
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

An Edge-Fog-Cloud Computing-Based Digital Twin Model for Prognostics Health Management of Process Manufacturing Systems
1 College of Mechanical Engineering, Donghua University, Shanghai, 201620, China
2 Institute of Artificial Intelligence, Donghua University, Shanghai, 201620, China
3 School of Mechanical Engineering, Shanghai Jiao Tong University, Shanghai, 200240, China
4 Beijing Chonglee Machinery Engineering Co., Ltd., Beijing, 101111, China
* Corresponding Author: Jie Zhang. Email:
(This article belongs to the Special Issue: Computing Methods for Industrial Artificial Intelligence)
Computer Modeling in Engineering & Sciences 2023, 135(1), 599-618. https://doi.org/10.32604/cmes.2022.022415
Received 09 March 2022; Accepted 20 May 2022; Issue published 29 September 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The prognostics health management (PHM) from the systematic view is critical to the healthy continuous operation of process manufacturing systems (PMS), with different kinds of dynamic interference events. This paper proposes a three leveled digital twin model for the systematic PHM of PMSs. The unit-leveled digital twin model of each basic device unit of PMSs is constructed based on edge computing, which can provide real-time monitoring and analysis of the device status. The station-leveled digital twin models in the PMSs are designed to optimize and control the process parameters, which are deployed for the manufacturing execution on the fog server. The shop-leveled digital twin maintenance model is designed for production planning, which gives production instructions from the private industrial cloud server. To cope with the dynamic disturbances of a PMS, a big data-driven framework is proposed to control the three-level digital twin models, which contains indicator prediction, influence evaluation, and decision-making. Finally, a case study with a real chemical fiber system is introduced to illustrate the effectiveness of the digital twin model with edge-fog-cloud computing for the systematic PHM of PMSs. The result demonstrates that the three-leveled digital twin model for the systematic PHM in PMSs works well in the system's respects.Keywords
Process manufacturing system (PMS) is a manufacturing system (MS) to conduct the transformation of materials’ physical status and chemical reaction, which is featured by continuous, dynamic, and complicated process recipes [1]. In PMSs, the system efficiency and stability are widely influenced by dynamic disturbances [2], including equipment faults, shortage of materials, rush jobs, environmental influence, etc. To maintain the continuous running of the PMS, prognostics health management (PHM) overcomes the disturbances from dynamic events in advance is a critical issue [3,4]. Different from the PHM of individual equipment, the PHM of PMSs should be considered from the view of system science to keep the continuous, dynamic, and complicated production. Therefore, it is an urgent need to form a new model of comprehensively systematic solution of PHM in PMSs.
In PHM of PMSs, turbulent and uncertain dynamic events in the production process emerging to be challenging, which can be categorized into three types:
(a) Frequently occurred dynamic disturbance events
Frequently occurring dynamic disturbance events will seriously affect the PHM of PMSs. Dynamic disturbance events of manufacturing systems (MS) include resource-related dynamic events, job-related dynamic events, and environment-related dynamic events. Resource-related dynamic events contain fault of equipment used in production and fault of jigs [5]. For the system-leveled PHM, it is necessary to apply a variety of failure prediction methods to deal with multi-part faults. This is a challenge for current empirical knowledge by skilled workers. These faults will directly affect the early replacement and maintenance of equipment parts. Typical job-related dynamic events include rush jobs, job cancellations, delays in processing, poor quality of jobs, and delays in material arrival. Though these events occur less frequently than equipment faults, the uncertainty of their occurrence will directly affect the generation of strategies. At present, there is no better method to effectively predict such dynamic events. Environment-related dynamic events contain temperature and humidity changes, airflow changes, and transportation equipment vibrations. These dynamic events occur every few days on average. Due to differences in equipment distribution areas in the workshop, the analysis by some simple environmental parameters is insufficient. Moreover, the prediction results of various dynamic events will directly affect the analysis and decision-making of PHM. So, it is urgent to effectively predict dynamic events.
(b) The impact evaluation of dynamic disturbance events
Due to the difference in the scope and degree of influence of different dynamic events on the system, it is difficult to comprehensively evaluate the impact. The difference in the impact range is manifested in the different dynamic events at different times and locations. From the perspective of system-leveled PHM, measures are taken to prepare spare parts or adjust the production plan, which is relatively different. The difference in the degree of impact is reflected by the same dynamic event on the system at different stages. For example, the early failure of the bearing may have minimal impact on a single device. But a serious failure of the bearing will cause the equipment to be damaged. This, in turn, affects the downstream production process of the equipment. Early failure of a single device can make maintenance decisions before the end of the remaining useful life. Once it affects downstream production, it will inevitably generate more demand for production regulation. In addition, because PHM is oriented to the entire PMS, evaluating the impact is a system-leveled PHM analysis process to better optimize decision-making. Therefore, it is urgent to effectively evaluate the impact of dynamic events in PMSs.
(c) The optimal coping strategy of dynamic disturbance events
The optimal coping strategy should be regulated timely to cope with the change of material in real-time in a PMS. However, the real-time optimization of production maintenance strategy remains to be a challenge since the big solution space and complicated constraints. The big solution space is mainly manifested in the greater computation time for all equipment fault predictions and evaluations. The predictions and evaluations in a PMS require massive amounts of data and customized models, which makes the PMS-leveled PHM time-consumed. The complicated constraints contain continuity of the PMS, multiple sub-processes, and time differences between different sub-processes. Continuity means that process production usually does not stop, which puts forward higher real-time requirements for restraining the impact. The PHM of multiple sub-processes needs to be uniformly scheduled according to the time difference to make them cooperate with each other. In summary, it is urgent to establish a PHM solution that can efficiently deal with the optimal coping strategy in PMS.
The digital twin is a novel mapping system between virtual space and physical space, which utilizes data to simulate the behavior in the real world [6]. It contains the function of virtual and actual interactive feedback, data fusion analysis, and decision-making interaction optimization, which is expected to become a new model for PHM. The advantages of using digital twin in PHM for PMS are described as follows:
• The digital twin provides an algorithm container for dynamic event prediction. Multi-source data collected by various sensors build analysis models for different needs in the digital twin space, which generate a library of various algorithms. It greatly increases the demand for forecasting different dynamic disturbance events.
• The digital twin responds to different impact evaluation needs and provides differentiated virtual spaces in different scenarios. Because digital twins can be built on devices based on different sizes and different functions. The differentiated virtual space can be analyzed in terms of breadth or depth to realize the evaluation of the different scope and degree of the impact on the system.
• The digital twin can provide an edge-fog-cloud fusion simulation environment. The synergistic effect of different levels of digital twins can cope with the difficulties of calculation time and complex constraints. It facilitates real-time decision-making of PHM in PMS.
In conclusion, the PHM of PMS based on the digital twin is forward-looking, dynamic, controllable, and of great significance. Facing the three difficulties of PHM in PMS, this paper proposes a new model of PHM in PMS based on digital twin, which is applied in a chemical fiber production system.
The subsequent section provides a detailed literature review and draws some conclusions. The proposed digital twin model for PHM on PMS is introduced in Section 3. Section 4 presents a big data-driven digital twin model for the PHM of PMSs process. Section 5 describes an example of maintenance for a chemical fiber production system, which verifies the effectiveness of the proposed new PHM model.
At present, the research and application of predictive maintenance for PMS are still in their infancy. Most predictive maintenance methods come from the equipment fault diagnosis, fault prediction, and maintenance of the discrete equipment manufacturing industry. Given the difficulties in the maintenance of process industry equipment and the trend of digital twin-based PHM, a review is made from three aspects: fault prediction, fault impact, and system maintenance.
(1) traditional PHM methods
(a) failure prediction methods of equipment
The failure prediction methods of equipment can be divided into three categories: The method based on reliability statistical probability, the method based on physical models, the data-driven method. (1) The method based on reliability statistical probability uses the statistical characteristics of historical failure information to predict faults. For example, Zhou et al. [7] proposed a recursive method of mixed hazard rate based on life attenuation factor and hazard rate increase factor, which relies on a reliability-centered sequential predictive model. Li et al. [8] proposed a new reliability predictive maintenance optimization model, which planned the optimal promotion measures for the system under consideration of the given required parameters. Shimada et al. [9] proposed a method of using practical data to extract characteristic indicators from the cumulative failure probability distribution to determine the priority order of equipment maintenance. (2) The method based on the physical model uses the internal working mechanism of the equipment to establish a mathematical model that reflects the physical law of equipment performance degradation. It can obtain prediction results by setting boundary conditions and system input parameters to solve mathematical models. For example, Boshnakov et al. [10] proposed a physical model-based diagnosis and prediction method for the state of metallurgical equipment. Iung et al. [11] proposed an effective degradation model that comprehensively considers operating conditions, health monitoring, and maintenance behaviors, which is based on the discrete state and cumulative continuous state of the equipment degradation level. Lei et al. [12] proposed a weighted minimum quantitative error health index, which realized the fusion of interactive information from multiple features, and correlated with the degradation process of the equipment. It uses maximum likelihood estimation to initialize the model parameters, and then uses the particle filter method to predict the remaining service life of the equipment [13]. (3) The method based on data-driven is to collect condition monitoring data from operating equipment, without establishing an accurate mathematical model of equipment failure evolution of life degradation. For example, Liao et al. [14] used a data-driven method to evaluate the health status of equipment and predict the performance degradation process, which determines the maintenance threshold and maintenance cycle of equipment. Daily et al. [15] used big data analysis methods to achieve predictive maintenance of complex equipment. Verhagen et al. [16] used big data analysis to determine the operating factors that have an impact on the failure rate. Baptsta et al. [17] used the ARMA model to predict the fault time of components and systems, and take maintenance measures. Convolutional Neural Network (CNN) has been widely applied in the research of smart fault classification [18,19], but the learning rate is a challenge to recognize the fault equipment. Wen et al. [20,21] proposed a novel learning rate scheduler based on reinforcement learning for convolutional neural network (RL-CNN) and promote it with automatic learning rate scheduler (AutoLR-CNN) method for fault detection. Several results show that these proposed methods achieved state-of-the-art performance in fault classification.
However, the reliably statistical probability method requires numerous experiments and a long time data records, which are not suitable for multiple parts, expensive prices, and poor anti-interference systems. The method based on the physical model requires that the assumed operating conditions are strictly consistent with the actual operating conditions. However, the actual working conditions often change, leading to inconsistencies in the prediction model during the useful life. Most data-driven models do not take the actual physical characteristics and differences of electromechanical equipment into account. It is difficult to adapt to the different problems of equipment failures if the PHM of different systems adopts undifferentiated data processing and analysis. In summary, the above three failure prediction methods all have their drawbacks.
(b) fault impact evaluation methods
Fault impact evaluation is also regarded as fault risk assessment, which is mainly divided into three categories: Failure mode and impact analysis, Fault tree analysis (FTA), and Markov analysis. (1) Failure mode and impact analysis are to use the top-down sequence to establish the relationship among the object, failure mode, and consequences of the failure. Afterward, the risk assessment is carried out based on the expert assessment results. In this method, the Risk Priority Number (RPN) quantifies the degree of risk of different failure modes. For example, Yang et al. [22] established an if-then rule base and SOD three-parameter evaluation method to evaluate the equipment failure risk. Gargama et al. [23] combined data envelopment analysis and failure mode impact to reduce the impact of subjective factors in the evaluation process. Mandal et al. [24] proposed a method of merging similar failure modes according to the similarity of the degree of danger, and adopt the same failure mode impact analysis for the merged group with a high degree of danger. (2) FTA uses graphical modeling methods to perform logical reasoning analysis to determine the cause of the failure with the frequency of occurrence. For example, Pande et al. [25] obtained the minimum segmentation set of the fault tree to perform the fault risk assessment. Garrick [26] used Monte Carlo simulation method to calculate the unreliability of the system, which was combined with the fault tree to carry out the fault risk assessment [26]. (3) Markov analysis expresses the maintenance status of the system through a series of random variables and the relationship between them. For example, Su et al. [27] introduced the economics of the full life cycle of a multi-state system into reliability calculations to find the lowest cost in the maintenance cycle. Soro et al. considered the impact of minimal repair, imperfect repair, and perfect repair on system performance, and propose a corresponding preventive maintenance Markov model. It evaluates the dynamic performance of a multi-stage degraded repairable system through the calculation of availability and productivity [28]. Ruiz-castro [29] applied the Markov counting process to analyze the performance of the system undergoing irregular inspections, which realizes the risk assessment of the system.
However, there are still shortcomings in the above risk evaluation methods, such as time-consuming analysis of failure modes and effects, insufficient analysis of the importance of parameters, etc. Fault tree analysis uses a dual reliability model to judge the state of the analysis object. However, for a complex system with multiple states, it is necessary to repeatedly build a tree, which prolongs the calculation time. And as the number of components and the complexity between components continues to increase, the failure of complex systems often has complex dynamic characteristics related to time and sequence. When using the Markov model for risk assessment, most assume that the probability of state change is fixed, and it is necessary to acknowledge the various probabilities of state change. The accuracy of the system for missing information is not high enough, so it is not suitable for medium and long-term assessment of system risks.
(c) impact evaluation strategies
The methods for dealing with the impact of interference events on equipment are divided into active maintenance methods and reactive maintenance methods, according to the non-occurrence of interference and the occurrence of interference. Active maintenance can tolerate interference events to a certain extent by extracting predictive knowledge from historical data. It can be divided into methods of semi-online methods [30,31], near-online methods [32], and forward-looking methods [33]. Reactive maintenance is defined by Kerr in the literature as “real-time and continuous adjustment of the schedule to keep it consistent with ongoing and unexpected events” [34]. Han et al. [35] proposed a single-machine and parallel-machine online scheduling algorithm based on mathematical programming, which can propose optimization methods in a short time without pre-collecting information, and provide maintenance solutions. In recent years, Metaheuristic algorithms have attracted the attention of researchers. But it is easy to fall into local optimum when searching for the optimal solution. Fan et al. [36] proposed a grey wolf optimizer (GWO) to lead to locally optimal situations. Besides, he put forward a logistic opposition-based learning (LOBL) mechanism and self-adaptive updating methods, which further improve the optimization solution [37].
Although proactive maintenance can reduce the probability of system interruption, it cannot cope with the impact of sudden changes such as production changes or process route changes. Due to the frequent dynamic interference events caused by mass customization production, the reactive maintenance capabilities are far from enough. Wang, et al. proposed a novel resilient scheduling paradigm in flexible scheduling [38], which can be understood as flexible operation and maintenance: Recover the loss of system performance caused by large-scale dynamic events by adjusting the processing sequence. However, due to the particularity of the process industry, the flexible operation and maintenance focus on the recovery operation after the disturbance event occurs. It needs to be able to make the recovery time shorter and the recovery performance better. Therefore, it is necessary to explore new methods of PHM in PMS from a new perspective.
(2) digital-twin-based PHM methods
In recent years, some scholars have tried the application of digital twin in PHM. Luo et al. [39] proposed a hybrid approach driven by digital twin, which is used in cutting tool life prediction with DT model-based and DT data-driven hybrid. However, it is used only in RUL prediction without considering the systematic PHM. Li et al. [40] used the concept of dynamic Bayesian networks to build a health monitoring model for the diagnosis and prognosis of each individual aircraft in digital twin. Though it emphasizes the variability of the parameters of each individual in the system, it does not highlight the correlation of the various components in the system. Michael Grieves and John Vickers give some overview examples from the perspective that digital twins should solve the connectivity barriers of information islands in complex systems, the difficulties of understanding the physical world and the construction of virtual models, and a large number of states [41]. But examples of PHM in PMSs are not given. Tao et al. [42] proposed a five-dimension digital twin model making effective use of the interaction mechanism and fused data of digital twin. But the application object of the example is conducted on a small scale, which cannot fully represent the PHM in PMS.
Through the above current research on the application of digital twin technology in PHM, it can be found that PHM based on digital twin has advantages and can deal with the problem of narrow coverage of traditional PHM. There are still two main problems. First, the application object with digital twin is relatively small, and it usually does not involve the continuous production workshop at the system level. Second, the application objects often do not analyze the interaction between various parts, and the operation and maintenance are relatively isolated. Therefore, it is imperative to establish an all-around digital twin system of PMSs that can integrate fault prediction, impact assessment, and equipment maintenance functions.
3 DTPHM-PMS: Digital Twin Model for PHM on PMS
In PMSs, impact ranges of dynamic disturbance events can be divided into system-level impact, regional-level impact, and unit-level impact. To cope with the dynamic disturbances with impacts in different scales, this section designs a three-layered hierarchical digital twin model to optimize the PMS, as shown in Fig. 1. The three layers are unit-level digital twin PHM based on edge computing, station-level digital twin PHM based on fog computing, shop-level digital twin PHM based on cloud computing.
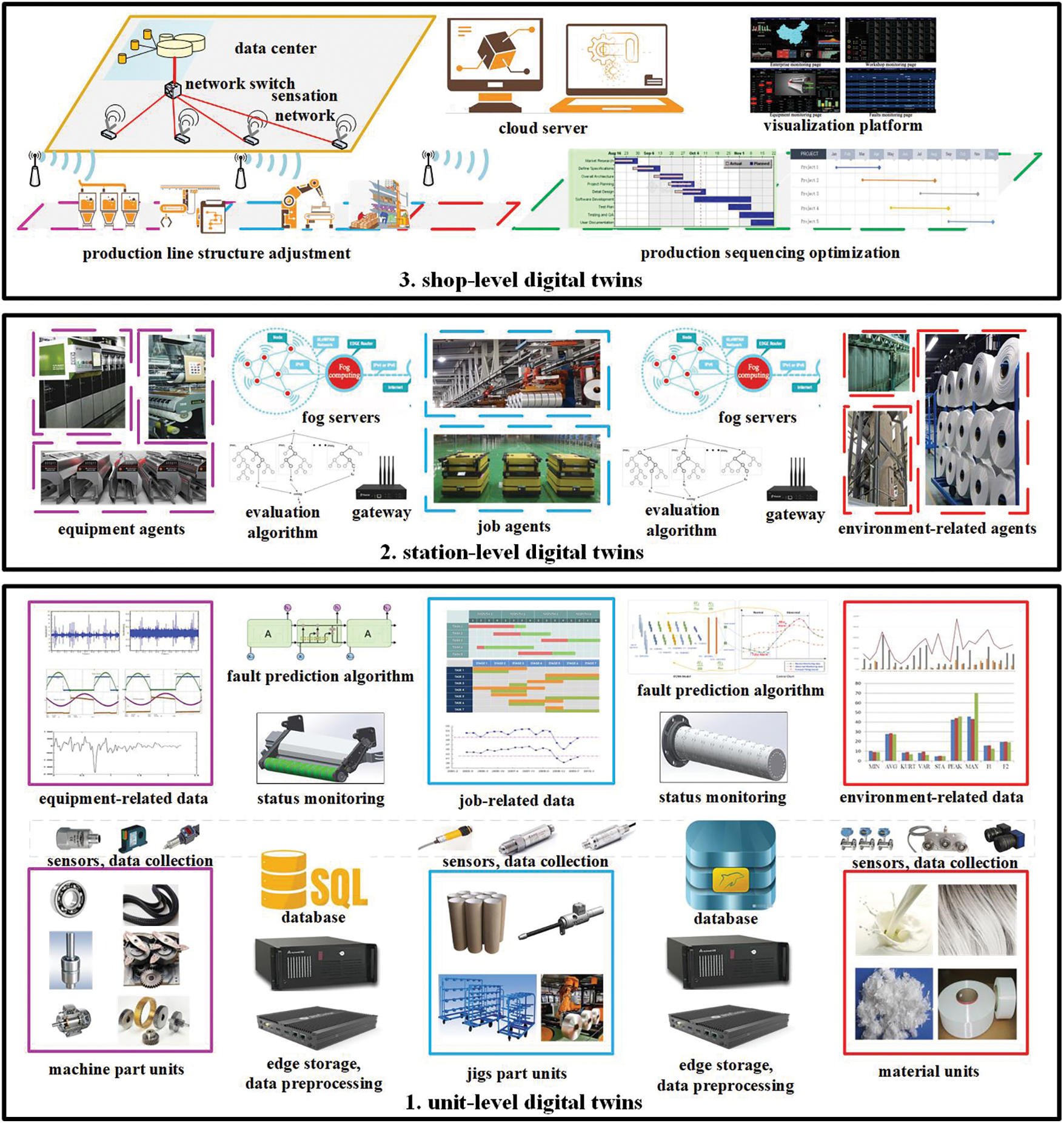
Figure 1: Structure of DTPHM-PMS
3.1 The Unit-Level Digital Twin Maintenance Model Based on Edge Computing
The unit-level digital twin operation and maintenance models (ULDT) are created to deal with the unit-level impact events, which include an exception, breakdown, shutdown of equipment, etc. Owing to the continuous production demand in PMSs, the unit level impact should be processed timely. The ULDTs are embedded in edge computing devices near the equipment to deal with the events in real-time. This section constructs the data model and operation process of ULDTs as follows:
The data in ULDT contains equipment-related data, job-related data, and environment-related data.
• Equipment-related data includes speed, current, voltage, vibration acceleration, displacement, movement, etc.
• Job-related data mainly comes from dynamic data in the MES system, including material quantity, flow rate, density, pressure, etc.
• Environment-related data can be temperature, humidity, wind speed, air pressure and so on.
The operation processes of the ULDT can be divided into these steps: data collection, data preprocessing, status monitoring, and fault prediction.
• Data collection uses sensors to collect rotation speed, current, voltage, vibration, displacement, movement, and other signals of the equipment.
• Data preprocessing refers to the process of reviewing, filtering, and sorting the collected data before analysis, including data cleaning, data integration, data transformation, and data specification.
• Status monitoring is considered to achieve the purpose of judging the health of the equipment by monitoring various parameters during the operation of the device.
• Fault prediction can be defined as predicting the failure of equipment components in advance and accurately judging the type of failure.
3.2 The Station-Level Digital Twin Maintenance Model Based on Fog Computing
The station-level digital twin operation and maintenance models (STLDT) are built to dispose of the impact of dynamic disturbances on the regional level. The STLDTs are deployed in fog computing servers to make control and adjustment effective on the regional level, since the STLDT communicates with several edge-computing agents. During the operation of STLDT, the edge-computing agents for PHM of equipment and regulation of production process are cooperated to adjust equipment, materials, environmental factors, and operators to cope with dynamic disturbances. For example, when a fault of equipment is predicted to occur in the future on an edge device, the message is sent to the regional computing server by fog networks. The regional server is possible to reduce the speed of the next batch of production equipment and the flow rate of materials. The production time of the original product can be increased in other production lines. For possible faults of equipment, corresponding spare parts and maintenance operators shall be added in advance. These control and adjustment should be arranged before the end of current production, which has little impact on the overall process.
3.3 The Shop-Level Digital Twin Maintenance Model Based on Cloud Computing
The shop-level digital twin operation and maintenance model (SHLDT) is constructed to deal with the dynamic events with system-level impact. This SHLDT optimizes the manufacturing systems by reconfiguring the whole system from both the production line structure adjustment and production sequencing optimization. Production line structure adjustment refers to adjusting the equipment in different regions with capacity demand and repairing or replacing parts according to the forecasting result. It can leave enough time to change the production plan in advance. Production sequencing optimization is considered to rearrange the remaining production plans on the basis of the adjusted production line structure. Cloud computing can provide computing services, allocate resources, and arrange sequences for multiple shop-level impact assessments and multiple unit-level faults predictions. For example, when part of the production line shuts down, or the product type needs to be changed, the SHLDT is supposed to make decisions to activate the backup production line to share the pressure caused by the sudden increase in production tasks. Then, the SHLDT re-optimizes the remaining production tasks based on the adjusted production line structure to minimize the impact of disturbance on system-level production. The SHLDT communicates with the fog-computing agents to integrate different stations to form a whole group to achieve the optimization of whole manufacturing systems. Hence, the SHLDT is deployed in cloud computing servers on the system level.
4 Big Data-Driven Operation Method of DTPHM-PMS
Big data technology is the core of the construction and operation of digital twin model, which supports the skeleton of the DTPHM-PMS. With the continuous operation of PMS, equipment, sensors, and system platforms produce numerous manufacturing process data [43]. By integrating multi-source data and using multiple algorithms to quickly analyze requirements, big data technology can accurately predict disturbing events. It can help people to understand the objective laws and make scientific decisions. Big data technology provides a systematic solution to deal with the impact of dynamic events. It finds an appropriate optimization scheme to reduce the loss of manufacturing systems and improve overall efficiency. The logical framework of DTSPM driven by big data is shown in Fig. 2. It includes three parts, indicator prediction, influence evaluation, and intelligent decision-making.
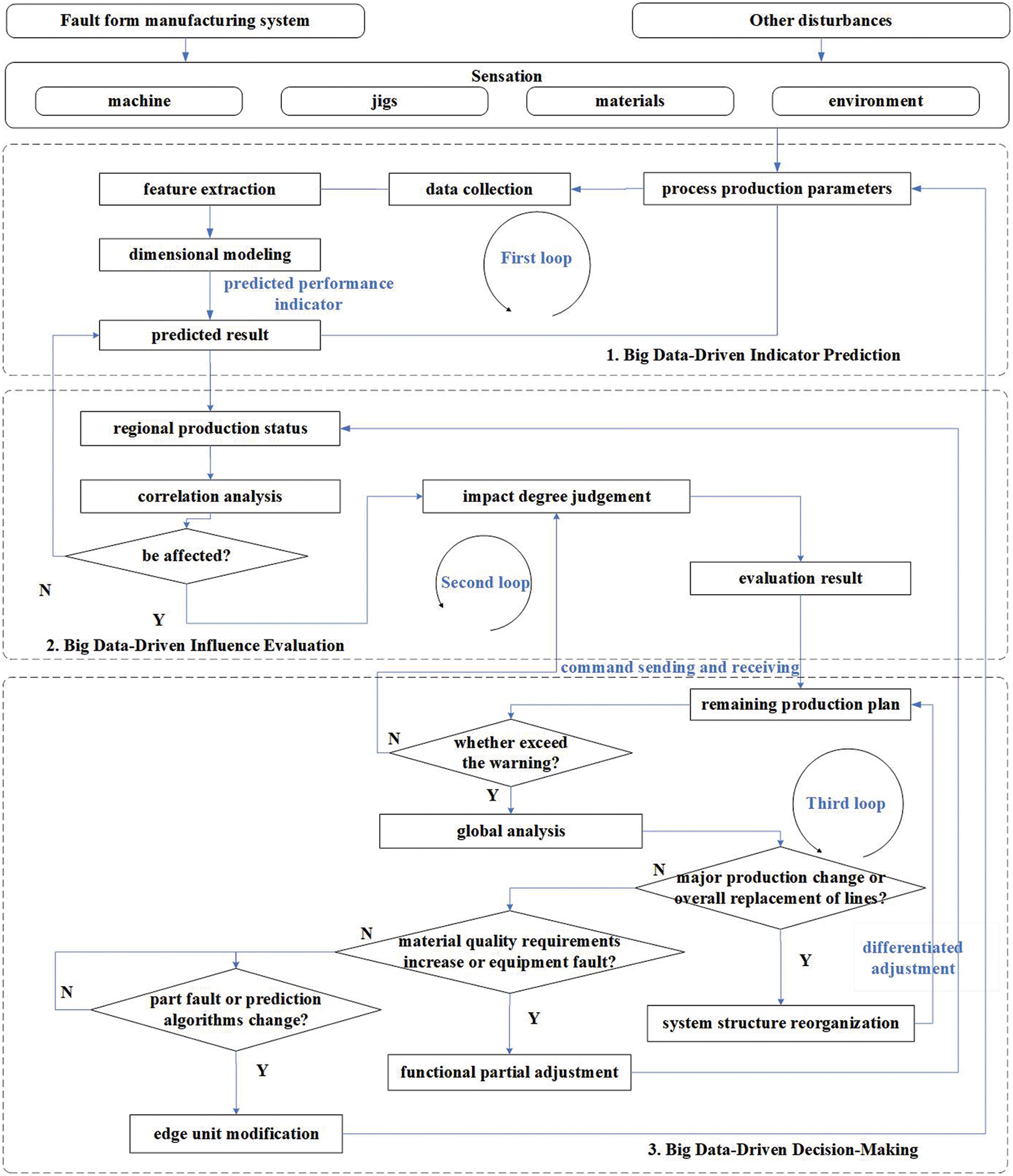
Figure 2: The process of big data-driven DTPHM-PMS
4.1 Big Data-Driven Indicator Prediction
Big data-driven indicator prediction is conducive to accurate prediction of dynamic disturbance events that may occur during process production. This section contains data collection, feature extraction, dimensional modeling, and result prediction. As described in 3.1, data collection uses a variety of sensors at edge devices to collect equipment status, material quantity, and environmental parameters during the production process. Feature extraction is to extract the common parts from integrated data of abnormal objects that are different from normal objects through empirical or intelligent methods. Sometimes according to the complexity of the actual object, the extracted features need to be fused. Dimensional modeling designs algorithms to extract characteristics of the equipment degradation process. Result prediction is to use the established model to predict unknown abnormal conditions and possible disturbances of the object. For example, at the edge device, data on the operation of equipment for at least one year is usually collected. Combining mechanical structure, mechanics, or dynamics models, and compared data forms, the specific part of abnormal equipment data can be extracted to form a feature set. Then, statistical methods, expert systems, artificial intelligence, and other methods can be used to build models that can predict the developing trend of equipment fault. Finally, the current equipment status data is imported into the model to obtain the prediction result. In addition, through long-term data collection and result feedback, the prediction model can be adjusted. The first loop is formed to achieve the continuous optimization of the dynamic disturbance events prediction.
4.2 Big Data-Driven Influence Evaluation
Influence evaluation is to estimate the degree of damage from dynamic disturbance events to the system. This section includes correlation analysis and impact degree judgment of dynamic disturbance events in PMSs. The correlation analysis refers to the correlation modeling of the prediction results on each edge device. Logical relationships among various dynamic disturbance events like causal, progressive, and parallel can be determined based on the prediction results. This process involves multiple devices, materials, and environmental factors. So, the analysis needs to be performed on a regional fog computing server or the cloud server. The impact degree judgment is considered by using correlation analysis results to calculate and classify the impact of disturbance events. According to the magnitude of the impact, the impact of disturbance can be divided into unit-level impact, regional-level impact, and system-level impact. Different levels of impact clarify the degree of damage to the system by different dynamic events, providing support for subsequent decision-making.
4.3 Big Data-Driven Decision-Making
Big data-driven decision-making optimizes the control strategy of the PMSs to prevent the influence of disturbance events. This section contains command sending and receiving, global analysis, and differentiated adjustment. Command sending and receiving means that the cloud server receives pending instructions from multiple fog servers and sends the decision instructions back. Since the instructions need to be analyzed before being sent back to fog servers, which can only regulate the equipment in a regional area. Therefore, a global analysis of the system needs to be performed on the cloud server. Global analysis is to sort the different evaluation results sent by fog servers or a cloud server itself to conduct a top-down analysis with system-level operation and maintenance requirements. These analysis goals can be minimizing costs, delays, or adjustment steps. The differentiated adjustment refers to the adjustment of production process parameters, part of the production line structure, and remaining production plans based on system-level, regional-level, and unit-level impacts. The above process can form loop II and loop III. For example, the cloud server receives unstable voltage signals collected from multiple voltage detection edge devices monitored by the fog server, and will gradually take the following measures. Firstly, the cloud server determines that the power supplies unit for this production line is about to be overhauled. Then, the cloud server design makes a plan to shut down the current production line and arrange backup production line equipment to adjust the remaining production plan. Finally, the cloud server sends the shutdown instruction to the fog server of the production line. At the same time, the instructions for preparing the remaining production tasks of the batch in advance are sent to the backup production line fog server. Hence, the big data-driven decision-making based on cloud computing for PMS is realized.
Chemical fiber production is a typical process-type production, in which the direct spinning of polyester fiber is the most widely used method for chemical fiber production. The process flow of direct spinning of polyester fiber mainly includes polyester melting, pressure spinning, cooling and bundling, silk winding, and silk texturing, which are shown in Fig. 3. Chemical fiber raw materials are usually solid particles, which fed into the smelting furnace. The melting furnace heats up and pressurizes raw materials, which change from solid to thick liquid. Through the pipeline, the liquid chemical fiber fluid is diverted to each metering pump, which forms the initial spinning position with a spinning box. Each spinning box is placed with 10 to 15 spinnerets, which can turn the molten chemical fiber solution into ultra fine silk. The ultra fine silk is cooled and oiled on the bundling hook, where the original chemical fiber formed. The chemical will turn into silk cakes on the high-speed winding machine. Finally, the silk cakes will enter the texturing process or directly enter the warehouse.

Figure 3: Polyester fiber direct spinning process
The proposed framework is a systematic generic operation policy focusing on minimizing the impact of dynamic disturbance events on the system. Usually, the framework of PHM based on digital twin should be customized according to every specific PMS. Therefore, a case study about chemical fiber winding shop is conducted to demonstrate the effectiveness of the proposed framework of PHM in PMS based on digital twin. Part of the framework based on edge-fog-cloud proposed in this paper has been currently trialed in a chemical fiber factory in Zhejiang Province. The chemical fiber winding process is a relatively fixed flow process, as shown in Fig. 4. The chemical fiber winds through multiple parts and uses multiple jigs. Suffered from several kinds of dynamic events such as multiple machine faults, disturbance from the environment, the PMS has to re-optimize the PHM method to avoid the delay of delivery time and unstable system operation. The chemical fiber winding machine is the key equipment in the winding shop, with complex structures and many parts. Moreover, for the unchangeable winding process, when a dynamic disturbance event occurs, it is likely to cause the winding machine to stop. Besides, it is easy to affect the cooling of the upper spinneret and the punctual storage of the lower part. However, not all components on the winding machine participate in production at the same time. Moreover, jigs involved in the chemical fiber winding process run intermittently. In face of uncertain interference, it is possible to redistribute the replacement parts of the winding machine and jigs without stopping the machine. For the parts that need to shut down the winding machine for replacement, the sponge winding machine position can be set for temporary production when the winding machine fails. So as to deliver overflow production tasks on time as much as possible.
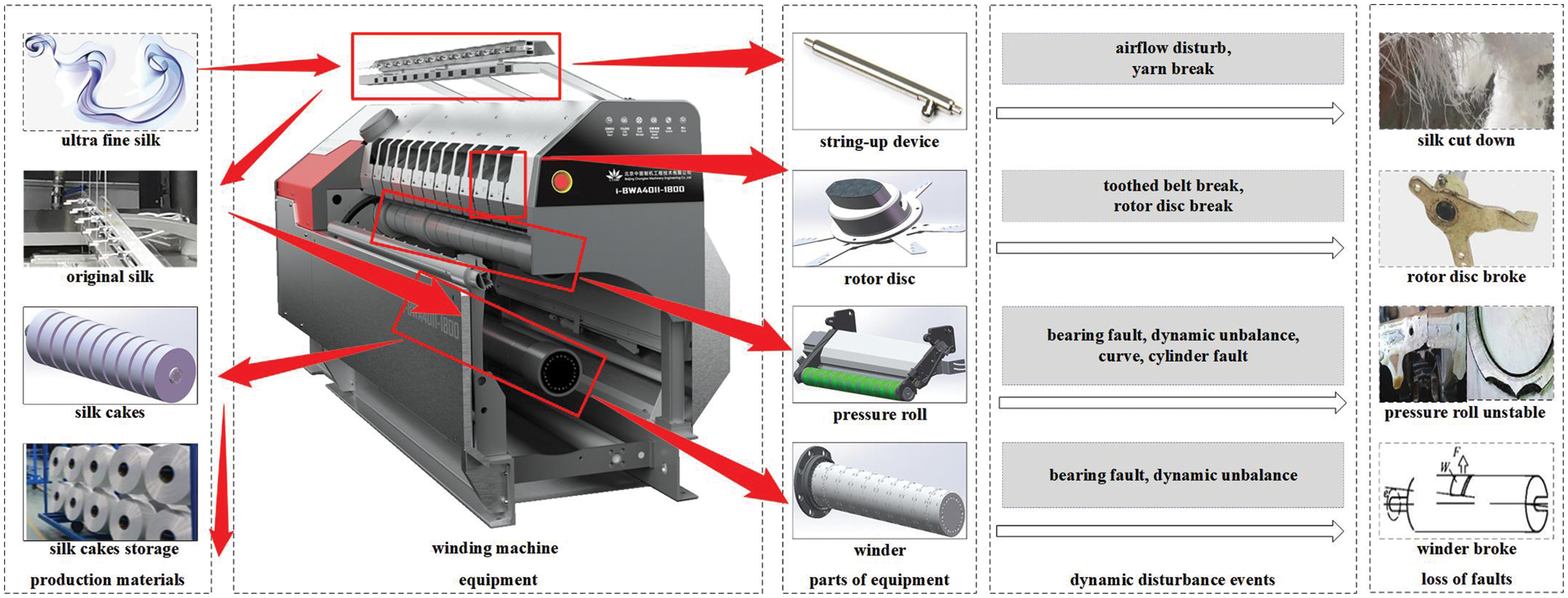
Figure 4: Chemical fiber winding production and its disturbances
There are three components in the customized PHM framework, named comprehensive and accurate prediction, dynamic association evaluation, and system control and decision-making. The specific implementation processes of applying these three components to the PHM of chemical fiber PMS are described as follows.
5.1 Comprehensive and Accurate Prediction of Chemical Fiber Winding Process
The comprehensive and accurate prediction of dynamic events in the chemical fiber winding workshop includes 4 steps: (1) multi-source data collection. (2) health indicator extraction. (3) data modeling. (4) dynamic event prediction, as shown in Fig. 5. For example, when faults of the winder bearings need to be predicted, multi-source data comes from equipment data, material data, and data from MES and ERP systems are collected. These data are conditionally filtered according to different objects to form multi-source data sets for different needs at edge devices, such as vibration data acquisition analyzer and electrical signal analyzer. Then, feature extraction formulas are set up to combine with the actual data set for fault feature mining. After several iterations, the fault features adapted to the characteristics of the winding machine are obtained. On the edge device side, the IFCNN method [44] in the internal algorithm library classifies the characteristic data features of different time periods according to the CNN framework and the improved confusion matrix. Meanwhile, the collected data continues to accumulate, which forms historical data for a certain period of time. The improved LSTM method in the internal algorithm library is used to model the trend of multiple feature indicators. Through the predicted model, it is obvious that the equipment deterioration trend and possible failures in the future can be obtained.
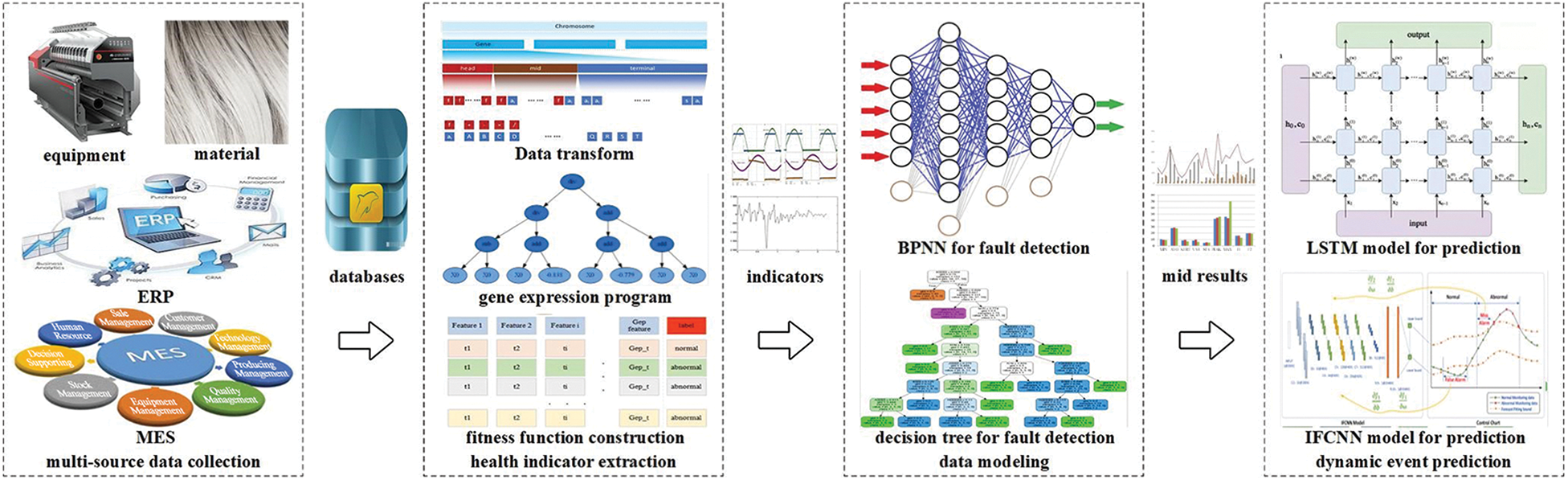
Figure 5: Dynamic disturbance event prediction process
The DTPHM of the winder needs to collect vibration data during its operation. Fig. 6 shows the fixed position of the vibration acceleration sensors on the winder and pressure roll. In order to clearly illustrate the relationship between the whole and each part, winding workshop, winding machine, rotor, winder, and bearings are shown in the figure. According to the working condition data in the MES system, the vibration data is dynamically collected and integrated. Through the RUL prediction method, the RUL curves of three bearings in the winder shown in Fig. 7 can be obtained, which cannot be achieved by the manual inspection of the fiber factory. Interventions are set up for some of the equipment that are predicted to fail to maintain continuous operation, resulting in the bearing fault diagnosis results shown in Fig. 8. Through the 6-month test at the edge of the digital twin-based PHM, it is found that the fault detection rate of the winder is higher than 80%, as shown in Table 1.

Figure 6: Winding shop, winding machine, and fixed positions of the vibration accelerometer sensors
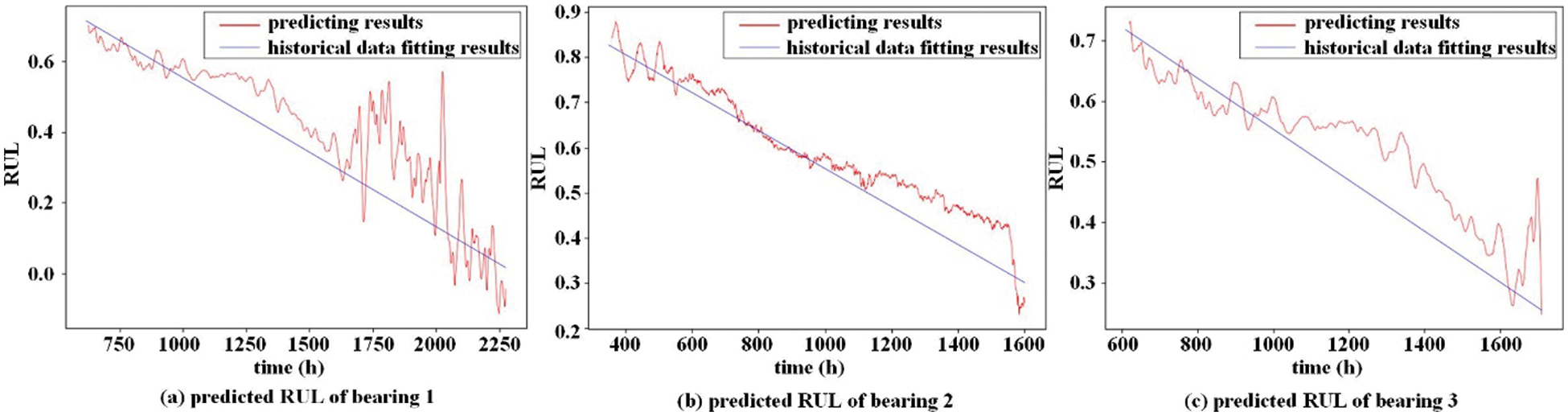
Figure 7: RUL prediction results for three bearings of the winder
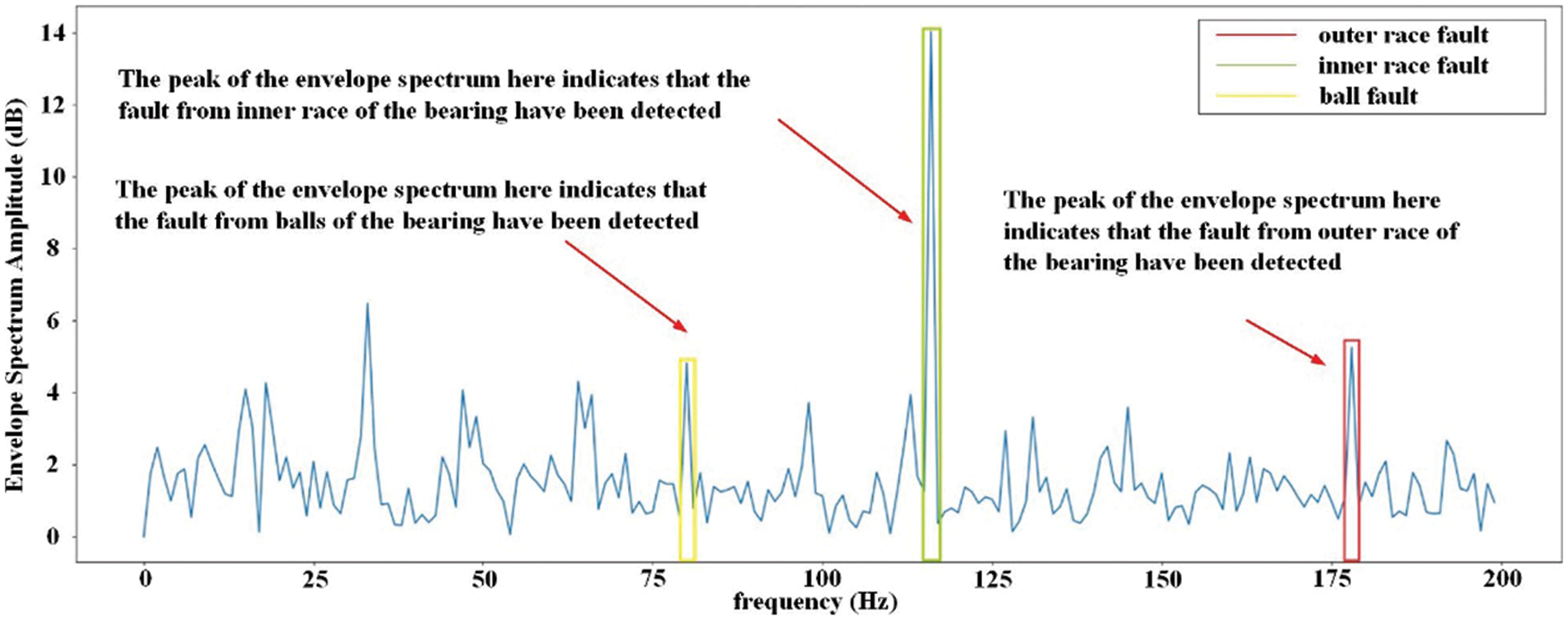
Figure 8: Fault diagnosis results of standard bearings of the winder

5.2 Dynamic Association Evaluation of Chemical Fiber Winding Process
If the dynamic event prediction at an edge device is oriented to the specific equipment, the correlation evaluation is oriented to the chemical fiber production process. The dynamic event association evaluation of the chemical fiber production process, as shown in Fig. 9, is mainly divided into two steps: (1) the correlation analysis of the predicted dynamic events at edge devices. (2) The level degree judgment of the disturbance. The chemical fiber silk is drafted and shaped by a hot roller, and then wounded into a yarn package, which will be sent to the warehouse by a forklift. When it is predicted that the winder bearing is about to fail, it will affect the operation of the upstream hot roller, which is a station-level effect. For example, the prediction result of multiple vibration data acquisition analyzers and electrical signal analyzers of a winding production line are transmitted to the fog computing server through the station-level network. In the fog computing server, the regression analysis method combines the forecast trends of each component of multiple winders and their respective production performance to obtain the estimated production capacity of each winder. It can indirectly estimate the loss of capacity due to the shutdown of each winding machine in the production line.
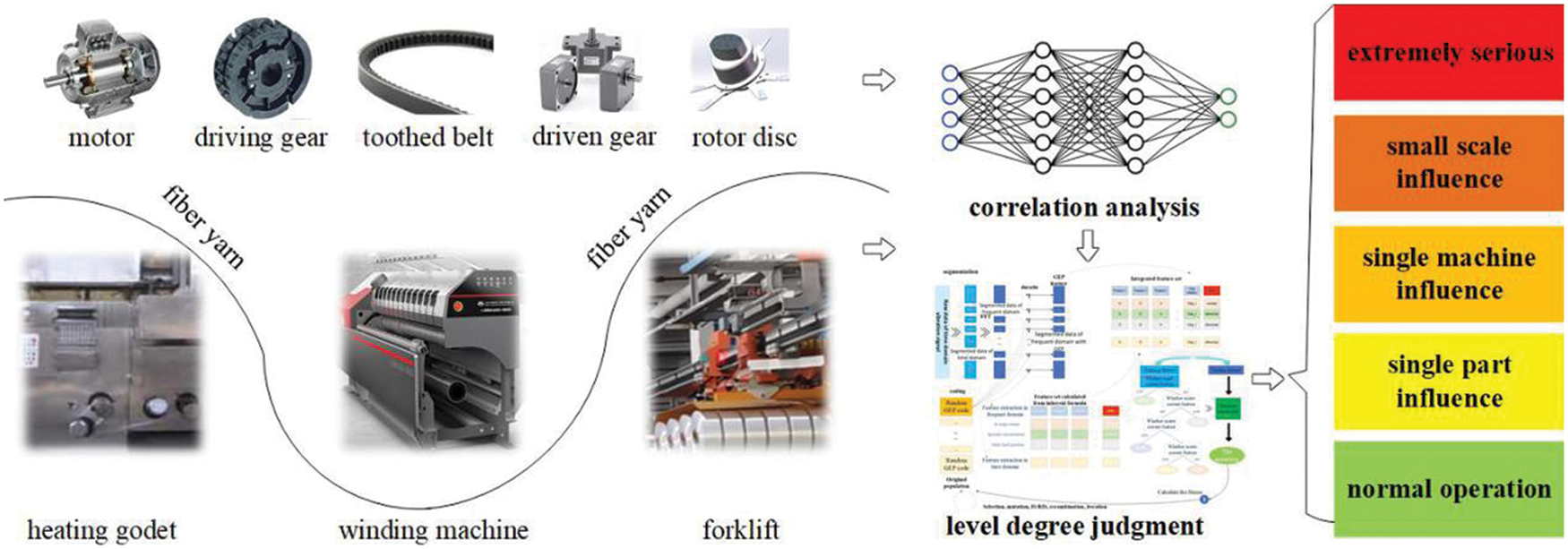
Figure 9: Dynamic event association evaluation process
Because the hardware performance of fog servers is better than edge devices and avoids the situation of all data being communicated between the cloud and the edge, the efficiency of fog computing is higher than edge computing and cloud computing. Table 2 shows the comparison of the response time of edge computing, fog computing, and cloud computing in evaluation. This comparison is 30 times averaged from the evaluation of the impact of each component failure on the winding machine of L1#1 and L1#2. It can be seen that the time is too long when all the evaluation calculations are run on the edge device. When all calculations are implemented in the cloud, the evaluation efficiency will be affected due to a large amount of data transmission. Therefore, the impact assessment of fog computing is more efficient.

5.3 System Control and Decision-Making of Chemical Fiber Winding Process
The system control and decision-making of the chemical fiber winding process are realized through command sending and receiving, global analysis, and differentiated adjustment, as shown in Fig. 10. The prediction results and evaluation results are periodically issued by the edge device and the fog server. The control and adjustment instructions are issued in a timely manner based on the results of the cloud server’s analysis. After the cloud server receives the evaluation results from each fog server, it conducts a global analysis according to the goals of minimum cost and shortest delay. Afterwards, a hierarchical control mechanism for the winding shop is established, which are reorganization of system structure, partial adjustment of functions, and modification of marginal entities. Since the chemical fiber production process is usually not changed, the system structure reorganization is usually achieved by changing the production plan. In the same way, the partial adjustment of functions is mainly realized by modifying the parameters in the chemical fiber production process. Edge entity modification usually refers to the maintenance of production equipment. For example, if it is predicted that the winder bearing is about to fail at a certain time in the future, the operating parameters of the winding machine need to be modified. Such as reducing the rotate speed and producing spare fiber silk products. Before the end of the predicted remaining useful life, the faulty equipment will be shut down, the faulty bearings will be replaced, and the spare winding machine and spare hot roll equipment will be activated to take over the original production task. When an emergency order is inserted, the remaining production plan needs to be revised and a spare production line is arranged to share the sudden increase in production tasks. After a rough estimate, the system control and decision-making strategy reduces the cost of chemical fiber production by 5%.
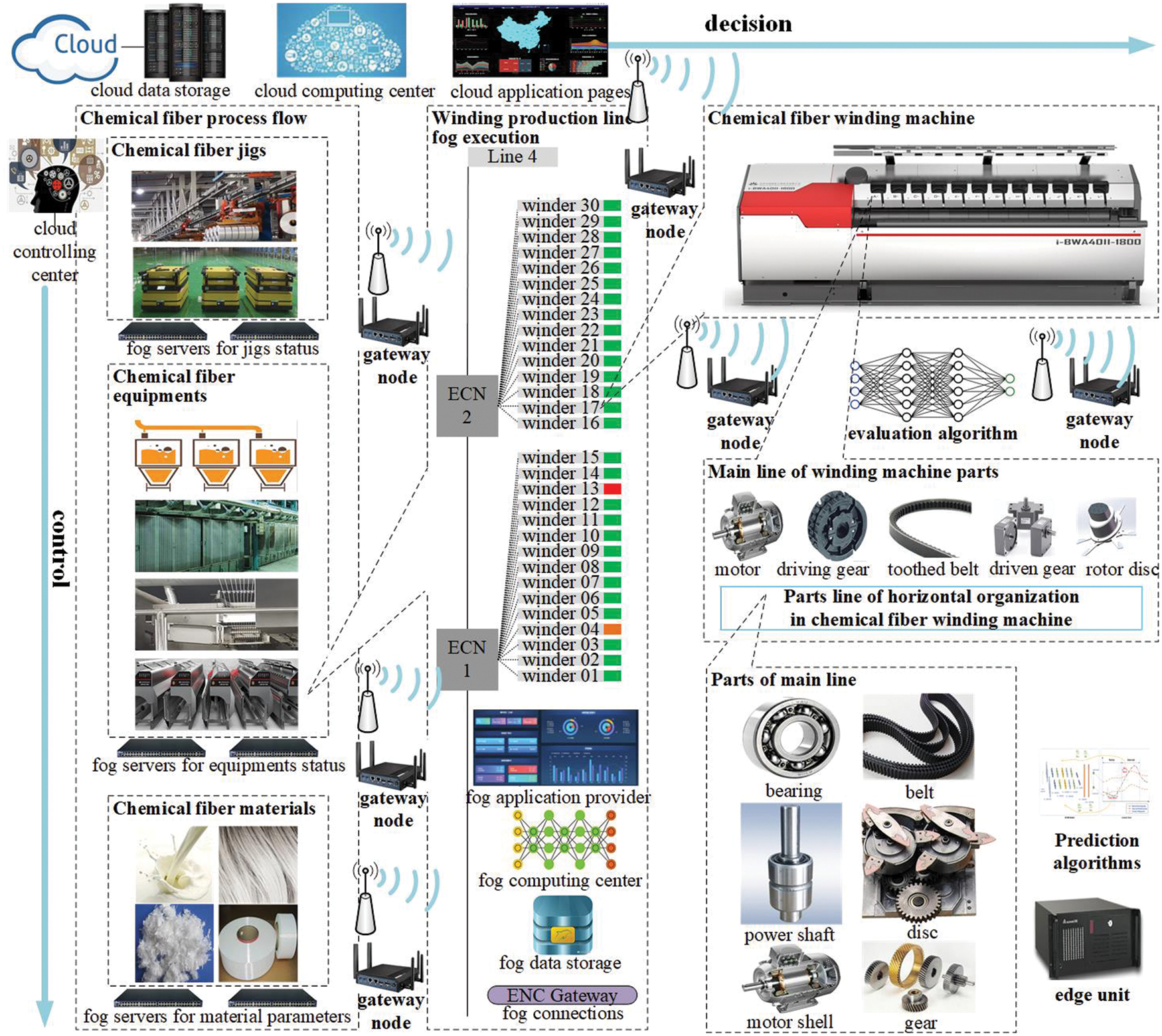
Figure 10: Control and decision-making of chemical fiber winding shop
Aiming to reduce the impact of dynamic interference on manufacturing systems, this paper proposed a new predictive operation and maintenance model for process manufacturing systems. Starting from frequently occurred, hard-evaluated and unsuppressed dynamic disturbance events, a new model of PHM based on a digital twin was proposed, which consists of the unit-level digital twin maintenance model based on edge computing, station-level digital twin maintenance model based on fog computing, shop-level digital twin maintenance model based on cloud computing. Then, a big data-driven PHM implementation process was designed. A case study for the maintenance of chemical fiber enterprise equipment was conducted to demonstrate the effectiveness of the proposed digital twin PHM paradigm.
The main contributions of this paper are summarized as follows:
(1) A three-leveled digital twin model is constructed of PHM for PMSs, which are unit-level digital twin PHM based on edge computing, station-level digital twin PHM based on fog computing, shop-level digital twin PHM based on cloud computing. The proposed three-layer digital twin model combines edge computing, fog computing, and cloud computing to form a systematic PHM of PMSs.
(2) Big data-driven operation method is proposed for DTPHM-PMS, which are indicator prediction, influence evaluation, and intelligent decision-making. The proposed method is capable of dynamic disturbance event prediction, disturbance impact estimation, and control strategy optimization.
(3) The proposed three-leveled digital twin model has been tried and applied in a process manufacturing system exemplified by chemical fiber production, which has played an exemplary role in the PHM of PMSs.
There are some limitations with the current work, which will be considered in future work. The first limitation is that the current work focuses on a process industry which takes chemical fiber as an example. This model is still lacking in research and validation in PHM of discrete manufacturing shops. In the future, we will consider interoperability in different particular production systems, such as wafer manufacturing systems, and welding production systems. Secondly, the method proposed in this paper also needs in-depth research on model variability, such as different types of PMSs operating in different regions, PHM in cases of a wide range of regions, and a large temperature change range will inevitably involve more changes. The third is that the proposed PHM model based on digital twins needs to be more routinely tried in the enterprise information system. In the future, we will take a system perspective to manufacturing systems with a comprehensive domain model.
Funding Statement: This research was supported by the Fundamental Research Funds for The Central Universities (Grant No. 2232021A-08), National Natural Science Foundation of China (Grant No. 51905091), Shanghai Sailing Program (Grand No. 19YF1401500).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Lager, T. (2017). A conceptual analysis of conditions for innovation in the process industries and a guiding framework for industry collaboration and further research. International Journal of Technological Learning, Innovation and Development, 9(3), 189–219. DOI 10.1504/IJTLID.2017.087403. [Google Scholar] [CrossRef]
2. Aaldering, L. J., Song, C. H. (2020). Of leaders and laggards-towards digitalization of the process industries. Technovation, 105, 102211. DOI 10.1016/j.technovation.2020.102211. [Google Scholar] [CrossRef]
3. Gui, W. H., Wang, C. H., Xie, Y. F., Song, S., Meng, Q. (2015). The necessary way to realize great-leap-forward development of process industires. Bulletin of National Natural Science Foundation of China, 29(5), 337–342. [Google Scholar]
4. Chen, Q. (2008). Study on maintenance optimization in reliability (Ph.D. Thesis). Tianjin University, Tianjin, China. [Google Scholar]
5. Lu, C., Gao, L., Li, X. Y., Xiao, S. Q. (2017). A hybrid multi-objective grey wolf optimizer for dynamic scheduling in a real-world welding industry. Engineering Applications of Artificial Intelligence, 57(1), 61–79. DOI 10.1016/j.engappai.2016.10.013. [Google Scholar] [CrossRef]
6. Bao, J. S., Guo, D. S., Li, J., Zhang, J. (2019). The modelling and operations for the digital twin in the context of manufacturing. Enterprise Information Systems, 13(4), 534–556. DOI 10.1080/17517575.2018.1526324. [Google Scholar] [CrossRef]
7. Zhou, X. J., Xi, L. F., Lee, J. (2005). A reliability-based sequential preventive maintenance model. Journal of Shanghai Jiaotong University, 39(12), 2044–2047. DOI 10.16183/j.cnki.jsjtu.2005.12.027. [Google Scholar] [CrossRef]
8. Li, C. Y., Zhang, Y. M., Xu, M. Q. (2012). Reliability-based maintenance optimization under imperfect predictive maintenance. Chinese Journal of Mechanical Engineering, 25(1), 160–165. DOI 10.3901/CJME.2012.01.160. [Google Scholar] [CrossRef]
9. Shimada, J., Satoko, S. (2016). A statistical approach to reduce failure facilities based on predictive maintenance. IEEE 2016 International Joint Conference on Neural Networks (IJCNN), pp. 5156–5160. Vancouver. DOI 10.1109/ijcnn.2016.7727880. [Google Scholar] [CrossRef]
10. Boshakov, K. P., Petkov, V. I., Doukovska, L. A., Vassileva, S. I., Mihailov, E. G. et al. (2013). Predictive maintenance model-based approach for objects exposed to extremely high temperatures. Signal Processing Symposium (SPS), pp. 1–5. Serock. DOI 10.1109/SPS.2013.6623621 [Google Scholar] [CrossRef]
11. Iung, B., Monnin, M., Voisin, A., Cocheteux, P., Levrat, E. (2008). Degradation state model-based prognosis for proactively maintaining product performance. CIRP Annals-Manufacturing Technology, 57(1), 49–52. DOI 10.1016/j.cirp.2008.03.026. [Google Scholar] [CrossRef]
12. Lei, Y. G., Li, N. P., Gontarz, S., Lin, J., Radkowski, S. et al. (2016). A model-based method for remaining useful life prediction of machinery. IEEE Transcations on Reliability, 65(3), 1314–1326. DOI 10.1109/TR.2016.2570568. [Google Scholar] [CrossRef]
13. Magargle, R., Johnson, L., Mandloi, P., Davoudabadi, P., Kesarkar, O. et al. (2017). A simulation-based digital twin for model-driven health monitoring and predictive maintenance of an automotive braking system. Proceddings of the 12th International Modelica Conference, pp. 15–17. Prague. DOI 10.3384/ecp1713235. [Google Scholar] [CrossRef]
14. Liao, W. Z., Wang, Y. (2012). Dynamic predictive maintenance model based on data-driven machinery prognostics approach. Applied Mechanics & Materials, 143(1), 901–906. DOI 10.4028/www.scientific.net/AMM.143-144.901. [Google Scholar] [CrossRef]
15. Daily, J., Peterson, J. (2017). Predictive maintenance: How big data analysis can imporve maintenance. Supply Chain Integration Challenges in Commercial Aerospace, pp. 267–278. Cham: Springer. DOI 10.1007/978-3-319-46155-7_18. [Google Scholar] [CrossRef]
16. Verhagen W. J.C., Curran, R., de Boer L. W.M. (2017). Component-based data-driven predictive maintenance to reduce unscheduled maintenance events. International Conference on Transdisciplinary Engineering (TE), pp. 3–10. Delft. DOI 10.3233/978-1-61499-779-5-3. [Google Scholar] [CrossRef]
17. Baptsta, M., Sankararaman, S., Medeiros I. P., D., Nascimento, C., Prendinger, H. et al. (2018). Forecasting fault events for predictive maintenance using data-driven techniques and ARMA modeling. Computers & Industrial Engineering, 115, 41–53. DOI 10.1016/j.cie.2017.10.033. [Google Scholar] [CrossRef]
18. Wen, L., Wang, Y., Li, X. (2022). A new cycle-consistent adversarial networks with attention mechanism for surface defect classification with small samples. IEEE Transactions on Industrial Informatics. DOI 10.1109/TII.2022.3168432. [Google Scholar] [CrossRef]
19. Wen, L., Xie, X., Li, X., Gao, L. (2022). A new ensemble convolutional neural network with diversity regularization for fault diagnosis. Journal of Manufacturing Systems, 24(62), 964–971. DOI 10.1016/j.jmsy.2020.12.002. [Google Scholar] [CrossRef]
20. Wen, L., Li, X., Gao, L. (2020). A new reinforcement learning based learning rate scheduler for convolutional neural network in fault classification. IEEE Transactions on Industrial Electronics, 68(12), 12890–12900. DOI 10.1109/TIE.2020.3044808. [Google Scholar] [CrossRef]
21. Wen, L., Gao, L., Li, X. Y., Zeng, B. (2021). Convolutional neural network with automatic learning rate scheduler for fault classification. IEEE Transactions on Instrumentation and Measurement, 70(1), 1–12. DOI 10.1109/TIM.2020.3048792. [Google Scholar] [CrossRef]
22. Yang, Z., Bonsall, S., Wang, J. (2008). Fuzzy rule-based bayesian reasoning approach for prioritization of failures in FMEA. IEEE Transactions on Reliability, 57(3), 517–528. DOI 10.1109/TR.2008.928208. [Google Scholar] [CrossRef]
23. Gargama, H., Chaturvedi, S. K. (2011). Criticality assessment models for failure mode effects and criticality analysis using fuzzy logic. IEEE Transactions on Reliability, 60(1), 102–110. DOI 10.1109/TR.2010.2103672. [Google Scholar] [CrossRef]
24. Mandal, S., Maiti, J. (2014). Risk analysis using FEMA: Fuzzy similarity value and possibility theory based approach. Expert Systems with Applications, 41(7), 3527–3537. DOI 10.1016/j.eswa.2013.10.058. [Google Scholar] [CrossRef]
25. Pander, P. K., Spector, M. E., Chatterjee, P. (1975). Computerized fault tree analysis: TREEL and MICSUP. Computer Science, 75(3), 1–12. [Google Scholar]
26. Garrick, B. J. (1970). Principles of unified system safety analysis. Nuclear Engineering and Design, 13(2), 245–321. DOI 10.1016/0029-5493(70)90165-2. [Google Scholar] [CrossRef]
27. Su, C. T., Chang, C. C. (2000). Minimization of the life cycle cost for a multistate system under periodic maintenance. International Journal of Systems Science, 31(2), 217–227. DOI 10.1080/002077200291334. [Google Scholar] [CrossRef]
28. Soro, I. W., Nourelfath, M., Ait-kadi, D. (2009). Performance evaluation of multi-state degraded systems with minimal repairs and imperfect preventive maintenance. Reliability Engineering & System Safety, 95(2), 65–69. DOI 10.1016/j.ress.2009.08.004. [Google Scholar] [CrossRef]
29. Ruiz-castro, J. E. (2016). Markov counting and reward processes for analysing the performance of a complex system subject to random inspections. Reliability Engineering & System Safety, 145(1), 155–168. DOI 10.1016/j.ress.2015.09.004. [Google Scholar] [CrossRef]
30. Ebenlendr, T., Sgall, J. (2011). Semi-online preemptive scheduling: One algorithm for all variants. Theory of Computing Systems, 48(3), 577–613. DOI 10.1007/s00224-010-9287-2. [Google Scholar] [CrossRef]
31. Yuan, J. J., Ng, C. T., Cheng, T. (2011). Best semi-online algorithms for unbounded parallel batch scheduling. Discrete Applied Mathematics, 159(8), 838–847. DOI 10.1016/j.dam.2011.01.003. [Google Scholar] [CrossRef]
32. Chen, L., Ye, D. S., Zhang, G. H. (2013). Approximating the optimal competitive ratio for an ancient online scheduling problem. Computer Science, 40(1), 1–21. DOI 10.48550/arXiv.1302.3946. [Google Scholar] [CrossRef]
33. Hock, K. P., Radjabli, K., Mcguiness, D., Boddeti, M. (2016). Predictive analysis in energy management system. IEEE International Conference on Environment and Electrical Engineering (EEEIC), pp. 1–4. Florence. DOI 10.1109/EEEIC.2016.7555506. [Google Scholar] [CrossRef]
34. Kerr, R. (1991). Knowledge-based manufacturing management: Applications of artificial intelligence to the effective management of manufacturing companies. USA: Addison-Wesley Longman Pub. Co. [Google Scholar]
35. Han, B., Zhang, W. J., Lu, X. W., Lin, Y. Z. (2015). On-line supply chain scheduling for single-machine and parallel-machine configurations with a single customer: Minimizing the makespan and delivery cost. European Journal of Operational Research, 244(3), 704–714. DOI 10.1016/j.ejor.2015.02.008. [Google Scholar] [CrossRef]
36. Fan, Q., Huang, H., Li, Y., Han, Z., Hu, Y. et al. (2021). Beetle antenna strategy based grey wolf optimization. Expert Systems with Applications, 165, 113882. DOI 10.1016/j.eswa.2020.113882. [Google Scholar] [CrossRef]
37. Fan, Q. S., Huang, H. S., Chen, Q. P., Yao, L. G., Yang, K. et al. (2021). A modified self-adaptive marine predators algorithm: Framework and engineering applications. Engineering with Computers, 37(1), 1–26. DOI 10.1007/s00366-021-01319-5. [Google Scholar] [CrossRef]
38. Wang, J. L., Zheng, P., Qin, W., Li, T. D., Zhang, J. (2018). A novel resilient scheduling paradigm integrating operation and design for manufacturing systems with uncertainties. Enterprise Information Systems, 13(4), 430–447. DOI 10.1080/17517575.2018.1526322. [Google Scholar] [CrossRef]
39. Luo, W. C., Hu, T. L., Ye, Y. X., Zhang, C. R., Wei, Y. L. (2020). A hybrid predictive maintenance approach for CNC machine tool driven by digital twin. Robotics and Computer-Integrated Manufacturing, 65. DOI 10.1016/j.rcim.2020.101974. [Google Scholar] [CrossRef]
40. Li, C. Z., Mahadeven, S., Ling, Y., Wang, L. P., Choze, S. (2017). A dynamic bayesian network approach for digital twin. The 19th AIAA Non-Deterministic Approaches Conference, Texas. DOI 10.2514/6.2017-1566. [Google Scholar] [CrossRef]
41. Grieves, M., Vickers, J. (2017). Digital twin: Mitigating unpredictable, undesirable emergent behavior in complex systems. In: Transdisciplinary perspectives on complex systems, pp. 85–113. Cham: Springer. DOI 10.1007/978-3-319-38756-7_4. [Google Scholar] [CrossRef]
42. Tao, F., Zhang, M., Liu, Y. S., Nee, A. Y. C. (2018). Digital twin driven prognostics and health management for complex equipment. CIRP Annals, 64(1), 169–172. DOI 10.1016/j.cirp.2018.04.055. [Google Scholar] [CrossRef]
43. Dai, H. N., Wang, H., Xu, G. Q., Wan, J. F., Imran, M. (2020). Big data analytics for manufacturing internet of things: Opportunities, challenges and enabling technologies. Enterprise Information Systems, 14(9–10), 1279–1303. DOI 10.1080/17517575.2019.1633689. [Google Scholar] [CrossRef]
44. He, J. J., Wang, J. L., Dai, L., Zhang, J., Bao, J. S. (2019). An adaptive interval forecast CNN model for fault detection method. 2019 IEEE 15th International Conference on Automation Science and Engineering, pp. 602–607. Vancouver. DOI 10.1109/COASE.2019.8843086. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools