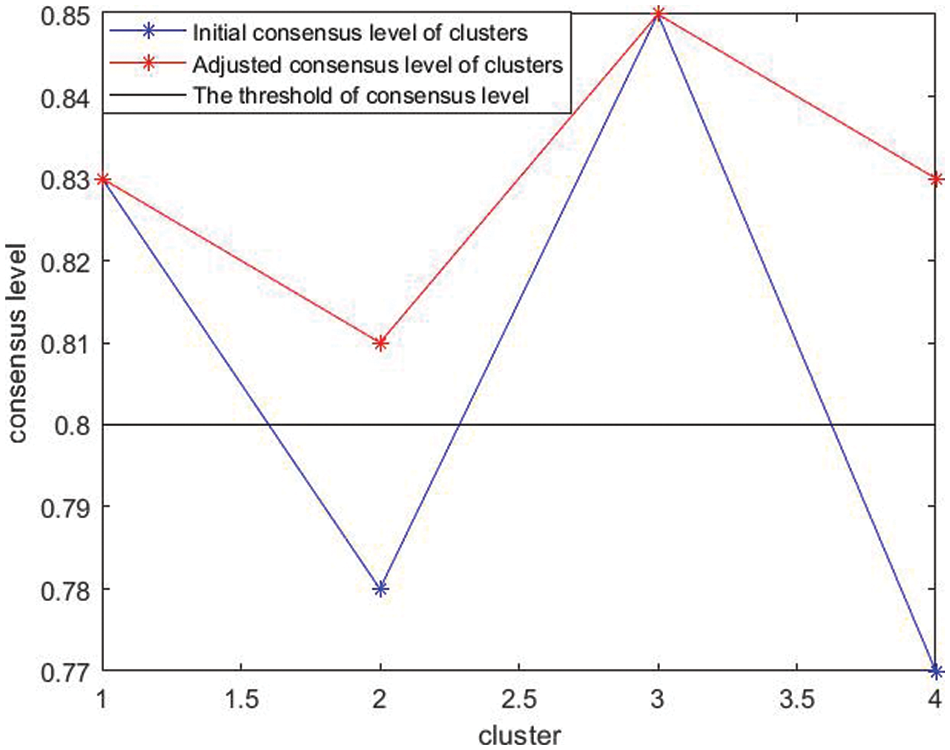
Figure 4: Changes in the consensus levels of clusters
Step 6: Calculate the consensus level of the whole group.
Set the threshold
Step 7: Selection of alternatives.
From Step 5 and Step 6, we can see that
The alternatives are ranked as:
5.3 Comparisons and Discussions
To further reflect the advantages and features of our proposed model, we conduct comparative analysis and discussion as follows:
5.3.1 Discussion on the PTC-Kmeans Clustering Algorithm
1) Determination of
We use the sum of the squared errors (SSE) to determine the value of k. The core idea of SSE is: as the number of clusters k increases, the division of the samples will be more refined, the aggregation degree of each cluster will gradually increase, and the value of SSE will naturally become smaller. When k is less than the optimal clustering number, since the increase of k will greatly increase the aggregation of each cluster, the decline of the value of SSE will be very large. When k reaches the optimal clustering number, the decline of the value of SSE will be slight with the increase of k. The SSE is shown as:
where
Fig. 5 presents the relationship between SSE and the number of clusters. When the number of clusters is more than 4, the SSE decreases slightly. Thus, we set
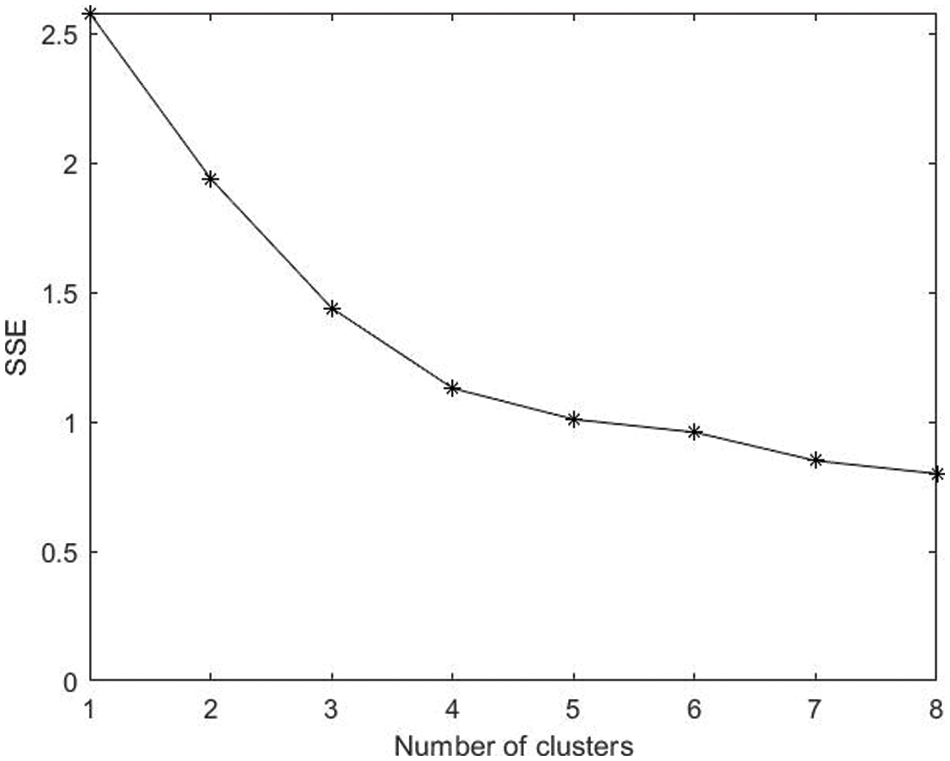
Figure 5: Relationship between SSE and the number of clusters
2) Determination of the trust constraints thresholds
The trust constraints play crucial roles in the determination of the initial clusters and the final cluster results. As shown in Fig. 6, the trust constraint threshold is positively correlated with the number of cannot-links while the threshold is negatively correlated with the number of must-links. The greater the number of cannot-links, the greater the minimum number of initial clusters, and the smaller the number of must-links, the greater the maximum number of initial clusters. For example, if there are 15 cannot-links, then it is possible that the minimum number of clusters required is 15; if there are 15 must-links, then it is possible that the maximum number of clusters is 1. In order to ensure that we can obtain 4 initial clusters, the cannot-link trust constraint link is set to

Figure 6: The relationship between the trust constraint threshold with the number of constraint links
3) Comparison with the traditional K-means algorithm
Where our algorithm differs from traditional algorithms is the addition of trust constraints. In our algorithm, experts with low trust should not be allocated to the same cluster while those with high trust must be in the same cluster. Through directly numerical comparison with the traditional K-means clustering method, the advantages of our algorithm are highlighted. As shown in Table 6, the overall trust degree and the consensus level of the initial clusters obtained by our proposed method are both higher than the initial clusters obtained by the traditional K-means. A higher degree of consensus level means a fewer number of positions to be adjusted. The decision cost of our proposed method is lower than the traditional K-means.

5.3.2 Discussion on the GDM Models
1) We use the data from the first consensus round in Section 5.2 to compare changes in the weight of experts when considering altruistic behavior and not considering altruistic behavior. Fig. 7 shows the difference in the weights of experts with altruistic and non-altruistic behaviors. We can see that when considering the altruistic behaviors of experts, the adjusted weight of experts is closer to the initial weight of experts than without altruistic behavior. It indicates that considering altruistic behavior not only can protect the interests of experts with non-cooperative behavior but also ensures the integrity of group opinions.
2) The comparisons with the management of non-cooperative behaviors in GDM models are demonstrated in Table 7. Compared with Tang et al. [20], Liao et al. [37], they only considered one type of non-cooperative behaviors. It can lead to a lack of integrity as they did not consider the whole problem. In our study, we define three types of non-cooperative behaviors. Dong et al. [15] also focused on different types of non-cooperative behaviors. However, in their models, they did not cluster the experts into subgroups and they assumed the maximum degree of cooperation is to totally accept the modification suggestions. For the definition of non-cooperative behaviors, they did not consider such a behavior that hesitant experts are purposed to provide their preference randomly to avoid revealing their true intentions. In this paper, we used the PTC-Kmeans algorithm to cluster experts into different subgroups and managed the non-cooperative behaviors based on different clusters. What’s more, we allowed experts to make more contributions to make up for the loss caused by experts with the non-cooperative behaviors, it protected the interests of experts with non-cooperative behaviors and ensured the integrity of decision-making information. We set different weight punishment according to the degree of non-cooperative and the degree of altruism.
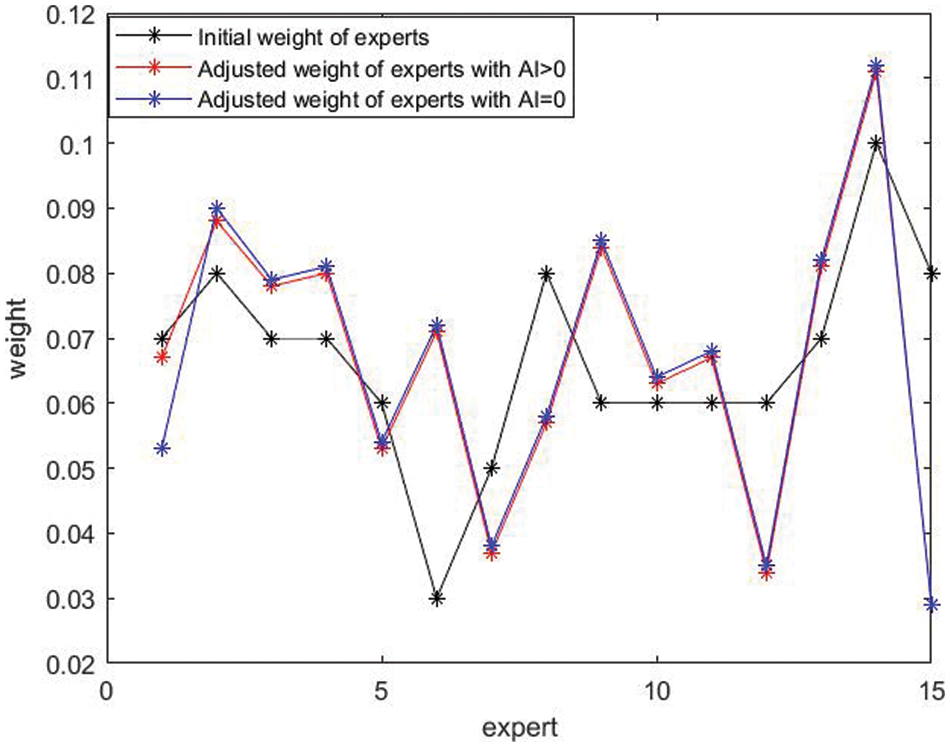
Figure 7: Changes in the weight of experts when considering altruistic behavior and not considering altruistic behavior

In this study, we proposed a consensus reaching model based on the social network which took into account different types of non-cooperative behaviors and altruistic behavior of experts in LSGDM problems. The main contributions and improvements could be summarized as follow: 1) the PTC-Kmeans algorithm was proposed to classify experts into several clusters based on the individual FPRs and trust relationships of experts. The two attributes were all regarded as important basis for classification and were seldom considered simultaneously in existing clustering methods. 2) A consensus reaching approach was proposed to improve the consensus level. Such a consensus reaching approach considered different types of non-cooperative behaviors and allowed experts with altruistic behaviors to make more contributions to compensate for the loss caused by the experts with non-cooperative behaviors. Different types of non-cooperative behaviors allowed for a more comprehensive consideration of the problem and the existence of altruistic behavior ensured the interests of experts with non-cooperative behavior. 3) The proposed LSGDM method was applied to a case study of the selection of emergency alternative after the flood in Henan, China.
There are still some limitations in this study. First, we only considered the non-cooperative behavior of experts but failed to consider the cooperative behavior. However, the cooperative behavior of experts may also affect the decision-making. Second, we did not take the cost control into consideration in the LSGDM. In the future, it is necessary to study how to merge altruistic behavior of experts into minimum cost consensus model. In addition, we assumed that all the experts used FPRs to express their preference information, in the future research, it is necessary to present the preference information of experts in more complex representations.
Funding Statement: The work was supported by the National Natural Science Foundation of China (Nos. 71771156, 71971145, 72171158).
Conflicts of Interest: The author declares that they have no conflicts of interest to report regarding the present study.
1https://new.qq.com/omn/20210620/20210620A06SFS00.html.
2https://www.sohu.com/a/211253384_770379.
3http://henan.sina.com.cn/news/2021-08-02/detail-ikqciyzk9115688.shtml.
4https://www.163.com/dy/article/GFDNN7OC0514R9L4.html.
References
1. Xu, X. H., Zhong, X. Y., Chen, X. H., Zhou, Y. J. (2015). A dynamical consensus method based on exit-delegation mechanism for large group emergency decision making. Knowledge-Based Systems, 86, 237–249. DOI 10.1016/j.knosys.2015.06.006. [Google Scholar] [CrossRef]
2. Xu, X. H., Du, Z. J., Chen, X. H. (2015). Consensus model for multi-criteria large-group emergency decision making considering non-cooperative behaviors and minority opinions. Decision Support Systems, 79, 150–160. DOI 10.1016/j.dss.2015.08.009. [Google Scholar] [CrossRef]
3. Xu, X. H., Huang, Y. X., Chen, K. (2019). Method for large group emergency decision making with complex preferences based on emergency similarity and interval consistency. Natural Hazards, 97(1), 45–64. DOI 10.1007/s11069-019-03624-1. [Google Scholar] [CrossRef]
4. Xu, X. H., Zhang, Q. H., Chen, X. H. (2020). Consensus-based non-cooperative behaviors management in large-group emergency decision-making considering experts’ trust relations and preference risks. Knowledge-Based Systems, 190, 105108. DOI 10.1016/j.knosys.2019.105108. [Google Scholar] [CrossRef]
5. Tang, M., Liao, H. C. (2021). From conventional group decision making to large-scale group decision making: What are the challenges and how to meet them in big data era? A state-of-the-art survey. Omega, 100, 102141. DOI 10.1016/j.omega.2019.102141. [Google Scholar] [CrossRef]
6. Saxena, A., Prasad, M., Gupta, A., Bharill, N., Patel, O. P. et al. (2017). A review of clustering techniques and developments. Neurocomputing, 267, 664–681. DOI 10.1016/j.neucom.2017.06.053. [Google Scholar] [CrossRef]
7. Wu, T., Liu, X. W., Qin, J. D. (2018). A linguistic solution for double large-scale group decision-making in E-commerce. Computers & Industrial Engineering, 116, 97–112. DOI 10.1016/j.cie.2017.11.032. [Google Scholar] [CrossRef]
8. Dong, Y. C., Zhao, S. H., Zhang, H. J., Chiclana, F., Herrera-Viedma, E. (2018). A self-management mechanism for noncooperative behaviors in large-scale group consensus reaching processes. IEEE Transactions on Fuzzy Systems, 26(6), 3276–3288. DOI 10.1109/TFUZZ.2018.2818078. [Google Scholar] [CrossRef]
9. Tian, Z. P., Nie, R. X., Wang, J. Q. (2019). Social network analysis-based consensus-supporting framework for large-scale group decision-making with incomplete interval type-2 fuzzy information. Information Sciences, 502, 446–471. DOI 10.1016/j.ins.2019.06.053. [Google Scholar] [CrossRef]
10. Newman, M. E. J., Girvan, M. (2004). Finding and evaluating community structure in networks. Physical Review E, 69(2), 026113. DOI 10.1103/PhysRevE.69.026113. [Google Scholar] [CrossRef]
11. Blondel, V. D., Guillaume, J. L., Lambiotte, R., Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 10. DOI 10.1088/1742-5468/2008/10/P10008. [Google Scholar] [CrossRef]
12. Du, Z. J., Luo, H. Y., Lin, X. D., Yu, S. M. (2020). A trust-similarity analysis-based clustering method for large-scale group decision-making under a social network. Information Fusion, 63, 13–29. DOI 10.1016/j.inffus.2020.05.004. [Google Scholar] [CrossRef]
13. Yu, S. M., Du, Z. J., Zhang, X. Y., Luo, H. Y., Lin, X. D. (2021). Punishment-driven consensus reaching model in social network large-scale decision-making with application to social capital selection. Applied Soft Computing, 113, 107912. DOI 10.1016/j.asoc.2021.107912. [Google Scholar] [CrossRef]
14. Cheng, D., Yuan, Y. X., Wu, Y., Hao, T. T., Cheng, F. X. (2022). Maximum satisfaction consensus with budget constraints considering individual tolerance and compromise limit behaviors. European Journal of Operational Research, 297(1), 221–238. DOI 10.1016/j.ejor.2021.04.051. [Google Scholar] [CrossRef]
15. Dong, Y. C., Zhang, H. J., Herrera-Viedma, E. (2016). Integrating experts’ weights generated dynamically into the consensus reaching process and its applications in managing non-cooperative behaviors. Decision Support Systems, 84, 1–15. DOI 10.1016/j.dss.2016.01.002. [Google Scholar] [CrossRef]
16. Mandal, P., Samanta, S., Pal, M., Ranadive, A. S. (2022). Three-way decision model under a large-scale group decision-making environment with detecting and managing non-cooperative behaviors in consensus reaching process. Artificial Intelligence Review, 55(7), 5517–5542. DOI 10.1007/s10462-021-10133-w. [Google Scholar] [CrossRef]
17. Quesada, F. J., Palomares, I., Martinez, L. (2015). Managing experts behavior in large-scale consensus reaching processes with uninorm aggregation operators. Applied Soft Computing, 35, 873–887. DOI 10.1016/j.asoc.2015.02.040. [Google Scholar] [CrossRef]
18. Zhang, H. J., Palomares, I., Dong, Y. C., Wang, W. W. (2018). Managing non-cooperative behaviors in consensus-based multiple attribute group decision making: An approach based on social network analysis. Knowledge-Based Systems, 162, 29–45. DOI 10.1016/j.knosys.2018.06.008. [Google Scholar] [CrossRef]
19. Simon, J., Saari, D., Keller, L. R. (2020). Interdependent altruistic preference models. Decision Analysis, 17(3), 189–207. DOI 10.1287/deca.2020.0411. [Google Scholar] [CrossRef]
20. Tang, M., Liao, H. C., Ding, W. P. (2022). Collective intelligence driven cross-functional group decision framework in digitalization technology selection for supply chain resilience. IEEE Transactions on Industrial Informatics. Technical Report. [Google Scholar]
21. Cao, J., Xu, X. H., Pan, B. (2022). Ambiguity-incorporated opinion formation model for multi-risk large-group emergency decision-making in social networks. Kybernetes, Ahead-of-print. DOI 10.1108/K-06-2021-0538. [Google Scholar] [CrossRef]
22. Stasser, G., Titus, W. (1985). Pooling of unshared information in group decision making: Biased information sampling during discussion. Journal of Personality and Social Psychology, 48(6), 1467–1478. DOI 10.1037/0022-3514.48.6.1467. [Google Scholar] [CrossRef]
23. Li, G. X., Kou, G., Peng, Y. (2021). Heterogeneous large-scale group decision making using fuzzy cluster analysis and its application to emergency response plan selection. IEEE Transactions on Systems, Man, and Cybernetics-Systems, 52(6), 3391–3403. [Google Scholar]
24. Liu, P. D., Wang, P., Pedrycz, W. (2020). Consistency-and consensus-based group decision-making method with incomplete probabilistic linguistic preference relations. IEEE Transactions on Fuzzy Systems, 29(9), 2565–2579. DOI 10.1109/TFUZZ.2020.3003501. [Google Scholar] [CrossRef]
25. Ding, S. F., Jia, H. J., Du, M. J., Xue, Y. (2018). A semi-supervised approximate spectral clustering algorithm based on HMRF model. Information Sciences, 429, 215–228. DOI 10.1016/j.ins.2017.11.016. [Google Scholar] [CrossRef]
26. Wu, Z. B., Xu, J. P. (2018). A consensus model for large-scale group decision making with hesitant fuzzy information and changeable clusters. Information Fusion, 41, 217–231. DOI 10.1016/j.inffus.2017.09.011. [Google Scholar] [CrossRef]
27. Liu, Q., Wu, H. Y., Xu, Z. S. (2021). Consensus model based on probability K-means clustering algorithm for large scale group decision making. International Journal of Machine Learning and Cybernetics, 12(6), 1609–1626. DOI 10.1007/s13042-020-01258-5. [Google Scholar] [CrossRef]
28. Tang, M., Zhou, X. Y., Liao, H. C., Xu, J. P., Fujita, H. et al. (2019). Ordinal consensus measure with objective threshold for heterogeneous large-scale group decision making. Knowledge-Based Systems, 180, 62–74. DOI 10.1016/j.knosys.2019.05.019. [Google Scholar] [CrossRef]
29. Yang, Y., Tan, W., Li, T. R., Ruan, D. (2012). Consensus clustering based on constrained self-organizing map and improved Cop-kmeans ensemble in intelligent decision support systems. Knowledge-Based Systems, 32, 101–115. DOI 10.1016/j.knosys.2011.08.011. [Google Scholar] [CrossRef]
30. Wagstaff, K., Cardie, C., Rogers, S., Schrödl, S. (2001). Constrained K-means clustering with background knowledge. Proceedings of the Eighteenth International Conference on Machine Learning, pp. 577–584. Williams College, Williamstown, MA, USA. [Google Scholar]
31. Liu, B. S., Zhou, Q., Ding, R. X., Palomares, I., Herrera, F. (2019). Large-scale group decision making model based on social network analysis: Trust relationship-based conflict detection and elimination. European Journal of Operational Research, 275(2), 737–754. DOI 10.1016/j.ejor.2018.11.075. [Google Scholar] [CrossRef]
32. Liao, H. C., Li, X. F., Tang, M. (2021). How to process local and global consensus? A large-scale group decision making model based on social network analysis with probabilistic linguistic information. Information Sciences, 579, 368–387. DOI 10.1016/j.ins.2021.08.014. [Google Scholar] [CrossRef]
33. Gao, Y., Zhang, Z. (2021). Consensus reaching with non-cooperative behavior management for personalized individual semantics-based social network group decision making. Journal of the Operational Research Society, 1–18. DOI 10.1080/01605682.2021.1997654. [Google Scholar] [CrossRef]
34. Li, S. L., Rodríguez, R. M., Wei, C. P. (2021). Managing manipulative and non-cooperative behaviors in large scale group decision making based on a WeChat-like interaction network. Information Fusion, 75, 1–15. DOI 10.1016/j.inffus.2021.04.004. [Google Scholar] [CrossRef]
35. Chao, X. R., Kou, G., Peng, Y., Viedma, E. H. (2021). Large-scale group decision-making with non-cooperative behaviors and heterogeneous preferences: An application in financial inclusion. European Journal of Operational Research, 288(1), 271–293. DOI 10.1016/j.ejor.2020.05.047. [Google Scholar] [CrossRef]
36. Lin, M. W., Wang, H. B., Xu, Z. S., Yao, Z. Q., Huang, J. L. (2018). Clustering algorithms based on correlation coefficients for probabilistic linguistic term sets. International Journal of Intelligent Systems, 33(12), 2402–2424. DOI 10.1002/int.22040. [Google Scholar] [CrossRef]
37. Liao, H. C., Kuang, L. S., Liu, Y. X., Tang, M. (2021). Non-cooperative behavior management in group decision making by a conflict resolution process and its implementation for pharmaceutical supplier selection. Information Sciences, 567, 131–145. DOI 10.1016/j.ins.2021.03.010. [Google Scholar] [CrossRef]
Appendix

Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools