
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

An Auto-Grading Oriented Approach for Off-Line Handwritten Organic Cyclic Compound Structure Formulas Recognition
Faculty of Artificial Intelligence in Education, Central China Normal University, Wuhan, 430079, China
* Corresponding Author: Bin He. Email:
(This article belongs to the Special Issue: Humanized Computing and Reasoning in Teaching and Learning)
Computer Modeling in Engineering & Sciences 2023, 135(3), 2267-2285. https://doi.org/10.32604/cmes.2023.023229
Received 15 April 2022; Accepted 22 August 2022; Issue published 23 November 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Auto-grading, as an instruction tool, could reduce teachers’ workload, provide students with instant feedback and support highly personalized learning. Therefore, this topic attracts considerable attentions from researchers recently. To realize the automatic grading of handwritten chemistry assignments, the problem of chemical notations recognition should be solved first. The recent handwritten chemical notations recognition solutions belonging to the end-to-end trainable category suffered from the problem of lacking the accurate alignment information between the input and output. They serve the aim of reading notations into electrical devices to better prepare relevant e-documents instead of auto-grading handwritten assignments. To tackle this limitation to enable the auto-grading of handwritten chemistry assignments at a fine-grained level. In this work, we propose a component-detection-based approach for recognizing off-line handwritten Organic Cyclic Compound Structure Formulas (OCCSFs). Specifically, we define different components of OCCSFs as objects (including graphical objects and text objects), and adopt the deep learning detector to detect them. Then, regarding the detected text objects, we introduce an improved attention-based encoder-decoder model for text recognition. Finally, with these detection results and the geometric relationships of detected objects, this article designs a holistic algorithm for interpreting the spatial structure of handwritten OCCSFs. The proposed method is evaluated on a self-collected data set consisting of 3000 samples and achieves promising results.Keywords
Preparation and grading of tests are the key activities in instruction, which could reflect the students’ cognitive level and provide sources for teachers to improve their teaching. To realize auto-grading is meaningful as it has multiple functions such as reducing the workload of teachers, providing immediate feed-backs to students and supporting highly personalized learning. It has been widely used in subjects of English and Computer to grade English composition [1] and computer program [2,3]. This paper will be focused on automatic grading of handwritten chemistry assignments. Obviously, handwritten chemical notations recognition is the preliminary technique.
Handwriting recognition could be divided into online and offline two cases. In the online case, the input is a sequence of stokes while the input is an image for the offline. The published works regarding handwritten chemical notations recognition were mainly focused on the online case as more information (time) is available compared to the offline case. However, the offline case could support more application scenarios, such as auto-grading of chemistry paper tests. In daily study of chemistry, examinations for a long time to come will still be based on paper tests. Thus, in this work, we expect to solve the problem of offline handwritten OCCSFs recognition. This task is very challenging from two respects: (1) Large intra-class variance. Handwritten cases contain deformations in size, shape, and other variations. (2) Complex 2-dimensional structures. OCCSFs usually contain one or more rings accompanied by multiple text chains. These features make the task become a tricky problem.
With the development of deep learning techniques, many landmark achievements were released in the offline handwriting recognition field. Dominant methods belong to the end-to-end trainable class including ones based on connectionist temporal classification (CTC) [4] and others based on attention mechanism [5]. These methods achieved significant success on 1D text recognition [6] or 2D handwritten math expressions recognition tasks [7,8] owing to the strong capabilities of learning robust feature representation and accessing the global contextual information. They usually take as input an image of handwritten texts and output the sequence of labels directly. However, the accurate alignment between the output sequence of labels and the input image is difficult to determine with the existing approaches, which is important for auto-grading to diagnose errors or generate fine-grained feed-backs.
Currently, the published solutions to handwritten chemical notations recognition serve only the aim of reading notations into electrical devices to better prepare relevant e-documents instead of auto-grading students’ assignments. The recent handwritten chemical notations recognition solutions [9] belonging to the end-to-end trainable category suffered from the problem of lacking the accurate alignment information between the input and the output. However, this accurate alignment information is required in grading assignments to diagnose errors and generate feed-backs at a fine-grained level. To tackle this limitation, we propose an auto-grading oriented approach for off-line handwritten OCCSFs Recognition. OCCSFs, as a typical two dimensional graphics language, have a complex spatial structure. Hand-drawn OCCSFs recognition is an appealing task as it exhibits big challenges for the complex spatial structure and variable writing style. Fig. 1 presents some examples of offline handwritten OCCSFs. In this work, we focus on OCCSFs with one or two ring structures. These types cover almost all the OCCSFs appearing in K12 education. To obtain the accurate alignment between the input and the output, we propose a components-detection-based approach for offline handwritten OCCSFs recognition.

Figure 1: Samples of offline handwritten OCCSFs
Deep convolutional neural networks (DCNNs) [10] demonstrated excellent performance on image classification tasks. It also boosted the developments in the object detection field, bringing on dramatic improvements on accuracy. Currently, CNN-based object detection algorithms generally could be divided into two categories, being two-stage detectors and one-stage detectors. The two-stage methods such as Faster-RCNN [11] firstly generate region proposals and then address detection as a classification problem over region proposals. The one-stage methods like SSD [12,13], and YOLO [14] skip the region proposal generation step and predict bounding boxes and confidences for multiple categories directly. These one-stage methods have comparable performance with two-stage methods and yet are faster [12].
OCCSFs contain both graphical components and text components. The idea proposed in this work for handwritten OCCSFs recognition is to regard these components as different objects and use object detection algorithms to detect them. Then with detection results and spatial relationships between detected components, we analyse the structure. As the problem involves both graphical objects and text objects detection, the common detectors SSD and YOLO are adopted both to detect the predefined objects in OCCSFs. Next, the detected text components need to be recognized further. As reported in [15], attention-based methods can achieve higher recognition accuracy than CTC-based methods on isolated word recognition tasks, but perform worse on sentence recognition tasks. Apparently, text components in chemical OCCSFs appearing in K12 are similar to words instead of sentences. Thus we use an improved attention-based model for text components recognition by mitigating the existing error accumulation problem. Finally, an algorithm is proposed for interpreting the formula structure, which takes the detection results as input and outputs the interpretation results. This work is an extended version of the paper [16] published in 2021 International Conference on Engineering, Technology, and Education. Compared with [16], the work is extended from several aspects. Firstly, component detection is improved by introducing YOLOv5. Secondly, text components recognition is performed via integrating scheduled sampling into Decoupled Attention Network. Thirdly, OCCSFs with multiple rings are considered in this paper.
The main contributions of this work are as follows:
• We propose an auto-grading oriented approach for off-line handwritten OCCSFs recognition, which could output the final recognition results, as well as the accurate alignment between the input and output. This accurate alignment information is indispensable for auto-grading to diagnose errors or generate fine-grained feed-backs. The approach addresses the problem by defining the different types of components as objects, then adopting object detection algorithms to detect different components, next recognizing the text objects if exist and finally using the detection results to interpret the structure.
• An improved attention-based model for text components recognition is proposed via mitigating the existing error accumulation problem.
• Several metrics at the object level are defined to better analyze the effects of components detection results on later structure interpretation.
• An off-line handwritten OCCSFs dataset which consists of 3000 samples is built and later will be released freely for the research aim.
This article will explain the related works in Section 2. Section 3 introduces the built dataset and Section 4 details the proposed approach. Section 5 gives the experimental details and results. Finally, Section 6 concludes this work and puts forward some ideas for future work.
In this section, we review the literatures from three aspects, being chemical structure formulas recognition, object detection and text recognition which are closely related to our work.
2.1 Chemical Structure Formulas Recognition
The data to be handled could be in print format or handwritten format. Further, handwriting data could be again divided into on-line and off-line two cases. In the on-line case, the input is a sequence of stokes while the input is an image for the off-line. Even though time information is not available compared to the on-line case, the off-line case could support more application scenarios, such as the auto-grading of chemistry paper tests.
Regarding chemical structural formulas recognition, the published works mainly focused on the on-line case. In 2007, Ouyang et al. designed an on-line recognition system for hand-drawn chemical diagrams [17]. The system used a trained classifier to locate and recognize chemical symbols, and then generated the initial structure considering the spatial context. Finally, the system used chemical knowledge to check the legitimacy of the interpreted structure and modified it if necessary. To promote the work in [17], they proposed “ChemInk” [18] a real-time recognition system which used a jointly trained conditional random field to combine multiple levels of visual features. The framework accessed different levels of details to enhance the system robustness to noise and drawing variations, thus improving the performance. Sadawi et al. [19] proposed a rule-based method where they used rules to identify atoms and bonds and deal with possible ambiguities. Sun et al. proposed a free-sketch recognition method [20] for chemical structural formulas. A dual-mode method was used to distinguish character input and non-character input first. Then they adopted an attribute graph to model sketched chemical structural formula and utilized domain knowledge to rectify the relationships among elements.
The research on off-line chemical structure formulas recognition goes into two branches—the rule-based category [21] and the end-to-end trainable category [9]. Bukhari et al. [21] proposed a system to automatically analyse the printed 2-D chemical structures in document images using traditional image processing techniques. The proposed recognition process consisted of a series of operations (totally 9) based on open-source libraries such as OpenCV-3.3. However, with embedded algorithms like Line Segment Detector and Hough Circle, it is difficult to deal with handwritten inputs which have multi-variations. Literature [9] published an attention-mechanism-based method which translated a bitmap image of a molecule directly into a SMILES—a machine-readable chemical format. This deep-learning-based method has a stronger generalization capability compared to the rule-based one. However, the accurate alignment between the output sequence of labels and the input image is difficult to determine. Unfortunately, the alignment information is indispensable for auto-grading to diagnose students’ errors and generate fine-grained feedback. Thus, to break these limitations to enable auto-grading of handwritten chemical assignments at a fine-grained level, we propose a component-detection-based approach for off-line handwritten OCCSFs recognition.
Before the era of CNNs, traditional object detection methods mainly consisted of three steps, being region selection, feature extraction and classification. Deformable Part Model (DPM) [22] and Selective Search [23] were two state-of-the-art methods.
In 2014, Girshick proposed the R-CNN [24] detection algorithm which is the first CNN-based object detection algorithm achieving impressive results. This method combined selective search region proposals and CNN-based post-classification together. The subsequent research [11,25,26] improved the quality of region proposal generation or post-classification stage alternatively. Post-classification is costly and time-consuming as it needs to process thousands of image regions. SPPnet [25] speeded up the R-CNN detection algorithm notably by introducing a spatial pyramid pooling layer between the convolutional layer and fully connected layer to improve feature extraction. However, the training of SPPnet was still a multi-stage pipeline, far away from being end-to-end. Fast R-CNN [26] strengthened SPPnet again by proposing a single-stage training algorithm that jointly learned to classify object proposals and refine their spatial locations. Faster R-CNN [11] improved the quality of proposal generation by replacing selective search method with a region proposal network (RPN). Furthermore, it proposed an alternative training method to integrate RPN with Fast R-CNN. In general, these methods consist of region proposal generation and proposal classification and are named as two-stage detectors.
Different from the above-mentioned two-stage detectors, YOLO [14] and SSD [12] discarded region proposal generation step and predicted bounding boxes and confidences for multiple categories directly, therefore possessing high speed. They were named as one-stage detectors. The common understanding is that YOLO performs better on smaller objects and SSD performs better on larger objects. Overall, one-stage detectors have comparable performance with two-stage methods and yet possess high speed. Thus we propose a method for component detection of handwritten OCCSFs based on the one-stage detectors. Both YOLO and SSD will be tested in our task to compare the performances.
The proposed methods for text recognition can be roughly divided into 2 classes, being segmentation-based and segmentation-free. The segmentation-based methods [27–29] usually involve segmenting characters, recognizing characters and combining the recognition results into the final outputs. However, accurate character segmentation is very difficult, especially for the handwriting input.
The segmentation-free methods encode the text input as a whole and decode the encoded features directly into the sequence of labels in an end-to-end trainable manner. With the strong ability of visiting global context information, this type of method achieved promising performance on a series of text recognition tasks. Two representative methods were CTC-based and attention-based. In [6], a novel neural network architecture was proposed, which integrated CNN (for feature extraction), RNN (for sequence modelling) and CTC (for transcription) into a unified framework. The attention mechanism was originally proposed in neural machine translation [5] and later was introduced into text recognition [30,31]. Different neural network models were proposed to work as the encoder to encode an input text image into a one-dimensional feature sequence [30,31] or a two-dimensional feature map [7]. The latter one retained the vertical spatial information. The attention model learned to focus on a specific region of the feature sequence or feature map at each time step. The conventional soft-attention mechanism proposed in [5] was developed in later works [7,32] to achieve better alignments. The decoder outputted the sequence of labels in an auto-regressive way. For the decoder module, the recurrent neural network was the most widely used model.
As reported in [15], attention-based methods can achieve higher recognition accuracy than CTC-based methods on isolated word recognition tasks, but perform worse on sentence recognition tasks. The text components in chemical organic structure formulas appearing in K12 could be regarded as words instead of sentences, which do not contain vertical structures. Thus, in this paper, we adopt the attention-based encoder-decoder model for text components recognition.
The typical attention-based method generates the target sequence of tokens one by one. It predicts the current token depending on both the previous token and the feature currently focused. Furthermore, the computation of the feature currently focused also depends on the previous token. That means once there is a mistake happening in the historical decoding, the error could be propagated quickly along the sequence via these dependencies. To tackle the limitations, Decoupled Attention Network (DAN) was proposed in [33] which decoupled the dependency of the computation of the feature currently focused on the previous token. It used a convolutional alignment module that computed the focused weights of each time step based on visual features from the encoder only. However, DAN solved this error accumulation problem of the attention-based model partially not totally since the prediction of the current token still related to the previous token. At the training stage, the ground-truth previous tokens are available but not available at inference. This discrepancy between training and inference could lead to errors that propagate quickly along the sequence. Scheduled sampling [34] was proposed by Google to mitigate this discrepancy. In this work, we combine DAN and scheduled sampling to improve the attention-based model and then apply it for text components recognition.
3 The Off-Line Handwritten OCCSFs Dataset
In this work, we focus on OCCSFs with one or two-ring structures. These types cover almost all the OCCSFs appearing in K12 education. To our knowledge, there is no public offline handwritten OCCSFs data set available yet. Thus a data set should be created first. We collected common handwritten OCCSF images such as aromatic hydrocarbon, halogenated hydrocarbon, cyclohexane, cyclohexene, xylene, trinitrotoluene and other derivatives. As this work aims for auto-grading eventually, some samples collected may not follow the chemical grammar rules. Totally, a data set was built consisting of 2000 one-ring structure images and 1000 two-ring structure images. For the data annotation, we labelled the collected samples by 4 predefined objects (benzene, ring, doublebond, textchain. Details can be found in Section 4.1) and save the annotation information as VOC2007 format which is supported by both SSD and YOLO. Table 1 provides the statistics of the built data set. According to these statistics, it is known that each sample contains 3.485 objects in average. Fig. 2 illustrates some collected samples (two-ring structures only).
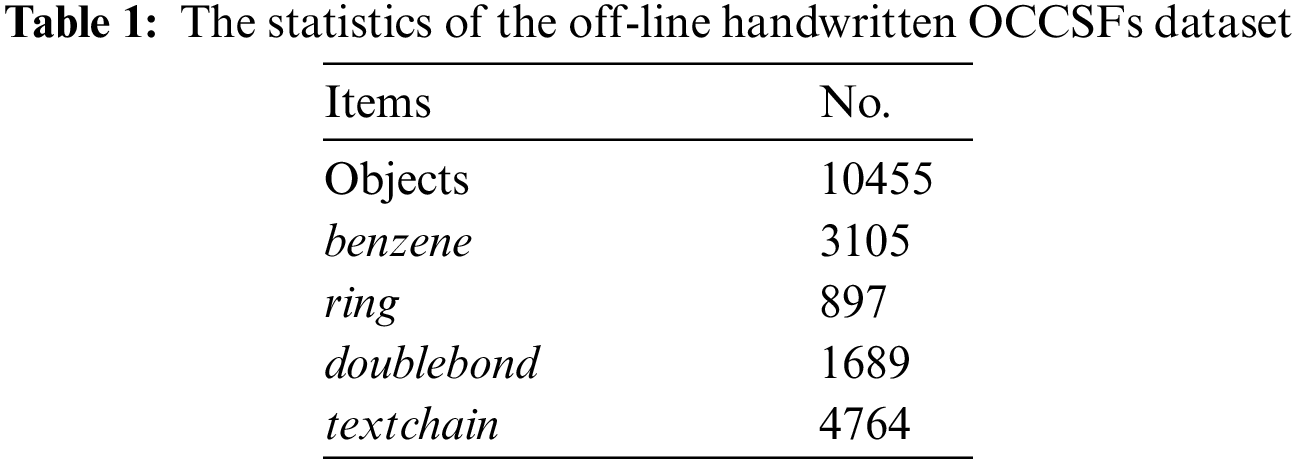

Figure 2: Samples of two-ring structure
In this paper, we consider the idea of using deep learning object detector to locate and classify the components in hand-drawn OCCSFs and interpreting the structure with the detection results. Specifically, a components-detection-based method (as shown in Fig. 3) was proposed which includes mainly 3 steps, being components detection, text components recognition and structure interpretation respectively. In the coming paragraphs, we will introduce these 3 steps in detail.

Figure 3: Illustration for the framework of the proposed method
We define 4 types of components as objects, namely benzene, ring, doublebond

Figure 4: Illustration for the predefined objects

Figure 5: The overall network structure of YOLOv5
4.2 Text Components Recognition
Different from the other 3 types of components, textchain need to be recognized further to obtain the sequence of labels. In [35], an end-to-end trainable system was proposed for recognizing handwritten chemical formulas. The proposed system adopted the CNN + RNN + CTC framework. With the strategy of introducing additional labels, this framework could interpret the ‘subscript’ and ‘superscript’ existing in chemical formula. As stated in work [15], the attention-based method can achieve a higher recognition accuracy than the CTC-based method on isolated word recognition tasks and the text components in OCCSFs appearing in K12 are very similar to words. Therefore, we will adopt the attention-based encoder-decoder model for text components recognition. However, the classical attention-based encoder-decoder model suffers from the error accumulation problem. In [33], a decoupled attention network was proposed which solves the error accumulation problem partially. In this work, we combine DAN and scheduled sampling [34] to further mitigate the problem and then apply the improved attention-based model for text components recognition.
The improved attention-based encoder-decoder model is composed of three major parts: encoder, convolutional alignment module and text decoder with scheduled sampling. The details will be given in the following paragraphs.
Resnet is adopted as the encoder to extract features from textchain components image regions. As Fig. 6 shows, it stacks 23 residual blocks. The size and number of kernels we use are embedded in each block.

Figure 6: The structure of encoder
4.2.2 Convolutional Alignment Module
This module takes a FCN-like architecture to compute the attention map directly, which is different from the traditional attention mechanism where the computation of the features currently attended depends on the previous token generated by the decoder. First, the features at each scale extracted by the encoder are fed into the convolution stage which contains several down-sampling convolutional layers; Then the deconvolution stage, by adding the feature in the corresponding convolution layer, makes dense predictions per-pixel channel-wise. The number of channels equals to the number of decoding steps.
4.2.3 Decoder with Scheduled Sampling
The decoder takes the feature map (from the encoder) and the attention map (from the convolutional alignment module) as input and outputs the sequence of labels. During the procedure of decoding, the decoder uses a GRU (gated recurrent unit) layer to model the contextual information. As illustrated in Fig. 7, The current hidden state of GRU is determined by three sources: the previous hidden state

Figure 7: Detailed structure of the decoder with scheduled sampling. gi represents the ground truth label
where
The previous token adopted being the ground truth token
where
In this work, we focus on the task of multi-ring structure interpretation. Ideally, we can obtain the accurate bounding boxes and categories of the predefined components in hand-drawn OCCSFs. With these bounding boxes and categories information, the structure can be interpreted unambiguously via analysing the spatial relationships between them. We introduce the proposed interpretation algorithm in detail as follows.
4.3.1 Geometric Property of OCCSFs
The standard benzene structure is a regular hexagon with a circle or 3 bonds inside. There also exist other cases where a regular hexagon is with 0, 1, 2 bonds inside [36]. No matter circle or bonds are inside, no matter where the bonds are, a regular hexagon (ring) could be drawn in 2 formats, being horizontal and vertical as shown in Fig. 8. Obviously, each hexagon (ring) has 6 vertices and 6 edges. In some cases, the edge and the internal bond form a double bond together. If we link each vertex and edge of the hexagon to the origin, 12 axes (6 vertex axes and 6 edge axes) could be obtained and the angle between the adjacent axes is

Figure 8: The vertical (left) and horizontal (right) formats of the ring structures which have a circle and 0 bond inside, respectively
4.3.2 Interpretation Algorithm
Given the geometric property of OCCSFs, it is intuitive to consider using the angle offset information between detected objects and standard formats to analyse the hand-drawn structure. Motivated by this idea, we design a bottom-up hand-drawn OCCSFs interpretation algorithm which analyzes the single-ring structure first, then connects two interpreted rings.
With respect to the single-ring structure interpretation, we first take the geometric center of detected benzene or ring object box as the origin to establish a rectangular coordinate system. Then draw an axis every

Figure 9: Printed formula is presented with 12 axes
where
Next, we introduce how to compute the angle offset between the hand-drawn ring structure and the standard format.
• If it is a textchain object, we compute the angle differences with 6 vertex axes of standard horizontal format and take the minimum one as
• If it is a doublebond object, we compute the angle differences with 6 edge axes of standard horizontal format and take the minimum one as
Each angle difference is calculated by measuring the angle between the line connecting two origins (the origin of the detected benzene or ring box and the origin of the detected textchain or doublebond box) and the corresponding axis. In the similar way, we can compute

Figure 10: Illustration for the computation process of
When the single-ring structure is interpreted, the rest task is to connect two rings if exist. The strategy we take is regarding one ring as textchain of the other ring and locating it with the same method aforementioned. Algorithm 1 provides the whole process for structure interpretation.
The off-line handwritten OCCSFs dataset is divided into the training set, validation set and test set with the ratio of 6:2:2.
• GPU: Nvidia GeForce RTX 2080 Ti with 11G memory
• Library: Pytorch 1.9; CUDA 11.1
• Batch size: 16
• Learning rate: 0.01
• Learning rate decay: Cosine annealing
In addition to the common evaluation metrics such as precision, recall and mAP in the field of object detection, we define new metrics at the object level to better analyse the effects of components detection results on later structure interpretation.
where n denotes the number of objects of one category in the ground truth file,
In this section, we detail the components detection results using one-stage detectors, SSD and YOLOv5. We first compare the performances of two detectors on our task with the metric of mAP@0.5. As shown in Table 2, both SSD and YOLO v5 have nearly perfect performances on benzene, ring and textchain detection. But YOLOv5 has achieved a higher mAP@0.5 on bond2 than SSD which is consistent with the common conclusion that YOLO performs better on detecting smaller objects.


To deeply analyse the detection results from the point of view of structure interpretation, we also give the detailed information with the proposed metrics in this work. Table 3 provides these interesting data. From the statistics we can see that SSD misses around


Figure 11: Detection results using SSD

Figure 12: Detection results using YOLOv5
There are 4764 textchain components in the off-line handwritten OCCSFs dataset which is in fact very limited in terms of quantity, scope and sequence length. Text components of chemical organic structure formulas look visually as same as chemical formulas, both composed of a sequence of chemical symbols. In order to better evaluate the proposed improved attention-based encoder-decoder model for text recognition, we use a larger handwritten chemical formulas dataset published in [35] which consists of 12,224 samples covering 97 chemical formulas. The data is divided into the training and test subset with the ratio of 8:2.
• GPU: Nvidia GeForce RTX 2080 Ti with 11 G memory
• Library: Pytorch 1.9; CUDA 11.1
• Batch size: 24
• Learning rate: 0.1
• Learning rate decay: 0.3162
Table 4 provides the detailed results at character level and formula level of handwritten chemical formulas recognition with different methods proposed in different literature [33,35,37]. As can be seen, for the task of handwritten chemical formulas recognition, the vanilla attention-based method [37] performs better than the CTC-based method [35] which is consistent with the conclusion in [15] that attention-based methods can achieve higher recognition accuracy than CTC-based methods on isolated word recognition tasks. When the decoupled attention [33] is introduced, the accuracies increase again (

We use the proposed model to recognize the detected textchain components.
As introduced in Algorithm 1, the interpretation algorithm takes detected boxes and their categories as input and outputs the corresponding interpretation results. We respectively evaluate the proposed algorithm on the single-ring and multi-ring samples from the test set. An overall accuracy of 74.32% is achieved considering the errors from the components detection step, where 87.62% of single-ring samples and 45.12% of multi-ring samples are correctly interpreted. It can be seen from the statistics that the proposed algorithm performs well on single-ring samples. However, the result on multi-ring samples is not ideal which could be caused by the conflict between the complex structures of multi-rings and the limited representation capability of the proposed angle offset feature. In Fig. 13, we present some interpreted samples including the correct cases, as well as some error cases to indicate the directions to improve the structure interpretation algorithm in future works.


Figure 13: Illustration of some interpreted samples. (a) A correctly interpreted single-ring sample; (b) A wrongly interpreted single-ring sample; (c) A correctly interpreted multi-ring sample; (d) A wrongly interpreted multi-ring sample
Overall, the proposed approach achieves a total accuracy of 73.52% for off-line handwritten OCCSFs recognition on a self-collected data set.
In this work, we propose an auto-grading oriented approach for off-line handwritten OCCSFs recognition. The proposed method firstly defines different components of OCCSFs as objects and adopts the deep learning detector YOLOv5 to detect them. Then, for the detected text objects, we introduce an improved attention-based encoder-decoder model for text recognition. Finally, a holistic algorithm is designed for interpreting the single-ring structures. With the proposed method, the accurate alignment information between the input and output is available which makes the auto-grading of handwritten chemistry assignments at a fine-grained level possible.
At present, the structure interpretation algorithm works well for single-ring structures but has limited performance on multi-ring samples. It could be caused by the conflict between the complex structures of multi-rings and the limited representation capability of the proposed angle offset feature. No doubt, low robustness, low generalization capability and limited representation capability are the common problems of manually designed features. This weakness will be tackled by learning feature representations automatically in future.
Funding Statement: This work is supported by National Natural Science Foundation of China (Nos. 62007014 and 62177024), the Humanities and Social Sciences Youth Fund of the Ministry of Education (No. 20YJC880024), China Post Doctoral Science Foundation (No. 2019M652678) and the Fundamental Research Funds for the Central Universities (No. CCNU20ZT019).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Southavilay, V., Yacef, K., Reimann, P., Calvo, R. A. (2013). Analysis of collaborative writing processes using revision maps and probabilistic topic models. The Third International Conference on Learning Analytics and Knowledge, pp. 38–47. Leuven Belgium. [Google Scholar]
2. Singh, R., Gulwani, S., Solar-Lezama, A. (2013). Automated feedback generation for introductory programming assignments. The 34th ACM Sigplan Conference on Programming Language Design and Implementation, pp. 15–26. Seattle, Washington DC, USA. [Google Scholar]
3. Gulwani, S., Radiek, I., Zuleger, F. (2014). Feedback generation for performance problems in introductory programming assignments. 22nd ACM SIGSOFT International Symposium on the Foundations of Software Engineering, 45(11), 41–51. [Google Scholar]
4. Graves, A., Fernández, S., Gomez, F., Schmidhuber, J. (2006). Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. Proceedings of the 23rd International Conference on Machine Learning, pp. 369–376. Pittsburgh Pennsylvania, USA. [Google Scholar]
5. Bahdanau, D., Cho, K., Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA. [Google Scholar]
6. Shi, B., Bai, X., Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(11), 2298–2304. DOI 10.1109/TPAMI.2016.2646371. [Google Scholar] [CrossRef]
7. Zhang, J., Du, J., Zhang, S., Liu, D., Hu, Y. et al. (2017). Watch, attend and parse: An end-to-end neural network based approach to handwritten mathematical expression recognition. Pattern Recognition, 71, 196–206. DOI 10.1016/j.patcog.2017.06.017. [Google Scholar] [CrossRef]
8. Sakshi, S., Kukreja, V. (2021). A retrospective study on handwritten mathematical symbols and expressions: Classification and recognition. Engineering Applications of Artificial Intelligence, 103, 104292. DOI 10.1016/j.engappai.2021.104292. [Google Scholar] [CrossRef]
9. Rajan, K., Zielesny, A., Steinbeck, C. (2020). DECIMER-towards deep learning for chemical image recognition. Journal of Cheminformatics, 12(1), 65. DOI 10.1186/s13321-020-00469-w. [Google Scholar] [CrossRef]
10. Krizhevsky, A., Sutskever, I., Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 60(6), 1097–1105. [Google Scholar]
11. Ren, S., He, K., Girshick, R., Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 39(6), 91–99. [Google Scholar]
12. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S. et al. (2016). Ssd: Single shot multibox detector. European Conference on Computer Vision, pp. 21–37. Amsterdam, The Netherlands, Springer. [Google Scholar]
13. Liao, M., Shi, B., Bai, X., Wang, X., Liu, W. (2017). TextBoxes: A fast text detector with a single deep neural network. Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, California, USA. [Google Scholar]
14. Redmon, J., Divvala, S., Girshick, R., Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788. Las Vegas, NV, USA. [Google Scholar]
15. Cong, F., Hu, W., Huo, Q., Guo, L. (2019). A comparative study of attention-based encoder-decoder approaches to natural scene text recognition. International Conference on Document Analysis and Recognition (ICDAR), pp. 916–921. Sydney, NSW, Australia. [Google Scholar]
16. Wang, Y., Zhang, T., Yu, X. (2021). A component-detection-based approach for interpreting off-line handwritten chemical cyclic compound structures. IEEE International Conference on Engineering, Technology, and Education (TALE), Wuhan, Hubei Province, China. [Google Scholar]
17. Ouyang, T. Y., Davis, R. (2007). Recognition of hand drawn chemical diagrams. AAAI, 7, 846–851. [Google Scholar]
18. Ouyang, T. Y., Davis, R. (2011). Chemink: A natural real-time recognition system for chemical drawings. Proceedings of the 16th International Conference on Intelligent User Interfaces, pp. 267–276. [Google Scholar]
19. Sadawi, N. M., Sexton, A. P., Sorge, V. (2012). Chemical structure recognition: A rule-based approach. Proceedings of SPIE 8297, Document Recognition and Retrieval XIX. International Society for Optics and Photonics, Burlingame, California, USA. [Google Scholar]
20. Sun, P., Chen, Y., Lyu, X., Wang, B., Qu, J. et al. (2018). A free-sketch recognition method for chemical structural formula. 2018 13th IAPR International Workshop on Document Analysis Systems (DAS), pp. 157–162. Vienna, Austria: IEEE. [Google Scholar]
21. Bukhari, S. S., Iftikhar, Z., Dengel, A. (2019). Chemical structure recognition (CSR) system: Automatic analysis of 2D chemical structures in document images. 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia: IEEE. [Google Scholar]
22. Felzenszwalb, P. F., Girshick, R. B., McAllester, D., Ramanan, D. (2009). Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9), 1627–1645. DOI 10.1109/TPAMI.2009.167. [Google Scholar] [CrossRef]
23. Uijlings, J. R., van de Sande, K. E., Gevers, T., Smeulders, A. W. (2013). Selective search for object recognition. International Journal of Computer Vision, 104(2), 154–171. DOI 10.1007/s11263-013-0620-5. [Google Scholar] [CrossRef]
24. Girshick, R., Donahue, J., Darrell, T., Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 580–587. Columbus, OH, USA. [Google Scholar]
25. He, K., Zhang, X., Ren, S., Sun, J. (2015). Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(9), 1904–1916. DOI 10.1109/TPAMI.2015.2389824. [Google Scholar] [CrossRef]
26. Girshick, R. (2015). Fast R-CNN. Proceedings of International Conference on Computer Vision, Santiago, Chile. [Google Scholar]
27. Bissacco, A., Cummins, M., Netzer, Y., Neven, H. (2013). Photoocr: Reading text in uncontrolled conditions. IEEE International Conference on Computer Vision, pp. 785–792. Sydney, NSW, Australia. [Google Scholar]
28. Jaderberg, M., Simonyan, K., Vedaldi, A., Zisserman, A. (2014). Synthetic data and artificial neural networks for natural scene text recognition. Annual Conference on Neural Information Processing Systems Deep Learning Workshop, Montreal, Quebec, Canada. [Google Scholar]
29. Wang, T., Wu, D. J., Coates, A., Ng, A. Y. (2012). End-to-end text recognition with convolutional neural networks. International Conference on Pattern Recognition, pp. 3304–3308. Tsukuba, Japan. [Google Scholar]
30. Lee, C. Y., Osindero, S. (2016). Recursive recurrent nets with attention modeling for ocr in the wild. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2231–2239. Las Vegas, NV, USA. [Google Scholar]
31. Shi, B., Wang, X., Lyu, P., Yao, C., Bai, X. (2016). Robust scene text recognition with automatic rectification. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4168–4176. Las Vegas, NV, USA. [Google Scholar]
32. Cheng, Z., Bai, F., Xu, Y., Zheng, G., Pu, S. et al. (2017). Focusing attention: Towards accurate text recognition in natural images. Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 5086–5094. Venice, Italy. [Google Scholar]
33. Wang, T., Zhu, Y., Jin, L., Luo, C., Cai, M. (2020). Decoupled attention network for text recognition. Proceedings of the AAAI Conference on Artificial Intelligence, 34(7), 12216–12224. [Google Scholar]
34. Bengio, S., Vinyals, O., Jaitly, N., Shazeer, N. (2015). Scheduled sampling for sequence prediction with recurrent neural networks. NIPS’15: Proceedings of the 28th International Conference on Neural Information Processing Systems, 1, 1171–1179. [Google Scholar]
35. Liu, X., Zhang, T., Yu, X. (2019). An end-to-end trainable system for offline handwritten chemical formulae recognition. 15th IEEE International Conference on Document Analysis and Recognition (ICDAR), pp. 577–582. Sydney, NSW, Australia. [Google Scholar]
36. Zheng, L., Zhang, T., Yu, X. (2019). Recognition of handwritten chemical organic ring structure symbols using convolutional neural networks. 15th IEEE International Conference on Document Analysis and Recognition, Workshop on Machine Learning (ICDAR-WML), pp. 165–168. Sydney, NSW, Australia. [Google Scholar]
37. Liu, X. (2019). Comparison between CTC-based and attention-based methods for offline handwritten chemical formulae recognition (Master Thesis). [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools