
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
A Road Segmentation Model Based on Mixture of the Convolutional Neural Network and the Transformer Network
Suzhou University of Science and Technology, Suzhou, 215009, China
* Corresponding Author: Fuyuan Hu. Email:
(This article belongs to the Special Issue: Advanced Intelligent Decision and Intelligent Control with Applications in Smart City)
Computer Modeling in Engineering & Sciences 2023, 135(2), 1559-1570. https://doi.org/10.32604/cmes.2022.023217
Received 15 April 2022; Accepted 07 June 2022; Issue published 27 October 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Convolutional neural networks (CNN) based on U-shaped structures and skip connections play a pivotal role in various image segmentation tasks. Recently, Transformer starts to lead new trends in the image segmentation task. Transformer layer can construct the relationship between all pixels, and the two parties can complement each other well. On the basis of these characteristics, we try to combine Transformer pipeline and convolutional neural network pipeline to gain the advantages of both. The image is put into the U-shaped encoder-decoder architecture based on empirical combination of self-attention and convolution, in which skip connections are utilized for local-global semantic feature learning. At the same time, the image is also put into the convolutional neural network architecture. The final segmentation result will be formed by Mix block which combines both. The mixture model of the convolutional neural network and the Transformer network for road segmentation (MCTNet) can achieve effective segmentation results on KITTI dataset and Unstructured Road Scene (URS) dataset built by ourselves. Codes, self-built datasets and trainable models will be available on .Keywords
Accurate and robust road image segmentation can play a cornerstone role in computer-assisted driving and visual navigation. Due to the deep learning revolution, the segmentation accuracy has achieved impressive results.
Motivated by the successes of CNN-based classifiers [1–3] and the help of various optimization algorithms [4–6], the task of semantic segmentation overcame many difficulties. Past researchers used image patches to eliminate all the redundant computation [7]. The most famous fully convolutional networks [8] extend image-level classification to pixel-level classification. Dilated convolutions were introduced in [9] to perform multi-scale information fusion. The typical U-shaped network, U-Net [10], obtained great success in a variety of medical imaging applications. The aforementioned techniques proved the excellent learning ability of CNN.
Currently, although the CNN-based methods lead the trend in the field of image segmentation, they have more improvement space. Meanwhile, Transformer is showing revolutionary performance improvements in the CV field. In [11], vision transformer (ViT) is proposed to perform the image recognition task. Taking image patches as the input and using self-attention mechanism, ViT can even achieve better performance compared with the CNN-based methods. LeVit [12] designed a patch descriptor to improve calculation efficiency and ensured the accuracy. CaiT [13] optimized the Transformer architecture, which significantly improved the accuracy of the deep Transformer. These methods show that CV and NLP are expected to be unified under the Transformer structure, and the modeling and learning experience of the two fields can be deeply shared, thereby accelerating the progress of their respective fields.
Motivated by the Transformer’s success, we take an approach based on U-shaped encoder-decoder and design a network architecture that combining the convolutional structure and Transformer structure (MCTNet). This method performs road detection pixel-level segmentation tasks well, and the reasons are as follows:
• We propose a fusion structure, which combine the result of CNN structure and Transformer structure. This method can gather the advantage of CNN’s ability to establish the relationship between neighboring pixels and Transformer’s ability to establish the relationship between all pixels.
• We find the respective characteristics of Transformer and CNN, which Transformer focuses on the main area of the road image and CNN focus on the details of edge area. Therefore, We design a post-processing adding with prior knowledge of the road scene to deal with the results, which make the accuracy of road area a certain degree of improvement.
• We built a harder task on structured and unstructured road area detection to test our method. The dateset we built contains 2000 road scene including gravel pavement, soil-covered pavement, water-covered pavement and highways. The experimental evaluation on KITTI and URS datasets proves our model validity.
Road Detection In recent years, more and more researches on autonomous driving at home and abroad have accumulated a certain research foundation. OFA-Net [14] used a strategy called “1-N Alternation” to train the model, which can make a fusion of features from detection and segmentation data. RoadNet-RT [15] speeded up the inference time by optimizing Depthwise separable convolution and non-uniformed kernel size convolution. ALO-AVG-MM [16] extracted multiples side-outputs and used filtering to improve network performance. Volpi et al. [17] proposed a new evaluation framework for online study about segmentation.
Transformer In the field of NLP, transformer-based methods have achieved the most advanced performance in various tasks. Vision transformer (ViT) [11], which achieved an impressive speed-accuracy trade-off in image recognition tasks was motivated by the success of Transformer. Deit [18] introduced several training strategies to make ViT perform better. On the basis of these methods, Swin Transformer [19] restricted self-attention calculations to non-overlapping partial windows, while allowing cross-window connections, which brought greater efficiency and flexibility. Compared to previous work, Swin Transformer is able to significantly reduce the computation. Besides, Swin-Unet [20] based on U-net and Swin Transformer stood out from medical image segmentation tasks.
Self-Attention to Mix CNN Given the ability to leverage long-term dependence, transformers are expected to help atypical convolutional neural networks overcome their inherent shortcomings of spatial induction bias. However, most of the recently proposed Transformer-based segmentation methods only use Transformer as an auxiliary module to help encode the global context as a convolutional representation, and have not studied how to best combine self-attention (the core of Transformer) with convolution. NnFormer [21] has an interleaved architecture based on a combination of self-attention and convolution experience. Reference [22] was an interleaved architecture based on the experience of self-attention and convolution. It achieved SOTA performance on ImageNet-1k classification without bells and whistles.
For now, the study in the field of autonomous driving has achieved considerable results. The development of transformer-based methods can provide a research foundation for autonomous driving road detection. Therefore, this paper focuses on road detection tasks based on U-net, Transformer and CNN.
The overall architecture is presented on Fig. 1. Two main pipelines are trained together. The details of two pipelines are presented on Fig. 2. We follow the base of [10]. The CNN pipeline is divided into encoding block and fusion block. The backbone of CNN pipeline encoder is resnet101. The image is down-sampled by convolution, the features are mapped to different scales, and then the image is up-sampled and restored by deconvolution. The extracted context features are fused with multiscale features from encoder via fusion block to complement spatial information.
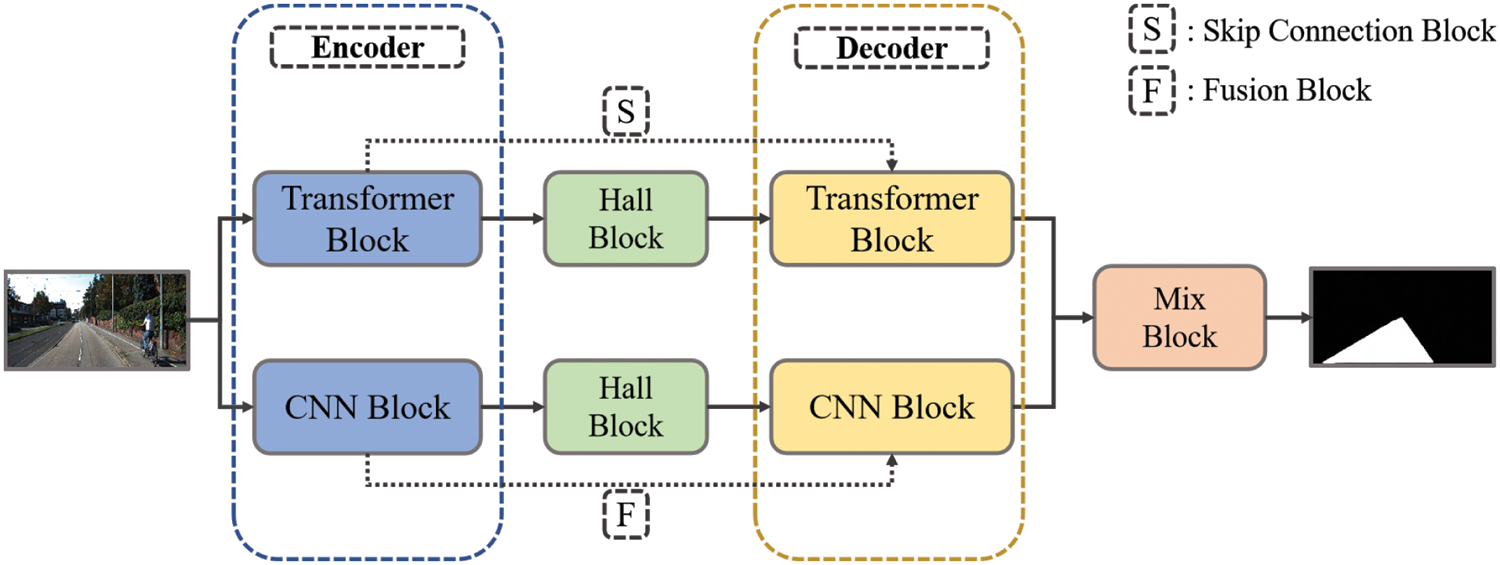
Figure 1: Network structure. The pipeline at the top is transformer-based U-net, and the pipeline at the bottom is CNN-based U-net
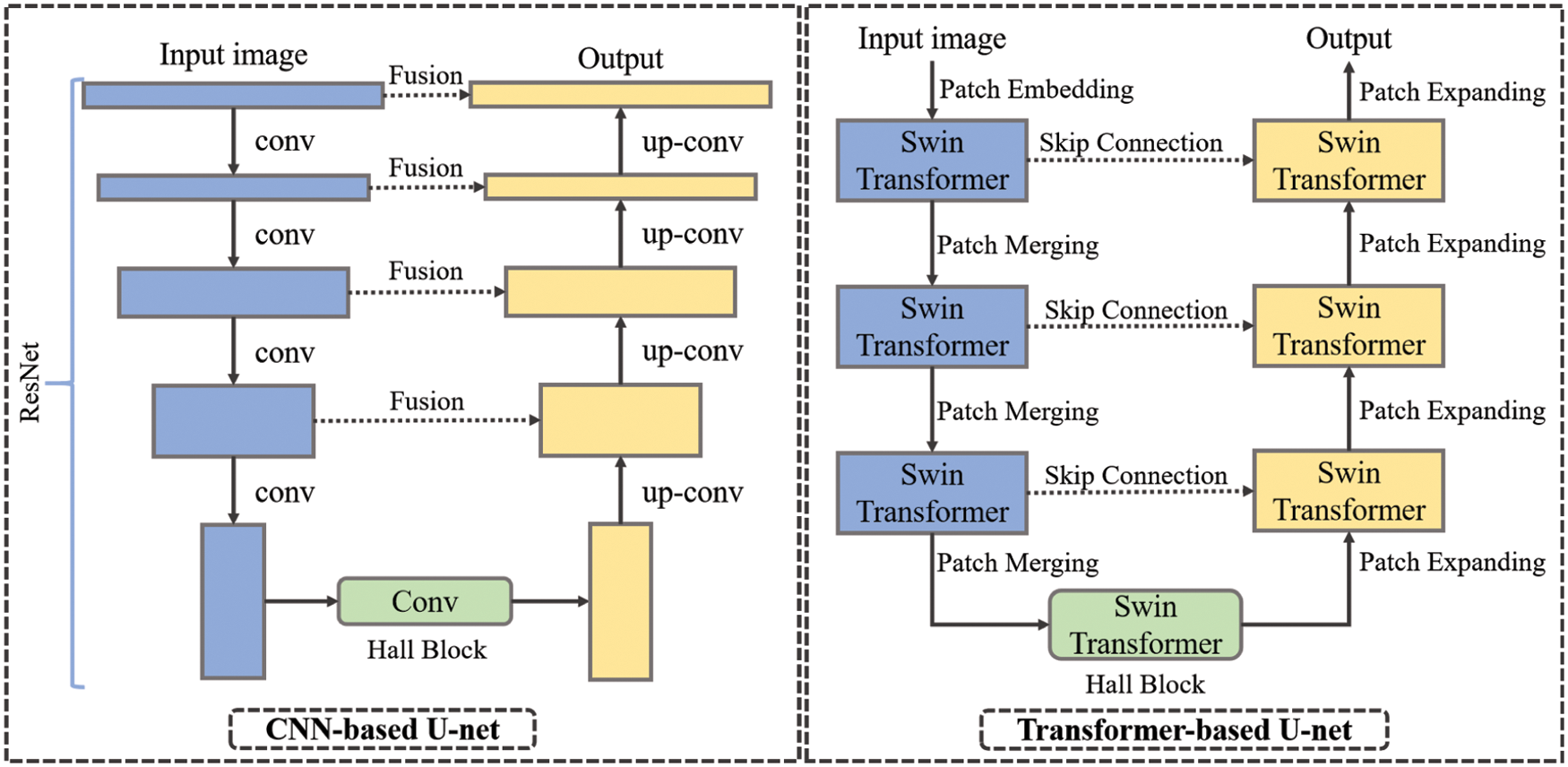
Figure 2: Details of network structure. In the section, blue rectangles indicate down-sampling process, yellow rectangles are up-sampling process, and green rectangles are hall block for deep feature representation
Our second part is based on Swin-Unet [20], which consists of encoder, hall block, decoder and skip connections. The backbone is inspired by Swin Transformer block. For the encoder, the images are split into non-overlapping patches to transform the inputs into sequence embeddings. The decoder is composed of Transformer blocks and Patch Expanding layer. The skip connections have the same function with fusion block. In contrast to patch merging layers, a patch expanding layer is designed to perform up-sampling. Then a linear projection layer is applied on these up-sampled features to output the pixel-level segmentation predictions. The output results of the two pipelines will be sent to Mix Block for further processing to obtain higher accuracy. Both the Hall Model of two pipelines are to learn the deep feature representation. The feature dimension and resolution are kept unchanged. The difference is that one uses convolution and the other uses Swin Transformer block.
The embedding block is the common patch processing method for Transformer structures. In this block, patches will be encoded as spatial information. Besides, Position embedding is able to preserve the location information of the image patches. ViT also encodes the position embedding at the input, and it is optional for Swin Transformer, because a relative position encoding is made by Swin Transformer when calculating attention. As a result, the embedding block only contains convolutional layer.
Swin transformer block is constructed based on shifted windows. In Fig. 3, two consecutive Swin transformer blocks are presented. With the shifted window partitioning approach, consecutive Swin transformer blocks are computed as:
where
where
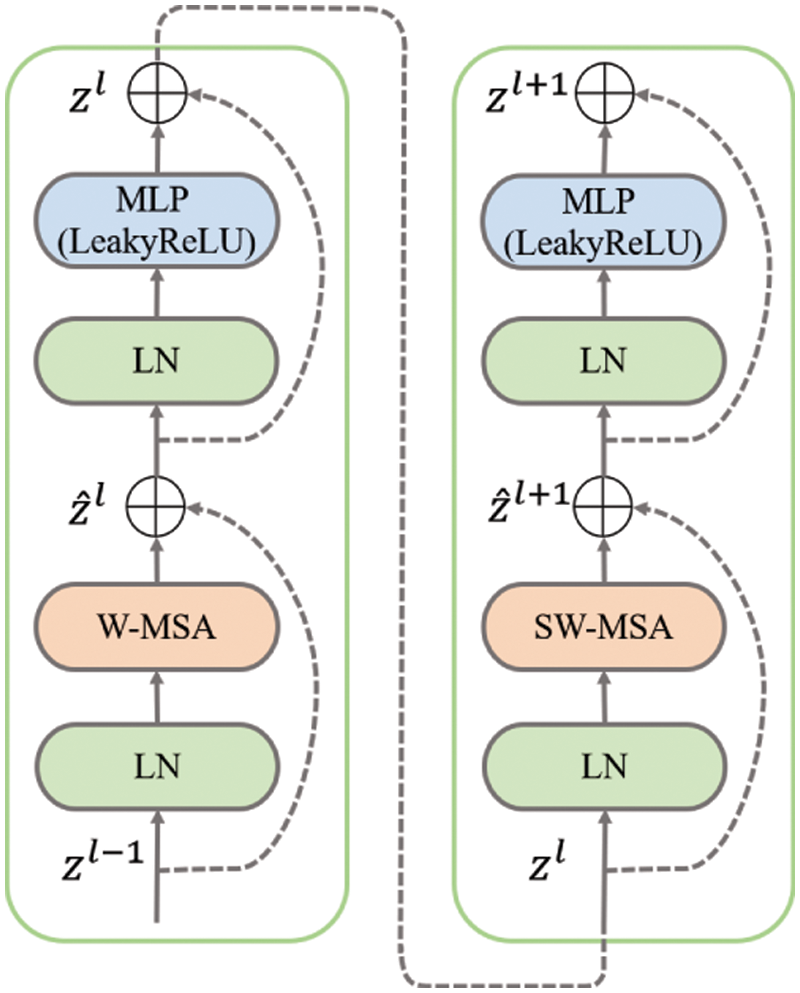
Figure 3: Transformer structure
3.4 Skip-Connection Block/Fusion Block
The fusion of deep and shallow information in FCN [8] is through the addition of corresponding pixels, we follow this method and apply it as the fusion block of CNN pipeline. U-net structure is through splicing. In the addition method, the dimension of the feature map has not changed, but each dimension contains more features. For ordinary classification tasks, which do not need to be restored from the feature map to the original resolution, this is an efficient selection; splicing retains more dimensional/location information, which allows the subsequent layers to freely choose between shallow and deep features, which benefits semantic segmentation tasks. Thus, the Skip-connection block of Transformer pipeline is depend on splicing.
As shown in Fig. 4, the Transformer pipeline focus on the main area of road detection. The results from CNN pipeline have a remarkable road edge detection effect, but it has quite a few false detection of non-road areas. Thus, we design a mix method below:

Figure 4: The results of different pipelines. The first row is the input; the second row is the result of CNN pipeline; the third row is the result of Transformer pipeline and the forth row is the result of mix block
The purpose of the above formula is to fuse two road confidence maps and enhance the pixels with similar probabilities. The first half of the formula is the general probability fusion formula, the second half adds consistency as marked in the formula (6). After the consistency item is strengthened, at any point
KITTI Dataset Our model is mainly estimated on KITTI-ROAD dataset, which includes 289 training and 290 testing structured road scenes. We split the original training set for supervised data. The new training and validation set contain 230 and 59 road scenes respectively. Ablation study is conducted on new data split. The final result comparison with other existing models is based on KITTI testing set.
URS Dataset To further verify our model efficiency, we examine the results on self-built dataset (Unstructured Road Scene dataset). As shown in Fig. 5, the dataset we built contains 2000 road images of different types containing gravel pavement, soil-covered pavement, water-covered pavement and cement pavement. These images include almost all types of roads. Unlike other open datasets, such as KITTI, this dataset contains a large number of unconventional road image, which provides more abundant and diversified challenges and tests for road segmentation tasks. Its applicable scenarios are also wider. We use 1400 images for training, 400 images for validation, and 200 images for test. The distribution of the number of image types is shown in the Table 3.

Figure 5: Different kinds of self-built dataset. The first row is the RGB image; the second row is the ground-truth
On KITTI dataset, we train two main pipelines separately. While network training, the input image size is set as 512 in both pipeline. Data augmentation is realized by rotating or cropping images.
We train MCTNet with batch size of 1 on one GPU (GeForce GTX 1080 8 GB), and use SGD optimizer with momentum = 0.9 and weight decay = 0.0005. Learning rate is set at 0.001 and decays by a factor of 10, attached every 6 epochs of 30 epochs in total. For Transformer pipeline, the stage of encoder and decoder is 4 and the number layers of them are [2,6,8,16]. In Mix block, the
On self-built dataset verification, the same network setting is utilized. In Mix block, the
For the purpose of exploring the influence of different factors on the accuracy, we conducted ablation studies on KITTI dataset. Specifically, optimizer, input sizes, and model scales are discussed below.
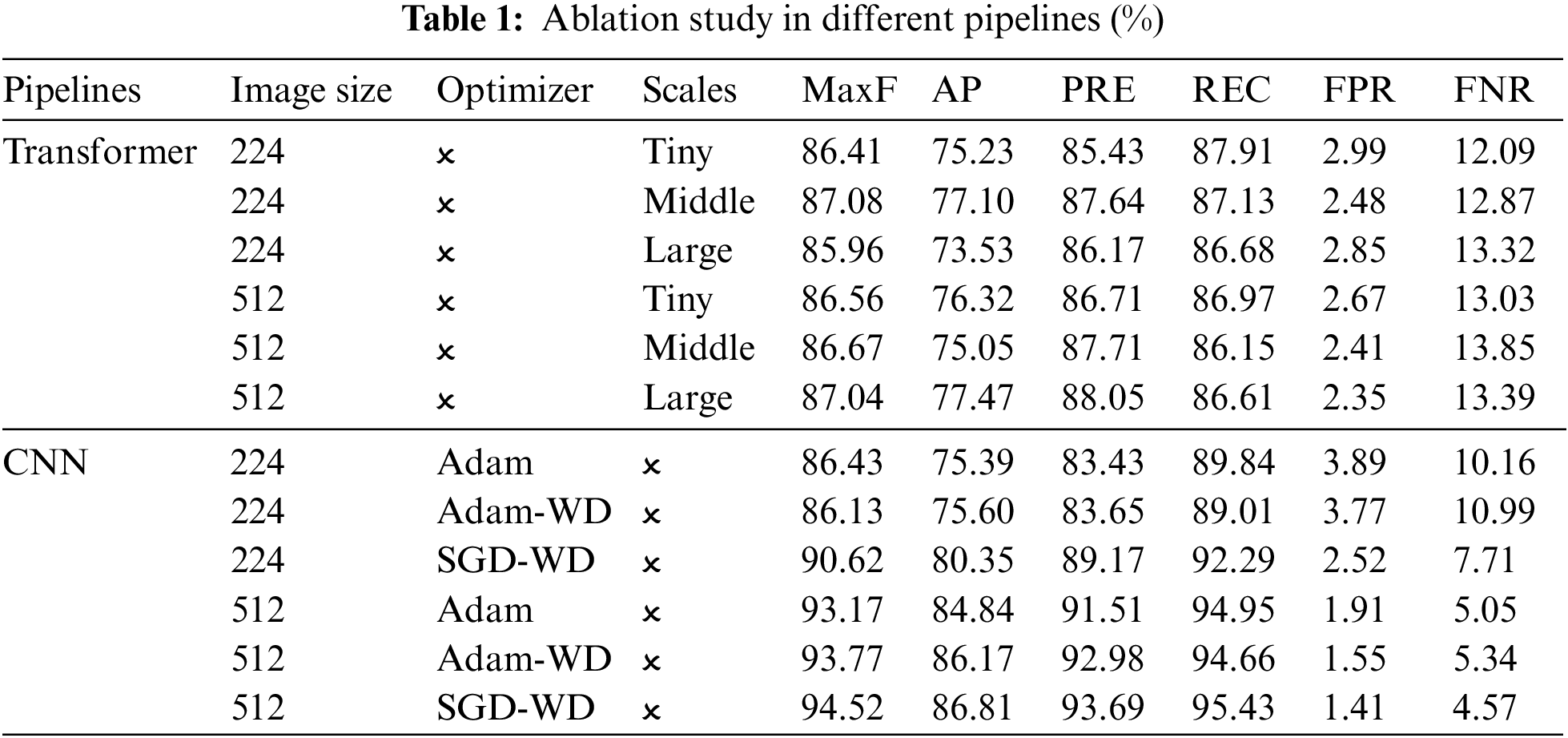
Effect of optimizers, model scales and image sizes: For CNN pipeline, we explore the effect of different optimizers and weight decay (WD). The experimental results in Table 1 indicate that the SGD combined with weight decay can obtain better segmentation accuracy. For Transformer pipeline, we discuss the effect of network deepening on model performance. Similar to [19], we try different scales of the network. It can be seen from Table 1 that increase of model scale improves the performance of the model. Considering the accuracy, we adopt the large-size model to perform road image segmentation. The testing results of the network with 224, 512 input resolutions as input are presented in Table 1. As the input size increases from 224 to 512 and the patch size remains the same as 4, the input token sequence of Transformer will become larger, and more semantic information is used to improve the ability of the Transformer pipeline. The CNN pipeline has the same effect, so the experiments in this paper use 512 resolution scale as the input.
Effect of fusion degree: The experimental results in Table 2 indicate that the results of Transformer pipeline do improve detection accuracy, although most of the effects are contributed by the CNN pipeline. The fusion degree balances the contributions of both and indicates each advantages.

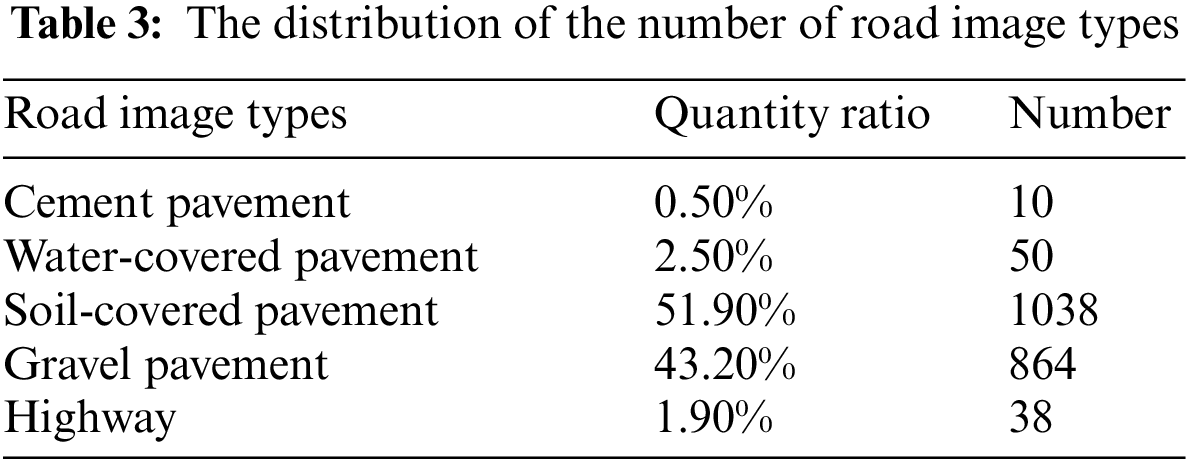
Tables 4 and 6 show the performance of our method (MCTNet) on KITTI test set, compared to other listed methods. According to Table 4, the model proposed in this chapter has obvious advantages in road segmentation compared with other models on KITTI dataset. Table 5 shows the result of mixing CNN pipeline and Transformer pipeline. It can be noted that MCTNet method is more effective because of combination of CNN and Transformer.
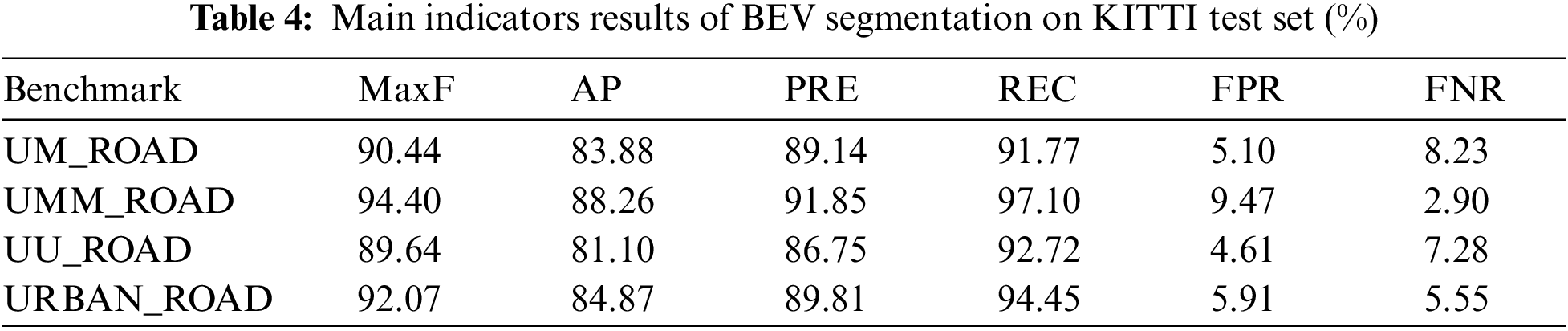

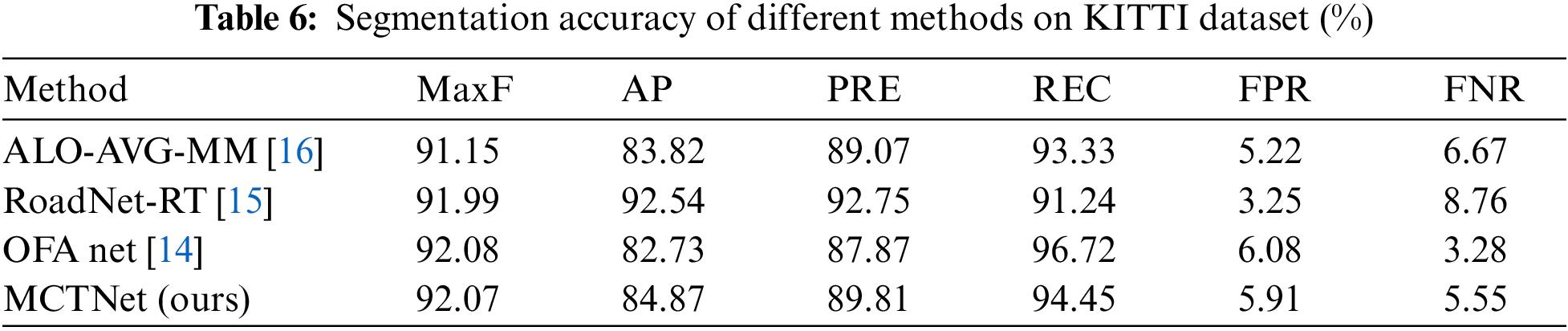
Table 7 shows the performance of our method (MCTNet) on self-built dataset. As shown in Fig. 6, the performance prove the ability of the network. Obviously, the blurred boundaries, the brightness interference of the field light, and the absence of artificial dividing lines make this task even more challenging. Table 8 shows the performance of our method and some classical segmentation models on URS dataset. Fig. 7 also shows that our method outperforms the others, and our method basically detects the main passable areas of the road. In the future, we will continue to experiment to test the effectiveness of our method and the challenge of this dataset.


Figure 6: The results of different pipelines on URS dataset. The first row is the input; the second row is the result of CNN pipeline; the third row is the result of Transformer pipeline and the forth row is the result of mix block
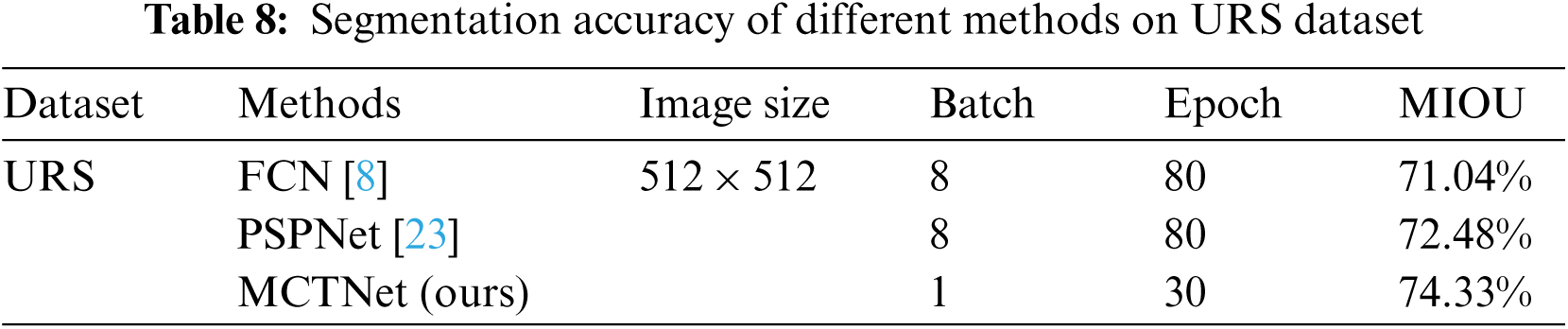

Figure 7: The results of different method on URS dataset. The first row is the input; the second row is the test result of FCN method on self-built dataset; the third row is the test result of PSPNet method on self-built dataset and the forth row is the result of our method (MCTNet)
Through the above experiments, we can naturally find that the convolution module of CNN and Swin Transformer Block have different representation effects. It is a better idea to combine them in a single network, and some researchers are already experimenting with it, such as [21]. We have tried to make the convolutional layer and Swin Transformer Block appear in the network at the same time, but we have not obtained excellent results for the time being. We will continue to explore their potentiality for road segmentation tasks.
We present a mix method of CNN and Transformer for road segmentation and achieve high performance on KITTI and self-built datasets. The method make full use of the CNN’s performance and Transformer’s advantages in the road segmentation task. To meet the demand of autonomous driving, a post-processing adding with prior knowledge of the road scene is also vital. Besides, the Unstructured Road Scene dataset we built shows us a unique road segmentation task scene, which brings diversity and applicability. With regard to future research, we will investigate more methods of combining CNN and Transformer for better performance.
Funding Statement: This work is supported by the Postgraduate Research & Practice Innovation Program of Jiangsu Province (SJCX21_1427) and General Program of Natural Science Research in Jiangsu Universities (21KJB520019).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Badrinarayanan, V., Kendall, A., Cipolla, R. (2017). Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12), 2481–2495. DOI 10.1109/TPAMI.34. [Google Scholar] [CrossRef]
2. Noh, H., Hong, S., Han, B. (2015). Learning deconvolution network for semantic segmentation. Proceedings of the IEEE International Conference on Computer Vision, pp. 1520–1528. Santiago. [Google Scholar]
3. Papandreou, G., Chen, L., Murphy, K., Yuille, A. (2015). Weakly-and semi-supervised learning of a DCNN for semantic image segmentation. arXiv preprint arXiv:1502.02734. [Google Scholar]
4. Wu, Z., Jiang, B., Karimi, H. R. (2020). A logarithmic descent direction algorithm for the quadratic knapsack problem. Applied Mathematics and Computation, 369, 124854. DOI 10.1016/j.amc.2019.124854. [Google Scholar] [CrossRef]
5. Wu, Z., Karimi, H. R., Dang, C. (2019). An approximation algorithm for graph partitioning via deterministic annealing neural network. Neural Networks, 117, 191–200. DOI 10.1016/j.neunet.2019.05.010. [Google Scholar] [CrossRef]
6. Wu, Z., Karimi, H. R., Dang, C. (2019). A deterministic annealing neural network algorithm for the minimum concave cost transportation problem. IEEE Transactions on Neural Networks and Learning Systems, 31(10), 4354–4366. DOI 10.1109/TNNLS.5962385. [Google Scholar] [CrossRef]
7. Li, H., Zhao, R., Wang, X. (2014). Highly efficient forward and backward propagation of convolutional neural networks for pixelwise classification. arXiv preprint arXiv:1412.4526. [Google Scholar]
8. Long, J., Shelhamer, E., Darrell, T. (2015). Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3431–3440. Boston. [Google Scholar]
9. Yu, F., Koltun, V. (2015). Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122. [Google Scholar]
10. Ronneberger, O., Fischer, P., Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. International Conference on Medical Image Computing and Computer-assisted Intervention, pp. 234–241. Munich, Springer. [Google Scholar]
11. Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X. et al. (2020). An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929. [Google Scholar]
12. Graham, B., El-Nouby, A., Touvron, H., Stock, P., Joulin, A. et al. (2021). Levit: A vision transformer in convnet’s clothing for faster inference. arXiv preprint arXiv:2104.01136. [Google Scholar]
13. Touvron, H., Cord, M., Sablayrolles, A., Synnaeve, G., Jégou, H. (2021). Going deeper with image transformers. arXiv preprint arXiv:2103.17239. [Google Scholar]
14. Zhang, S., Zhang, Z., Sun, L., Qin, W. (2020). One for all: A mutual enhancement method for object detection and semantic segmentation. Applied Sciences, 10(1), 13. DOI 10.3390/app10010013. [Google Scholar] [CrossRef]
15. Bai, L., Lyu, Y., Huang, X. (2020). Roadnet-RT: High throughput CNN architecture and SOC design for real-time road segmentation. IEEE Transactions on Circuits and Systems I: Regular Papers, 68(2), 704–714. DOI 10.1109/TCSI.8919. [Google Scholar] [CrossRef]
16. Reis, F. A., Almeida, R., Kijak, E., Malinowski, S., Guimarães, S. J. F. et al. (2019). Combining convolutional side-outputs for road image segmentation. 2019 International Joint Conference on Neural Networks (IJCNN), pp. 1–8. Budapest. [Google Scholar]
17. Volpi, R., de Jorge, P., Larlus, D., Csurka, G. (2022). On the road to online adaptation for semantic image segmentation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 19184–19195. New Orleans. [Google Scholar]
18. Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A. et al. (2021). Training data-efficient image transformers & distillation through attention. International Conference on Machine Learning, pp. 10347–10357. Vienna, PMLR. [Google Scholar]
19. Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y. et al. (2021). Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030. [Google Scholar]
20. Cao, H., Wang, Y., Chen, J., Jiang, D., Zhang, X. et al. (2021). Swin-Unet: Unet-like pure transformer for medical image segmentation. arXiv preprint arXiv:2105.05537. [Google Scholar]
21. Zhou, H. Y., Guo, J., Zhang, Y., Yu, L., Wang, L. et al. (2021). Nnformer: Interleaved transformer for volumetric segmentation. arXiv preprint arXiv:2109.03201. [Google Scholar]
22. Zhao, Y., Wang, G., Tang, C., Luo, C., Zeng, W. et al. (2021). A battle of network structures: An empirical study of cnn, transformer, and mlp. arXiv preprint arXiv:2108.13002. [Google Scholar]
23. Zhao, H., Shi, J., Qi, X., Wang, X., Jia, J. (2017). Pyramid scene parsing network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2881–2890. Honolulu. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools