
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Optimizing BERT for Bengali Emotion Classification: Evaluating Knowledge Distillation, Pruning, and Quantization
Department of Electrical and Computer Engineering, North South University, Dhaka, 1229, Bangladesh
* Corresponding Author: Rashedur M. Rahman. Email:
(This article belongs to the Special Issue: Emerging Artificial Intelligence Technologies and Applications)
Computer Modeling in Engineering & Sciences 2025, 142(2), 1637-1666. https://doi.org/10.32604/cmes.2024.058329
Received 10 September 2024; Accepted 22 November 2024; Issue published 27 January 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
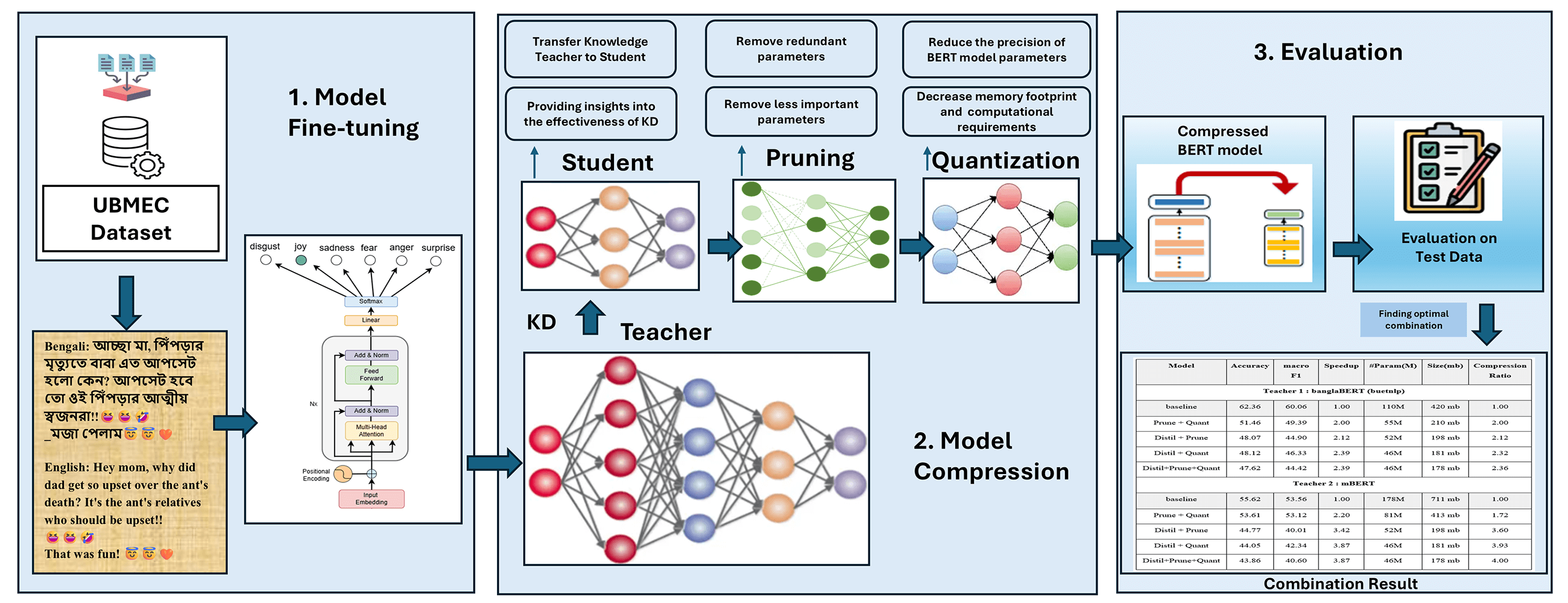
The rapid growth of digital data necessitates advanced natural language processing (NLP) models like BERT (Bidirectional Encoder Representations from Transformers), known for its superior performance in text classification. However, BERT’s size and computational demands limit its practicality, especially in resource-constrained settings. This research compresses the BERT base model for Bengali emotion classification through knowledge distillation (KD), pruning, and quantization techniques. Despite Bengali being the sixth most spoken language globally, NLP research in this area is limited. Our approach addresses this gap by creating an efficient BERT-based model for Bengali text. We have explored 20 combinations for KD, quantization, and pruning, resulting in improved speedup, fewer parameters, and reduced memory size. Our best results demonstrate significant improvements in both speed and efficiency. For instance, in the case of mBERT, we achieved a 3.87× speedup and 4× compression ratio with a combination of Distil + Prune + Quant that reduced parameters from 178 to 46 M, while the memory size decreased from 711 to 178 MB. These results offer scalable solutions for NLP tasks in various languages and advance the field of model compression, making these models suitable for real-world applications in resource-limited environments.Graphic Abstract
Keywords
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools