| Computer Modeling in Engineering & Sciences |
DOI: 10.32604/cmes.2022.020639
ARTICLE
Efficient UAV-Based MEC Using GPU-Based PSO and Voronoi Diagrams
1Department of Information Technology, College of Computing & Information Technology at AlKamil, University of Jeddah, Jeddah, Saudi Arabia
2Department of Computer Science, Faculty of Computers and Informatics, Suez Canal University, Ismailia, Egypt
*Corresponding Author: Mohamed H. Mousa. Email: mohamed_mousa@ci.suez.edu.eg
Received: 04 December 2021; Accepted: 18 February 2022
Abstract: Mobile-Edge Computing (MEC) displaces cloud services as closely as possible to the end user. This enables the edge servers to execute the offloaded tasks that are requested by the users, which in turn decreases the energy consumption and the turnaround time delay. However, as a result of a hostile environment or in catastrophic zones with no network, it could be difficult to deploy such edge servers. Unmanned Aerial Vehicles (UAVs) can be employed in such scenarios. The edge servers mounted on these UAVs assist with task offloading. For the majority of IoT applications, the execution times of tasks are often crucial. Therefore, UAVs tend to have a limited energy supply. This study presents an approach to offload IoT user applications based on the usage of Voronoi diagrams to determine task delays and cluster IoT devices dynamically as a first step. Second, the UAV flies over each cluster to perform the offloading process. In addition, we propose a Graphics Processing Unit (GPU)-based parallelization of particle swarm optimization to balance the cluster sizes and identify the shortest path along these clusters while minimizing the UAV flying time and energy consumption. Some evaluation results are given to demonstrate the effectiveness of the presented offloading strategy.
Keywords: Task offloading; mobile-edge computing; unmanned aerial vehicles; Internet of Things; voronoi diagrams; GPU; particle swarm optimization
Table 1 describes the meaning of the common terms abbreviations and acronyms found throughout the paper.
Mobile-Edge Computing (MEC) has been become the most promising framework for meeting Quality of Service (QoS) requests, taking into account the requirements of processing cycles and energy. This is essential for computationally intensive mobile applications and the Internet of Things (IoT) to cope with capability limitations of mobile and IoT devices [1–3]. A cloud-based layer supports an edge network of servers that handles computationally intensive tasks, allowing for a reduction in the required energy and corresponding turnaround time. The close proximity of the edge servers to IoT and mobile devices provides low latency and a high bandwidth for delay-sensitive IoT applications [4 –6]. However, in some locations, the deployment of edge servers may be difficult, if not impossible [7–11]. As a real-life example, monitoring and observing forests and woodlands is a difficult task because such monitoring is time-consuming and requires considerable effort along with suitable resources. Stopping dangerous undertakings that can cause great damage to nature is a major challenge and responsibility of monitoring forestlands. Because forests cover such a wide area, it is difficult for forest managers and workers to take immediate action in cases of problems such as forest fires and illegal tree felling. Communication with ground sensors, aerial surveillance, mapping, aerial photography, and thermal imaging are some approaches in which Unmanned Aerial Vehicles (UAVs) can carry out forest monitoring. Thus, monitoring by UAVs contributes to the conservation of wildlife, biodiversity, and vegetation, the balance of ecology, and other forestry-related issues.
The UAV industry has made significant advances with regard to both technology and cost during the past decade, and many different applications have been demonstrated, such as intelligent transportation, agriculture, and wilderness monitoring [12–15]. In addition, throughout this period, communication technologies have advanced in various ways (e.g., IoT, cloud computing, etc.) [16]. UAVs have been highly successful due to their cost-effective and flexible deployment [17]. These advances in communication technologies have been used to improve the collaborative computation between UAVs and ground devices. In fact, UAV-Assisted Computing (UAC) is regarded as computation services provided to ground devices using UAVs as flying bases [18]. To this end, UAVs can support offloading in MEC architecture in various ways such as:
• UAV-assisted communication: For IoT devices, UAVs allow quick, flexible, and cost-effective network coverage by acting as relays for distant ground base stations [19,20].
• UAV-assisted Computing MEC (UCMEC) architecture: For cloud services, UAVs equipped with edge servers allow for the offloading and processing of ground device tasks.
A unified communication network that integrates a UAV with an MEC network, as well as near line-of-sight wireless communication, are important for meeting the QoS specifications of mobile applications with regard to energy consumption and sensitivity to delay [21,22]. UAVs are constrained by their energy limitations, which lead to delays in their offloading processes. Two challenges must be taken into account in the development of any UAV-assisted computing MEC method:
1. Locally, ground devices are not distributed uniformly. Hence, the offloading and execution of tasks must be partitioned and balanced along a set of clusters in order to achieve high performance of the UCMEC offloading system.
2. Despite the energy limitations, UAVs should collect IoT data from various locations, process offloaded tasks, and report the results back. These paths have to be optimized to satisfy the energy constraints of the UAVs.
This research designs a UCMEC framework to offload tasks with the goal of optimizing the amount of required energy and computational turnaround time for both mobile devices and UAVs. As depicted in Fig. 1, we propose a space partitioning of the offloaded tasks into different regions, with the UAV hovering over each region to process the offloaded tasks. Finally, the UAV trajectory is optimized considering the time and energy limits of the UAV. The contributions according to the proposal are as follows:
• “Voronoi Diagrams” (VDs) are used based on a formal mathematical model of the UCMEC system to partition the IoT wireless devices into set regions, where the offloaded subset of tasks in each region meets the overall time constraint.
• The initial partitioning of the wireless devices is improved using the proposed “Graphics Processing Unit” (GPU)-based Particle Swarm Optimization (PSO).
• The same GPU-based PSO (GPUPSO) steps are used for obtaining a near-optimum path minimizing the UAV trajectory and load balancing tasks in the partitioned regions according to both energy and time constraints.
• PSO has the advantage of being simple to implement and has a good capability for convergence in comparison with many population-based approaches, such as Genetic Algorithms (GAs) [23]. The main disadvantage is that PSO may be attracted to local minima. We overcome this issue by adding an aging factor that guarantees exploration of the global search space.
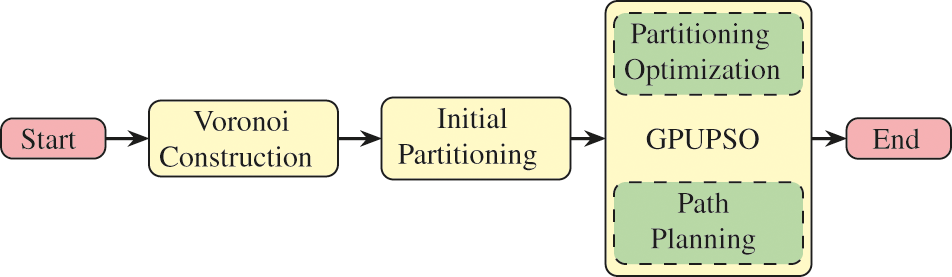
Figure 1: The proposed offloading framework
The rest of the paper is organized as follows. The next section presents the related work, followed by a formulation of the optimization model in terms of the time and energy constraints as well as the affecting factors in Section 3. Section 4 explains the proposed optimization framework on the basis of clustering of the ground devices and the use of the GPU-based PSO. Finally, Section 5 presents some experimental results, followed by the conclusions in Section 6.
Edge servers are always privileged by their high bandwidths and low latency. Therefore, the performance of offloaded tasks is enhanced by MEC for restricted systems in terms of energy and time [24,25]. When UAVs are equipped with MEC servers and communicating channels, UAVs contribute to computing services and instant communications. This yields a better energy consumption and rate of transmission for mobile devices. However, the UAV’s energy limitations have an adverse effect on ground mobile equipment with regard to communication and computation [26]. To address these key challenges, a variety of research studies have been conducted to explore different configurations, optimization objectives, and underlying constraints.
In [27], optimum planning of the UAV trajectory, ratio of offloading tasks, and user scheduling were studied together to minimize all users’ delays. In [28], UCMEC was proposed as a novel framework of agent-based task offloading. With the aim of obtaining the optimal offloading plan, the intelligence agent was led to obtain a plan that was as efficient as possible. However, this study did not address UAV trajectory optimization. In [29], the authors demonstrated that partial offloading can be optimized through the optimization of offloading ratios, local computing frequencies, transmission power, and edge server computing frequencies. However, their framework did not consider UAV mobility. In [30], the authors proposed an MEC system involving multi-UAVs and ground IoT nodes to offload computational tasks that they could not handle using their limited capabilities. To balance the computational load of the UAVs, they employed a deep reinforcement learning approach. However, stable MEC clustering with greater computing power does not guarantee generation by this method. In [31], using the Dinkelbath algorithm and “successive convex approximation” (SCA) techniques, the authors solved a nonconvex optimization problem formulated in the UAV scenario. In this system, neither the level of distribution of mobile devices on the ground level nor the timing of tasks that are to be offloaded were considered. As part of resource allocation and joint computation offloading, task assignment to MECs while reducing turnaround time and required energy is an important issue. Reference [32] focused on the number and location of UAVs in the development of algorithms for deploying multi-UAVs in a FANET. Based on whether tasks are offloaded or processed locally, a greedy algorithm was proposed to determine the optimal solution. However, it is important to determine when and how to offload tasks from IoT devices, particularly if the tasks are uncertain in order to improve accuracy while reducing cloud communications costs. Using the UAV computing platform, Chen et al. [33] proposed an intelligent task offloading algorithm (iTOA) that can solve the computationally intensive problem of task processing. The offloading operation is performed using the deep “Monte Carlo Tree Search” algorithm (MCTS), which is the principal algorithm of Alpha Go. To arrive at the optimal decision, MCTS simulates the future trajectory of the unloading decision and optimizes the rewards based on this simulation. To be effective, the proposed offloading strategy requires training data, a prediction model of the channel state, and a period of self-learning. In [34], the UAV served as a supporting unit for helping ground devices offload their tasks to access points for further computations. They employed a greedy algorithm to optimize the required energy based on a suitable selection of UAV paths and allocation of resources. However, only the UAV velocity is taken into account in the optimization process. In [35], the relation between energy consumption and latency is considered for task offloading and for evaluating MEC system performance. Their approach used iterative optimization to determine the path of the UAV. However, this optimization does not take into account how clustered fixed slots should be partitioned or consider time delays. In [36], the UAV energy consumption was minimized by optimizing its trajectory and task scheduling. This will further shorten the operational time if some memory-intensive and computation-intensive tasks are executed on the UAV. In [37], greedy search optimization based on the uplink and downlink communications between UAVs and devices was utilized as a means of offloading and receiving data while ensuring energy-efficient operation of the system. In [38], a new mobile edge system integrating UAVs and IoT devices was developed. By launching a UAV, the system enables the provisioning of services to IoT devices by using wireless communication. Additionally, their approach formulates the problem as a nonconvex optimization problem by optimizing UAV position, resource allocation decisions, and task splitting decisions jointly to minimize the total delay and consumption of energy. However, it does not take task scheduling into account. In summary, the approach based on exhaustive and greedy searches is not suitable for such optimization. In fact, the majority of problems in consideration have many factors that must be optimized, such as the shortest path planning, ground user number and locations, energy consumption, and time delay parameters. Thus, most researchers deployed heuristic settings such as fixed partitions. However, their frameworks are not extensible due to their high complexity. In addition, learning-based approaches [39,40] request a preprocessing training step. Such a preprocessing step makes these approaches inapplicable to probabilistic problems.
Thus, the metaheuristic optimization framework is a suitable candidate for dealing with such stochastic problems. In this study, we employ a combination of a computational geometry algorithm, namely, the VD construction algorithm, and a natural phenomena simulation, namely, PSO, to carry out the required minimization of the time delay and energy consumption of the task offloading problem using UCMEC in a reasonable timeframe.
3 UAV-Based Offloading Framework
Now, we describe the employed time and energy models in this section. Table 2 lists the set of symbols and factors employed in the suggested task offloading model.
Two layers comprise an offloading system based on UAVs. A ground layer consists primarily of IoT and mobile devices that have N fixed-position wireless devices on the ground. Let
For the UAV, an altitude of
Provided that the UAV with device di is in the covered region, i.e., the following condition is satisfied:
While the UAV hovers over a region Rk, device di requests to offload its tasks
In this section, we will describe the communicating model controlling the UAV. Suppose that device di is within cluster Rk. This means that when the UAV is hovering over Rk, di lies in the
where
Let
Based on Eq. (5), the time required to offload all of the tasks within Rk is as follows:
Depending on the decision value,
In this section, we will formulate the time of the computation model based on the computation capacity of the UAV. Let fu be the UAV computational capacity; therefore, the time required to execute task ti is evaluated as follows:
Similar to
Using Eqs. (6) and (8), the overall time required within Rk is evaluated as follows:
In this section, we will describe the required energy to offload the tasks in Rk. In fact, the consumption of energy results from the following:
• the energy required to send the receive tasks’ data,
• the energy required to execute the received tasks, and
• the energy required to the flying operation.
For the transmission and reception of data, let the communication energy factor be denoted by
Let
For the UAV hovering energy, we followed the propulsion energy model of [42]. Let
Using Eqs. (10)–(12), the required energy is given by:
In this section, we present the principal factors of the objective function on which the PSO will be based. In fact, the set of ground devices is arranged into a set of clusters. This set is dynamically constructed based on the following factors: the maximum cluster capacity,
In the same manner, based on Eq. (13), the required energy, E, along all clusters is evaluated as follows:
We formulate the function,
subjected to:
The first constraint,
where
In this section, we describe our proposed optimization approach. First, we propose a partitioning of the set of wireless devices, D, using the VDs with respect to the UAV communication range
VD partitions a two-dimensional plane containing a set of N anchors, called sites, with a set of N Voronoi polygons. Each Voronoi polygon is associated with a unique site (see Fig. 2a) such that any points inside that polygon are closer to the specified site [43,44]. In addition, the vertices of the Voronoi polygon are called Voronoi vertices, and the circles centered at these vertices that pass through the neighboring sites are called Voronoi circles [45] (see Figs. 2b). We note that the site may be shared with more than one Voronoi circle.
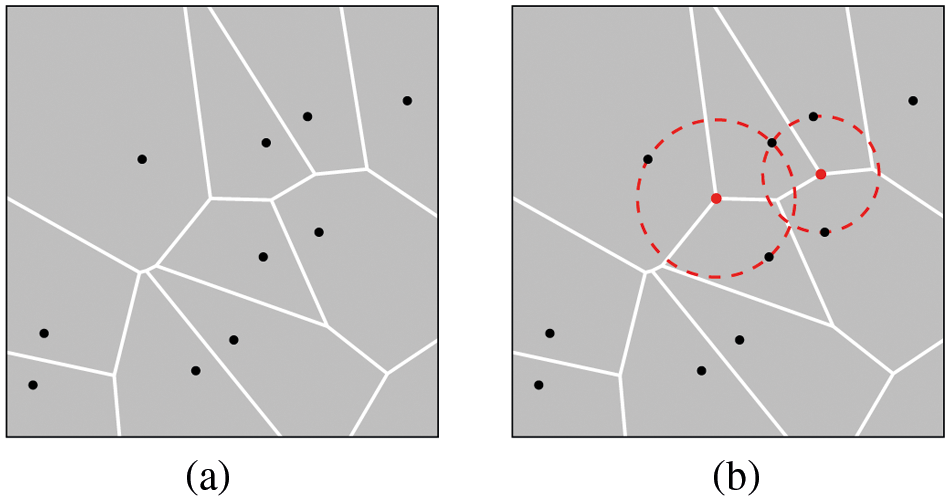
Figure 2: VD construction. (a) Each Voronoi polygon corresponds to a unique site, and (b) the Voronoi circles are centered at Voronoi vertices and pass through the corresponding sites
Given a region R containing a set of mobile devices D, where
1. All of the associated mobile devices in the region should be in the coverage area,
2. The sum of the transmission time and the computation time of the assigned devices in the region should be less than Tu,

Algorithm 1 summarizes the steps for the initial partitioning of D. The input of the algorithm is the set of mobile devices D. The algorithm starts by constructing the Voronoi diagram of the set of devices, VD(D). Once VD is constructed, we identify all of the Voronoi circles of the diagram. For each device di, we identify the corresponding devices,
Starting with the smallest fitting circle L[i], where i = 0, we identify of all the fitting circles L[j] that share at least one device with L[i]. Now, for each L[j], we test whether the circle can be merged with L[i] without violating the constraint specified in Eq. (19). If the merge is eligible, then L[i] is updated to
In fact, the initial partitioning of the given devices may produce unbalanced partitions. Although these initial partitions are constructed in accordance with the time constraints of the UAV, these partitions may increase the transfer time necessary to achieve all the tasks in each partition. When the UAV is in a specified region, the UAV may cover devices from neighboring partitions as shown in Fig. 3. The existence of these overlapping areas creates the possibility of improving the transfer time of such devices. In Fig. 3, device s can be covered from regions R2 and R3. The question here is which is better, offloading the device s within region R2 or within region R3? We use PSO to answer this question by associating s with the corresponding region, which optimizes the overall time, namely, the offloading time, along the UAV trajectory. In the next section, we describe the proposed implementation of GPU-based PSO that finds the optimized association of shared devices and the optimal UAV path that minimizes the overall time and energy consumption.
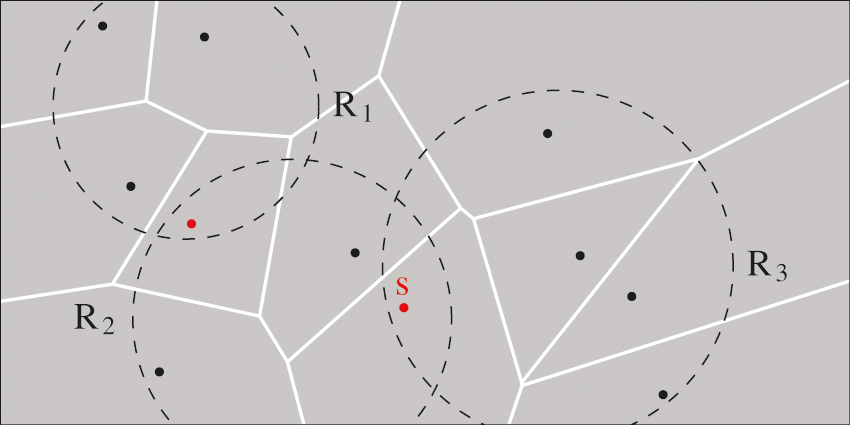
Figure 3: An example of three regions (dashed circles) with shared devices (red)
4.2 GPU-Based Particle Swarm Optimization
In this section, we illustrate how to implement PSO on a GPU architecture. We start by introducing the classical PSO. Then, we summarize the benefits of the current advances of GPUs [46]. In addition, we show how to use GPU-based PSO in optimizing the wireless device association to improve the clustering of the set of devices D. Finally, we illustrate how to choose the shortest path for the UAV that minimizes the problem stated in Eq. (17).
4.2.1 Particle Swarm Optimization
The classical PSO algorithm is classified as a stochastic global optimization technique. PSO was developed in 1995 by Eberhard and Kennedy based on the social behavior of birds or fish [47]. Fig. 4 depicts the overall process of the classical PSO, in which each particle Pi is provided with the following information:
•
•
• bi: the historical best position of Pi.
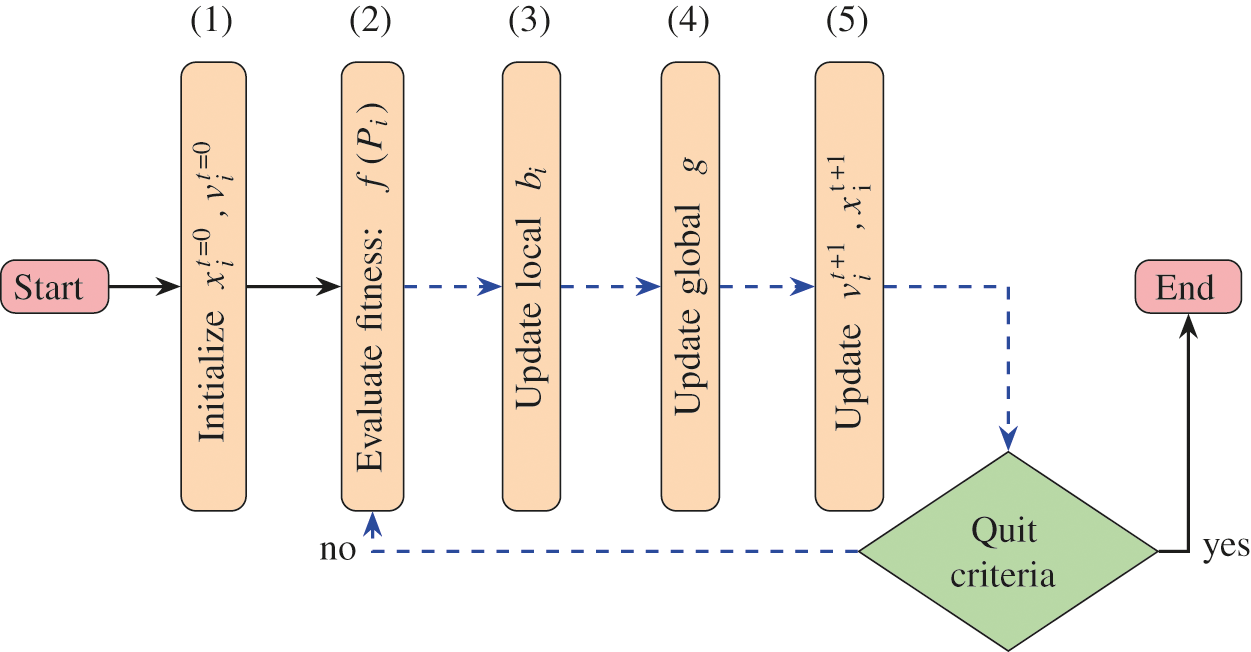
Figure 4: The classical particle swarm optimization algorithm
The algorithm shares the information of the historical global best position among all particles in the swarm, g. Using the PSO, each particle in the swarm adjusts its velocity,
where
This makes all the particles align their positions in the search space to the local and global best positions in the search space. Fig. 5 shows a graphical illustration of the effect of Eqs. (23) and (24) describe the inertia and cognitive and social behaviors of particle Pi. The choice of a convenient value for
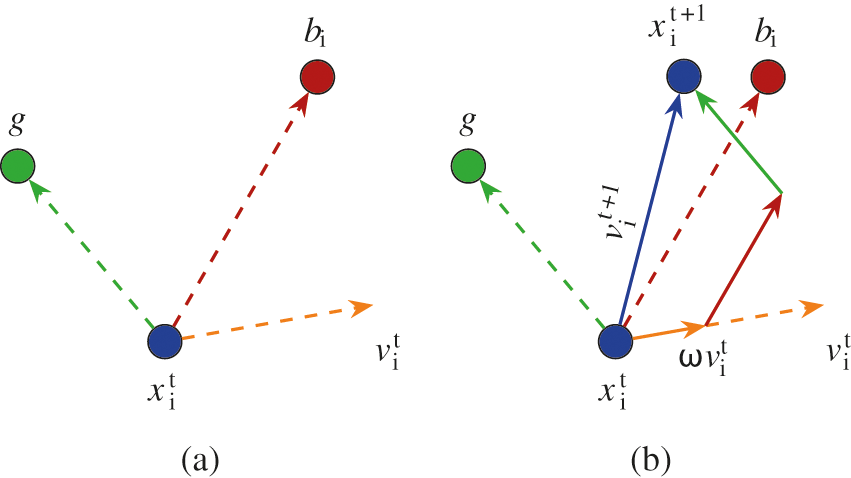
Figure 5: The alignment of the particle position according to cognitive and social behaviors. The orange, red and green solid lines correspond to the inertia and cognitive and social behaviors, respectively, of particle Pi
In fact, PSO has been considered one of the most powerful nature-inspired optimization algorithms. However, for high-dimensional space or large swarm optimization problems, PSO requires performance improvements. This is due to successive evaluations of the fitness function as well as the need to update the particle locations. The first intuitive solution for overcoming this performance degradation is to parallelize the steps from (2)–(5); see the blue shaded loop in Fig. 4 [49]. However, it is insufficient to set subjobs in a parallel calculation job by introducing a single thread for each job that includes a time-consuming evaluation task.
Due to the emergence of General Purpose GPUs (GPGPUs) and their rapid arithmetic kernels, performance has dramatically improved in many fields. In fact, a GPU performs computations faster than a CPU. Due to the high transistor density, floating-point operations can be performed much faster with a GPU than with a CPU because it devotes more transistors to data processing than to data caching and flow control. The second benefit of GPUs is their data-parallel capabilities; they are particularly well suited to problem solving in data-parallel computations with a high arithmetic intensity, that is, for problems where there is a high ratio of arithmetic operations to memory operations.
Furthermore, programming on GPUs has been greatly simplified by the existing platforms, particularly by the Compute Unified Device Architecture (CUDA) [50]. For the CUDA programming concept, as shown in Fig. 6, GPUs can be considered a high-performance computing device capable of handling many threads at the same time. Kernels are the heart of CUDA, and a batch of threads is responsible for executing these kernels simultaneously. This batch is organized as a grid consisting of a number of thread blocks. Generally, a block of threads is a collection of threads. This collection collaborates by allowing data sharing using an efficient and dedicated shared memory. In addition, the collection synchronizes their execution to flawlessly optimize their memory hits. A key feature of CUDA is its memory model that is closely related to the mechanism used by the batch of threads. Every thread has its own local memory, registers, and a unique id. Global memory can be accessed by all threads within a grid, while shared memory can only be accessed within a block. For our implementation, we mostly use shared memory and global memory.
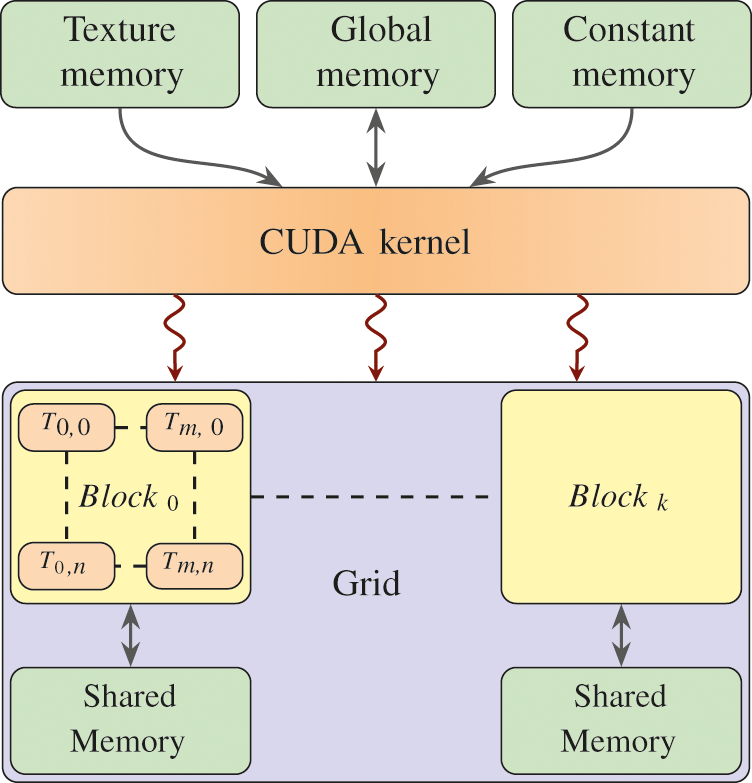
Figure 6: The programming architecture of the CUDA kernel
In this research, we propose a robust implementation of PSO using CUDA. The GPU-based PSO can enhance optimization performance, increase the swarm population, enlarge the size of the problem, and greatly speed up implementation. This allows users to solve critical time problems or complex optimization problems in a reasonable amount of time.
Based on the initial partitioning described in the previous section, we propose a multiobjective GPUPSO that minimizes:
1. The routing path of the UAV,
2. The energy consumption, and
3. The shared devices’ offloading time.
In fact, the association of shared devices affects the overall time and transmission energy since the offloading time and energy depend on the positions of the UAV and the devices, as described in Eqs. (1), (3), (4), and (10). On the other hand, the path of the UAV affects both the time and energy consumption.
Let
In addition, we define the set of regions
1.
2.
Now, we define the structure of the part concerning the first objective. First, each
The cost consists of the sum of the total time and energy transmission for devices in D′. For the second objective, we define the structure of this part as a set of floating values describing the priority of visiting the partitions Ri by the UAV;
The final structure of particle Pi is the concatenation of

The experiments are performed on an NVIDIA CUDA Maxwell architecture embedded in an Intel Core i7-8565U CPU running at 1.8 and 1.99 GHz and a GeForce MX130 GPU with 4 GB RAM under Windows 10. Here, we present some experimental results that demonstrate the effectiveness of the proposed approach. A set of wireless devices is randomly distributed over the square region of

Fig. 7 shows a graphical illustration of the proposed approach. First, a set of 40 wireless devices is randomly generated, as shown in Fig. 7a. The VDs of these devices are created using the sweep-line algorithm [53,54], as shown in Fig. 7b. For each device, the corresponding Voronoi circles are determined, as shown in Fig. 7c, to apply the merging step. In the merging step, the Voronoi vertices are merged together, as described in Algorithm1 with respect to the UAV covering radius
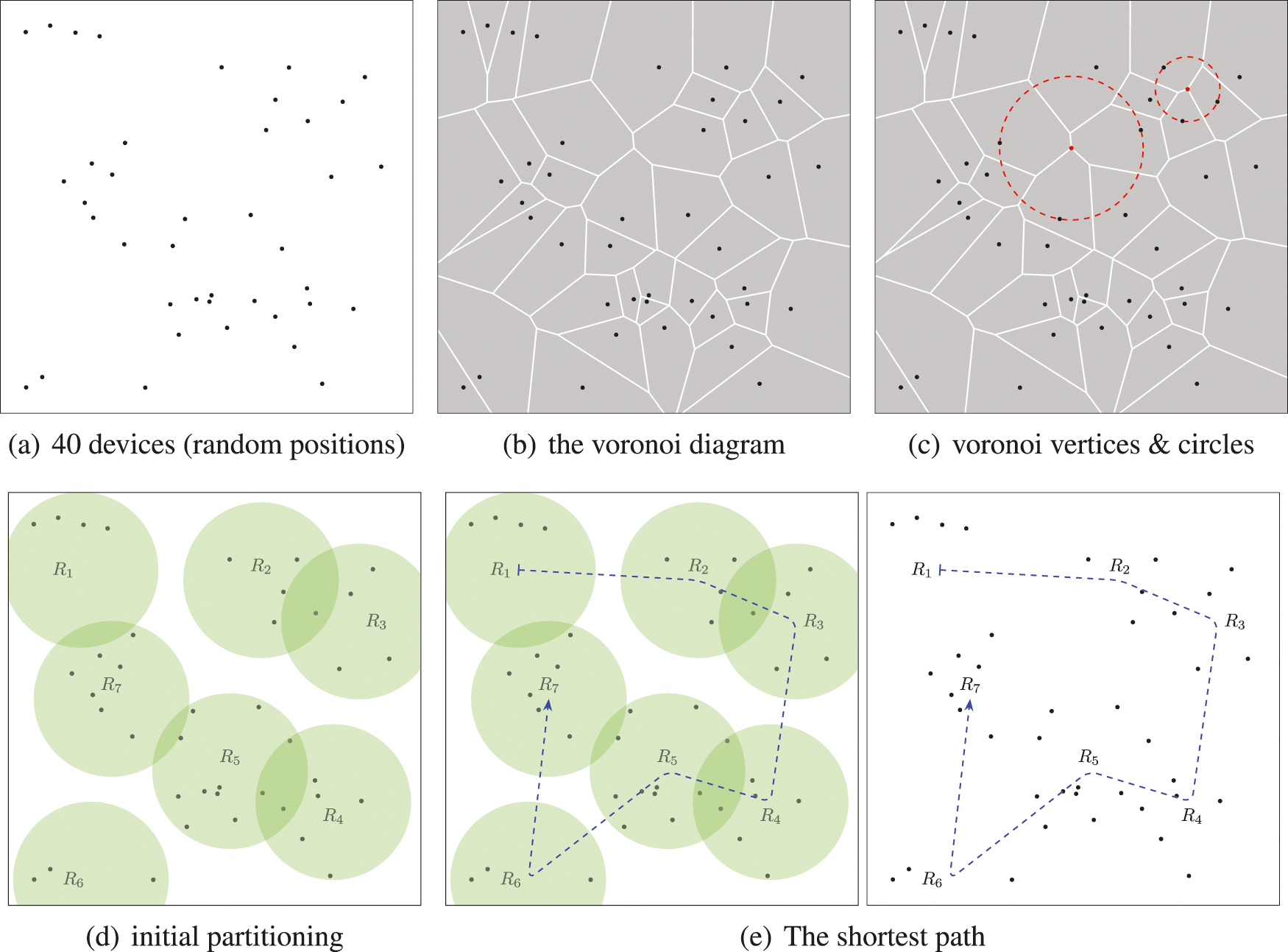
Figure 7: (a) The set of devices, (b) the Voronoi diagram of the devices, (c) the Voronoi vertices (red) and their corresponding Voronoi circles, (d) the initial partitioning of the devices, and (e) the shortest path
Moreover, we compare the proposed optimization of our system vs. a GA. In fact, the GA is a metaheuristic optimization approach based on natural reproduction phenomena. The GA simulates the three main Darwinian operators of natural evolution, namely, selection of the fittest, crossover, and mutation operators. The algorithm starts by randomly initializing an initial population and selecting the fittest individuals for reproduction (applying the crossover and mutation) of the next generation offspring. The individual structure is called a chromosome. In our experiments, we use a chromosome structure similar to the proposed particle structure, as described in Section 4.2.3, and apply the classical GA operators. Fig. 8 shows a comparison of the proposed optimization and a GA. The population size is 800 particles (or individuals for GA). Fig. 8 shows that the proposed GPU-based PSO has a higher convergence rate than the GA.
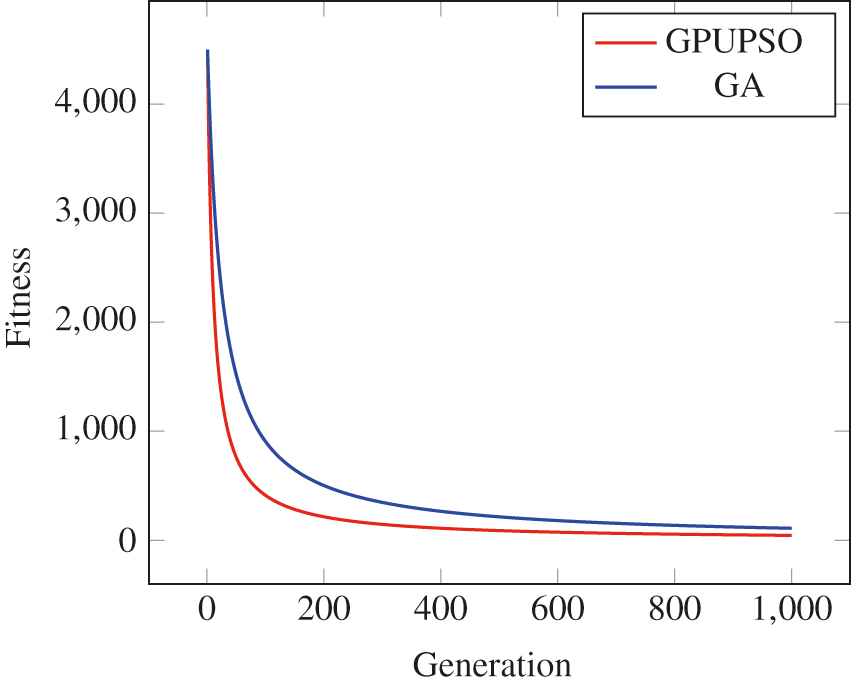
Figure 8: A comparison between the proposed GPU-based PSO (red) and a GA (blue). The GPU-based PSO converges faster to the optimal value than the GA
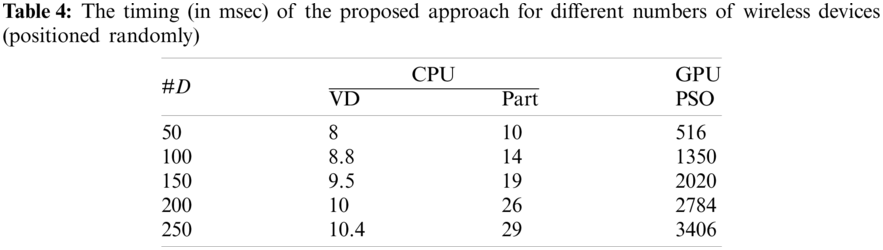
The analysis of the computational time shows that the GPU architecture speeds up calculation, as presented in Table 4. The columns from left to right are the number of wireless devices, the Voronoi construction time, the partitioning time, and the optimization time. The number of iterations and swarm size are set to 1000 and 800, respectively. The timings presented in Table 4 show that the optimization process incurs the main bulk of the computational cost of the proposed approach. In addition, when the number of wireless devices increases, the dimensionality of the problem also increases, and the optimization step is the most strongly affected portion of the proposed approach. However, due to the high performance of the GPU architecture, the performance difference is negligible.
This paper proposed a UCMEC system to improve the performance of offloading tasks from mobile devices with the goal of minimizing the task delay and the energy consumption of the system. The proposed system partitions the ground devices into regions where the UAV can hover over each region to process the offloaded tasks. A VD is used for the partitioning process. The UAV trajectory over the regions is optimized using a GPU-based PSO. The performance of the proposed system was validated by comparison with other algorithms in the literature.
The limitation of the proposed offloading process is that it is valid only for stationary devices. In other words, it does not take into account the dynamic positioning of the ground sensors. In addition, the performance of the PSO in defining the optimal clustering and the shortest path of the UAV is very sensitive to the intrinsic parameters of the PSO, namely, the inertia, cognitive, and social parameters. In fact, this is a general drawback for all metaheuristic approaches. Our future work will consider the mobility of ground devices as well as the adaptive setting of the algorithm parameters.
Funding Statement: This work was funded by the University of Jeddah, Saudi Arabia, under Grant No. (UJ-20-102-DR). The authors, therefore, acknowledge the technical and financial support by the University.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Hussein, M. K., Mousa, M. H. (2020). Efficient task offloading for IoT-based applications in fog computing using ant colony optimization. IEEE Access, 8, 37191–37201. DOI 10.1109/Access.6287639. [Google Scholar] [CrossRef]
2. Jiang, E., Wang, L., Wang, J. (2021). Decomposition-based multi-objective optimization for energy-aware distributed hybrid flow shop scheduling with multiprocessor tasks. Tsinghua Science and Technology, 26(5), 646–663. DOI 10.26599/TST.2021.9010007. [Google Scholar] [CrossRef]
3. Xu, X., Li, H., Xu, W., Liu, Z., Yao, L. et al. (2022). Artificial intelligence for edge service optimization in internet of vehicles: A survey. Tsinghua Science and Technology, 27(2), 270–287. DOI 10.26599/TST.2020.9010025. [Google Scholar] [CrossRef]
4. Wang, S., Zhang, X., Zhang, Y., Wang, L., Yang, J. et al. (2017). A survey on mobile edge networks: Convergence of computing, caching and communications. IEEE Access, 5, 6757–6779. DOI 10.1109/ACCESS.2017.2685434. [Google Scholar] [CrossRef]
5. Mabrouki, J., Azrour, M., Dhiba, D., Farhaoui, Y., Hajjaji, S. E. (2021). IoT-Based data logger for weather monitoring using arduino-based wireless sensor networks with remote graphical application and alerts. Big Data Mining and Analytics, 4(1), 25–32. DOI 10.26599/BDMA.2020.9020018. [Google Scholar] [CrossRef]
6. Malek, Y. N., Najib, M., Bakhouya, M., Essaaidi, M. (2021). Multivariate deep learning approach for electric vehicle speed forecasting. Big Data Mining and Analytics, 4(1), 56–64. DOI 10.26599/BDMA.2020.9020027. [Google Scholar] [CrossRef]
7. Mohamed, N., Al-Jaroodi, J., Jawhar, I., Noura, H., Mahmoud, S. (2017). UAVFog: A UAV-based fog computing for internet of things. 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), San Francisco, CA, USA, IEEE. https://ieeexplore.ieee.org/document/8397657/. [Google Scholar]
8. Cheng, N., Xu, W., Shi, W., Zhou, Y., Lu, N. et al. (2018). Air-ground integrated mobile edge networks: Architecture, challenges, and opportunities. IEEE Communications Magazine, 56(8), 26–32. DOI 10.1109/MCOM.35. [Google Scholar] [CrossRef]
9. Liu, Y., Song, Z., Xu, X., Rafique, W., Zhang, X. et al. (2021). Bidirectional GRU networks-based next POI category prediction for healthcare. International Journal of Intelligent Systems. DOI 10.1002/int.22710. [Google Scholar] [CrossRef]
10. Yuan, L., He, Q., Chen, F., Zhang, J., Qi, L. et al. (2022). CSEdge: Enabling collaborative edge storage for multi-access edge computing based on blockchain. IEEE Transactions on Parallel and Distributed Systems, 33(8), 1873–1887. DOI 10.1109/TPDS.2021.3131680. [Google Scholar] [CrossRef]
11. Xu, X., Liu, X., Yin, X., Wang, S., Qi, Q. et al. (2020). Privacy-aware offloading for training tasks of generative adversarial network in edge computing. Information Sciences, 532, 1–15. DOI 10.1016/j.ins.2020.04.026. [Google Scholar] [CrossRef]
12. Bejaoui, A., Park, K. H., Alouini, M. S. (2020). A QoS-oriented trajectory optimization in swarming unmanned-aerial-vehicles communications. IEEE Wireless Communications Letters, 9(6), 791–794. DOI 10.1109/LWC.5962382. [Google Scholar] [CrossRef]
13. Zhu, B. J., Hou, Z. X., Lu, Y. F., Shan, S. Q. (2015). The direction zone of engineless UAVs in dynamic soaring. Computer Modeling in Engineering and Sciences, 105(6), 467–490. DOI 10.3970/cmes.2015.105.467. [Google Scholar] [CrossRef]
14. Zhu, B. J., Hou, Z. X., Wang, X. Z., Chen, Q. Y. (2015). Long endurance and long distance trajectory optimization for engineless UAV by dynamic soaring. Computer Modeling in Engineering & Sciences, 106(5), 357–377. DOI 10.3970/cmes.2015.106.357. [Google Scholar] [CrossRef]
15. Liu, D. N., Hou, Z. X., Guo, Z., Yang, X. X., Gao, X. Z. (2016). Permissible wind conditions for optimal dynamic soaring with a small unmanned aerial vehicle. Computer Modeling in Engineering & Sciences, 111(6), 531–565. DOI 10.3970/cmes.2016.111.531. [Google Scholar] [CrossRef]
16. Aggarwal, S., Kumar, N. (2020). Path planning techniques for unmanned aerial vehicles: A review, solutions, and challenges. Computer Communications, 149, 270–299. DOI 10.1016/j.comcom.2019.10.014. [Google Scholar] [CrossRef]
17. Zhang, J., Chen, T., Zhong, S., Wang, J., Zhang, W. et al. (2019). Aeronautical AdHoc networking for the internet-above-the-clouds. Proceedings of the IEEE, 107(5), 868–911. DOI 10.1109/PROC.5. [Google Scholar] [CrossRef]
18. Qi, X., Li, B., Chu, Z., Huang, K., Chen, H. et al. (2019). Secrecy energy efficiency performance in communication networks with mobile sinks. Physical Communication, 32, 41–49. DOI 10.1016/j.phycom.2018.06.009. [Google Scholar] [CrossRef]
19. Wang, J., Jiang, C., Wei, Z., Pan, C., Zhang, H. et al. (2019). Joint UAV hovering altitude and power control for space-air-ground IoT networks. IEEE Internet of Things Journal, 6(2), 1741–1753. DOI 10.1109/JIoT.6488907. [Google Scholar] [CrossRef]
20. Fu, S., Tang, Y., Zhang, N., Zhao, L., Wu, S. et al. (2020). Joint unmanned aerial vehicle (UAV) deployment and power control for internet of things networks. IEEE Transactions on Vehicular Technology, 69(4), 4367–4378. DOI 10.1109/TVT.25. [Google Scholar] [CrossRef]
21. Mao, Y., You, C., Zhang, J., Huang, K., Letaief, K. B. (2017). A survey on mobile edge computing: The communication perspective. IEEE Communications Surveys & Tutorials, 19(4), 2322–2358. DOI 10.1109/COMST.2017.2745201. [Google Scholar] [CrossRef]
22. Zhou, F., Hu, R. Q., Li, Z., Wang, Y. (2020). Mobile edge computing in unmanned aerial vehicle networks. IEEE Wireless Communications, 27(1), 140–146. DOI 10.1109/MWC.7742. [Google Scholar] [CrossRef]
23. Wang, D., Tan, D., Liu, L. (2018). Particle swarm optimization algorithm: An overview. Soft Computing, 22(2), 387–408. DOI 10.1007/s00500-016-2474-6. [Google Scholar] [CrossRef]
24. Yu, Y. (2016). Mobile edge computing towards 5G: Vision, recent progress, and open challenges. China Communications, 13(Supplement 2), 89–99. DOI 10.1109/CC.6245522. [Google Scholar] [CrossRef]
25. Zakaryia, S. A., Ahmed, S. A., Hussein, M. K. (2021). Evolutionary offloading in an edge environment. Egyptian Informatics Journal, 22(3), 257–267. DOI 10.1016/j.eij.2020.09.003. [Google Scholar] [CrossRef]
26. Nguyen, V., Khanh, T. T., van Nam, P., Thu, N. T., Seon Hong, C. et al. (2020). Towards flying mobile edge computing. 2020 International Conference on Information Networking (ICOIN), Barcelona, Spain, IEEE. https://ieeexplore.ieee.org/document/9016537/. [Google Scholar]
27. Hu, Q., Cai, Y., Yu, G., Qin, Z., Zhao, M. et al. (2019). Joint offloading and trajectory design for UAV-enabled mobile edge computing systems. IEEE Internet of Things Journal, 6(2), 1879–1892. DOI 10.1109/JIoT.6488907. [Google Scholar] [CrossRef]
28. Wang, R., Cao, Y., Noor, A., Alamoudi, T. A., Nour, R. (2020). Agent-enabled task offloading in UAV-aided mobile edge computing. Computer Communications, 149, 324–331. DOI 10.1016/j.comcom.2019.10.021. [Google Scholar] [CrossRef]
29. Tang, Q., Chang, L., Yang, K., Wang, K., Wang, J. et al. (2020). Task number maximization offloading strategy seamlessly adapted to UAV scenario. Computer Communications, 151, 19–30. DOI 10.1016/j.comcom.2019.12.018. [Google Scholar] [CrossRef]
30. Yang, L., Yao, H., Wang, J., Jiang, C., Benslimane, A. et al. (2020). Multi-UAV-enabled load-balance mobile-edge computing for IoT networks. IEEE Internet of Things Journal, 7(8), 6898–6908. DOI 10.1109/JIoT.6488907. [Google Scholar] [CrossRef]
31. Li, M., Cheng, N., Gao, J., Wang, Y., Zhao, L. et al. (2020). Energy-efficient UAV-assisted mobile edge computing: Resource allocation and trajectory optimization. IEEE Transactions on Vehicular Technology, 69(3), 3424–3438. DOI 10.1109/TVT.25. [Google Scholar] [CrossRef]
32. Wang, Y., Ru, Z. Y., Wang, K., Huang, P. Q. (2020). Joint deployment and task scheduling optimization for large-scale mobile users in multi-UAV-enabled mobile edge computing. IEEE Transactions on Cybernetics, 50(9), 3984–3997. DOI 10.1109/TCYB.6221036. [Google Scholar] [CrossRef]
33. Chen, J., Chen, S., Luo, S., Wang, Q., Cao, B. et al. (2020). An intelligent task offloading algorithm (iTOA) for UAV edge computing network. Digital Communications and Networks, 6(4), 433–443. DOI 10.1016/j.dcan.2020.04.008. [Google Scholar] [CrossRef]
34. Hu, X., Wong, K. K., Yang, K., Zheng, Z. (2019). UAV-Assisted relaying and edge computing: Scheduling and trajectory optimization. IEEE Transactions on Wireless Communications, 18(10), 4738–4752. DOI 10.1109/TWC.7693. [Google Scholar] [CrossRef]
35. Li, L., Wen, X., Lu, Z., Jing, W. (2020). An energy efficient design of computation offloading enabled by UAV. Sensors, 20(12), 3363. DOI 10.3390/s20123363. [Google Scholar] [CrossRef]
36. Zhan, C., Hu, H., Sui, X., Liu, Z., Niyato, D. (2020). Completion time and energy optimization in the UAV-enabled mobile-edge computing system. IEEE Internet of Things Journal, 7(8), 7808–7822. DOI 10.1109/JIoT.6488907. [Google Scholar] [CrossRef]
37. Guo, H., Liu, J. (2020). UAV-Enhanced intelligent offloading for internet of things at the edge. IEEE Transactions on Industrial Informatics, 16(4), 2737–2746. DOI 10.1109/TII.9424. [Google Scholar] [CrossRef]
38. Yu, Z., Gong, Y., Gong, S., Guo, Y. (2020). Joint task offloading and resource allocation in UAV-enabled mobile edge computing. IEEE Internet of Things Journal, 7(4), 3147–3159. DOI 10.1109/JIoT.6488907. [Google Scholar] [CrossRef]
39. Lan, Y., Wang, X., Wang, C., Wang, D., Li, Q. (2019). Collaborative computation offloading and resource allocation in cache-aided hierarchical edge-cloud systems. Electronics, 8(12), 1430. DOI 10.3390/electronics8121430. [Google Scholar] [CrossRef]
40. Wang, L., Wang, K., Pan, C., Xu, W., Aslam, N. et al. (2021). Deep reinforcement learning based dynamic trajectory control for UAV-assisted mobile edge computing. IEEE Transactions on Mobile Computing, 1. DOI 10.1109/TMC.7755. [Google Scholar] [CrossRef]
41. He, H., Zhang, S., Zeng, Y., Zhang, R. (2018). Joint altitude and beamwidth optimization for UAV-enabled multiuser communications. IEEE Communications Letters, 22(2), 344–347. DOI 10.1109/LCOMM.2017.2772254. [Google Scholar] [CrossRef]
42. Wu, F., Yang, D., Xiao, L., Cuthbert, L. (2019). Energy consumption and completion time tradeoff in rotary-wing UAV enabled WPCN. IEEE Access, 7, 79617–79635. DOI 10.1109/Access.6287639. [Google Scholar] [CrossRef]
43. Aurenhammer, F., Klein, R. (2000). Voronoi diagrams**Partially supported by the Deutsche Forschungsgemeinschaft, grant K1 655 2-2. Handbook of Computational Geometry, pp. 201–290. North-Holland: Elsevier. https://linkinghub.elsevier.com/retrieve/pii/B9780444825377500061. [Google Scholar]
44. Guiling, W., Guohong, C., LaPorta, T. (2003). A bidding protocol for deploying mobile sensors. 11th IEEE International Conference on Network Protocols, USA, http://ieeexplore.ieee.org/document/1249781. [Google Scholar]
45. Edla, D. R., Jana, P. K. (2012). A novel clustering algorithm using voronoi diagram. Seventh International Conference on Digital Information Management (ICDIM 2012), Macau, Macao, IEEE. http://ieeexplore.ieee.org/document/6360125/. [Google Scholar]
46. Mousa, M. H., Hussein, M. K. (2021). High-performance simplification of triangular surfaces using a GPU. PLoS One, 16(8), e0255832. DOI 10.1371/journal.pone.0255832. [Google Scholar] [CrossRef]
47. Kennedy, J., Eberhart, R. (1995). Particle swarm optimization. International Conference on Neural Networks, vol. 4. Perth, WA, Australia, IEEE. http://ieeexplore.ieee.org/document/488968/. [Google Scholar]
48. Cui, H., Shu, M., Song, M., Wang, Y. (2017). Parameter selection and performance comparison of particle swarm optimization in sensor networks localization. Sensors, 17(3), 487. DOI 10.3390/s17030487. [Google Scholar] [CrossRef]
49. Lalwani, S., Sharma, H., Satapathy, S. C., Deep, K., Bansal, J. C. (2019). A survey on parallel particle swarm optimization algorithms. Arabian Journal for Science and Engineering, 44(4), 2899–2923. DOI 10.1007/s13369-018-03713-6. [Google Scholar] [CrossRef]
50. NVIDIA (2021). Compute Unified Device Architecture (CUDA) Programming Guide. https://docs.nvidia.com/cuda/. [Google Scholar]
51. Elloumi, M., Escrig, B., Dhaou, R., Idoudi, H., Saidane, L. A. (2017). Designing an energy efficient UAV tracking algorithm. 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, IEEE. http://ieeexplore.ieee.org/document/7986274/. [Google Scholar]
52. Al-Shabi, M. A., Hatamleh, K. S., Asad, A. A. (2013). UAV dynamics model parameters estimation techniques: A comparison study. 2013 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), Amman, Jordan, IEEE. http://ieeexplore.ieee.org/document/6716436/. [Google Scholar]
53. Fortune, S. (1987). A sweepline algorithm for voronoi diagrams. Algorithmica, 2(1–4), 153–174. DOI 10.1007/BF01840357. [Google Scholar] [CrossRef]
54. Software (2019). A C implementation for creating 2D voronoi diagrams. https://github.com/JCash/voronoi. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |